ディプロマシーというボードゲームのためのAI
'ディプロマシー'というボードゲームのAI
エージェントはコミュニケーションと交渉を通じてより良く協力し、約束を破った場合の罰則は彼らを誠実に保つのに役立ちます
成功したコミュニケーションと協力は、歴史を通じて社会の進歩を助けるために重要でした。ボードゲームの閉じられた環境は、相互作用とコミュニケーションのモデリングと調査のための砂場として機能し、私たちはそれらをプレイすることで多くのことを学ぶことができます。私たちの最近の論文は、人工エージェントがコミュニケーションを使ってボードゲーム「Diplomacy」でより良く協力する方法を示しています。このゲームは、人工知能(AI)研究の活発な領域であり、同盟構築に焦点を当てて知られています。
Diplomacyは、シンプルなルールを持ちながらも、プレイヤー間の強い相互依存関係と膨大な行動範囲により、高い出現的複雑性を持つため、挑戦的なゲームです。この課題を解決するために、私たちは交渉アルゴリズムを設計しました。これにより、エージェントがコミュニケーションを行い、共同計画に合意することができ、この能力を持たないエージェントを克服することができます。
相手が約束を守らない場合、協力は特に困難です。私たちはDiplomacyを使用して、エージェントが過去の合意から逸脱する可能性がある場合に何が起こるかを探求するための砂場として使用しています。私たちの研究は、複雑なエージェントが意図を誤表示したり、将来の計画について他の人を誤導したりする場合に生じるリスクを示しており、それに伴う大きな問いが浮かび上がります:信頼できるコミュニケーションとチームワークを促進する条件は何でしょうか?
私たちは、契約を破る同僚に制裁を加える戦略が、彼らが約束を放棄することによって得られる利点を劇的に減少させ、より正直なコミュニケーションを促進することを示しています。
Diplomacyとは何か、そしてなぜ重要なのか?
チェス、ポーカー、囲碁、さまざまなビデオゲームなどのゲームは、常にAI研究の豊かな土壌でした。Diplomacyは、交渉と同盟形成の7人プレイヤーゲームであり、ヨーロッパの古い地図を用いたもので、各プレイヤーは複数のユニットを制御します(Diplomacyのルール)。ゲームの標準バージョンであるPress Diplomacyでは、各ターンには交渉フェーズが含まれ、その後、すべてのプレイヤーが選択した動きを同時に公開します。
Diplomacyの核心は、プレイヤーが次の動きについて合意しようとする交渉フェーズです。例えば、あるユニットは他のユニットに支援を行い、他のユニットによる抵抗を克服することができます。以下に示すような例です:

Diplomacyへの計算的アプローチは1980年代から研究されており、その多くはNo-Press Diplomacyと呼ばれるより単純なバージョンのゲームで探求されました。このバージョンでは、プレイヤー間の戦略的なコミュニケーションは許されていません。研究者たちはまた、コンピュータに適した交渉プロトコル、いわゆる「Restricted-Press」を提案しています。
私たちは何を研究しましたか?
私たちはDiplomacyを現実世界の交渉のアナログとして使用し、AIエージェントが動きを調整するための方法を提供しました。コミュニケーションを行わないDiplomacyエージェントを取り、共同行動のための契約交渉のプロトコルを与えることで、彼らをDiplomacyでプレイするように拡張しました。これらの拡張エージェントをBaseline Negotiatorsと呼び、彼らは彼らの合意に拘束されています。

私たちは2つのプロトコルを考慮しています:相互提案プロトコルと提案-選択プロトコル。詳細は本文で詳しく説明されています。私たちのエージェントは、さまざまな契約の下でゲームがどのように展開するかをシミュレートし、相互に利益のある取引を特定するアルゴリズムを適用します。私たちはゲーム理論からのナッシュ交渉解を使用して、高品質の合意を特定するための原則的な基盤としています。ゲームはプレーヤーの行動によってさまざまな方法で展開する可能性があるため、私たちのエージェントは次のターンで起こり得ることを見るためにモンテカルロシミュレーションを使用します。
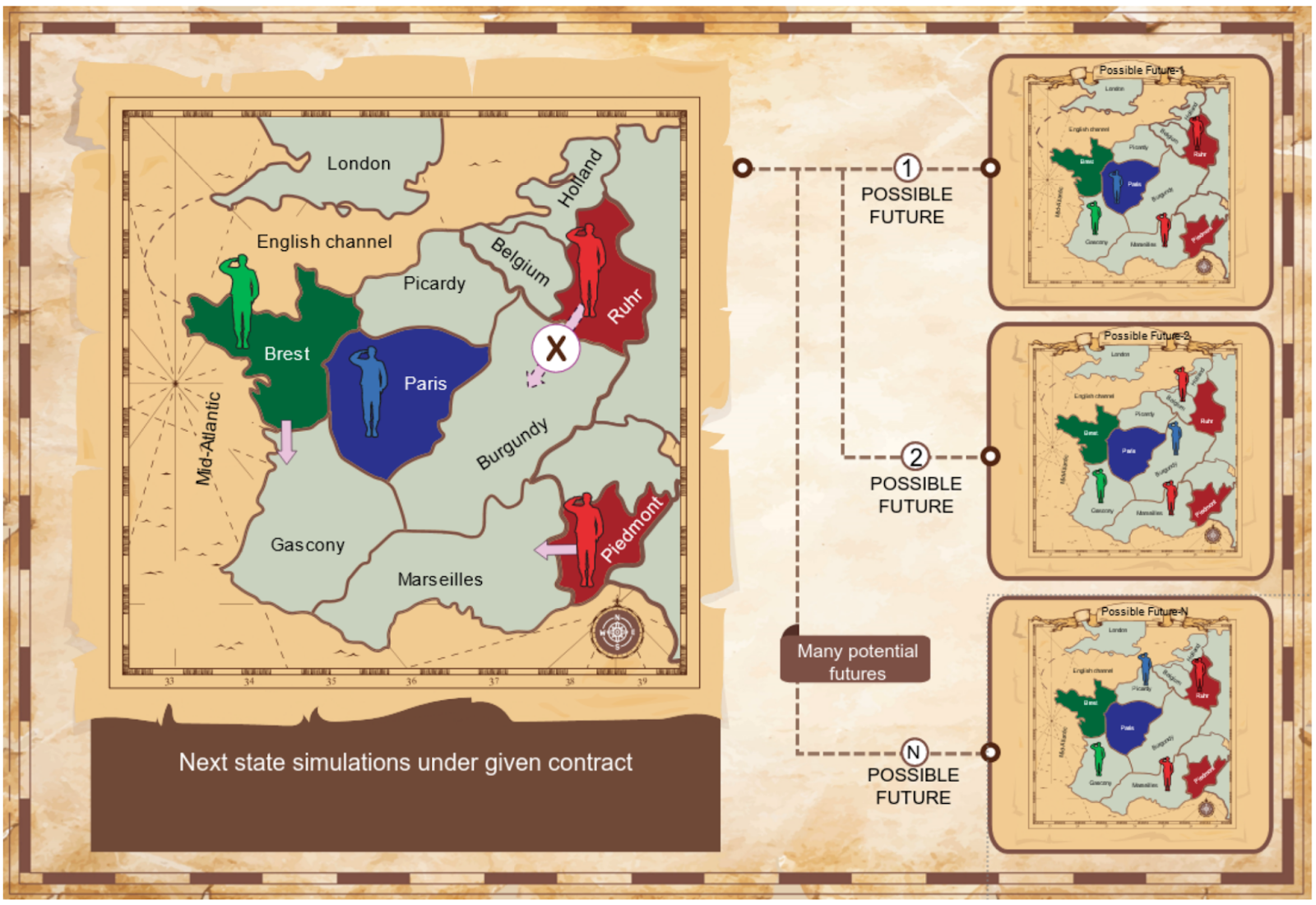
私たちの実験では、交渉メカニズムによってBaseline Negotiatorsが基準の非コミュニケーションエージェントを大幅に上回ることが示されています。

合意を破るエージェント
外交において、交渉中に行われる合意は拘束力を持ちません(コミュニケーションは「安い話し合い」です)。しかし、1ターンで契約に同意したエージェントが次のターンにそれを逸脱するとどうなるでしょうか?多くの現実の状況では、人々は特定の方法で行動することに同意しますが、後でその約束を守ることができません。AIエージェント間やエージェントと人間の間での協力を可能にするためには、エージェントが戦略的に合意を破る可能性と、この問題を解決する方法を検討する必要があります。私たちは外交を使用して、コミットメントを放棄する能力が信頼と協力を侵食する方法、および誠実な協力を促進する条件を研究しました。
したがって、私たちは合意した契約から逸脱することで正直なBaseline Negotiatorsに勝つDeviator Agentsを考慮しています。シンプルなDeviatorsは単に契約に同意したことを「忘れ」、自由に動くものです。条件付きDeviatorsはより洗練されており、契約に同意した他のプレーヤーがそれに従うと仮定して行動を最適化します。

私たちは、シンプルで条件付きのディヴィエーターが、ベースラインの交渉者よりもはるかに優れたパフォーマンスを発揮することを示しています。特に、条件付きのディヴィエーターは圧倒的な優位性を持っています。

エージェントに正直であるよう促す
次に、ディヴィエーションの問題に対処するために、ディフェンシブエージェントを使用します。ディフェンシブエージェントは、ディヴィエーションに逆に反応するエージェントであり、Binary Negotiatorsと呼ばれるエージェントを調査します。彼らは、彼らとの合意を破るエージェントとの通信をただちに絶つだけです。しかし、これは軽微な反応ですので、サンクショニングエージェントと呼ばれるエージェントも開発しました。彼らは裏切りを軽視せず、代わりにディヴィエーターの価値を積極的に下げるために目標を変更します-恨みを持つ相手です!我々は、どちらのタイプのディフェンシブエージェントもディヴィエーションの優位性を低下させることを示していますが、特にサンクショニングエージェントが効果的です。
最後に、サンクショニングエージェントに対して複数のゲームで行動を適応させ、最適化する学習ディヴィエーターを紹介します。学習ディヴィエーターは、ディヴィエーションからの即時の利益が十分に高く、他のエージェントの報復能力が十分に低い場合にのみ契約を破ります。実際には、学習ディヴィエーターはゲーム終盤に契約を破ることがあり、それによってサンクショニングエージェントよりわずかな優位性を獲得します。しかし、そのような制裁は、学習ディヴィエーターが99.7%以上の契約を守るように促します。
また、サンクショニングとディヴィエーションの学習ダイナミクスも調査しています。サンクショニングエージェントも契約を破る可能性がある場合や、この行動がコストのかかる場合にサンクショニングを停止するインセンティブが生じる可能性があります。このような問題は協力関係を徐々に侵食することがありますので、複数のゲームでの反復的な相互作用や信頼と評判システムのような追加のメカニズムが必要とされるかもしれません。
私たちの論文は、将来の研究に多くの問いを残しています: より洗練されたプロトコルを設計して、さらに正直な行動を促進することは可能でしょうか? コミュニケーション技術と不完全な情報の組み合わせをどのように扱うことができるのでしょうか? 最後に、他のどのような仕組みが合意の破棄を防ぐことができるのでしょうか? 公正で透明性のある信頼できるAIシステムの構築は、非常に重要なトピックであり、DeepMindのミッションの重要な一部です。Diplomacyのような砂場でこれらの問題を研究することは、協力と競争の緊張関係を現実世界で理解するために役立ちます。最終的に、これらの課題に取り組むことで、社会の価値観と優先事項に沿ったAIシステムの開発方法をより良く理解できると信じています。
私たちの完全な論文はこちらで読むことができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






