テキストデータのチャンキング方法-比較分析
テキストデータのチャンキング方法-比較分析
テキストチャンキングの異なるアプローチを探索する。
はじめに
Natural Language Processing(NLP)における「テキストチャンキング」とは、非構造化テキストデータを意味のある単位に変換するプロセスです。この見かけ上簡単なタスクには、それを達成するために使用されるさまざまな方法の複雑さが隠されています。それぞれに長所と短所を持つさまざまな手法があります。
大まかなレベルでは、これらの手法は通常、2つのカテゴリのいずれかに属します。最初のルールベースの手法は、句読点やスペース文字などの明示的な区切り文字の使用、または正規表現などの高度なシステムの適用に依存してテキストをチャンクに分割します。2番目のカテゴリである意味クラスタリング手法は、テキストに埋め込まれた固有の意味を活用してチャンキングプロセスを導きます。これには、機械学習アルゴリズムを使用してコンテキストを把握し、テキスト内の自然な区分を推測することが含まれます。
この記事では、これら2つの異なるテキストチャンキング手法を探求し、比較します。ルールベースの手法をNLTK、Spacy、Langchainで表し、これをKMeansと隣接文クラスタリングの2つの異なる意味クラスタリング手法と対比します。
この目的は、実践者が各手法の長所、短所、理想的な使用ケースを明確に理解し、NLPプロジェクトでのより良い意思決定を可能にすることです。
- 軌跡予測のためのマップマッチング
- 「時系列分析のための欠落した日付の修正方法」
- 「ChatGPTのリリースはオープンデータの生産に影響を与えているのか? 研究者が調査し、人気を集めるLLMがStackOverflowのコンテンツの大幅な減少をもたらしていることを検証」
ブラジルの俗語では、「abacaxi」は「パイナップル」という意味で、「良い結果を生み出さないもの、もつれたもの、または良くないもの」という意味を持ちます。
テキストチャンキングの用途
テキストチャンキングは、さまざまなアプリケーションで使用されることがあります:
- テキスト要約:大量のテキストを管理可能なチャンクに分割することで、各セクションを個別に要約し、より正確な全体の要約を作成することができます。
- 感情分析:短い、一貫したチャンクの感情を分析することは、文書全体を分析するよりも正確な結果を得ることができることがよくあります。
- 情報抽出:チャンキングは、テキスト内の特定のエンティティやフレーズを特定するのに役立ち、情報検索のプロセスを向上させます。
- テキスト分類:テキストをチャンクに分割することで、分類器は文書全体ではなく、文脈に関連する意味のある小さな単位に焦点を当てることができます。これにより、パフォーマンスが向上する場合があります。
- 機械翻訳:翻訳システムはしばしば単語や文書全体ではなく、テキストのチャンクで動作します。チャンキングは、翻訳されたテキストの一貫性を保つのに役立ちます。
これらの用途を理解することで、特定のプロジェクトに最適なチャンキング技術を選択するのに役立ちます。
意味チャンキングの異なる方法の比較
この記事のこの部分では、非構造化テキストの意味チャンキングの人気のある方法を比較します:NLTK Sentence Tokenizer、Langchain Text Splitter、KMeans Clustering、および類似性に基づいた隣接文クラスタリング。
次の例では、PDFから抽出したテキストを使用して、文とそのクラスタを評価します。
使用したデータは、ブラジルのウィキペディアページからエクスポートしたPDFでした。
PDFからテキストを抽出し、NLTKを使用して文に分割するために、次の関数を使用します:
from PyPDF2 import PdfReaderimport nltknltk.download('punkt')# Extracting Text from PDFdef extract_text_from_pdf(file_path): with open(file_path, 'rb') as file: pdf = PdfReader(file) text = " ".join(page.extract_text() for page in pdf.pages) return text# Extract text from the PDF and split it into sentencestext = extract_text_from_pdf(file_path)これにより、長さが210964文字の文字列textが得られます。
以下は、Wikiテキストのサンプルです:
sample = text[1015:3037]print(sample)"""=======Output:=======Brazil is the world's fifth-largest country by area and the seventh most popul ous. Its capitalis Brasília, and its most popul ous city is São Paulo. The federation is composed of the union of the 26states and the Federal District. It is the only country in the Americas to have Portugue se as an officiallangua ge.[11][12] It is one of the most multicultural and ethnically diverse nations, due to over a century ofmass immigration from around t he world,[13] and the most popul ous Roman Catholic-majority country.Bounde d by the Atlantic Ocean on the east, Brazil has a coastline of 7,491 kilometers (4,655 mi).[14] Itborders all other countries and territories in South America except Ecuador and Chile and covers roughl yhalf of the continent's land area.[15] Its Amazon basin includes a vast tropical forest, home to diversewildlife, a variety of ecological systems, and extensive natural resources spanning numerous protectedhabitats.[14] This unique environmental heritage positions Brazil at number one of 17 megadiversecountries, and is the subject of significant global interest, as environmental degradation through processeslike deforestation has direct impacts on gl obal issues like climate change and biodiversity loss.The territory which would become know n as Brazil was inhabited by numerous tribal nations prior to thelanding in 1500 of explorer Pedro Álvares Cabral, who claimed the discovered land for the Portugue seEmpire. Brazil remained a Portugue se colony until 1808 when the capital of the empire was transferredfrom Lisbon to Rio de Janeiro. In 1815, the colony was elevated to the rank of kingdom upon theformation of the United Kingdom of Portugal, Brazil and the Algarves. Independence was achieved in1822 with the creation of the Empire of Brazil, a unitary state gove rned unde r a constitutional monarchyand a parliamentary system. The ratification of the first constitution in 1824 led to the formation of abicameral legislature, now called the National Congress."""NLTK文のトークナイザ
自然言語処理ツールキット(NLTK)は、テキストを文に分割する便利な機能を提供しています。この文のトークナイザは、与えられたテキストブロックを構成要素の文に分割し、さらなる処理に使用することができます。
実装
NLTK文のトークナイザの使用例を以下に示します:
import nltknltk.download('punkt')# テキストを文に分割するdef split_text_into_sentences(text): sentences = nltk.sent_tokenize(text) return sentencessentences = split_text_into_sentences(text)これにより、入力テキストから抽出された2670の文のリストが返されます。各文の平均文字数は78です。
NLTK文のトークナイザの評価
NLTK文のトークナイザは、大量のテキストを個々の文に分割するための直感的かつ効率的な方法ですが、次の制限があります:
- 言語依存性:NLTK文のトークナイザはテキストの言語に強く依存しています。英語では良いパフォーマンスを発揮しますが、他の言語では追加の設定がないと正確な結果が得られない場合があります。
- 省略形と句読点:トークナイザは時々省略形や文末の句読点を誤解することがあります。これにより、文の断片が独立した文として扱われる場合があります。
- 意味理解の欠如:ほとんどのトークナイザと同様に、NLTK文のトークナイザは文間の意味的な関係を考慮しません。そのため、複数の文をまたぐ文脈はトークナイズのプロセスで失われる場合があります。
Spacy文の分割
Spacyという別の強力な自然言語処理ライブラリは、言語のルールに基づいて文を分割する機能を提供しています。これはNLTKと同様のアプローチです。
実装
Spacyの文の分割を実装するのは非常に簡単です。Pythonでの実装方法は次のとおりです:
import spacynlp = spacy.load('en_core_web_sm')doc = nlp(text)sentences = list(doc.sents)これにより、入力テキストから抽出された2336の文のリストが返されます。各文の平均文字数は89です。
Spacy文の分割の評価
Spacyの文の分割は、Langchain文字テキスト分割器と比較して、より小さなチャンクを作成する傾向があります。これは、分析に小さなテキスト単位が必要な場合に有利です。
ただし、NLTKと同様に、Spacyのパフォーマンスは入力テキストの品質に依存します。句読点や構造の整っていないテキストの場合、特定の文の境界が常に正確であるとは限りません。
次に、Langchainがテキストデータの分割のためのフレームワークを提供し、それをNLTKとSpacyと比較します。
Langchain文字テキスト分割器
Langchain文字テキスト分割器は、テキストを特定の文字で再帰的に分割することによって機能します。一般的なテキストに特に有用です。
この分割器は文字のリストで定義されています。生成されたチャンクが所望のサイズ基準を満たすまで、これらの文字に基づいてテキストを分割しようとします。デフォルトのリストは[“\n\n”, “\n”, ” “,”“]であり、段落、文、単語をできるだけまとめて意味的な関連性を保つことを目指しています。
実装
次の例では、この方法を使用してPDFから抽出されたサンプルテキストを分割します。
# カスタムパラメータでテキスト分割器を初期化custom_text_splitter = RecursiveCharacterTextSplitter( # カスタムチャンクサイズを設定 chunk_size = 100, chunk_overlap = 20, # テキストの長さをサイズの基準として使用 length_function = len,)# チャンクを作成texts = custom_text_splitter.create_documents([sample])# 最初の2つのチャンクを表示print(f'### Chunk 1: \n\n{texts[0].page_content}\n\n=====\n')print(f'### Chunk 2: \n\n{texts[1].page_content}\n\n=====')"""=======Output:=======### Chunk 1: Brazil is the world's fifth-largest country by area and the seventh most popul ous. Its capital=====### Chunk 2: is Brasília, and its most popul ous city is São Paulo. The federation is composed of the union of====="""最終的に、textsリストで表されるテキストのチャンクが3205個得られました。ここでは、平均して1つのチャンクあたり65.8文字となります。これはNLTKの平均(79文字)よりも少ないです。
パラメータの変更と’\n’セパレータの使用:
Langchain Splitterをよりカスタマイズしたアプローチにするために、chunk_sizeとchunk_overlapパラメータを必要に応じて変更することができます。さらに、\nのような1つの文字(または文字のセット)だけを区切り文字として指定することもできます。これにより、スプリッターはテキストを改行文字でのみチャンクに分割します。
以下に、chunk_sizeを300、chunk_overlapを30に設定し、セパレータとして\nのみを使用する例を考えてみましょう。
# カスタムパラメータでテキストスプリッターを初期化custom_text_splitter = RecursiveCharacterTextSplitter( # カスタムチャンクサイズを設定 chunk_size = 300, chunk_overlap = 30, # テキストの長さをサイズの指標として使用 length_function = len, # セパレータとして"\n\n"のみを使用 separators = ['\n'])# チャンクを作成custom_texts = custom_text_splitter.create_documents([sample])# 最初の2つのチャンクを表示print(f'### チャンク1: \n\n{custom_texts[0].page_content}\n\n=====\n')print(f'### チャンク2: \n\n{custom_texts[1].page_content}\n\n=====')それでは、標準パラメータとカスタムパラメータのいくつかの出力を比較してみましょう:
# 'Standard Parameters'からのサンプルチャンクを表示print("==== 'Standard Parameters'のサンプルチャンク: ====\n\n")for i, chunk in enumerate(texts): if i < 4: print(f"### チャンク{i+1}: \n{chunk.page_content}\n")print("==== 'Custom Parameters'からのサンプルチャンク: ====\n\n")for i, chunk in enumerate(custom_texts): if i < 4: print(f"### チャンク{i+1}: \n{chunk.page_content}\n")"""=======Output:=========== 'Standard Parameters'のサンプルチャンク: ====### チャンク1: ブラジルは世界で5番目に広い面積を持ち、7番目に人口が多い国です。首都はブラジリアで、最も人口が多い都市はサンパウロです。連邦は26の州と連邦地区の連合で構成されています。ポルトガル語が公用語となっているのはアメリカ大陸では唯一の国です。### チャンク2: カスタムパラメータのサンプルチャンク: ====### チャンク1: ブラジルは世界で5番目に広い面積を持ち、7番目に人口が多い国です。首都はブラジリアで、最も人口が多い都市はサンパウロです。連邦は26の州と連邦地区の連合で構成されています。### チャンク2: アメリカを含む多文化的で民族的に多様な国であり、世界中からの大量の移民があったため、その理由です。カスタムパラメータでは、これらのカスタムパラメータは、デフォルトのパラメータセットよりもはるかに大きなチャンクを生成し、より多くのコンテンツを保持します。これにより、カスタムパラメータではデフォルトのパラメータセットよりもはるかに大きなチャンクが生成され、より多くのコンテンツが保持されることがわかります。
Langchainキャラクターテキストスプリッターの評価
異なるパラメータを使用してテキストをチャンクに分割した後、textsとcustom_textsという2つのチャンクのリストを得ます。それぞれ3205個と1404個のテキストチャンクが含まれています。では、これら2つのシナリオのチャンクの長さの分布をプロットして、パラメータの変更の影響をより良く理解しましょう。

このヒストグラムでは、x軸はチャンクの長さを表し、y軸は各長さの頻度を表しています。青い棒は元のパラメータのチャンクの長さの分布を、オレンジの棒はカスタムパラメータのチャンクの長さの分布を表しています。これら2つの分布を比較することで、パラメータの変化が結果のチャンクの長さにどのような影響を与えたかを確認することができます。
覚えておいてください、理想的な分布はテキスト処理の特定の要件に依存します。細かい解析を行う場合はより小さな、より多くのチャンクが必要な場合がありますし、広範な意味解析を行う場合はより大きな、より少ないチャンクが必要な場合があります。
Langchainキャラクターテキストスプリッター対NLTKとSpacy
先に、Langchainスプリッターをデフォルトのパラメータで使用して3205のチャンクを生成しました。一方、NLTK文トークナイザーは同じテキストを合計2670の文に分割しました。
これらの方法の違いを直感的に理解するために、チャンクの長さの分布を可視化することができます。次のプロットは、各方法のチャンクの長さの密度を示しており、長さがどのように分布しているか、どこに長さが集中しているかを見ることができます。

図1から、Langchainスプリッターはより簡潔なクラスター長の密度を持ち、より長いクラスターが多く存在する傾向があります。一方、NLTKとSpacyはクラスターの長さに関して非常に類似した出力を生成する傾向があります。小さな文を好みながら、長さが最大で1400文字に達する外れ値が多く存在し、長さが減少する傾向があります。
KMeansクラスタリング
文のクラスタリングは、意味的な類似性に基づいて文をグループ化する技術です。文の埋め込みとK-meansなどのクラスタリングアルゴリズムを使用することで、文のクラスタリングを実装することができます。
実装
以下は、Pythonライブラリsentence-transformersを使用して文の埋め込みを生成し、scikit-learnを使用してK-meansクラスタリングを行う簡単な例のコードスニペットです:
from sentence_transformers import SentenceTransformerfrom sklearn.cluster import KMeans# Sentence Transformerモデルをロードmodel = SentenceTransformer('all-MiniLM-L6-v2')# 文のリスト(テキストデータ)を定義sentences = ["This is an example sentence.", "Another sentence goes here.", "..."]# 文の埋め込みを生成embeddings = model.encode(sentences)# 適切なクラスタの数を選択(ここでは例として5を選択)num_clusters = 3# K-meansクラスタリングを実行kmeans = KMeans(n_clusters=num_clusters)clusters = kmeans.fit_predict(embeddings)ここでは、文のリストをクラスタリングするための手順は次の通りです:
- Sentence Transformerモデルをロードします。この場合、HuggingFaceのsentence-transformers/all-MiniLM-L6-v2から
all-MiniLM-L6-v2を使用しています。 - 文を定義し、モデルの
encode()メソッドを使用して埋め込みを生成します。 - 次に、クラスタリング手法とクラスタの数(ここでは3つのクラスタを使用しています)を定義し、データセットに適合させます。
KMeansクラスタリングの評価
最後に、各クラスタのWordCloudをプロットします。
from wordcloud import WordCloudimport matplotlib.pyplot as pltfrom nltk.corpus import stopwordsfrom nltk.tokenize import word_tokenizeimport stringnltk.download('stopwords')# ストップワードのリストを定義stop_words = set(stopwords.words('english'))# 文をクリーニングする関数を定義するdef clean_sentence(sentence): # 文をトークン化する tokens = word_tokenize(sentence) # 小文字に変換する tokens = [w.lower() for w in tokens] # 句読点を削除する table = str.maketrans('', '', string.punctuation) stripped = [w.translate(table) for w in tokens] # アルファベット以外のトークンを削除する words = [word for word in stripped if word.isalpha()] # ストップワードをフィルタリングする words = [w for w in words if not w in stop_words] return words# 各クラスタのWord Cloudを計算してプリントするfor i in range(num_clusters): cluster_sentences = [sentences[j] for j in range(len(sentences)) if clusters[j] == i] cleaned_sentences = [' '.join(clean_sentence(s)) for s in cluster_sentences] text = ' '.join(cleaned_sentences) wordcloud = WordCloud(max_font_size=50, max_words=100, background_color="white").generate(text) plt.figure() plt.imshow(wordcloud, interpolation="bilinear") plt.axis("off") plt.title(f"クラスタ{i}") plt.show()以下は、生成されたクラスターのワードクラウドプロットです:

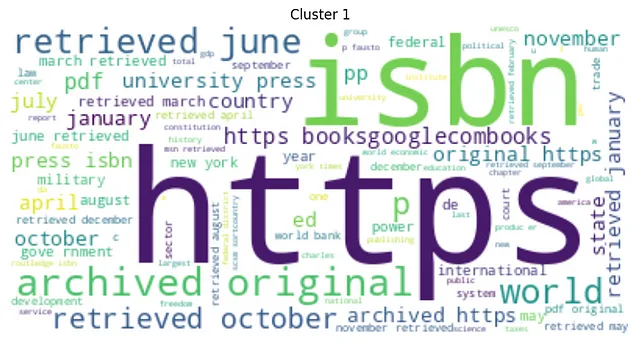

KMeansクラスタリングのワードクラウドの分析では、最も頻出する単語の意味に基づいて、各クラスターが明確に異なることが明らかになりました。これにより、クラスター間の強い意味的な差異が示されます。また、クラスターのサイズには明らかな変動があり、各クラスターが含むシーケンスの数に著しい差異があることを示しています。
KMeansクラスタリングの制約事項
文のクラスタリングには利点がありますが、いくつかの注目すべき制約事項もあります。主な制約事項は次のとおりです:
- 文の順序の喪失:文のクラスタリングは、ナラティブの自然な流れを歪める可能性がある、元の文の順序を保持しません。 **これは非常に重要です**
- 計算効率:KMeansは、特に大きなテキストコーパスやクラスターの数が多い場合には計算量が多く、遅くなる場合があります。これは、リアルタイムアプリケーションやビッグデータの処理にとって重要な制約事項となります。
隣接する文のクラスタリング
KMeansクラスタリングの制約事項、特に文の順序の喪失を克服するために、意味的類似性に基づいて隣接する文をクラスタリングする別のアプローチが考えられます。このアプローチの基本的な前提は、テキスト内で連続して現れる2つの文は、それよりも遠くにある2つの文よりも意味的に関連している可能性が高いということです。
実装
以下は、Spacyの文を入力として使用したこのヒューリスティックの拡張実装です:
import numpy as npimport spacy# Spacyモデルのロードnlp = spacy.load('en_core_web_sm')def process(text): doc = nlp(text) sents = list(doc.sents) vecs = np.stack([sent.vector / sent.vector_norm for sent in sents]) return sents, vecsdef cluster_text(sents, vecs, threshold): clusters = [[0]] for i in range(1, len(sents)): if np.dot(vecs[i], vecs[i-1]) < threshold: clusters.append([]) clusters[-1].append(i) return clustersdef clean_text(text): # テキストのクリーニングプロセスを追加してください return text# クラスターの長さリストと最終的なテキストリストの初期化clusters_lens = []final_texts = []# チャンクの処理threshold = 0.3sents, vecs = process(text)# 文をクラスタリングするclusters = cluster_text(sents, vecs, threshold)for cluster in clusters: cluster_txt = clean_text(' '.join([sents[i].text for i in cluster])) cluster_len = len(cluster_txt) # クラスターが短すぎるかどうかをチェック if cluster_len < 60: continue # クラスターが長すぎるかどうかをチェック elif cluster_len > 3000: threshold = 0.6 sents_div, vecs_div = process(cluster_txt) reclusters = cluster_text(sents_div, vecs_div, threshold) for subcluster in reclusters: div_txt = clean_text(' '.join([sents_div[i].text for i in subcluster])) div_len = len(div_txt) if div_len < 60 or div_len > 3000: continue clusters_lens.append(div_len) final_texts.append(div_txt) else: clusters_lens.append(cluster_len) final_texts.append(cluster_txt)このコードの主なポイントは次のとおりです:
- テキスト処理:各テキストチャンクは
process関数に渡されます。この関数はSpaCyライブラリを使用して文の埋め込みを作成し、テキストチャンク内の各文の意味的な意味を表すために使用されます。 - クラスタ作成:
cluster_text関数は、埋め込みのコサイン類似度に基づいて文のクラスタを形成します。コサイン類似度が指定された閾値よりも小さい場合、新しいクラスタが開始されます。 - 長さのチェック:その後、コードは各クラスタの長さをチェックします。クラスタが短すぎる(60文字未満)または長すぎる(3000文字以上)場合、閾値が調整され、その特定のクラスタに対してプロセスが繰り返され、受け入れ可能な長さが達成されます。
このアプローチからのいくつかの出力チャンクを見て、Langchain Splitterと比較してみましょう:
==== 'Langchain Splitter with Custom Parameters'からのサンプルチャンク: ====### チャンク 1:ブラジルは面積で世界第5位、人口で世界第7位の国です。首都はブラジリアで、最も人口の多い都市はサンパウロです。26の州と連邦地区の連合で構成されています### チャンク 2:。ポルトガル語を公用語としている唯一のアメリカ諸国です。100年以上にわたり、多文化と多様な民族構成を持つ国の一つです。==== 'Adjacent Sentences Clustering'からのサンプルチャンク: ====### チャンク 1:ブラジルは面積で世界第5位、人口で世界第7位の国です。首都はブラジリアで、最も人口の多い都市はサンパウロです。### チャンク 2:連邦地区の26州と連邦地区の連合で構成されています。ポルトガル語を公用語としている唯一のアメリカ諸国です。それでは、final_texts(隣接シーケンスクラスタリングアプローチからのもの)のチャンクの長さの分布を、Langchain Character Text SplitterとNLTK Sentence Tokenizerの分布と比較してみましょう。これを行うには、まずfinal_texts内のチャンクの長さを計算する必要があります:
final_texts_lengths = [len(chunk) for chunk in final_texts]これで、3つのメソッドの分布をプロットすることができます:
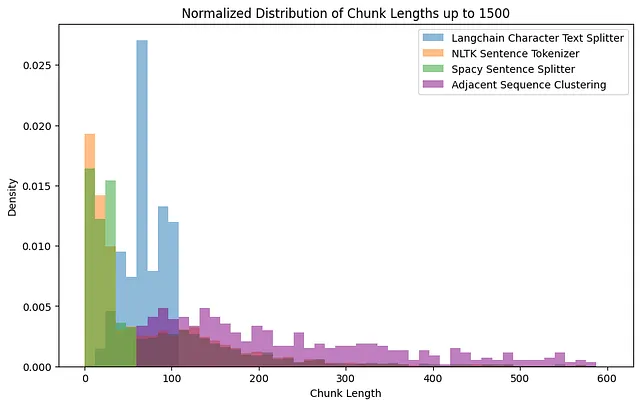
図6から、Langchain Splitterは事前定義されたチャンクサイズを使用して一様な分布を作成し、一貫したチャンクの長さを示していることがわかります。
一方、Spacy Sentence SplitterとNLTK Sentence Tokenizerは、より小さい文を好む傾向がありますが、多くの大きな外れ値があり、分割を決定するために言語的な手がかりに依存しており、不規則なサイズのチャンクを生成する可能性があります。
最後に、隣接シーケンスクラスタリングアプローチは、意味的な類似性に基づいてクラスタリングするため、より多様な分布を示しています。これは、コンテンツの一貫性を維持しながら、サイズの柔軟性を許すより文脈に敏感なアプローチを示唆しているかもしれません。
隣接シーケンスクラスタリングアプローチの評価
隣接シーケンスクラスタリングアプローチには、次のようなユニークな利点があります:
- 文脈的一貫性:意味的および文脈的な一貫性を考慮して、テーマに一貫したチャンクを生成します。
- 柔軟性:コンテキストの保存と計算効率をバランスさせ、調整可能なチャンクサイズを提供します。
- 閾値の調整:類似性の閾値を調整することで、チャンキングプロセスを必要に応じて微調整できます。
- シーケンスの保存:テキスト内の文の元の順序を保持し、シーケンシャル言語モデルやテキストの順序が重要なタスクに必要です。
テキストチャンキングの方法の比較:洞察の概要
Langchain Character Text Splitter
このメソッドは、統一的なチャンク長を提供し、均等な分布を生み出します。これは、下流処理や分析に標準サイズが必要な場合に有益です。このアプローチは、テキストの特定の言語構造に対してはあまり敏感ではなく、あらかじめ定義された文字数のチャンクを生成することに重点を置いています。
NLTK文トークナイザとSpacy文分割器
これらのアプローチは、より小さな文に対して好ましい傾向がありますが、多くの大きな外れ値も含まれています。これにより、文法的に連続性のあるチャンクが生成されることがありますが、チャンクのサイズの高い可変性も生じる可能性があります。
これらの方法は、下流のタスクへの入力としても良い結果を生み出すことがあります。
隣接シーケンスのクラスタリング
このメソッドは、より多様な分布を生成し、コンテキストに敏感なアプローチを示しています。意味的類似性に基づいてクラスタリングすることで、各チャンク内の内容が一貫性を持ちつつ、チャンクのサイズに柔軟性を持たせることができます。この方法は、テキストデータの意味的な連続性を保持することが重要な場合に有利です。
より視覚的で抽象的(または愚かな)表現をするために、以下の図7を見て、どのようなパイナップルの「切り方」が議論されたアプローチをよりよく表現できるか考えてみましょう:
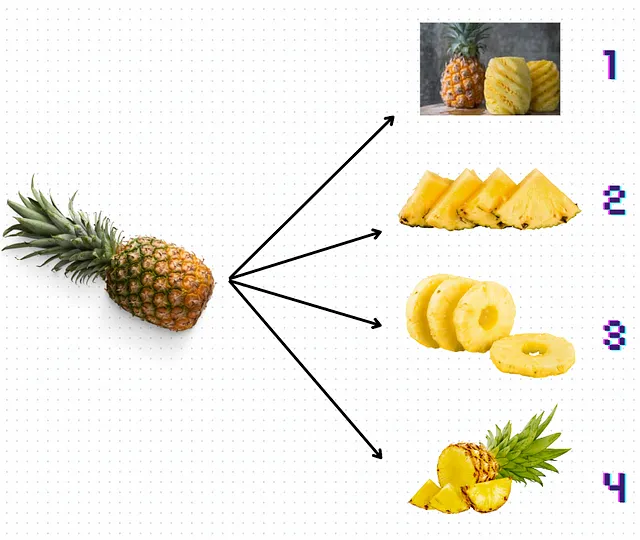
それらを順番にリストアップします:
- カットナンバー1はルールベースのアプローチを表しており、フィルターや正規表現に基づいて必要な「ジャンク」テキストを単に「剥がす」ことができます。ただし、パイナップル全体を処理するためには多くの作業が必要であり、より大きなコンテキストサイズの外れ値も保持します。
- Langchainはカットナンバー2のようなものです。サイズは非常に似ていますが、完全な望ましいコンテキストを持っていません(三角形なのでスイカにもなり得ます)。
- カットナンバー3は明らかにKMeansです。意味のある部分だけをグループ化することもできますが、そのコアを得ることはできません。コアがないと、チャンクはすべての構造と意味を失います。特に大きなパイナップルの場合、それを行うのは多くの作業が必要です。
- 最後に、カットナンバー4は隣接文のクラスタリングメソッドを示しています。チャンクのサイズは変動する場合がありますが、果物の全体的な構造を示す不均一なパイナップルのように、しばしば文脈情報を保持しています。
要約:この記事では、3つのテキストのチャンキングメソッドとそれらの独自の利点を比較しました。Langchainは一貫したチャンクサイズを提供しますが、言語構造は後回しにされます。NLTKとSpacyは文法的に連続性のあるチャンクを提供しますが、サイズはかなり変動します。隣接シーケンスのクラスタリングは、柔軟なチャンクサイズとともに内容の一貫性を提供する意味的類似性に基づくクラスタリングを行います。最終的な選択は、言語的な一貫性、チャンクサイズの均一性、および利用可能な計算能力など、特定のニーズに依存します。
お読みいただきありがとうございます!
- Linkedinで私に従ってください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
