テキストの生成方法:トランスフォーマーを使用した言語生成のための異なるデコーディング方法の使用方法
テキストの生成方法の異なるデコーディング方法の使用
![]()
はじめに
近年、大規模なトランスフォーマーベースの言語モデル(例えば、OpenAIの有名なGPT2モデル)が数百万のウェブページを学習することで、オープンエンドの言語生成に対する関心が高まっています。条件付きのオープンエンドの言語生成の結果は印象的です。例えば、ユニコーンに関するGPT2、XLNet、CTRLでの制御言語生成などです。改良されたトランスフォーマーアーキテクチャや大量の非教示学習データに加えて、より良いデコーディング手法も重要な役割を果たしています。
このブログ記事では、異なるデコーディング戦略の概要と、さらに重要なことに、人気のあるtransformersライブラリを使ってそれらを簡単に実装する方法を紹介します!
以下のすべての機能は、自己回帰言語生成に使用することができます(ここでは復習です)。要するに、自己回帰言語生成は、単語のシーケンスの確率分布を条件付き次の単語の分布の積として分解できるという仮定に基づいています:
- 「The Reformer – 言語モデリングの限界を押し上げる」
- より小さく、より速い言語モデルのためのブロック疎行列
- エンコーダー・デコーダーモデルのための事前学習済み言語モデルチェックポイントの活用
P(w1:T∣W0)=∏t=1TP(wt∣w1:t−1,W0) ,with w1:0=∅, P(w_{1:T} | W_0 ) = \prod_{t=1}^T P(w_{t} | w_{1: t-1}, W_0) \text{ ,with } w_{1: 0} = \emptyset, P(w1:T∣W0)=t=1∏TP(wt∣w1:t−1,W0) ,with w1:0=∅,
ここで、W0W_0W0は初期のコンテキスト単語シーケンスを表します。単語シーケンスの長さTTTは通常、タイムステップt=Tt=Tt=TでEOSトークンがP(wt∣w1:t−1,W0)P(w_{t} | w_{1: t-1}, W_{0})P(wt∣w1:t−1,W0)から生成される時に決定されます。
自己回帰言語生成は、PyTorchとTensorflow >= 2.0の両方でGPT2、XLNet、OpenAi-GPT、CTRL、TransfoXL、XLM、Bart、T5で利用できます!
現在最も主要なデコーディング手法、主にGreedy Search、Beam Search、Top-K Sampling、Top-p Samplingのツアーをご紹介します。
さあ、transformersをインストールしてモデルをロードしましょう。ここではデモンストレーションのためにTensorflow 2.1でGPT2を使用しますが、APIはPyTorchと1対1の同じです。
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q tensorflow==2.1
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id)グリーディーサーチ
グリーディーサーチは、最も高い確率を持つ単語を次の単語として選択します:wt=argmaxwP(w∣w1:t−1)w_t = argmax_{w}P(w | w_{1:t-1})wt=argmaxwP(w∣w1:t−1) の各タイムステップtttで。次のスケッチは、グリーディーサーチを示しています。

「The」という単語から始まり、アルゴリズムは次の確率が最も高い「nice」、次に「woman」などを貪欲に選択し、最終的に生成される単語のシーケンスは(「The」「nice」「woman」)で、全体的な確率は0.5×0.4=0.20.5 \times 0.4 = 0.20.5×0.4=0.2です。
以下では、GPT2を使用して単語のシーケンスを生成します。コンテキストは(「私」、「楽しむ」、「散歩」、「と」、「私の」、「かわいい」、「犬」)です。transformersで貪欲検索がどのように使用されるかを見てみましょう:
# コンテキストをエンコード
input_ids = tokenizer.encode('私はかわいい犬と散歩を楽しむ', return_tensors='tf')
# 出力の長さが50になるまでテキストを生成
greedy_output = model.generate(input_ids, max_length=50)
print("出力:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))よし!GPT2で最初の短いテキストを生成しました 😊。コンテキストに続く生成された単語は妥当ですが、モデルはすぐに繰り返しを始めます!これは一般的な言語生成の非常に一般的な問題であり、特に貪欲検索とビーム検索ではさらに顕著です。詳細はVijayakumar et al.、2016およびShao et al.、2017を参照してください。
ただし、貪欲検索の主な欠点は、低確率の単語の後ろに隠れた高確率の単語を見逃すことです。上記の例では、高い条件付き確率0.9の単語「has」が、2番目に高い条件付き確率しか持たない単語「dog」の後ろに隠れているため、貪欲検索では単語のシーケンス「The」「dog」「has」を見逃してしまいます。
幸いなことに、この問題を緩和するためにビーム検索があります!
ビーム検索
ビーム検索は、各時間ステップで最も可能性の高いnum_beams個の仮説を保持し、最終的に全体的に最も確率の高い仮説を選択することで、隠れた高確率の単語シーケンスを見逃すリスクを減らします。例としてnum_beams=2を使用して説明しましょう:

時間ステップ1では、最も可能性の高い仮説(「The」「nice」)に加えて、ビーム検索は2番目に可能性の高い仮説(「The」「dog」)も追跡します。時間ステップ2では、ビーム検索は単語シーケンス(「The」「dog」「has」)の確率が0.36で最も高いことを見つけます。これは、確率が0.20の単語シーケンス(「The」「nice」「woman」)よりも高い確率です。素晴らしい、おもちゃの例では最も可能性の高い単語シーケンスが見つかりました!
ビーム検索は常に貪欲検索よりも確率の高い出力シーケンスを見つけますが、最も可能性の高い出力を見つけることは保証されません。
transformersでビーム検索を使用する方法を見てみましょう。 num_beams > 1 および early_stopping=True を設定して、すべてのビーム仮説がEOSトークンに到達したときに生成が終了するようにします。
# ビーム検索とearly_stoppingを有効化
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
early_stopping=True
)
print("出力:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))結果はおそらくより流暢ですが、出力にはまだ同じ単語のシーケンスの繰り返しが含まれています。Paulus et al. (2017)およびKlein et al. (2017)によって導入されたn-gram(またはn単語のシーケンス)ペナルティを導入することで、この問題を解決することができます。最も一般的なn-gramペナルティは、すでに存在するn-gramを作成できる次の単語の確率を手動で0に設定することによって、重複するn-gramが表示されないようにします。
例としてno_repeat_ngram_size=2を設定して、2-gramが二度現れないようにしてみましょう:
# no_repeat_ngram_sizeを2に設定する
beam_output = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("出力:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))素晴らしい、これはずっと良く見えます!繰り返しがもう現れないことが分かります。ただし、n-gramペナルティは注意して使用する必要があります。ニューヨークの都市に関する記事を生成する場合、2-gramペナルティを使用してはいけません。そうでないと、その都市の名前がテキスト全体で1回しか現れないことになります!
ビームサーチのもう一つの重要な特徴は、生成後にトップのビームを比較し、目的に最も適した生成ビームを選択できることです。
transformersでは、パラメータnum_return_sequencesを最高スコアのビームの数に設定するだけです。ただし、num_return_sequences <= num_beamsであることを確認してください!
# return_num_sequencesを1より大きく設定する
beam_outputs = model.generate(
input_ids,
max_length=50,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
# 現在、3つの出力シーケンスがあります
print("出力:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))わかるように、5つのビームの仮説はお互いにほとんど変わりません – これは5つのビームしか使用していない場合にはあまり驚くべきことではありません。
オープンエンドの生成では、ビームサーチが最適なオプションではない理由がいくつか最近提案されています:
-
ビームサーチは、機械翻訳や要約など、望ましい生成の長さがある程度予測可能なタスクで非常にうまく機能することがあります – Murray et al. (2018)やYang et al. (2018)を参照してください。ただし、対話やストーリーの生成など、望ましい出力の長さが大きく異なる場合にはその限りではありません。
-
ビームサーチは、繰り返しの生成に非常に苦しんでいることが分かりました。これは特にストーリーの生成においてn-gramなどのペナルティを制御するのが難しいです。なぜなら、強制的な「繰り返し禁止」と同一のn-gramのサイクルの間での良いトレードオフを見つけるには、多くの微調整が必要だからです。
-
Ari Holtzman et al. (2019)の議論によると、高品質な人間の言語は高確率の次の単語の分布に従いません。言い換えると、私たち人間は生成されたテキストに驚きを感じたいのです。著者たちは、モデルが人間のテキストに与える確率とビームサーチが行うことを素晴らしく示しています。
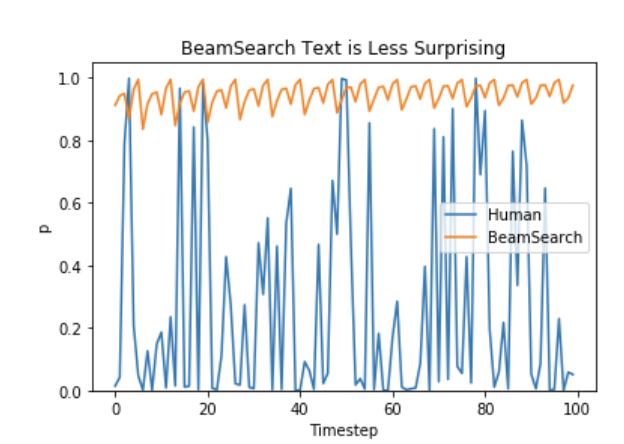
では、退屈ではなく、いくつかのランダム性を導入しましょう 🤪。
サンプリング
基本的な形では、サンプリングとは、次の単語を条件付き確率分布に基づいてランダムに選ぶことを意味します:
wt∼P(w∣w1:t−1) w_t \sim P(w|w_{1:t-1}) wt∼P(w∣w1:t−1)
上記の例を使って、以下のグラフィックはサンプリングを使用した言語生成を視覚化しています。

明らかになるのは、サンプリングを使用した言語生成は決定論的ではないということです。単語(“car”)(“car”)(“car”)は条件付き確率分布P(w∣”The”)P(w | \text{“The”})P(w∣”The”)からサンプリングされ、次に(“drives”)(“drives”)(“drives”)がP(w∣”The”,”car”)P(w | \text{“The”}, \text{“car”})P(w∣”The”,”car”)からサンプリングされます。
transformersでは、do_sample=Trueとし、Top-Kサンプリングを無効にするためにtop_k=0を設定します。以下では、説明のためにrandom_seed=0を固定しています。モデルを試すためにrandom_seedを変更しても構いません。
# シードを設定して結果を再現できるようにします。異なる結果を得るためには、シードを変更しても構いません
tf.random.set_seed(0)
# top_kサンプリングを無効化し、top_kの値を0に設定することでサンプリングを有効化します
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0
)
print("出力:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))興味深いですね!テキストはまあまあですが、よく見ると非常に一貫性がありません。3-gramの”new hand sense”や”local batte harness”は非常に奇妙で、人間が書いたものではないように聞こえません。これは、単語のシーケンスをサンプリングする際に大きな問題です。モデルはしばしば一貫性のないゴミを生成します。詳しくは、Ari Holtzman et al. (2019)を参照してください。
ソフトマックスの温度を下げることで、分布P(w∣w1:t−1)P(w|w_{1:t-1})P(w∣w1:t−1)をよりシャープにする(高確率の単語の出現確率を高め、低確率の単語の出現確率を低下させる)トリックがあります。
上記の例に温度を適用したイラストは次のようになります。

ステップt=1の条件付き次単語分布は、温度を下げることで非常にシャープになり、単語”car”の選択確率がほとんどなくなります。
ライブラリで分布を緩める方法を見てみましょう。温度を0.7に設定することで、分布を緩めることができます。
# シードを設定して結果を再現できるようにします。異なる結果を得るためには、シードを変更しても構いません
tf.random.set_seed(0)
# 低確率の候補に対する感度を減らすために温度を使用します
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=0,
temperature=0.7
)
print("出力:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))なかなか良いですね!テキストは以前よりも少し一貫性があります。ただし、温度を適用することで分布がよりランダムになる可能性があります。温度を限りなく0に近づけると、温度スケーリングされたサンプリングは貪欲なデコーディングと同じ問題に直面することになります。
Top-Kサンプリング
Fan et. al (2018)は、Top-Kサンプリングというシンプルで非常に強力なサンプリング手法を紹介しました。Top-Kサンプリングでは、K個の次の単語のうち最も確率が高いものが選ばれ、確率の割合がそれらのK個の単語に再分配されます。GPT2はこのサンプリング手法を採用し、ストーリー生成の成功の一因となりました。
上記の例で使用されるサンプリングステップの単語範囲を3単語から10単語に拡張して、Top-Kサンプリングをよりよく説明します。

K=6と設定した場合、両方のサンプリングステップでサンプリングプールを6単語に制限します。最も確率が高い6単語(Vtop-K)は、最初のステップでは全体の確率の約2/3をカバーしますが、2番目のステップではほぼ全ての確率をカバーします。しかし、2番目のサンプリングステップでは、”not”、”the”、”small”、”told”といった非常に奇妙な候補が正常に排除されていることがわかります。
ライブラリでTop-Kを使用する方法を見てみましょう。top_k=50に設定することで、Top-Kサンプリングを行うことができます。
# シードを設定して結果を再現できるようにします。異なる結果を得るためには、シードを変更しても構いません
tf.random.set_seed(0)
# top_kを50に設定します
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50
)
print("出力:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))なかなか良いですね!テキストはこれまでで一番人間らしく聞こえます。ただし、Top-Kサンプリングの問題点として、次の単語の確率分布P(w∣w1:t−1)P(w|w_{1:t-1})P(w∣w1:t−1)からフィルタリングされる単語の数を動的に適応しないという点があります。これは、一部の単語が非常にシャープな分布(グラフの右側の分布)からサンプリングされる一方で、他の単語はよりフラットな分布(グラフの左側の分布)からサンプリングされる可能性があるため、問題が発生する可能性があります。
ステップt=1では、Top-Kは(“people”,”big”,”house”,”cat”)のような妥当な候補をサンプルする可能性を排除します。一方、ステップt=2では、この方法はサンプル単語プールに不適切な単語(“down”,”a”)を含みます。したがって、サンプルプールを固定サイズKに制限すると、シャープな分布では意味不明な出力を生成する可能性があり、フラットな分布ではモデルの創造性が制限される可能性があります。この直感により、Ari HoltzmanらはTop-pサンプリングまたはnucleusサンプリングを作成しました。
Top-p(ヌクレウス)サンプリング
Top-pサンプリングでは、最も確率の高いK単語だけでなく、累積確率がpを超える可能性がある最小の単語セットから選択します。その後、この単語セットに確率の質量が再分配されます。これにより、単語セットのサイズ(または単語の数)が次の単語の確率分布に応じて動的に増減することができます。これは非常に冗長な説明でしたので、可視化しましょう。

p=0.92と設定した場合、Top-pサンプリングは確率質量の92%を超えるために最小数の単語を選び出します。最初の例では、最も確率の高い9つの単語が含まれていますが、2番目の例では92%を超えるためにトップ3の単語だけを選び出す必要があります。非常にシンプルですね!次の単語が予測しにくいと思われる場合は、幅広い単語が保持され、例えばP(w∣”The”)のような場合、次の単語がより予測しやすい場合は、ごくわずかな単語だけが保持されます、例えばP(w∣”The”,”car”)のような場合です。
それでは、transformersで確認しましょう!top_p < 1と設定することで、Top-pサンプリングをアクティブにします:
# 結果を再現するためにシードを設定します。結果を変えるためにシードを変更しても構いません
tf.random.set_seed(0)
# top_kサンプリングを無効にし、最も確率の高い単語のみを92%からサンプリングします
sample_output = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_p=0.92,
top_k=0
)
print("出力:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
出力:
----------------------------------------------------------------------------------------------------
私はかわいい犬と散歩するのが好きです。彼は決して同じになりません。彼の遊びを見ています。
みんな、私の犬には名前が必要です。特に彼が羽根を持って見つかった場合は。
それは何だったの?私はたくさんの素晴らしい、それは人間によって書かれたかのようですね。まだ完璧ではないかもしれませんが。
理論的には、Top-pはTop-Kよりも優れているように思えますが、実際には両方の方法がうまく機能します。Top-pはTop-Kと組み合わせて使用することもできます。これにより、非常に低い順位の単語は避けつつ、いくつかの動的な選択が可能となります。
最後に、複数の独立したサンプル出力を取得するには、再びnum_return_sequences > 1というパラメータを設定できます:
# 結果を再現するためにシードを設定します。結果を変えるためにシードを変更しても構いません
tf.random.set_seed(0)
# top_k = 50、top_p = 0.95、num_return_sequences = 3と設定します
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("出力:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
出力:
----------------------------------------------------------------------------------------------------
0: 私はかわいい犬と散歩するのが好きです。犬と一緒に散歩する機会を持てることはとても良いことです。しかし、犬に関する問題があります。彼はいつも私たちを見ており、私が何かをすることができると私に見せようとしています
1: 私はかわいい犬と散歩するのが好きです。彼女は惑星のさまざまな場所に旅行するのが大好きで、砂漠でも!私たちの愛しい子犬と一緒にバスで旅行するには世界は十分に広くはありませんが、私はそこで私の愛を見つけます
2: 私はかわいい犬と散歩し、子供たちと遊ぶのが好きです」と米国のヒューマン・ソサエティのディレクター、デビッド・J・スミスは語った。
「そのため、私はより多くの仕事を持っています」と彼は言いました。クール、これでモデルに物語を書かせるためのすべてのツールを持っているはずです。transformersを使用しています!
結論
アドホックなデコーディング方法として、top-pサンプリングとtop-Kサンプリングは、オープンエンドの言語生成において従来の貪欲法やビームサーチよりも流暢なテキストを生成するように思われます。最近、モデルの問題(特にモデルの訓練方法)によるものであるという証拠が増えてきました。具体的には、greedyとbeam searchによって生成される単語の繰り返しという問題は、Welleck et al.(2019)によって示されています。また、Welleck et al.(2020)で示されているように、top-Kサンプリングとtop-pサンプリングも単語の繰り返しを生成するという問題があります。
Welleck et al.(2019)では、人間の評価によると、モデルのトレーニング目標を適応させると、ビームサーチはTop-pサンプリングよりもより流暢なテキストを生成できることが示されています。
オープンエンドの言語生成は、急速に進化している研究分野であり、一つの方法がすべてに適しているわけではないため、特定のユースケースで最適な方法を見つける必要があります。
良いことに、transformersでさまざまなデコーディング方法を試すことができます🤗。
これはtransformersで異なるデコーディング方法を使用する方法と、オープンエンドの言語生成の最近のトレンドについての短い紹介でした。
フィードバックや質問は、Githubリポジトリで非常に歓迎されます。
もっと楽しく物語を生成するために、Writing with Transformersをご覧ください。
このブログ記事に貢献してくれたすべての方々に感謝します:Alexander Rush、Julien Chaumand、Thomas Wolf、Victor Sanh、Sam Shleifer、Clément Delangue、Yacine Jernite、Oliver Åstrand、John de Wasseige。
付録
generateメソッドには、上記で説明されていないいくつかの追加パラメータがあります。ここで簡単に説明します!
-
min_lengthは、min_lengthに達する前にEOSトークン(=文を終了させない)を生成しないようにモデルに強制するために使用できます。これは要約でよく使用されますが、ユーザーがより長い出力を望む場合にも一般的に役立ちます。 -
repetition_penaltyは、すでに生成された単語やコンテキストに属する単語をペナルティとするために使用できます。これは最初にKeskar et al.(2019)によって導入され、Welleck et al.(2019)のトレーニング目標でも使用されています。繰り返しを防ぐのに非常に効果的ですが、異なるモデルとユースケースに非常に敏感であり、Githubのこの議論を参照してください。 -
attention_maskは、パディングされたトークンをマスクするために使用できます。 -
pad_token_id、bos_token_id、eos_token_id:モデルにこれらのトークンがデフォルトでない場合、ユーザーは他のトークンIDを手動で選択することができます。
詳細については、generate関数のドキュメント文字列も参照してください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






