テキストのポテンシャルを引き出す:プリエンベッドテキストクリーニング方法の詳細な調査
テキストのポテンシャルを引き出す' means 'Unlocking the potential of text'. 'プリエンベッドテキストクリーニング方法の詳細な調査' means 'Detailed investigation of pre-embedded text cleaning methods'. So, the condensed version would be 'Unlocking the potential of text Detailed investigation of pre-embedded text cleaning methods
この記事では、テキストデータから最大のパフォーマンスを引き出すために必要な異なるクリーニング技術について説明します。
テキストクリーニングの方法をデモンストレーションするために、Kaggleの「metamorphosis」というテキストデータセットを使用します。
まず、クリーニングプロセスに必要なPythonライブラリをインポートしましょう。
import nltk, re, stringfrom nltk.corpus import stopwordsfrom nltk.stem.porter import PorterStemmer次に、データセットを読み込みましょう。
file_directory = 'データセットのローカルディレクトリへのリンク'file = open(file_directory, 'rt', encoding='utf-8')text = file.read()file.close()上記のコードセルが動作するためには、データファイルのローカルディレクトリパスを指定する必要があります。
- 「生データから洗練されたデータへ:データの前処理を通じた旅 – パート1」
- 「ソフトウェア開発におけるAIの活用:ソリューション戦略と実装」
- 「Med-PaLM Multimodal(Med-PaLM M)をご紹介します:柔軟にエンコードし、解釈するバイオメディカルデータの大規模なマルチモーダル生成モデル」
テキストデータを単語ごとに分割します。
words = text.split()print(words[:120])
ここでは、句読点が保持されていること(例:armor-likeやwasn’t)がわかります。また、文末の句読点も最後の単語と一緒に保持されていること(例:thought.)がわかりますが、これは望ましくありません。
そこで、今度は非単語の文字を使用してデータを分割してみましょう。
words = re.split(r'\W+', text)print(words[:120])
ここでは、「thought.」のような単語が「thought」に変換されていることがわかります。ただし、「wasn’t」のような単語が「wasn」と「t」に変換されてしまっている問題があります。修正する必要があります。
Pythonでは、string.punctuationを使用して一度に複数の句読点を取得できます。これを使用してテキストから句読点を削除します。
print(string.punctuation)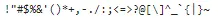
したがって、単語ごとに分割し、データに記録されているすべての句読点を削除します。
words = text.split()re_punc = re.compile('[%s]' % re.escape(string.punctuation))stripped = [re_punc.sub('', word) for word in words]print(stripped[:120])
ここでは、「thought.」のような単語がなくなったことがわかりますが、「wasn’t」のような単語は正しく残っています。
テキストには印刷できない文字も含まれることがあります。これらもフィルタリングする必要があります。これには、Pythonの「string.printable」を使用できます。これは印刷可能な文字のリストを提供します。したがって、このリストに存在しない文字を削除します。
re_print = re.compile('[^%s]' % re.escape(string.printable))result = [re_print.sub('', word) for word in stripped]print(result[:120])
さて、すべての単語を小文字にします。これにより、ボキャブラリーが減ります。ただし、いくつかの欠点もあります。これを行うと、企業名としての「Apple」と果物としての「apple」などの2つの単語が同じエンティティと見なされます。
result = [word.lower() for word in result]
print(result[:120])

また、1文字の単語はほとんどのNLPタスクに貢献しないため、それらも削除します。
result = [word for word in result if len(word) > 1]
print(result[:120])

NLPでは、「is」「as」「the」のような頻出単語はモデルの学習にあまり貢献しないため、これらの単語はストップワードとして知られ、テキストクリーニングのプロセスで削除することが推奨されています。
import nltk
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
print(stop_words)

result = [word for word in result if word not in set(stop_words)]
print(words[:110])

ここで、同じ意味を持つ単語を単一の単語に減らします。たとえば、「run」「running」「runs」の単語は、トレーニング中のモデルに対して同じ意味を与えるため、「run」という単語にのみ減らします。これは、nltkライブラリのPorterStemmerクラスを使用して実行できます。
from nltk.stem.porter import PorterStemmer
ps = PorterStemmer()
result = [ps.stem(word) for word in result]
print(words[:110])

ステミングされた単語には意味があるかもしれません。単語に意味を持たせたい場合は、ステミング技術ではなく、単語が変換後も意味を持つことを保証するレンマ形成技術を使用できます。
次に、アルファベットだけで作られていない単語を削除しましょう
result = [word for word in result if word.isalpha()]
print(result[:110])

この段階では、テキストデータは単語埋め込み技術に使用するには十分なものに見えます。ただし、特定の種類のデータ(たとえば、HTMLコード)には、このプロセスに追加のステップが必要な場合があることに注意してください。
この記事がお役に立てれば幸いです。記事についてのご意見がありましたら、お知らせください。建設的なフィードバックは大いに歓迎します。
LinkedInでご連絡ください。
メールアドレス:[email protected]
素晴らしい一日をお過ごしください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「BI-LSTMを用いた次の単語予測のマスタリング:包括的なガイド」
- 「研究論文メタデータの簡単な説明」
- 「Scikit-Learnクラスを使用したカスタムトランスフォーマを作成するためのシンプルなアプローチ」
- 「多数から少数へ:機械学習における次元削減による高次元データの取り扱い」
- 「MITとスタンフォードの研究者は、効率的にロボットを制御するために機械学習の技術を開発しましたこれにより、より少ないデータでより良いパフォーマンスが得られるようになります」
- 「LG AI Researchが提案するQASA:新しいAIベンチマークデータセットと計算アプローチ」
- 「カルロス・アルカラス vs. ビッグ3」
