テキストから類義語(似た言葉)を抽出する方法:BERTとNMSLIBの活用🔥
テキストから類義語を抽出する方法:BERTとNMSLIBの活用🔥
BERT&NMSLIBを使用して複数のテキスト行内の類似/同義語を抽出するアプローチ

単語ごとにテキストをトークナイズして、単語単位の出力を行います。次に、BERT(文の変換器)を使用して最も一般的な単語を埋め込み、NMBLIBを使用してそれぞれに最も近いマッチを取得します。Twitterからのツイートデータセットを使用して、それら内で類似する単語を見つけます。
注意 – この記事では、データセット全体から類似する単語/同義語を探しています。したがって、すべての行を取り、名詞である最も一般的な単語を抽出し、それらをまとめて処理します。行の概念はありません。また、結果の単語は必ずしも完全に置き換え可能な同義語ではなく、単に似たような単語である場合があります。例えば、「excellence」と「quality」、「soundcloud」と「spotify」のようなものが得られます。
ツイートのクリーニング
まず、データをクリーニングします。ストップワードと数字を削除し、テキストを小文字にします。

- 「Nvidia Triton Inference Serverを使用してPyTorchモデルをデプロイする」
- 「NLPモデルの正規化に関するクイックガイド」
- 「Plotly Graph Objectsを使用してウォーターフォールチャートを作成する方法」
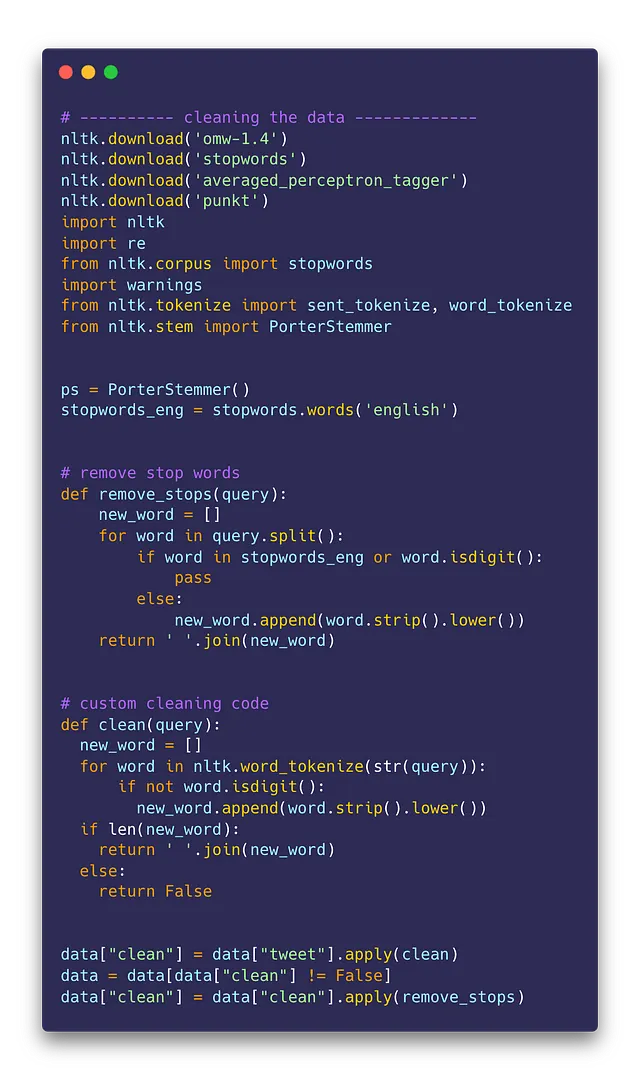
すべてのツイートからの単語リストの作成
各ツイートをクリーニングした後、各ツイートを単語にトークナイズし、リストを作成します。
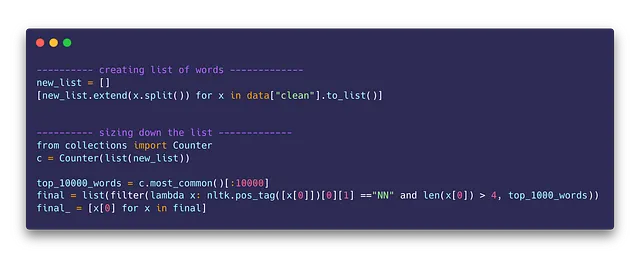
単語リストの縮小
多くの単語を扱う必要があるため、すべての単語に対して類似する単語を見つけることは意味がありません。そのため、最も頻出の単語(上位10,000)を取り、それらから名詞のみをさらにフィルタリングしました。
単語埋め込みの作成
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





