ゼロからdbtモデルを設計する方法
ゼロからdbtモデルを設計する方法' can be condensed to 'dbtモデルの設計方法'.
実際に使用されるdbtモデルを構築するためのシンプルなフレームワーク。
Ultimate Guide to dbtを調査していたとき、ゼロからモデルを構築するための資料が少ないことに驚きました。具体的な手順ではなく、ツールでの取り組み方は数え切れないほどのブログやチュートリアルでカバーされています。正しい設計方法はどうやって知るのでしょうか?ステークホルダーがそのモデルを実際に使用することを確認するにはどうすればいいのでしょうか?信頼され、理解されることが確実なモデルにするためにはどうすればいいのでしょうか?
これらの手順を踏まずに新しいモデルを展開すると、以下のような重大な影響が生じる可能性があります:
- ステークホルダーからの質問や追加の要求が殺到する
- 他のデータエンジニアや分析エンジニアからのコード改善の提案を受ける
- 新しい機能を追加し、改善を行い、すべての質問に答える前に作業をやり直さなければならない
このプロセスを繰り返すと、データとビジネスチームの間の信頼が損なわれ、フィードバックの嵐からお互いがますます疲弊することになります。これは非常に復旧が困難なものです。
これは、モデルの設計について慎重に考えることの重要性を強調しています。単にdbt内で個人的にではなく、ステークホルダー全員と共にモデルの設計について考え、ワークフローを構築することで、各モデルを有用になる前に4〜5回も構築することを避けるためです。
この記事は、dbtモデルを設計および実装するための最適な方法についての研究と実験の結果です。dbtで実行するコマンドはありませんが、モデルの考え方と時間を無駄にしないためのワークフローの構造について説明します。

異なるアプローチ
私は幸運なことに、この問題について考えた最初の人ではありません。他の多くの分野も同様の課題に直面し、データモデリングのアプローチについて独自のフレームワークやプロセスを作成しています。たとえば:
アジャイルの原則は、急速に変化する要件の環境に対して逆行するウォーターフォール開発アプローチをソフトウェアエンジニアに非推奨しています[1]。代わりに、アジャイルは迅速な反復を採用し、変化する要件に素早く対応できることの競争上の優位性を認識しています。
デザインの原則も、デザインプロジェクトにおいて複数のステークホルダーとの作業方法について慎重に考える必要があることを認識しています[2]。このフレームワークでは、人々を優先し、フィードバックを奨励し、開発の各段階で最善の解決策をできるだけ迅速に見つけることを重視しています。

データモデリングの祖であるRalph Kimballも、データモデリングプロセスにおいてステークホルダーからの品質の高い入力を早期に取得する重要性に言及しています[3]。その第1ステップは、モデルの構築を考える前に、ビジネスプロセスについてできるだけ多くの情報を学ぶことです。
ただし、この問題について考える際に最も影響力のある情報源は、多くのステークホルダーが関与する複雑な問題に取り組むための一連の真理であるシステムエンジニアリングヒューリスティクスでした[4]:
- 元の問題の陳述が必ずしも最善、または正しいものとは限らないと想定しないこと。
- プロジェクトの初期段階では、未知の要素が既知の問題よりも大きな問題となる。
- 可能な限り、構築する前にモデルを作成すること。
- 最も深刻なミスは早い段階で起こる。
これらの情報源は、ゼロからデータモデルを設計するための以下のプロセスを形成するのに役立ちました。
データモデリングの設計プロセス
そこで、私はそれらの原則に忠実で、繰り返し可能で、実際に最初にモデルを適切に構築することができるプロセスを構築したいと考えました。
以下に私が考えついたものを示します:

以下では、各ステップを詳細に説明します。
以下の例は、私がプロダクトの責任者であるデータキャンバスのcount.coからのスクリーンショットを示しています。ただし、このプロセスはツールに依存しません。ここでのスクリーンショットの例に従って進めることができます。
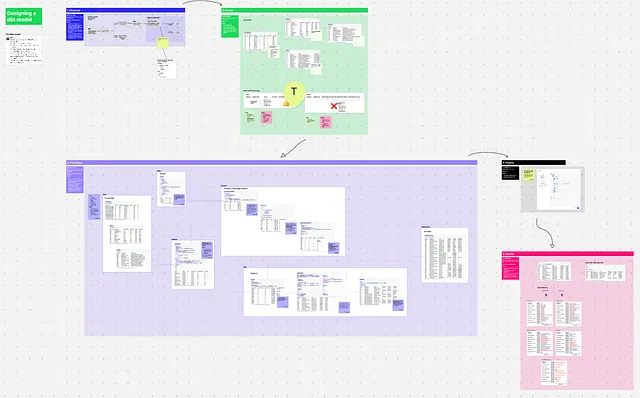
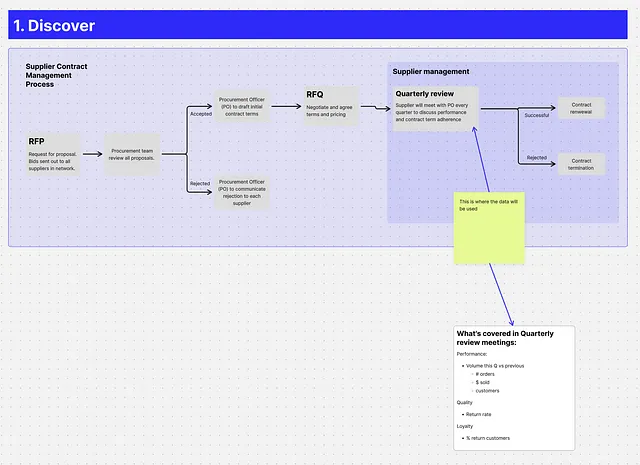
ステップ1:発見
目的:モデル化するビジネスプロセスを理解する。
関係者:あなた、ビジネス関係者
活動:
- ビジネスプロセスをマッピングする
- ステークホルダーが最終テーブルで行いたいこと(計算する必要のあるメトリック、追加する必要のあるフィルターなど)を特定する
- 彼らが現在どのようにそれを行っているかを理解する(もし行っている場合)。それらの解決策には何か問題がありますか?
- 他にも使用する人はいますか?話し合うべき他の関係者はいますか?
- 他の関連するビジネスコンテキストはありますか? 例えば、誰かが来週このトピックについての大きなプレゼンテーションを行う
ステップ2:設計(および反復!)
目的:モデルを構築するための可能なアプローチをマッピングする
関係者:あなた
活動:
- 最終テーブルをマッピングする
- どの粒度を選択しますか?
- どの列を含めますか?
- 最終テーブルのデザインに複数のオプションがある場合は、続行する前にステークホルダーからフィードバックを得る

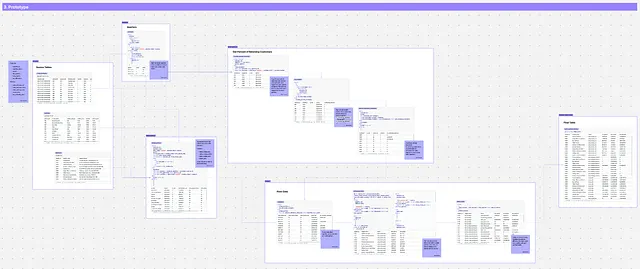
ステップ3:プロトタイプ(および反復!)
目的:合意された最終テーブルに到達する方法をマッピングする。コードと説明を含める。
関係者:あなた、データチームのメンバー、ステークホルダー
活動:
- モデルの各ステップをマッピングする(各段階でのコードと結果を含む)
- 別のデータチームのメンバーがコードを確認することを確認する
- ステークホルダーとロジックを共有し、彼らの期待とコンテキストに合致するか確認する
- プロトタイプモデルの結果を検証する
- ビジネス関係者とデータチームがアプローチと結果を理解し承認するまで反復する
ステップ4:デプロイ
目的: dbtでモデルを展開する
参加者: あなた
活動:
- 最終のプロトタイプコードを取り、dbtのコードベースに展開します
- すべてのテストに合格することを確認します

ステップ5: 提供する
目的: 関係者にテーブルが利用可能であることと、テーブルとの対話方法を知らせる
参加者: あなた、ビジネスステークホルダー
活動:
- ドキュメントを作成します(dbtまたは他の場所で)
- テーブルとドキュメントへのリンクを関係者に送信します
- [オプション] テーブルのサンプル分析を作成し、始めるための出発点を提供します
- [オプション] 新しいテーブルの紹介を希望する人向けに、短いセッションを開催します

次のステップ
次回、ゼロからdbtモデルを構築する際には、このプロセスを試してみてください。これは、あなたと関係者の両方にとって大きな変化となるでしょうが、新しいモデルの展開時間を大幅に短縮し、それらのモデルの全体的な採用を向上させることが証明されています。
データモデリングプロセスにより多くの人々を参加させ、透明性を示すことは、信頼を促進し、価値あるデータモデルを迅速に提供するのに役立ちます。
もし試してみた場合は、コメントを残していただき、どのように進んだかや改善のアイデアを教えてください!これらのことは常に繰り返されなければなりません af..
リソース
[1] アジャイルマニフェスト。 (2001)。アジャイルマニフェストの原則。2023年7月1日に取得、https://agilemanifesto.org/principles.htmlから
[2] デザインカウンシル。 (2004)。イノベーションのためのフレームワーク。2023年7月1日に取得、https://www.designcouncil.org.uk/our-resources/framework-for-innovation/から
[3] ホリスティクス。 キンボールの次元データモデリング。2023年7月1日に取得、https://www.holistics.io/books/setup-analytics/kimball-s-dimensional-data-modeling/から
[4] ピーターブルック。 “システムエンジニアリングヒューリスティックス”。SEBoK編集委員会。2023。システムエンジニアリング知識体系(SEBoK)ガイド、v. 2.8、R.J. Cloutier(総編集責任者)。ホーボーケン、NJ:スティーブンス工科大学の理事会。[DATE]にアクセスしました。www.sebokwiki.org。BKCASEは、スティーブンス工科大学システムエンジニアリング研究センター、国際システム工学協議会、および電子機器技術者協会システム評議会によって管理および維持されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
