トランスフォーマーにおけるセルフアテンション
セルフアテンション in Transformers
セルフアテンションメカニズムの初心者向けガイド

OpenAIのChatGPT、DALL-E、Stable Diffusion、Midjourneyなど、最近の技術に興味を持っていますか?
「Transformer」は、AIの現在の進歩の中心的な要素の1つです。数年前まではAIはSFのように思われていましたが、2022年にはChatGPTやDALL-Eなどの技術が人々の生活に欠かせない存在になりました。その功績は、Googleとトロント大学による画期的な2017年の論文「Attention Is All You Need」[1]にあります。この論文では、アテンションメカニズムを重要な要素とするディープニューラルネットワークアーキテクチャであるTransformerが紹介されました。したがって、アテンションとその数学的基礎を理解することは、AIエンジニアや研究者に多くの機会を開くでしょう。
「Attention」の意味を探求する
まず、「Attention」という用語の文字通りの意味から始めましょう。Wikipediaによると、
「それは情報の一部に選択的に集中するプロセスです」。
友達との会話を想像してみてください。耳には全ての言葉が届いていますが、あなたは特定の言葉にだけ注意を払っています。あなたは一部の言葉に優先度を付け、他の言葉を無視しています。そして、このプロセスは無意識のうちにあなたの脳によって行われています。これは、私たち人間に備わった洗練された認知能力です。
機械学習におけるアテンションも同じですが、数学の関与がある点が異なります。AIモデルに関連性の高い情報に焦点を当て、関連性の低い/重要でない情報を無視することで、入力の文脈を理解するのに役立ちます。
文脈理解
次の文を考えてみてください。
文1:「私はお金を預けるために銀行に行った」。
文2:「川の土手は乾いていてぬかるんでいた」。
「銀行」という単語を見てみましょう。この単語の意味は両方の文で異なります。自分で意味を推測するために少し時間をかけてみてください。前者の文では、おそらく金融機関のような意味だと推測したでしょうし、後者の文では、もしくは私が間違っていなければ、水辺と接する土地のことだと推測したでしょう。先程も述べたように、私たちは生まれつきの才能を持っているので、それに自信を持つべきです。
意味を正しく推測したのは、あなたの無意識のうちに他の隣接する単語を観察し、文の文脈を把握しようとしたからです。最初の文では、「預ける」と「お金」という言葉を観察しました。2番目の文では、「川」、「乾いている」、「ぬかるんでいる」という言葉があります。したがって、隣接する単語が「銀行」の文脈を把握するのに役立ち、文脈が明確になると正しく推測できるのです。
この実験で明確になった非常に重要なことは、文の各単語の意味は文脈に依存し、それは他の単語に依存するということです。したがって、MLモデルが入力を処理する際に文脈情報を追加することは非常に重要です。
セルフアテンション
文の各単語を「銀行」と比較することで、「銀行」の文脈情報を得ることができます。しかし、物事はいつもそれほど単純ではありません。文の全体的な文脈情報を把握するためには、単語「銀行」だけでなく、文のすべての単語を考慮する必要があります。
文の全体的な文脈情報は、すべての単語の文脈情報に依存します。つまり、文の各単語について、文中に存在するすべての単語を使用してその文脈情報を決定しようとする必要があります。これが私たちが行うことであり、数学を使って人間の思考プロセスを模倣します。これにより、モデルは複雑な文を簡単に学習し理解することができます。このために、私たちはこれを「セルフアテンション」と呼びます。
セルフアテンションは、各単語/トークンを表すベクトルを入力として受け取ります。各入力ベクトルを文脈情報を取り入れるために変更し、入力と同じ次元のベクトルを出力します。
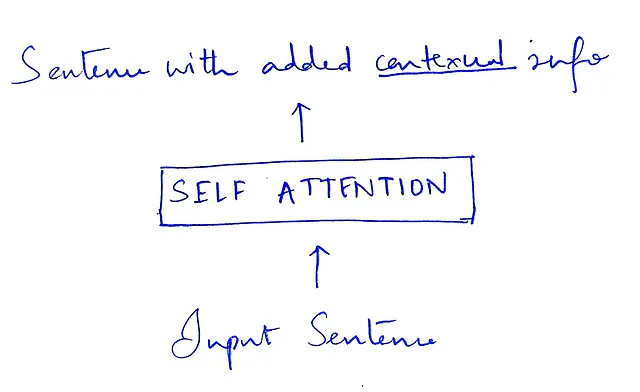
セルフアテンションブロックとその内部の動作を詳しく見てみましょう。
セルフアテンションは、文の各単語を調べ、他のすべての単語にどれだけの重要性を与えるべきかを計算します。
例えば、単語「bank」は他の単語よりも「money」と「deposit」に対してより多くの注目/重要性を示します。または、それらはより関連性が高いと言えるかもしれません。
しかし、二つの単語間の重要度/注目度/関連度の量を決定することが課題です。その解決策は、私たちの例自体にあります。「bank」という単語を取りましょう。この場合、「money」と「deposit」への注目度は他の単語よりも高いです。また、これらの単語が他の単語よりも「bank」と最も類似していることにも気付けると思います。私たちは、類似スコアを注目/焦点/重要性の代理として使用することができます。そうです、「Attention is all you need」という論文の著者たちはこれを実装しました。

では、二つの単語間の類似度をどのように計算するのでしょうか?
私たち人間にとっては、単語は至る所にありますが、モデルには単語の理解はありません。モデルが操作するのはベクトル/行列/テンソルだけです。
したがって、文をセルフアテンションブロックに入力する前に、まず埋め込みベクトルに変換されます。ベクトルの次元は常に固定されています。埋め込みベクトルの後、各単語の位置情報も追加されます。なぜなら、位置は重要であり、単語/文の意味を変えることができるからです。したがって、モデルが各ベクトル/単語の位置を追跡できるようにするためです。これらの概念はこの記事の範囲外です。ここではセルフアテンションに焦点を当てます。要するに、実際のテキストの単語はアテンションブロックに入力されず、代わりに各単語/トークンのベクトル表現が入力されます。
今度は、単語ではなくベクトルを取得しているので、少し単純化されています。そして、今の目標は、任意の二つのベクトル間の類似度を計算することです。
高校の線形代数を思い出してください。二つのベクトル間の類似度を計算する際に使用できる二つの指標があります。
i. ドット積
ii. コサイン類似度
ただし、ドット積は計算がはるかに高速であり、スペースが最適化されているため、私たちはドット積に固執します。ただし、コサイン類似度を試しても構いません。
ドット積
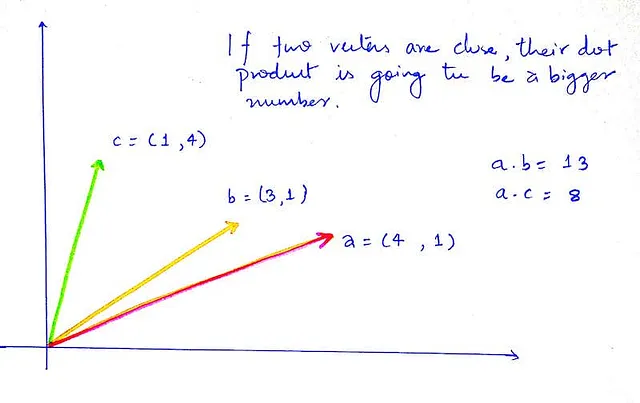

そして類似スコアには、数値、スカラーが必要です。幸いなことに、ドット積は常にスカラーの結果を提供してくれます。
よりシンプルな文「Hello I play games」を取りましょう。そして、類似スコアがどのように計算されるかを見てみましょう。
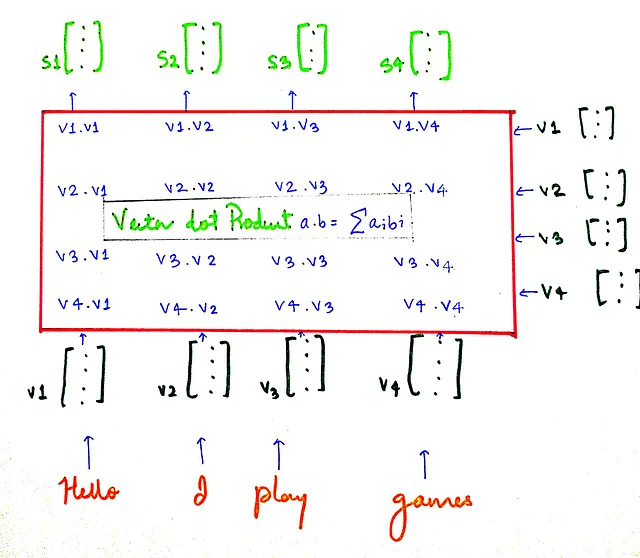
sベクトルは、類似スコアを含むベクトルです。
sᵢは、ベクトルvᵢと他のすべてのベクトルとの類似スコアを含んでいます。例えば、s₁はベクトルv₁と他のすべてのベクトルとの類似スコアを含んでいます(v₁は私たちの例で単語「Hello」を表します)。類似スコアがわかったので、正規化、特にスケーリングとソフトマックスを行いましょう。
ドット積のスケーリングダウン
スケーリングを行わない場合、ドット積の大きなマグニチュードが優位となり、他の要素を overshadow してしまいます。我々は注意/重要度の分布をよりバランス良くし、最も類似したベクトルだけでなく、複数のベクトルに重要度を与えたいと考えています。
したがって、結果(類似スコア)を定数√dₖで除算します。

Softmax を使用した正規化
通常、深層学習では大きな数値ではなく LayerNorm/BatchNorm を使用して正規化し、収束を早めるために小さな値を取得します。ここでも同じことを行います。つまり、注意/類似度スコアの値は1未満になるようにしたいと考えています。そして、各単語について、他のすべての単語との注意スコアの合計が1になるようにします。これが softmax 関数が行うことです。softmax 関数は、ドット積から得られたスコアまたはロジットを確率分布に変換します。
ある単語の注意スコアが他のすべての単語に対して合計で1になると、人間にも解釈可能になります。
Softmax 関数は、k個の実数値ベクトルを取り、それを合計が1になるk個の実数値ベクトルに変換します。
入力値に関係なく、出力は常に0から1の実数であり、合計が1になります。したがって、1からの重みとして解釈することもできます。
softmax の結果は、0から1のスコアを得ることです。これを注意の重みと呼びます。これは、1に対して1つのベクトル/単語が他の単語にどれだけの注意重みを与えるべきかを表します(モデルのパラメータとして扱われるわけではありません)
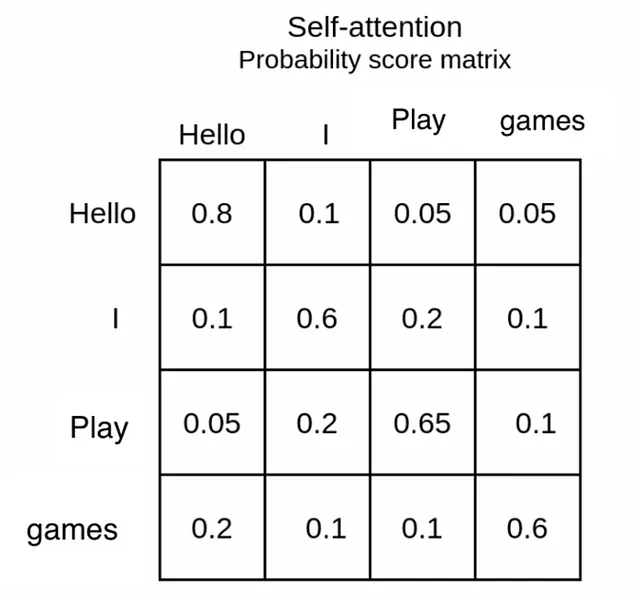
例えば、単語「私」を取り上げましょう。それは自己に焦点を当てますが、これは無視します(類似性のためにすべての単語が自己に焦点を当てます)。その後、単語「Play」に重要度を与えます。これは、「私」は質問「誰がゲームをプレイしますか?」の答えであることを推測できます。これが softmax の結果です。これらが重みです。
セルフアテンションの最初にお伝えしたことを思い出してください。つまり、「文脈情報を抽出する」と「それを入力文に注入する」ことです。私たちは単に文脈情報を抽出したと考えることができます。では、この情報を注入することに移りましょう。
文脈情報の注入
Softmax 関数によって、重みを含む注意行列が得られました。各ベクトル vᵢ について、それが wᵢ に保存されている注意重みと V(すべての入力ベクトルからなる行列)との積を取ります。つまり、重要な特徴/単語が強調され、その影響がより大きくなり、一方で重要でない単語は抑制され、その出力への影響はそれほど大きくありません。
さらに、注意メカニズムを考える際に、なぜベクトルが自己に対してより大きな注意を払う必要があるのかを理解することが重要です。これには、ベクトルの元の情報を保持するという願望があります。
文脈情報を組み込むことは重要ですが、ベクトルの元の情報の重要性を見落とすべきではありません。
y₁ の方程式は、この問題についてさらなる明確さを提供することができます。
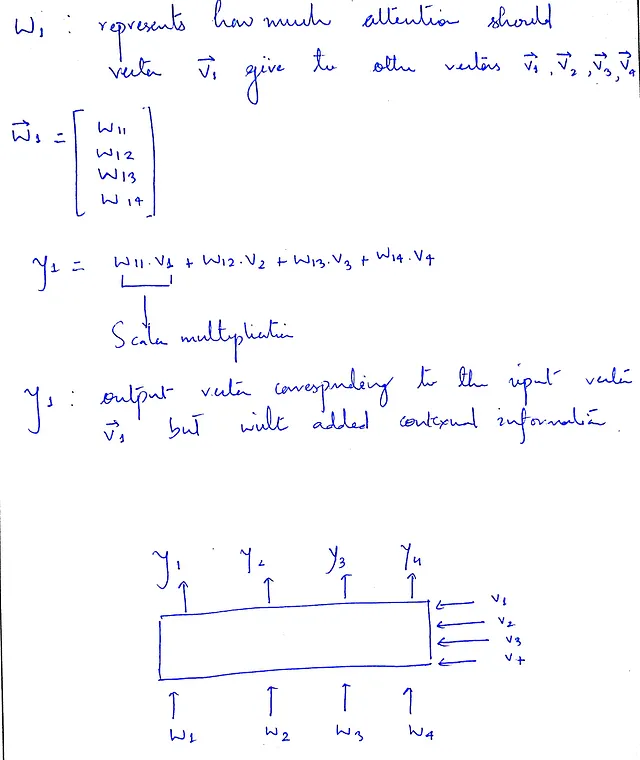
クエリ、キー、および値の概念
タダー、私たちは元のベクトルを修正して、文脈情報を組み込むことに成功しました。しかし、それは見にくくて凝縮していますよね?ベクトルではなく、深層学習アルゴリズムは通常テンソル/行列で操作することに注意してください。そして、入力行列(V)を3回使用していることに注意してください。わかりやすくするために、それぞれに名前を付けましょう。ドット積を行う最初の回、このV行列を2回使用します。次のようにしましょう、自分自身に質問をしましょう、ドット積のステップでは実際に何をしましたか?
答えは私たちに適切な名前を与えます。各ベクトルvᵢについて、他のすべてのベクトル(v₁、v₂、v₃、v₄)との類似性を尋ねました。なぜ私たちは、類似性スコアを尋ねるための行列V(vベクトルで構成される)に対して「クエリ」という名前を付けないのでしょうか?
以前の二文の例から、単語「銀行」の文脈を決定する際に、それはクエリワードと考えることができます(これはクエリベクトルと、すべての単語のクエリベクトルの連結として考えることができるクエリ行列と同じです)。そして、「預金」、「お金」などの他の単語はキーワードと考えることができます(キーマトリックスを構成するもの)。
そして、クエリという名前を、クエリとしてドット積を使用して類似性を計算している行列Vに付けるのはどうでしょうか?
最良の比喩は、YouTubeでビデオを検索することです。検索ボックスにクエリを入力し、YouTubeのデータベースに保存されているすべてのビデオのタイトルとクエリを一致させようとします。最も類似/一致するビデオが最初に表示されます。これはドット積のステップで正確に行ったことです。クエリ行列がキーマトリックスとどれだけ類似しているかを尋ねました。クエリ行列とキーマトリックスの両方は同じであり、等しいです。なぜなら、どちらも入力ベクトルの行列表現だからです。
行列Vを3回目に使用したのは、文脈情報を入力行列に戻すためです。私たちは文脈情報を抽出し、重要な情報を強調し、関連性の低い情報を抑制する必要があります。これを「値行列」と呼ぶべきです。このステップは、行列形式で操作を行う場合に行列の乗算を使用して実装できます。
行列の乗算は、活性化関数やバイアスのない線形層と同じです-実装する際に大きな問題ではありません。
重要なことは、行列Q、K、およびVは本質的に同一であり、値も等しいということです。それらに異なる名前を割り当てる唯一の理由は、アテンションメカニズム内でのそれらの特定の役割と目的を示すためです。使用法に基づいた明確なラベルを提供することで、意図した機能を効果的に伝えながら、等しさを維持することができます。私たちのプロセスの明確で簡潔なステップは次のとおりです:
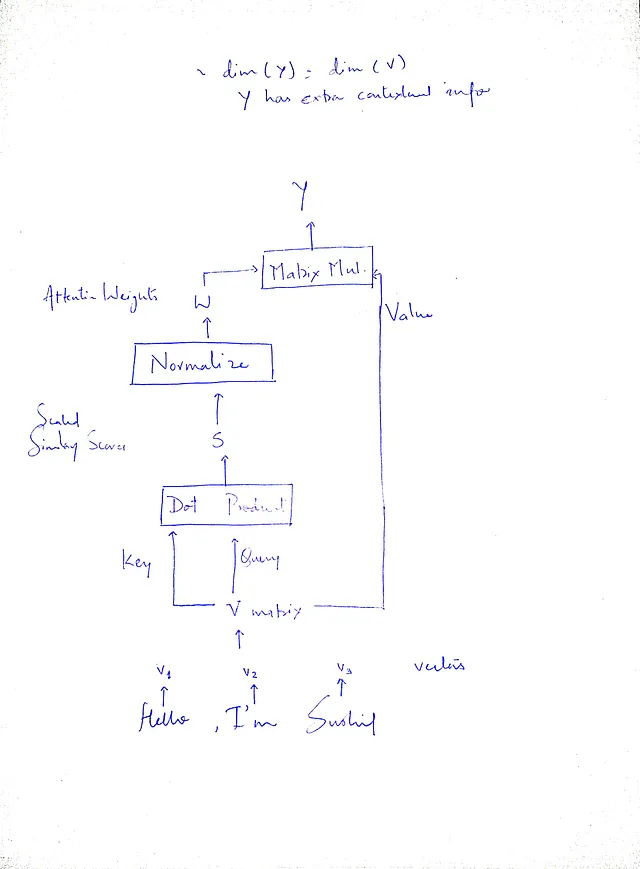
しかし、1つだけまだ足りないものがあります、あなたは推測しましたか?
学習可能なパラメータはどこにありますか?
バックプロパゲーション中に最適化できる学習可能なパラメータはありません。これがなければ、私たちの全システムは無意味になります。学習可能な重みがないと、これを機械学習モデルと呼ぶことはできないと強く疑います。
では、学習可能なパラメータをどこに追加すればよいのでしょうか?
私たちが行っているのは、入力ベクトルクエリ(Q)、キー(K)、および値(V)に基づいた計算です。なぜこれらの行列を使用する前にこれらの行列を乗算しないのでしょうか?そうすれば、学習可能なパラメータが得られ、Q、K、およびVの次元は同じままになります(どうやって?適切な形状の行列と乗算することで、行列乗算は次元を保ったままにすることができます)。
解決策を見つけたようですね。論文でもこのように実装されています。これで問題ありません。行列をクエリウェイト(Wᵩ)、キーウェイト(Wₖ)、およびバリューウェイト(Wᵥ)と呼びます。

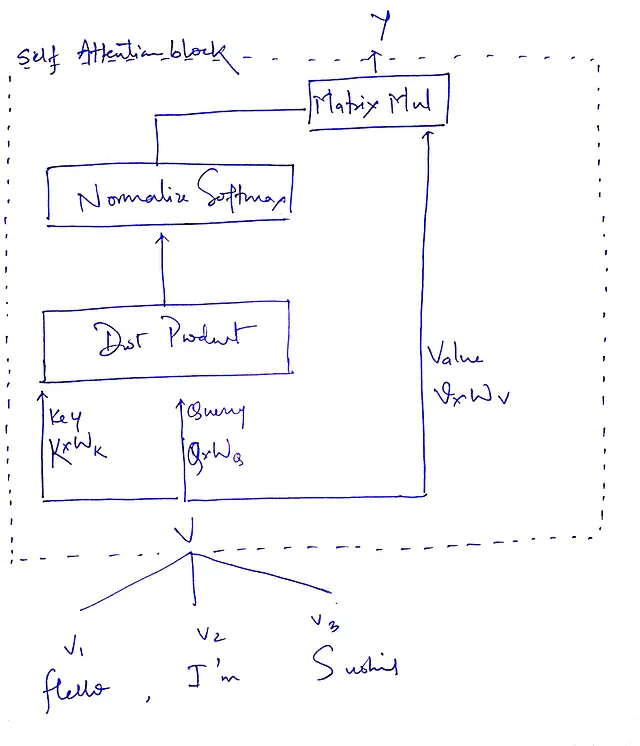
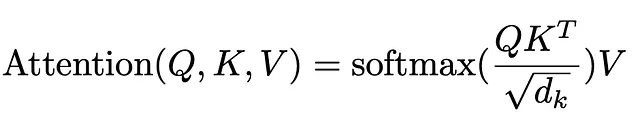
この式は私たちの全体のプロセスをまとめています。まず、QとKのドット積(転置 – より深く探求/実装する際に転置する理由がわかりますが、それは宿題として残されています)。そして、スケーリングダウンは、アテンションの重みを取得するためにソフトマックス関数を適用することに続き、最後に元の入力ベクトルと乗算して、ソフトマックスから受け取った重みに応じて重みをつけます。
以上です!
Transformerは、AIの分野における逆伝播以来の最も注目すべき研究の進歩の1つです。毎週、数多くの最先端のモデルが紹介され、興奮とイノベーションがますます高まっています。この記事[2]とこのYouTubeの動画[3]を読むことを強くお勧めします。これらの情報源は、この画期的なアーキテクチャの複雑さと重要性を理解するのに役立つ洞察と視点を提供してくれます。
手を汚すことを忘れないでください。好奇心を持ち続け、このようなコンテンツをもっと提供するために私に従ってください。
参考文献
[1] Vaswani, Ashish & Shazeer, Noam & Parmar, Niki & Uszkoreit, Jakob & Jones, Llion & Gomez, Aidan & Kaiser, Lukasz & Polosukhin, Illia、「Attention is all you need」、2017年。
[2] Micheal Phi、「Illustrated Guide to transformers- Step by Step Explanation」、ブログ投稿、2020年。
[3] Ark、「Intuition Self-Attention Mechanism in Transformer Networks」、2021年、YouTube。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「BeLFusionに出会ってください:潜在的拡散を用いた現実的かつ多様な確率的人間の動作予測のための行動的潜在空間アプローチ」
- 「40以上のクールなAIツールをチェックアウトしましょう(2023年8月)」
- 大規模画像モデルのための最新のCNNカーネル
- 「生成AI技術によって広まる気候情報の誤情報の脅威」
- 「CREATORと出会ってください:ドキュメントとコードの実現を通じて、LLMs自身が自分のツールを作成するための革新的なAIフレームワーク」
- アバカスAIは、新しいオープンロングコンテキスト大規模言語モデルLLM「ジラフ」を紹介します
- 「非常にシンプルな数学が大規模言語モデル(LLMs)の強化学習と高次関数(RLHF)に情報を提供できるのか? このAIの論文はイエスと言っています!」





