セグメントエニシングモデル:画像セグメンテーションの基礎モデル
セグメントエニシングモデル:画像セグメンテーションの基礎モデル' The condensed result is 'Segment Enicing Model Fundamental Model for Image Segmentation
セグメンテーションは、コンピュータビジョンの中核である、オブジェクトに属する画像のピクセルを識別するプロセスです。このプロセスは、科学的イメージングから写真編集までのアプリケーションで使用され、正確なモデリングのために高度なスキルと大量の注釈付きデータを持つAIインフラストラクチャへのアクセスが必要です。
最近、Meta AIはSegment Anythingプロジェクトを発表しました。これは、コンピュータビジョンの基礎モデルのさらなる研究を支援する、画像セグメンテーションのデータセットとモデルであり、Segment Anythingモデル(SAM)とSA-1Bマスクデータセットを備えています。これは、コンピュータビジョンの基礎モデルのための史上最大のセグメンテーションデータセットであり、SA-1Bは研究用に提供され、SAMはApache 2.0オープンライセンスでライセンスされており、誰でもこのデモを使用して自分の画像でSAMを試すことができます!

セグメンテーションタスクの一般化に向けて
以前、セグメンテーションの問題は、2つのアプローチのクラスを使用してアプローチされました:
- ユーザーがマスクを繰り返し洗練させることによってセグメンテーションタスクをガイドするインタラクティブセグメンテーション。
- 自動セグメンテーションでは、猫や椅子などの選択的なオブジェクトカテゴリを自動的にセグメンテーションすることができますが、トレーニングには大量の注釈付きオブジェクトが必要であり、セグメンテーションモデルをトレーニングするためにはコンピューティングリソースと技術的な専門知識が必要です。どちらのアプローチもセグメンテーションに対する一般的で完全に自動的な解決策を提供していませんでした。
SAMは、インタラクティブセグメンテーションと自動セグメンテーションの両方を1つのモデルで使用しています。提案されたインターフェースは柔軟な使用を可能にし、適切なプロンプト(クリック、ボックス、テキストなど)をエンジニアリングすることで、さまざまなセグメンテーションタスクを実行できます。
SAMは、このプロジェクトの一環として収集された10億以上の高品質なマスクを含む広範なデータセットを使用して開発されました。そのため、トレーニング中に観察されたものを超えた新しいタイプのオブジェクトと画像に汎化する能力を持っています。その結果、実践者はもはや自分のセグメンテーションデータを収集し、特定のユースケースに合わせたモデルを作成する必要はありません。
これらの機能により、SAMはタスクとドメインの両方を一般化することができます。これまで他の画像セグメンテーションソフトウェアが行ったことがないことです。
SAMの機能とユースケース
SAMには、セグメンテーションタスクをより効果的にするための強力な機能が備わっています:
- さまざまな入力プロンプト:セグメンテーションを指示するプロンプトにより、追加のトレーニング要件なしでさまざまなセグメンテーションタスクを簡単に実行できます。インタラクティブなポイントやボックスを使用してセグメンテーションを適用したり、画像内のすべてを自動的にセグメンテーションしたり、曖昧なプロンプトに対して複数の有効なマスクを生成したりすることができます。以下の図では、テキストプロンプトを使用して特定のオブジェクトのセグメンテーションが行われています。

- 他のシステムとの統合:SAMは、将来的にはAR/VRヘッドセットからユーザーの視線を取得し、オブジェクトを選択するなど、他のシステムからの入力プロンプトを受け入れることができます。
- 拡張可能な出力:出力マスクは、他のAIシステムへの入力として機能することができます。例えば、オブジェクトマスクはビデオで追跡され、画像編集アプリケーションで使用され、3D空間に持ち上げられたり、コラージュなどの創造的な用途に使用されたりすることができます。
- ゼロショットの汎化:SAMは、追加のトレーニングなしに未知のオブジェクトに素早く適応することができるようになったオブジェクトの理解を開発しています。
- 複数のマスクの生成:SAMは、セグメンテーションに関する不確実性に直面した場合に複数の有効なマスクを生成することができ、現実世界のセグメンテーションの解決において重要な支援を提供します。
- リアルタイムのマスク生成:SAMは、画像埋め込みを事前計算した後、リアルタイムで任意のプロンプトに対するセグメンテーションマスクを生成することができます。これにより、モデルとのリアルタイムな対話が可能になります。
SAMの理解:どのように機能するのか?
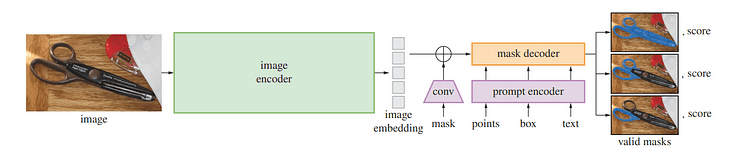
自然言語処理とコンピュータビジョンの最近の進歩の一つは、プロンプトを通じて新しいデータセットやタスクに対してゼロショットおよびフューショット学習を可能にする基礎モデルです。Meta AIの研究者は、SAMをトレーニングして、前景/背景ポイント、ラフなボックス/マスクまたはマスク、自由形式のテキスト、または画像内の対象オブジェクトを示す情報など、任意のプロンプトに対して有効なセグメンテーションマスクを返すようにしました。
有効なマスクとは、プロンプトが複数のオブジェクトを指す可能性がある場合でも(たとえば、シャツの1つのポイントがそれ自体を表すだけでなく、それを着ている人を表すかもしれない場合)、その出力は1つのオブジェクトに対して合理的なマスクを提供する必要があります。つまり、モデルを事前トレーニングし、プロンプトによる一般的な下流セグメンテーションタスクを解決することができます。
研究者は、事前トレーニングタスクと対話型データ収集がモデル設計に特定の制約を課したことを観察しました。最も重要な制約は、リアルタイムシミュレーションがWebブラウザ上のCPUで効率的に実行される必要があり、アノテーターがSAMをリアルタイムで効果的に使用して効率的に注釈を付けることができるようにすることです。ランタイムの制約により、品質とランタイムの制約の間でトレードオフが生じましたが、実際のところ、シンプルな設計は実用的な結果を生み出しました。
SAMの下には、画像エンコーダが画像のための一度限りの埋め込みを生成し、軽量エンコーダがリアルタイムで任意のプロンプトを埋め込みベクトルに変換します。これらの情報源は、SAMで計算された画像埋め込みに基づいてセグメンテーションマスクを予測する軽量デコーダによって組み合わされるため、SAMはWebブラウザで任意のプロンプトに対してわずか50ミリ秒でセグメントを生成することができます。
SA-1Bの構築:10億のマスクのセグメンテーション
モデルの構築とトレーニングには、トレーニング開始時には存在しなかった膨大かつ多様なデータプールへのアクセスが必要です。今日のセグメンテーションデータセットのリリースは、これまでで最も大きなものです。アノテーターは、この新しいデータでSAMを更新する前に、SAMを使用して画像に対して対話型に注釈を付けることを繰り返し行い、モデルとデータセットの両方を継続的に改善しました。
SAMによるセグメンテーションマスクの収集は、以前よりも速くなりました。インタラクティブな方法でアノテーションを行うため、1つのマスクあたりの注釈にはわずか14秒しかかかりません。これは、高速なアノテーションインターフェースを使用してわずか7秒かかるバウンディングボックスのアノテーションよりも2倍遅いプロセスです。COCOの完全手動ポリゴンベースのマスクアノテーションには約10時間かかりますが、SAMのモデル支援アノテーションはさらに速く、データアノテーション時間において1つのマスクあたりのアノテーション時間が6.5倍速く、以前のモデル支援の大規模データアノテーション努力と比較して2倍遅いです!
マスクのインタラクティブな注釈による収集だけでは、SA-1Bデータセットを生成するためには不十分でした。そのため、データエンジンが開発されました。このデータエンジンには3つの「ギア」が含まれており、助けのアノテーターから始まり、収集されるマスクの多様性を高めるために完全に自動化されたアノテーションと助けのアノテーションを組み合わせ、最終的にデータセットのための完全自動マスク作成に移行します。
SA-1Bの最終的なデータセットは、1100万以上のライセンスされたプライバシー保護された画像で収集された10億以上のセグメンテーションマスクを特集しており、これは既存のセグメンテーションデータセットのマスク数の4倍に相当します。人間の評価研究によると、これらのマスクは、より小さなサンプルサイズで手動で注釈付けされた以前のデータセットと比較して、高品質かつ多様性があることが確認されています。
SA-1Bの画像は、さまざまな地理的地域と所得水準を代表する複数の国からの画像プロバイダーから取得されました。特定の地理的地域は未だに十分に代表されていませんが、SA-1Bはより多くの画像と全体的に優れたカバレッジを持つため、より多様な地域を提供しています。
研究者は、性別の表現、肌の色認識、人々の年齢層、提示される人々の年齢の知覚など、さまざまなグループにおけるモデルのバイアスを明らかにするためのテストを実施し、SAMモデルがさまざまなグループで同様に機能することを見つけました。彼らは、これが実世界のユースケースで適用される際に、その結果の作業をより公平にすることを期待しています。
SA-1Bは研究の成果を可能にしましたが、他の研究者が画像セグメンテーションのための基礎モデルをトレーニングすることもできます。さらに、このデータは追加の注釈付きデータセットの基盤となる可能性もあります。
今後の研究とまとめ
メタAIの研究者たちは、自身の研究とデータセットを共有することで、画像セグメンテーションと画像およびビデオの理解の研究を加速させることができると期待しています。このセグメンテーションモデルは、より大きなシステムの一部としてこの機能を実行することができます。
この記事では、SAMとその機能とユースケースについて説明しました。その後、SAMの動作方法とトレーニング方法について説明し、モデルの概要を示しました。最後に、将来のビジョンと作業で記事を締めくくります。SAMについてさらに詳しく知りたい場合は、論文を読んでデモを試してみてください。
参考文献
- Segment Anything: 画像セグメンテーションのための最初の基礎モデルの紹介
- SA-1Bデータセット
- Segment Anything
Youssef Rafaatは、コンピュータビジョンの研究者兼データサイエンティストです。彼の研究は、医療アプリケーション向けのリアルタイムコンピュータビジョンアルゴリズムの開発に焦点を当てています。彼はまた、マーケティング、ファイナンス、およびヘルスケアのドメインで3年以上データサイエンティストとしても働いています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles