「ジオスペーシャルデータエンジニアリング:空間インデックス」
ジオスペーシャルデータエンジニアリング:空間インデックス
クエリの最適化、実行時間の改善、および地理空間データサイエンスアプリケーション
イントロ:なぜ空間インデックスは便利なのか?
地理空間データサイエンスの作業を行う際には、書いているコードの最適化について考えることが非常に重要です。何億行ものデータセットをより速く集計または結合する方法はありますか?そのような場合には、空間インデックスなどの概念が役立ちます。この記事では、空間インデックスの実装方法、その利点と制限、およびUberのオープンソースのH3インデックスライブラリを使用した興味深い空間データサイエンスアプリケーションについて説明します。さあ、始めましょう!
🗺 空間インデックスとは何ですか?
通常のインデックスは、本の末尾に見つけることができるものです:単語のリストとテキスト内での出現場所です。これにより、特定のテキスト内の単語に関する参照を迅速に調べることができます。この便利なツールがないと、興味のある単語の言及を読みたいと思うために、本のすべてのページを手動で調べる必要があります。
現代のデータベースにおいても、このクエリと検索の問題は非常に重要です。インデックスを作成することで、データの検索がフィルタリングよりも速くなる場合があり、興味のある列に基づいてインデックスを作成できます。特に地理空間データでは、「交差」や「近くにある」などの操作をしばしば調べる必要があります。これらの操作を可能な限り高速にするために、どのように空間インデックスを作成できますか?まず、いくつかの地理空間データを見てみましょう:
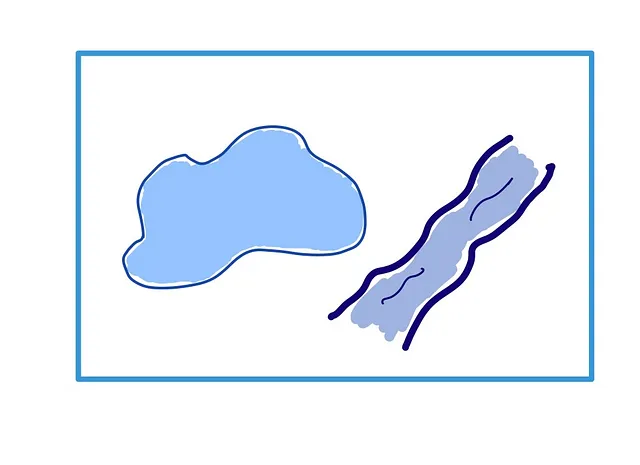
これらの2つの図形が交差しているかどうかを判断するクエリを実行したいとしましょう。データベースは、ジオメトリを含む境界ボックスからインデックスを作成します:
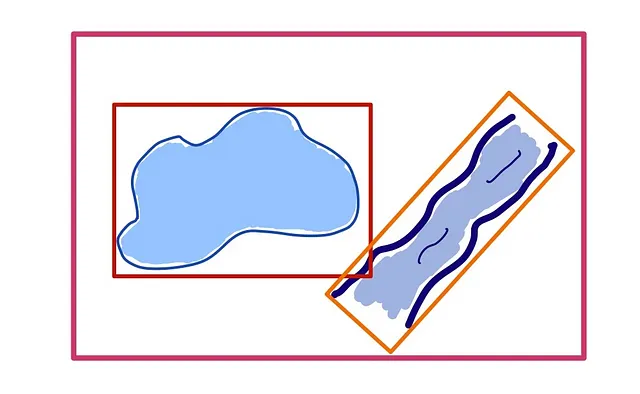
これら2つの図形が交差しているかどうかを判断するために、データベースは2つの境界ボックスが共通の領域を持っているかどうかを比較します。見ての通り、これはすぐに誤った結果につながる可能性があります。この問題を修正するために、PostGISなどの空間データベースでは、これらの大きな境界ボックスをますます小さなものに分割します:

これらのパーティションはRツリーに格納されます。Rツリーは階層的なデータ構造であり、大きな「親」の境界ボックス、その子供、子供の子供などを追跡します。すべての親の境界ボックスには、その子の境界ボックスが含まれています:
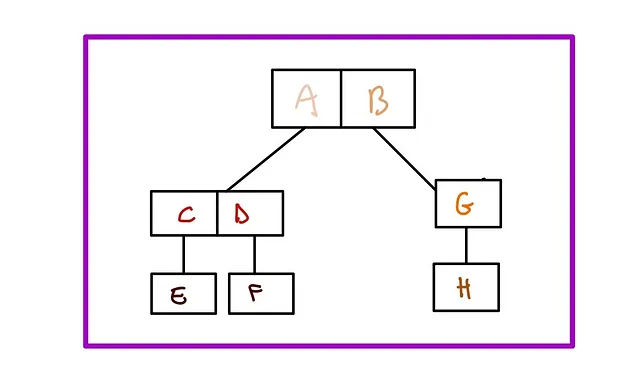
「交差」は、この構造から利益を得る主要な操作の1つです。交差をクエリする際、データベースはこのツリーを下に向かって「現在の境界ボックスが興味のある図形と交差しているかどうか?」と尋ねます。はいと答える場合、その境界ボックスの子供を見て同じ質問をします。このようにして、データベースは迅速にツリーを走査し、交差しないブランチをスキップしてクエリのパフォーマンスを向上させることができます。最終的には、望ましい交差するジオメトリを返します。
🧰 実践:GeoPandasを使った空間インデックスの試用
では、具体的に通常の行ベースの手順と空間インデックスを使用した場合の違いを見てみましょう。私は、ニューヨーク市の国勢調査地域と市の施設を表す2つのデータセットを使用します(両方ともオープンデータで提供されており、こちらおよびこちらで入手できます)。まず、GeoPandasで「交差」操作を試してみましょう。GeoPandasの「交差」は、対象のジオメトリに興味のある列の各行をチェックし、交差するかどうかを確認する行ベースの関数です。
GeoPandasはまた、Rツリーを使用して空間インデックス操作も提供しており、交差演算も行うことができます。以下は、交差操作を100回実行した場合の2つの方法のランタイム比較です(注:デフォルトの交差関数は遅いため、元のデータセットから約100個のジオメトリを選択しました):
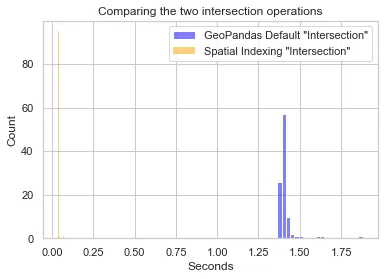
ご覧のように、空間インデックスのアプローチは通常の交差方法に比べてはるかに高速なパフォーマンスを提供しました。実際、それぞれの実行時間の95%信頼区間は次のとおりです:


素晴らしい!では、なぜ常に空間インデックスを使用したくないのでしょうか?メリットがない場合もあるのでしょうか?実際にはあります。これらの制限のいくつかは、空間インデックスがデータの葉をどのように保存するかに起因しています。実際、元のデータがどのように分散しているかは、バウンディングボックスがRツリーに配置される方法に影響を与えます。具体的には、データの大部分が同じ地理的空間に集中している場合、それらは同じ親を共有し、したがって同じ枝にグループ化される傾向があります。これにより、クエリ時に最適化の恩恵をほとんど受けられない歪んだツリーが生じる可能性があります。
💻 他の空間インデックスはどのように見えるのか?
他の企業も独自の空間インデックスを採用しています。UberはH3という、世界を等面積の六角形に分割する階層的なインデックスシステムを使用しています。六角形は都市周辺の人々の移動をモデリングする場合や、半径の計算などの問題に多くの利点があります。地理空間データはこれらの六角形にバケット分けされ、これが会社の主要な分析単位となります。このグリッドは、正二十面体地図投影に122個の六角形セルを重ね合わせて構築され、集計、結合、機械学習アプリケーションなどの幅広い機能をサポートしています。
このシステムおよびその多くの機能はオープンソースであり、分析のためにGitHubで利用可能です。H3 APIの機能の1つは、緯度と経度のポイントを一意の六角形を表す文字列に変換することです。全施設データベースに対してこの操作を行い、六角形の文字列をポリゴンに変換しましょう:
空間データの分析プロジェクトでは、六角形ごとにいくつのプロジェクトが「エージェンシー」という列で分類されているかという質問がよく出てきます。幸いなことに、H3の六角形にデータをバケット分けしたので、これを計算して可視化することは非常に簡単です:

この場合、DCAS(市全体行政サービス局)とPARKS(公園およびレクリエーション局)が各六角形あたりで最も多くの施設を持っていることがわかります。これはおそらく、これらの2つのエージェンシーがより多くの物理的な施設(管理ビルや公園など)を持っているためです。
結論
空間インデックスは、ジオスペーシャルデータサイエンスや分析において非常に有用な最適化ツールです。単純な交差クエリの場合、空間インデックスを使用することで、標準のGeoPandasの交差関数と比較してクエリのパフォーマンスが大幅に向上します。このインデックスの実装方法や、クラスタリングされたデータの大きな枝など、さまざまなニュアンスがあります。企業は独自の解決策を開発しています。UberのH3オープンソースインデックスはその一例であり、さまざまな空間分析の質問に答えることができます。私たちは施設の数を数える操作を紹介しましたが、H3は他のより複雑な機械学習アプリケーションの基準を提供します。
もし興味があれば、このようなコンテンツが好きで都市計画技術についてもっと幅広く学びたい場合、私は「The Zoned Out Chronicles」というニュースレターも書いています。ぜひチェックしてみてください!
読んでいただき、ありがとうございました!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
