創造力を解き放つ:ジェネレーティブAIとAmazon SageMakerがビジネスを支援し、AWSを活用したマーケティングキャンペーンの広告クリエイティブを生み出します
ジェネレーティブAIとAmazon SageMakerは創造力を解き放ち、AWSを活用したマーケティングキャンペーンの広告クリエイティブを生み出します
広告代理店は、生成AIとテキストから画像への基礎モデルを使用して、革新的な広告クリエイティブとコンテンツを作成することができます。この記事では、Amazon SageMakerを使用して既存の基本画像から新しい画像を生成する方法を示します。Amazon SageMakerは、スケールでMLモデルを構築、トレーニング、展開するための完全に管理されたサービスです。このソリューションにより、大きなコストと時間をかけずに、ビジネスが新しい広告クリエイティブコンテンツを開発することが可能になります。
ソリューションの概要
次のシナリオを考えてみましょう:グローバルな自動車会社は、新しい車のデザインのために新しいマーケティング資料を作成する必要があり、強力なブランドを持つクライアント向けに広告ソリューションを提供することで知られているクリエイティブエージェンシーを雇います。自動車メーカーは、ブランドのアイデンティティを維持しながら、モデルをさまざまな場所、色、視点、展望で表示する低コストの広告クリエイティブを求めています。最先端の技術の力を借りて、クリエイティブエージェンシーは、セキュアなAWS環境内で生成AIモデルを使用して顧客をサポートできます。
このソリューションは、Amazon SageMakerの生成AIとテキストから画像へのモデルで開発されています。SageMakerは、完全に管理されたインフラストラクチャ、ツール、ワークフローを備えた、あらゆるユースケースに対して簡単にMLモデルを構築、トレーニング、展開するための完全に管理された機械学習(ML)サービスです。Stability AIのStable Diffusionは、画像生成プロセスを支えるテキストから画像への基礎モデルです。Diffuserは、既存の画像をプロンプトに基づいて新しい画像を生成するためにStable Diffusionを使用する事前トレーニングモデルです。Stable DiffusionをControlNetなどのDiffuserと組み合わせることで、既存のブランド固有のコンテンツを使用して見事なバージョンを開発することができます。AWS内でソリューションを開発することの主な利点は次のとおりです:
- プライバシー – データをAmazon Simple Storage Service(Amazon S3)に保存し、SageMakerを使用してモデルをホストすることで、アセットを公開せずにAWSアカウント内でセキュリティベストプラクティスに準拠することができます。
- スケーラビリティ – SageMakerエンドポイントとして展開されたStable Diffusionモデルは、インスタンスサイズとインスタンス数を設定することでスケーラビリティを実現します。SageMakerエンドポイントには、自動スケーリング機能があり、高い可用性を備えています。
- 柔軟性 – エンドポイントの作成と展開時に、SageMakerはGPUインスタンスタイプを選択する柔軟性を提供します。また、SageMakerエンドポイントの背後のインスタンスは、ビジネスのニーズに応じて最小限の努力で変更することができます。AWSは、生成AIの推論において高性能かつ最低コストのAWS Inferentia2を使用したハードウェアやチップも開発しています。
- 迅速なイノベーション – 生成AIは、新しいアプローチやモデルが常に開発・リリースされている急速に進化するドメインです。Amazon SageMaker JumpStartは、定期的に新しいモデルと基礎モデルをオンボードしています。
- エンドツーエンドの統合 – AWSを使用すると、クリエイティブプロセスを任意のAWSサービスと統合し、AWS Identity and Access Management(IAM)を介した細粒度のアクセス制御、Amazon Simple Notification Service(Amazon SNS)を介した通知、イベント駆動型コンピュートサービスAWS Lambdaを介した後処理を行うことができます。
- ディストリビューション – 新しいクリエイティブが生成された場合、AWSを使用してAmazon CloudFrontを介して複数のリージョンのグローバルチャネルにコンテンツを配布することができます。
この記事では、以下のGitHubのサンプルを使用します。このサンプルでは、Amazon SageMaker Studioを使用して、基礎モデル(Stable Diffusion)、プロンプト、コンピュータビジョン技術、およびSageMakerエンドポイントを使用して、既存の画像から新しい画像を生成します。次の図は、ソリューションアーキテクチャを示しています。
- 「Amazon SageMakerを使用したヘルスケアの要約オプションの探索」
- 「AIの創造性の測定」 AIの創造性を測定する
- 「アルゴリズムを使用して数千件の患者請求を不適切に拒否した」として、シグナが告発されました
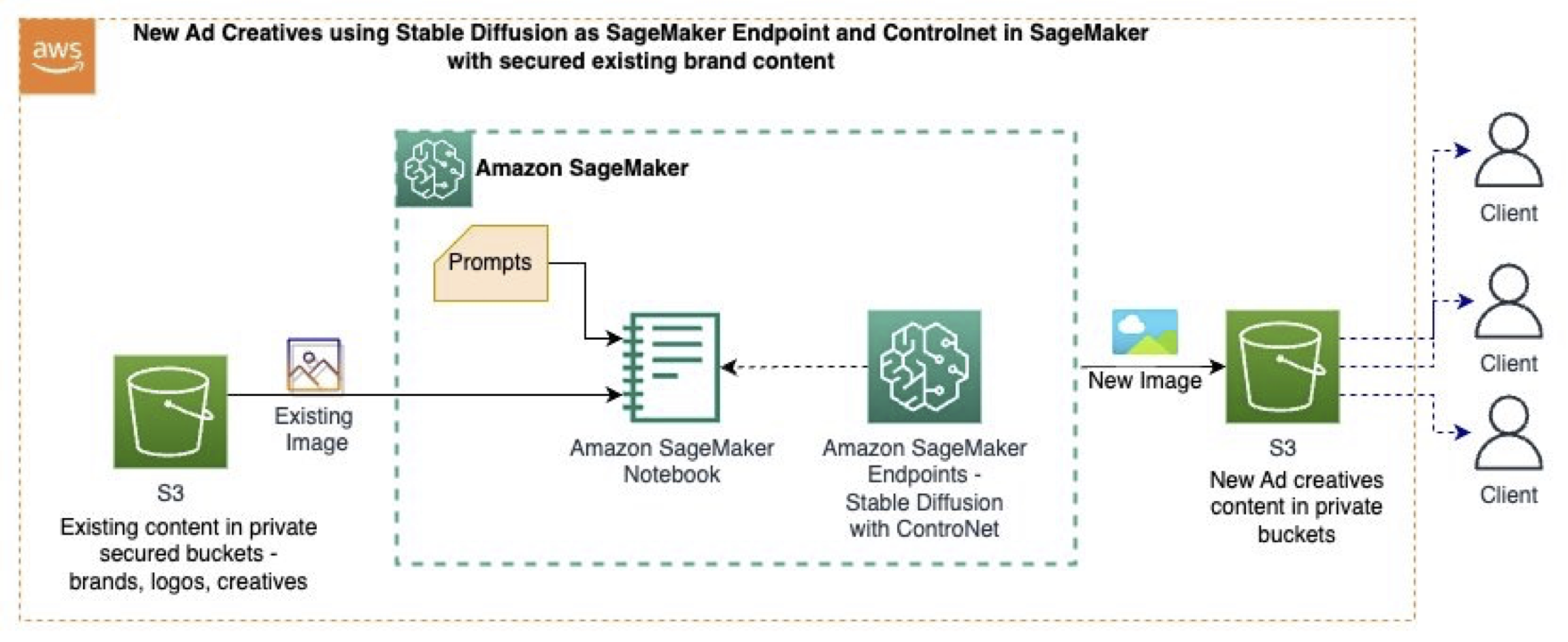
ワークフローは次の手順で構成されています:
- 既存のコンテンツ(画像、ブランドスタイルなど)をS3バケットに安全に保存します。
- SageMaker Studioノートブック内で、元の画像データをコンピュータビジョン技術を使用して画像に変換します。これにより、製品(車のモデル)の形状が保持され、色と背景が削除され、中間の単調な画像が生成されます。
- 中間画像は、ControlNetを使用したStable Diffusionの制御画像として機能します。
- SageMaker JumpstartからのStable Diffusionテキストから画像への基礎モデルとControlNetを使用して、好みのGPUベースのインスタンスサイズでSageMakerエンドポイントを展開します。
- 新しい背景と車の色を説明するプロンプトと中間の単調な画像を使用して、SageMakerエンドポイントを呼び出し、新しい画像を生成します。
- 新しい画像は、生成されるとS3バケットに保存されます。
SageMakerエンドポイントにControlNetを展開する
モデルをSageMakerエンドポイントに展開するためには、各個別のテクニックモデルアーティファクトとStable Diffusionの重み、推論スクリプト、およびNVIDIA Tritonの設定ファイルを含む圧縮ファイルを作成する必要があります。
以下のコードでは、異なるControlNetテクニックとStable Diffusion 1.5のモデル重みをtar.gzファイルとしてローカルディレクトリにダウンロードします:
if ids =="runwayml/stable-diffusion-v1-5":
snapshot_download(ids, local_dir=str(model_tar_dir), local_dir_use_symlinks=False,ignore_patterns=unwanted_files_sd)
elif ids =="lllyasviel/sd-controlnet-canny":
snapshot_download(ids, local_dir=str(model_tar_dir), local_dir_use_symlinks=False) モデルパイプラインを作成するために、SageMakerのリアルタイムエンドポイントがStable DiffusionとControlNetのtar.gzファイルをロードしてホストするために使用するinference.pyスクリプトを定義します。以下はinference.pyからのスニペットで、モデルのロード方法とCannyテクニックの呼び出し方を示しています:
controlnet = ControlNetModel.from_pretrained(
f"{model_dir}/{control_net}",
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
f"{model_dir}/sd-v1-5",
controlnet=controlnet,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32)
# Cannyテクニックのための技術関数を定義する
image = cv2.Canny(image, low_threshold, high_threshold)モデルURIから必要なインスタンスサイズ(GPUタイプ)でSageMakerエンドポイントを展開します:
huggingface_model = HuggingFaceModel(
model_data=model_s3_uri, # トレーニング済みのSageMakerモデルへのパス
role=role, # エンドポイントを作成するための権限を持つIAMロール
py_version="py39", # DLCのPythonバージョン
image_uri=image_uri,
)
# SageMakerエンドポイントとしてモデルを展開する
predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.p3.2xlarge",
)新しい画像を生成する
SageMakerエンドポイントがSageMakerエンドポイント上に展開されたので、プロンプトとベースラインとして使用する元の画像を渡すことができます。
プロンプトを定義するために、新しい画像で探している内容に対するポジティブなプロンプトp_pと避けるべきネガティブなプロンプトn_pを作成します:
p_p="金属のオレンジ色の車、完成した車、カラー写真、屋外での気持ちの良い風景、リアルな、高品質"
n_p="切り抜き、フレーム外、最悪の品質、低品質、JPEGアーティファクト、醜い、ぼやけた、悪い解剖学、悪い比率"最後に、プロンプトとソース画像を引数としてエンドポイントを呼び出して新しい画像を生成します:
request={"prompt":p_p,
"negative_prompt":n_p,
"image_uri":'s3://<bucker>/sportscar.jpeg', #既存のコンテンツ
"scale": 0.5,
"steps":20,
"low_threshold":100,
"high_threshold":200,
"seed": 123,
"output":"output"}
response=predictor.predict(request)異なるControlNetのテクニック
このセクションでは、異なるControlNetのテクニックとそれらが生成された画像に与える影響を比較します。以下の元の画像を使用して、Amazon SageMakerでStable DiffusionとControl-netを使用して新しいコンテンツを生成します。

以下のテーブルは、テクニックの出力が元の画像からどの部分に焦点を当てるかを示しています。
| テクニック名 | テクニックの種類 | テクニックの出力 | プロンプト | Stable Diffusion with ControlNet |
| canny | 黒い背景に白いエッジのあるモノクロ画像。 |  |
金属のオレンジ色の車、完成した車、カラー写真、屋外での気持ちの良い風景、リアルな、高品質 |  |
| depth | 深い領域を黒、浅い領域を白で表したグレースケール画像。 |  |
金属の赤色の車、完成した車、カラー写真、海辺の気持ちの良い風景での屋外、リアルな、高品質 |  |
| hed | 黒い背景に白い柔らかいエッジのあるモ
クリーンアップジェネレーティブAIを使用して新しい広告クリエイティブを生成した後、使用されないリソースをクリーンアップしてください。Amazon S3のデータを削除し、追加の料金が発生しないようにSageMaker Studioのノートブックインスタンスを停止してください。SageMaker JumpStartを使用してSageMakerリアルタイムエンドポイントとしてStable Diffusionを展開した場合は、SageMakerコンソールまたはSageMaker Studioを介してエンドポイントを削除してください。 結論この記事では、Amazon S3に保存されている既存の画像から新しいコンテンツ画像を作成するためにSageMaker上で基本モデルを使用しました。これらの技術を使用することで、マーケティング、広告、その他のクリエイティブエージェンシーはジェネレーティブAIツールを使用して広告クリエイティブのプロセスを拡張することができます。このデモで表示されたソリューションとコードの詳細については、GitHubリポジトリをご覧ください。 また、ジェネレーティブAI、基本モデル、テキストから画像へのモデルに関するユースケースについては、Amazon Bedrockを参照してください。 We will continue to update VoAGI; if you have any questions or suggestions, please contact us! Was this article helpful?93 out of 132 found this helpful Related articles 
AIニュース人工知能の世界からの最新ニュースと更新情報を入手してください Discover more
AI研究
「このAI研究は、姿勢オブジェクト認識を次のトークン予測として新しいアプローチを提案します」という意味ですどのようにして効果的に物体認識にアプローチできるのでしょうか? Meta AIとメリーランド大学の研究チームは、画像埋め込み...
機械学習
RPDiffと出会ってください:3Dシーン内の6自由度オブジェクト再配置のための拡散モデル日常のタスクを実行するためのロボットの設計と構築は、コンピュータサイエンスエンジニアリングの最も刺激的で挑戦的な分野...
機械学習
「Amazon SageMaker のルーティング戦略を使用して、リアルタイムの推論レイテンシを最小限に抑えましょう」Amazon SageMakerは、リアルタイム推論のための機械学習(ML)モデルの展開を簡単に行えるだけでなく、AWS InferentiaなどのC...
データサイエンス
オレゴン大学とアドビの研究者がCulturaXを紹介します:大規模言語モデル(LLM)の開発に適した167の言語で6.3Tのトークンを持つ多言語データセット大規模言語モデル(LLM)は、幅広いタスクで最先端のパフォーマンスを劇的に向上させ、新たな新興スキルを明らかにすることに...
Want to read more? Go here
|





