シンボルの調整は言語モデルの文脈における学習を向上させます
シンボルの調整は学習を向上させます
Google Researchの学生研究者であるJerry Weiと主任科学者のDenny Zhouによって投稿されました。
人間の知性の重要な特徴の一つは、わずかな例だけを用いて推論することで新しいタスクを学ぶことができることです。言語モデルのスケーリングによって、マシンラーニングにおいて新たな応用やパラダイムを実現することができました。しかし、言語モデルはプロンプトの与え方に敏感であり、頑健な推論を行っているわけではないことを示しています。例えば、言語モデルはしばしばプロンプトエンジニアリングやタスクの指示としてのフレーズのような作業が必要であり、不正確なラベルが表示されてもタスクのパフォーマンスに影響を与えないという予期しない振る舞いを示すことがあります。
「Symbol tuning improves in-context learning in language models」では、シンボルチューニングと呼ばれるシンプルなファインチューニング手法を提案しています。この手法は入力とラベルのマッピングを強調することで、インコンテキスト学習を改善することができます。私たちはFlan-PaLMモデルにおけるシンボルチューニングの実験を行い、さまざまな設定での利点を観察しました。
- シンボルチューニングは、未知のインコンテキスト学習タスクにおいてパフォーマンスを向上させ、指示や自然言語のラベルがないような曖昧なプロンプトに対しても非常に頑健です。
- シンボルチューニングされたモデルは、アルゴリズムの推論タスクにおいて非常に強力です。
- 最後に、シンボルチューニングされたモデルは、インコンテキストで提示された反転したラベルを追従する能力が大幅に向上しており、インコンテキスト情報を使用して以前の知識を上書きすることができます。
 |
| シンボルチューニングの概要。モデルは自然言語のラベルが任意のシンボルに置き換えられたタスクでファインチューニングされます。シンボルチューニングは、指示や関連するラベルが利用できない場合、モデルがインコンテキストの例を使用してタスクを学ぶ必要があるという直感に基づいています。 |
動機
指示チューニングは一般的なファインチューニング手法であり、パフォーマンスを向上させ、モデルがインコンテキストの例に従う能力を改善することが示されています。ただし、評価例に指示と自然言語のラベルを通じてタスクが冗長に定義されるため、モデルは例を使用する必要がありません。例えば、上の図の左側では、例がモデルがタスク(感情分析)を理解するのに役立つことができますが、モデルは例を無視してタスクを示す指示を読むことができます。
- 「ポッドキャスティングのためのトップAIツール(2023年)」
- 何でもセグメント化、しかしより速く! このAIアプローチはSAMモデルの速度を向上させます
- 「DreamIdentityに会ってください:テキストから画像モデルのための編集可能性を保ちつつ、各顔のアイデンティティのための最適化フリーAIメソッド」
シンボルチューニングでは、モデルは指示が削除され、自然言語のラベルが意味的に関連のないラベル(例:「Foo」、「Bar」など)に置き換えられた例でファインチューニングされます。この設定では、インコンテキストの例を見ないとタスクが明確になりません。例えば、上の図の右側では、タスクを理解するために複数のインコンテキストの例が必要です。シンボルチューニングはモデルにインコンテキストの例を推論することを教えるため、シンボルチューニングされたモデルは、インコンテキストの例とそのラベルの間の推論を必要とするタスクにおいてより優れたパフォーマンスを発揮するはずです。
 |
| シンボルチューニングに使用されるデータセットとタスクの種類。 |
シンボル調整手順
私たちは、シンボル調整手順に使用するために、22の公開されている自然言語処理(NLP)データセットを選択しました。これらのタスクは過去に広く使用されており、私たちは離散的なラベルを必要とするため、分類タイプのタスクのみを選択しました。その後、ラベルを整数、文字の組み合わせ、および単語の3つのカテゴリから選択された約30,000の任意のラベルの1つにランダムにマッピングします。
実験では、PaLMの指示に調整されたバリアントであるFlan-PaLMをシンボル調整します。Flan-PaLMモデルの3つの異なるサイズを使用します:Flan-PaLM-8B、Flan-PaLM-62B、およびFlan-PaLM-540B。また、Flan-cont-PaLM-62B(780Bトークンではなく1.3TトークンでのFlan-PaLM-62B)もテストし、62B-cと略称します。
 |
| 私たちは3つのカテゴリ(整数、文字の組み合わせ、単語)からなる約300,000の任意のシンボルセットを使用しています。約30,000のシンボルは調整中に使用され、残りは評価のために保持されます。 |
実験のセットアップ
未知のタスクを実行するモデルの能力を評価したいため、シンボル調整(22のデータセット)や指示調整(1,800のタスク)で使用されたタスクでは評価できません。そのため、ファインチューニング中に使用されなかった11のNLPデータセットを選択します。
文脈における学習
シンボル調整手順では、モデルは文脈内の例を理解してタスクを成功させるために推論する必要があります。なぜなら、プロンプトは関連するラベルや指示から単純に学習することはできないように変更されるからです。シンボル調整されたモデルは、タスクが不明で文脈内の例とそのラベルの間の推論が必要な設定でより良いパフォーマンスを発揮するはずです。これらの設定を探索するために、入力とラベルの間でタスクを学習するために必要な推論の量が異なる4つの文脈内学習設定を定義します(指示/関連するラベルの入手可能性に基づいて)
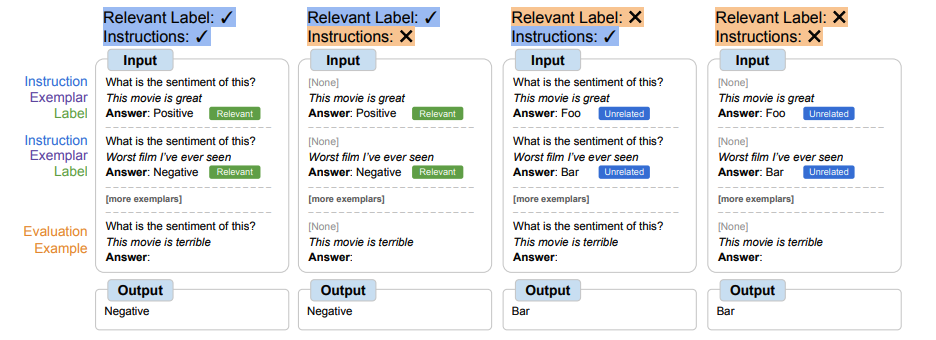 |
| 指示や関連する自然言語のラベルの入手可能性に応じて、モデルは文脈内の例との推論を行う必要があります。これらの特徴が利用できない場合、モデルは与えられた文脈内の例との推論を行う必要があります。 |
シンボル調整は、モデル62B以上のすべての設定でパフォーマンスを向上させます。関連する自然言語のラベルがある設定ではわずかな改善(+0.8%から+4.2%)、関連する自然言語のラベルがない設定では大幅な改善(+5.5%から+15.5%)が見られます。驚くべきことに、関連するラベルが利用できない場合、シンボル調整されたFlan-PaLM-8BはFlanPaLM-62Bを上回り、シンボル調整されたFlan-PaLM-62BはFlan-PaLM-540Bを上回ります。このパフォーマンスの違いは、シンボル調整により、これらのタスクでより小さなモデルが大きなモデルと同様のパフォーマンスを発揮できる可能性があることを示しています(推論計算を約10倍節約)。
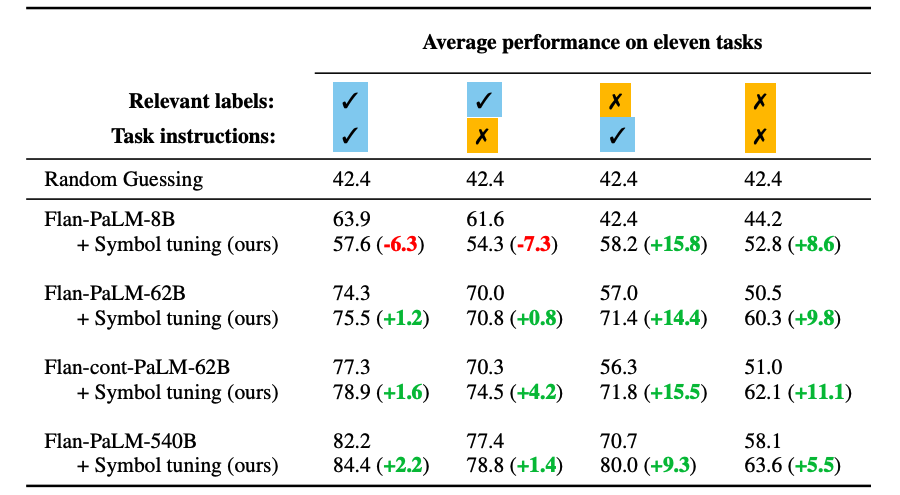 |
| 大きなシンボル調整モデルは、特に関連するラベルが利用できない設定で、コンテキスト内の学習においてベースラインよりも優れています。パフォーマンスは、11つのタスク全体での平均モデルの正確性(%)として示されます。 |
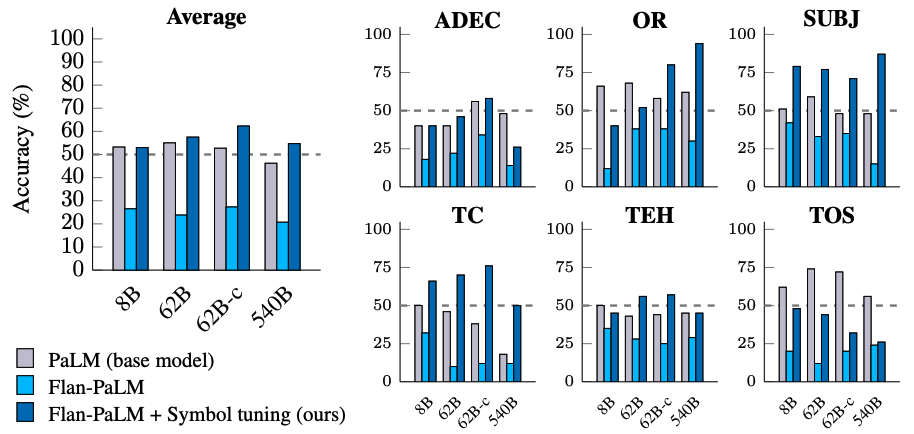
アルゴリズム的推論
BIG-Benchからのアルゴリズム的推論タスクについても実験を行っています。主なタスクは2つあります:1)リスト関数—非負の整数を含む入力と出力リスト間の変換関数(例:リストの最後の要素を削除する)を特定すること。2)シンプルなチューリング概念—バイナリ文字列を使って、入力を出力にマッピングする概念を学ぶための理由付け(例:文字列内の0と1を入れ替える)。
リスト関数とシンプルなチューリング概念のタスクにおいて、シンボル調整による平均パフォーマンスの向上は、それぞれ18.2%と15.3%です。さらに、シンボル調整を行ったFlan-cont-PaLM-62Bは、リスト関数タスクにおいて平均的にFlan-PaLM-540Bを上回り、推論計算の約10倍の削減に相当します。これらの改善は、シンボル調整がどのようなアルゴリズムデータも含まなかったにもかかわらず、モデルの未知のタスクタイプにおけるコンテキスト内での学習能力を強化することを示しています。
 |
| シンボル調整されたモデルは、リスト関数タスクとシンプルなチューリング概念タスクにおいて、より高いパフォーマンスを発揮します。(A–E):リスト関数タスクのカテゴリ。 (F):シンプルなチューリング概念タスク。 |
反転したラベル
反転したラベルの実験では、コンテキスト内と評価例のラベルが反転しており、先行知識と入力-ラベルのマッピングが一致していない(例:ポジティブな感情を含む文が「ネガティブな感情」としてラベル付けされている)ため、モデルが先行知識を上書きできるかどうかを研究することができます。以前の研究では、事前学習されたモデル(指示調整なし)は、コンテキスト内で提示される反転したラベルをある程度追従できるが、指示調整はこの能力を低下させることが示されています。
すべてのモデルサイズで同様の傾向が見られます — シンボル調整されたモデルは、指示調整されたモデルよりもはるかに反転したラベルを追従する能力が高いです。シンボル調整を行った後、Flan-PaLM-8Bは、すべてのデータセットで平均的な改善率26.5%、Flan-PaLM-62Bは33.7%、Flan-PaLM-540Bは34.0%の改善を見せました。さらに、シンボル調整されたモデルは、事前学習のみのモデルと同等かそれ以上のパフォーマンスを発揮します。
 |
| シンボル調整されたモデルは、コンテキスト内で提示される反転したラベルを追従する能力が指示調整されたモデルよりも優れています。 |
結論
私たちはシンボルチューニングという、自然言語のラベルが任意のシンボルに変換されるタスクでモデルをチューニングする新しい方法を提案しました。シンボルチューニングは、モデルが指示や関連するラベルを使用して提示されたタスクを決定することができない場合、代わりに文脈の中での例から学習することによって行われます。私たちは、22のデータセットと約30,000の任意のシンボルをラベルとして使用し、シンボルチューニング手順を用いて4つの言語モデルをチューニングしました。
まず、シンボルチューニングが未知の文脈学習タスクでのパフォーマンスを改善することを示しました。特に、プロンプトに指示や関連するラベルが含まれていない場合に顕著な効果がありました。また、シンボルチューニングされたモデルは、数値やアルゴリズムのデータがシンボルチューニング手順には含まれていないにもかかわらず、アルゴリズム的な推論タスクにおいては非常に優れた結果を示しました。最後に、入力のラベルが反転した文脈学習の設定では、シンボルチューニング(一部のデータセットに対して)が指示チューニング中に失われた反転したラベルの従う能力を回復させることができました。
今後の課題
シンボルチューニングを通じて、モデルが文脈学習中に入力とラベルのマッピングをより詳細に調べ、学習できる度合いを高めることを目指しています。私たちの結果が、言語モデルが文脈中で提示されるシンボルに対して推論する能力を向上させるためのさらなる研究に対する動機づけとなることを望んでいます。
謝辞
この記事の著者は現在Google DeepMindの一員です。この研究は、Jerry Wei、Le Hou、Andrew Lampinen、Xiangning Chen、Da Huang、Yi Tay、Xinyun Chen、Yifeng Lu、Denny Zhou、Tengyu Ma、およびQuoc V. Leによって行われました。Google ResearchおよびGoogle DeepMindの同僚には、アドバイスと有益な議論に感謝いたします。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






