クロスバリデーションの助けを借りて、あなたの機械学習モデルに自信を持ちましょう
クロスバリデーションで自信を持つ機械学習モデル
<h2 id="交差検証は、機械学習モデルが新しいデータで十分信頼できるかどうかを確認するための重要なツールです。この記事では、交差検証について、なぜ必要なのか、データに対してどのように実行するかについて説明します。
過学習
訓練済みの機械学習モデルを訓練データ自体で評価することは基本的に間違っています。これを行うと、モデルは訓練中に学習した値のみを返します。この評価では常に100%の正確性を示し、訓練済みモデルが新しいデータでどれほど優れているかについては何の洞察も提供しません。そのようなモデルは新しいデータ上で性能が低い可能性が高いです。このような訓練データ上で高い正確性を持つが新しいデータ上では非常に低い性能を示す状態を過学習と呼びます。
データのトレーニングデータとテストデータへの分割
しばしば、データは過学習の問題に対処し、訓練済みモデルの実際の正確性を知るために2つの部分に分割されます。これらの2つの分割部分はトレーニングデータとテストデータと呼ばれます。テストデータは元のデータの約10%〜20%程度のサイズです。
ここでのアイデアは、データをトレーニングデータでトレーニングし、その後、テストデータで訓練済みモデルを評価することです。
しかし、この手法でも過学習の可能性がわずかにあります。線形サポートベクターマシンアルゴリズムの例を取りましょう。サポートベクターマシンアルゴリズムには、モデルの制約を増減させるために使用されるパラメータ「C」があります。人は「C」の値を調整して、テストデータ上で訓練済みモデルの高い正確性を得ることができます。これにより、実際の正確性を向上させるのではなく、実験フェーズでテストデータ上で高い性能を達成するために調整されたモデルは、本番環境での性能が低下する可能性があります。
過学習の問題に対処するためには、データをトレーニング、検証、テストの3つの部分に分割することができます。
データをトレーニング、検証、テストの3つの部分に分割する
データを3つの部分に分割することで、実験フェーズでモデルを高い正確性に調整することを防ぐことができます。
トレーニングデータは分割の中で最も大きな部分になります(元のデータの約80%)。検証データとテストデータは元のデータのそれぞれ約10%です。これらの割合は参考のために与えられているだけであり、必要に応じて変更することができます。
機械学習モデルはトレーニングデータで訓練されます。訓練済みモデルの評価は検証データを使用して行われます。最後に、テストデータでの予測は訓練済みモデルの実際の性能を確認するための手段です。
検証データ上で高い正確性を得るようにモデルを調整しようとしても、テストデータ上のパフォーマンスを通じて訓練済みモデルが信頼性があるかどうかを知ることができます。
この手法にも欠点があります。
データを3つに分割することで、訓練目的で使用できたデータが減少することになります。データの分割により、データの20%が失われる可能性があります。
また、この手法のもう一つの欠点は、モデルの正確性が行われる分割によって異なることです。一つの分割では非常に高い正確性が得られる一方、別の分割では低い正確性が得られる可能性があります。
交差検証手法は、これらの2つの欠点にある程度対処するために使用されます。
交差検証
交差検証では、テストデータは必要ですが、検証データは必要ありません。
まず、元のデータをトレーニングデータとテストデータに分割します。そして、モデルは以下のようにトレーニングデータ上で訓練されます:
- トレーニングデータを「n」個の等しい部分に分割します。それぞれの分割を分割1から分割nと名付けましょう。
- モデルは、可能なすべての「n-1」分割のグループで訓練されます。n個のグループが得られます。
- 訓練済みモデルは、(n-1)分割の各グループに対して残りの分割を使用して評価されます。
これをより明確に理解するために、例を1つ挙げましょう。
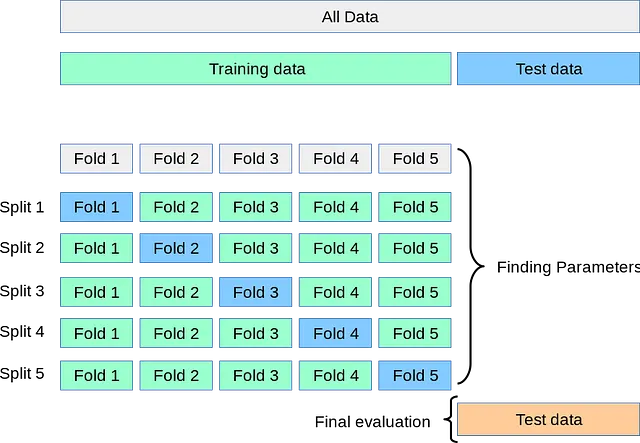
トレーニングデータを5つのパートに分割するとしましょう。そして、4つの分割のすべての可能なグループを見つけます。これらのグループは上記のダイアグラムにおいて緑色で表示されています。そして、4つの分割のグループごとに残りの最後の分割は上記のダイアグラムにおいて青色で表示されています。
分割1では、モデルはグループ(Fold2、Fold3、Fold4、Fold5)でトレーニングされます。トレーニング後、モデルはFold1で評価されます。
分割2では、モデルはグループ(Fold1、Fold3、Fold4、Fold5)でトレーニングされます。トレーニング後、モデルはFold2で評価されます。
分割3では、モデルはグループ(Fold1、Fold2、Fold4、Fold5)でトレーニングされます。トレーニング後、モデルはFold3で評価されます。
分割4では、モデルはグループ(Fold1、Fold2、Fold3、Fold5)でトレーニングされます。トレーニング後、モデルはFold4で評価されます。
分割5では、モデルはグループ(Fold1、Fold2、Fold3、Fold4)でトレーニングされます。トレーニング後、モデルはFold5で評価されます。
最後に、すべての分割の正確さを平均して最終的な正確さを得ます。この平均正確さが検証パフォーマンスとなります。各分割の正確さを取得するため、これらの正確さの標準偏差も得ることができます。
その後、クロスバリデーションで使用されるパラメータでトレーニングされたモデルのパフォーマンスをテストデータを使用してチェックします。これを正確さのテストパフォーマンスと呼びます。
モデルの検証パフォーマンスとテストパフォーマンスが良好で比較可能であれば、モデルはリアルタイムで使用するために信頼性があると考えることができます。
scikit-learnのcross_val_scoreメソッドを使用してデータにクロスバリデーションを実行する
デモンストレーションにはアイリスの花のデータセットを使用しましょう。
## 必要なライブラリのインポートimport warningswarnings.filterwarnings('ignore')import numpy as npimport pandas as pdfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split, cross_val_score, cross_val_predictfrom sklearn.ensemble import RandomForestClassifier## 実行するデータのロードdata = load_iris()df = pd.DataFrame()df[data.feature_names] = data.datadf['target'] = data.target## データを独立変数と従属変数に分割X, y = df.drop('target', axis=1), df['target']## データをトレーニングデータとテストデータに分割X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)## ランダムフォレストクラシファイアモデルをクロスバリデーションによって評価rfc = RandomForestClassifier(max_depth=3)cross_validation_score = cross_val_score(rfc, X_train.values, y_train.values, cv=5, scoring = 'accuracy')print(f"ランダムフォレストクラシファイアのクロスバリデーションスコアは{round(cross_validation_score.mean(), 2)} +/- {round(cross_validation_score.std(),2)}です。")
ここで、’cv’の値は整数です。’cv’パラメータにクロスバリデーションイテレータ(KFold、StratifiedKFoldなど)を使用して値を提供できます。
## クロスバリデーションイテレータKFoldを使用from sklearn.model_selection import KFoldrfc = RandomForestClassifier(max_depth=3)kf = KFold(n_splits=5)cross_validation_score = cross_val_score(rfc, X_train, y_train, cv=kf, scoring = 'accuracy')print(f"ランダムフォレストクラシファイアのクロスバリデーションスコアは{round(cross_validation_score.mean(), 2)} +/- {round(cross_validation_score.std(),2)}です。")
## クロスバリデーションイテレータStratifiedKFoldを使用from sklearn.model_selection import StratifiedKFoldrfc = RandomForestClassifier(max_depth=3)skf = StratifiedKFold(n_splits=5)cross_validation_score = cross_val_score(rfc, X_train, y_train, cv=skf, scoring = 'accuracy')print(f"ランダムフォレストクラシファイアのクロスバリデーションスコアは{round(cross_validation_score.mean(), 2)} +/- {round(cross_validation_score.std(),2)}です。")
データは、StratifiedKFoldイテレータを使用して、ターゲットクラスに基づいてトレーニングデータとテストデータに等しい割合で分割されます。
クロスバリデーションを実行する際にトレーニングされたモデルを使用して、予測結果を見つけることもできます。
## クロスバリデーションを使用して予測を行う
from sklearn.model_selection import cross_val_predict
rfc = RandomForestClassifier(max_depth=3)
cv_predictions = cross_val_predict(rfc, X, y, cv=5)
print(f"テストデータの予測結果は:{cv_predictions} (形状:{cv_predictions.shape})")
scikit-learnパイプラインを使用したクロスバリデーション
モデルにデータをトレーニングする前に、データに対して1つの前処理ステップを実行します。パイプラインを作成し、クロスバリデーションスコアを見つけましょう。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipe = Pipeline([
('standardization', StandardScaler()),
('model', RandomForestClassifier(max_depth=3))
])
cross_validation_score = cross_val_score(pipe, X_train, y_train, cv=5, scoring = 'accuracy')
print(f"ランダムフォレスト分類器のクロスバリデーションスコアは{round(cross_validation_score.mean(), 2)} +/- {round(cross_validation_score.std(),2)}です。")この記事がお気に召しましたら、ぜひご意見をお聞かせください。建設的なフィードバックは大いに歓迎します。LinkedInでご連絡ください。素晴らしい1日をお過ごしください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 高リスクの女性における前がん変化の予測 マンモグラフィに基づくディープラーニング手法の突破
- 光ベースのコンピューティング革命:強化された光ニューラルネットワークでChatGPTタイプの機械学習プログラムを動かす
- 「Advanced Reasoning Benchmark(ARB)に会いましょう:大規模な言語モデルを評価するための新しいベンチマーク」
- 「FACTOOLにご紹介いたします:大規模言語モデル(例:ChatGPT)によって生成されたテキストの事実エラーを検出するためのタスクとドメインに依存しないフレームワーク」
- LGBMClassifier 入門ガイド
- 「MLOpsの全機械学習ライフサイクルをカバーする:論文要約」
- 「ゲート付き再帰型ユニット(GRU)の詳細な解説:RNNの数学的背後理論の理解」






