データサイエンスのキャリアトレンドを理解するためにSQLを使用する
キャリアトレンド理解のためSQL使用

データが新たな石油であるとされる世界で、データサイエンスのキャリアの微妙なニュアンスを理解することは今まで以上に重要です。データに興味がある人や機会を探しているベテランの方にとって、SQLを使用することでデータサイエンスの求人市場に対する洞察を得ることができます。
どのデータサイエンスの求人が最も魅力的なのか、または最も高給のものはどれなのかを知りたくなるのは当然です。あるいは、経験レベルがデータサイエンスの平均給与にどのように関連しているのかが気になるかもしれません。
この記事では、データサイエンスの求人市場に深く入り込んでこれらの疑問(およびその他の疑問)に答えます。さあ始めましょう!
データセットの給与トレンド
この記事で使用するデータセットは、2021年から2023年の間のデータサイエンス分野の給与パターンについて明らかにします。職務経歴、職位、企業の場所などの要素を重点的に取り上げることで、セクター内の賃金のばらつきに関する重要な洞察を提供します。
この記事では、以下の質問に答えます:
- 異なる経験レベルごとの平均給与はどのようになっていますか?
- データサイエンスの中で最も一般的な職名は何ですか?
- 企業の規模による給与分布の違いはどのようになっていますか?
- データサイエンスの求人は主にどの地域にありますか?
- どの職名がデータサイエンスで最高給与を提供していますか?
このデータはKaggleからダウンロードすることができます。
1. 異なる経験レベルごとの平均給与はどのようになっていますか?
このSQLクエリでは、異なる経験レベルごとの平均給与を求めています。GROUP BY句はデータを経験レベルごとにグループ化し、AVG関数は各グループの平均給与を計算します。
これにより、分野での経験が収入の可能性にどのように影響するかを理解することができます。以下にコードを示します。
SELECT experience_level, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY experience_level;
さて、この出力をPythonで可視化しましょう。
以下にコードを示します。
# プロットのために必要なライブラリをインポート
import matplotlib.pyplot as plt
import seaborn as sns
# グラフのスタイルを設定
sns.set(style="whitegrid")
# グラフを保存するためのリストを初期化
graphs = []
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x))
plt.title('経験レベル別の平均給与')
plt.xlabel('経験レベル')
plt.ylabel('平均給与(USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
さて、エントリーレベルと経験豊富なレベル、中級レベルと上級レベルの給与を比較してみましょう。
まず、エントリーレベルと経験豊富なレベルの比較です。以下にコードを示します。
# エントリーレベルと経験豊富なレベルのデータをフィルタリング
entry_experienced = df[df['experience_level'].isin(['Entry_Level', 'Experienced'])]
# 中級レベルと上級レベルのデータをフィルタリング
mid_senior = df[df['experience_level'].isin(['Mid-Level', 'Senior'])]
# エントリーレベル対経験豊富なレベルのグラフをプロット
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=entry_experienced, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('平均給与:エントリーレベル vs 経験豊富なレベル')
plt.xlabel('経験レベル')
plt.ylabel('平均給与(USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
以下はグラフです。
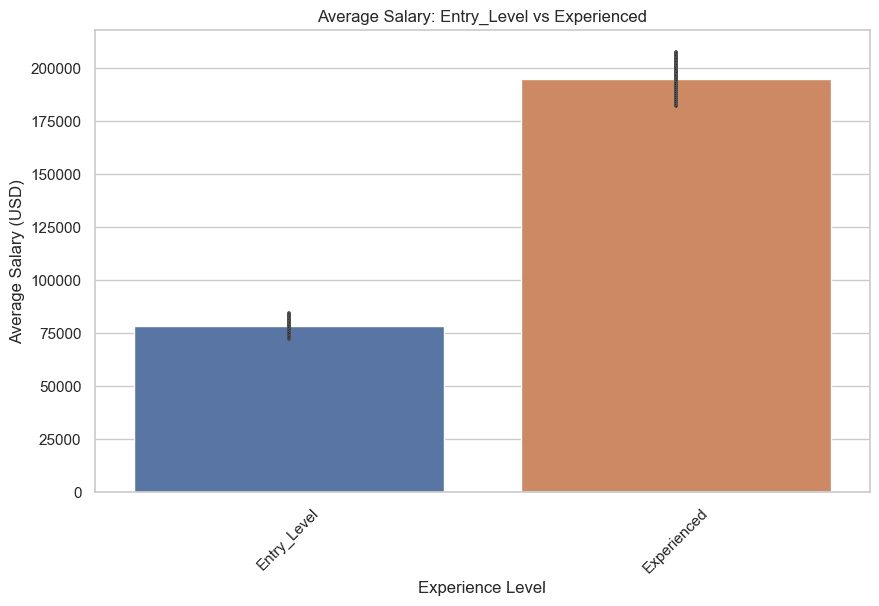
次に、中級レベルと上級レベルの給与を描画しましょう。以下にコードを示します。
# 中級レベル対上級レベルのグラフをプロット
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=mid_senior, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('平均給与:中級レベル vs 上級レベル')
plt.xlabel('経験レベル')
plt.ylabel('平均給与(USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show() 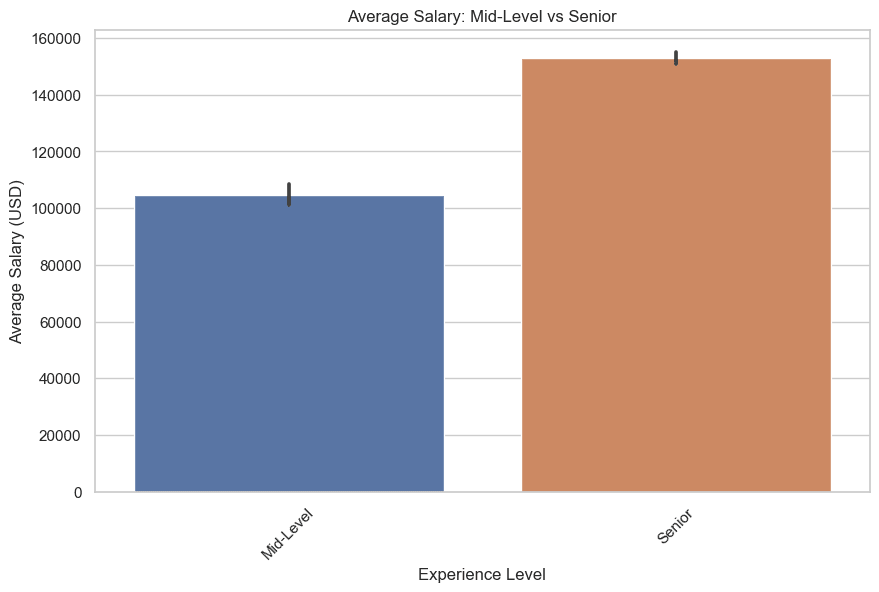
2. データサイエンスにおける最も一般的な職名は何ですか?
ここでは、データサイエンスにおける上位10の最も一般的な職名を抽出します。COUNT関数は各職名の出現回数を数え、結果は降順に並べ替えられ、最も一般的な職名が上部に表示されます。
この情報は、求人市場の需要を把握することで、ターゲットとする潜在的な役割を特定する際に役立ちます。コードを見てみましょう。
SELECT job_title, COUNT(*) AS job_count
FROM salary_data
GROUP BY job_title
ORDER BY job_count DESC
LIMIT 10;
さて、Pythonを使用してこのクエリを可視化しましょう。
以下にコードを示します。
plt.figure(figsize=(12, 8))
sns.countplot(y='job_title', data=df, order=df['job_title'].value_counts().index[:10])
plt.title('データサイエンスにおける最も一般的な職名')
plt.xlabel('職名の数')
plt.ylabel('職名')
graphs.append(plt.gcf())
plt.show()
グラフを見てみましょう。
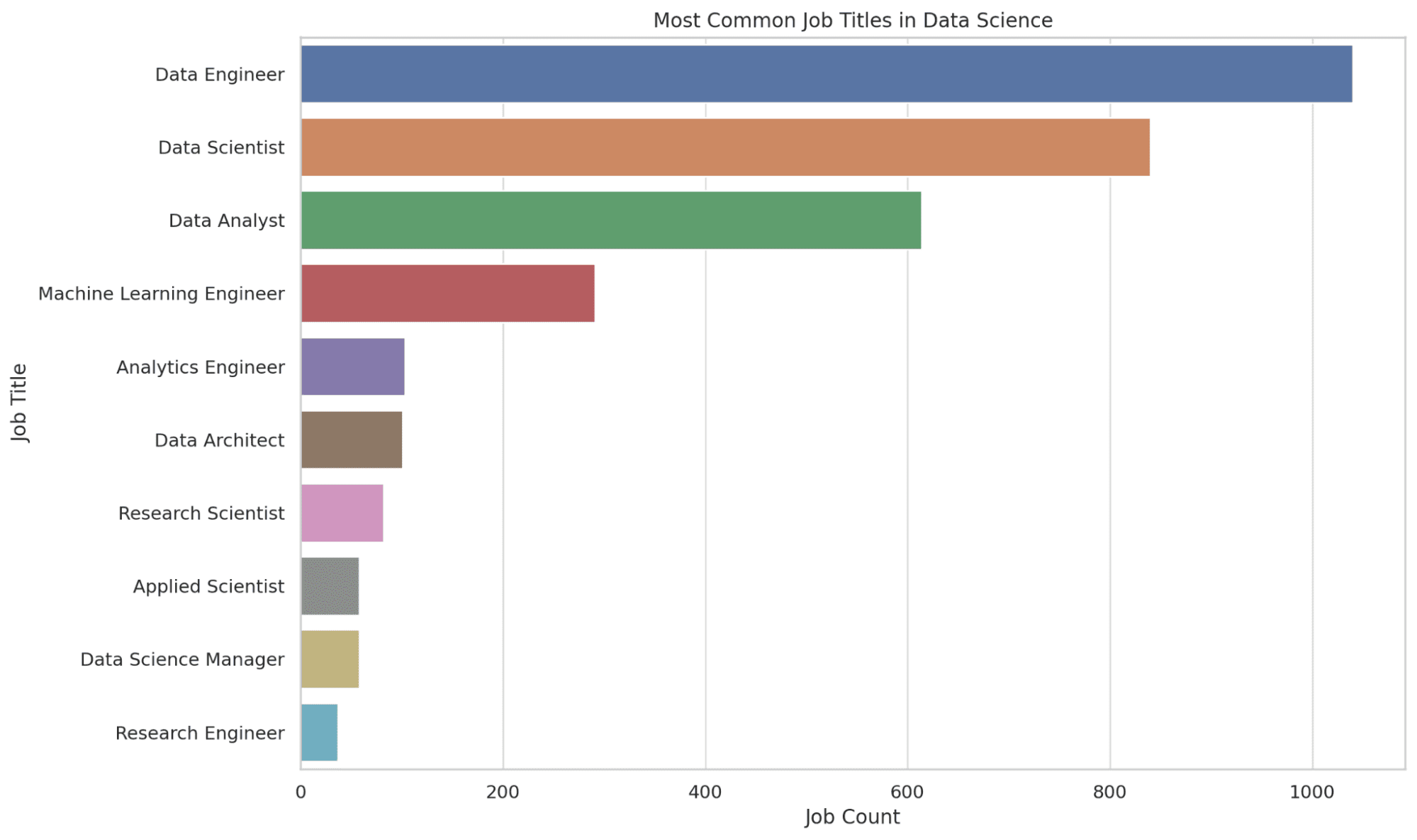
3. 企業の規模による給与分布の変動はどのようになりますか?
このクエリでは、企業の規模別に平均、最小、最大の給与を抽出します。AVG、MIN、MAXなどの集計関数を使用することで、企業の規模と給与の関係を包括的に把握することができます。
このデータは、参加する企業の規模によって期待できる給与を理解するのに役立ちます。コードを見てみましょう。
SELECT company_size, AVG(salary_in_usd) AS avg_salary, MIN(salary_in_usd) AS min_salary, MAX(salary_in_usd) AS max_salary
FROM salary_data
GROUP BY company_size;
さて、Pythonを使用してこのクエリを可視化しましょう。
以下にコードを示します。
plt.figure(figsize=(12, 8))
sns.barplot(x='company_size', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0, order=['Small', 'VoAGI', 'Large'])
plt.title('企業の規模による給与分布')
plt.xlabel('企業の規模')
plt.ylabel('平均給与(USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
以下が出力結果です。
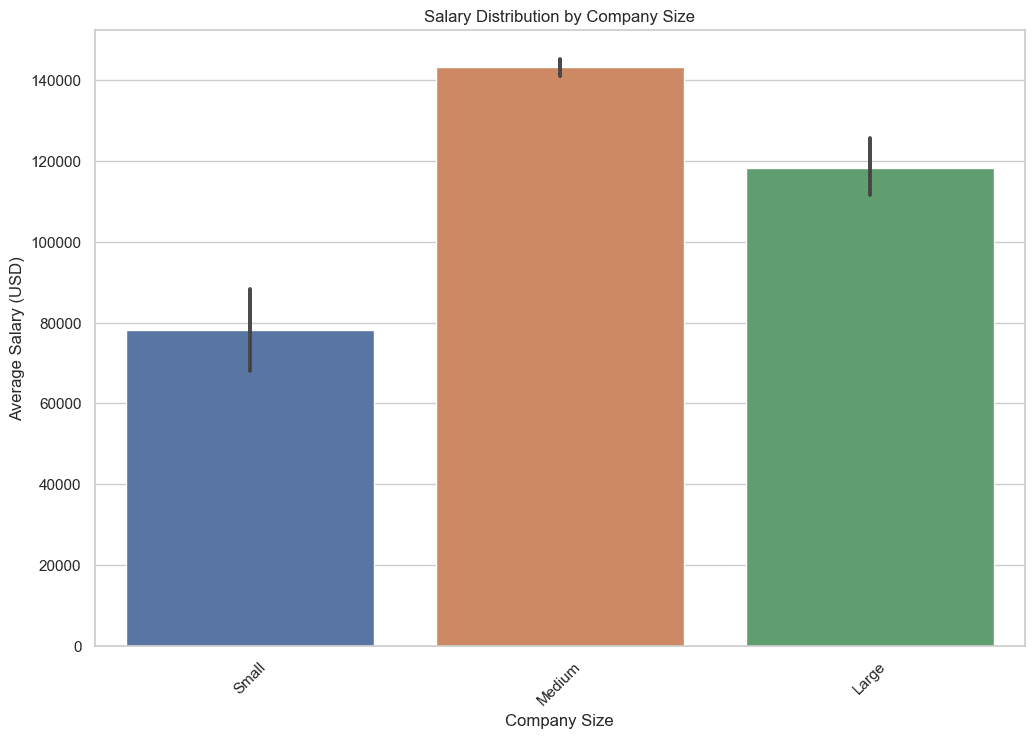
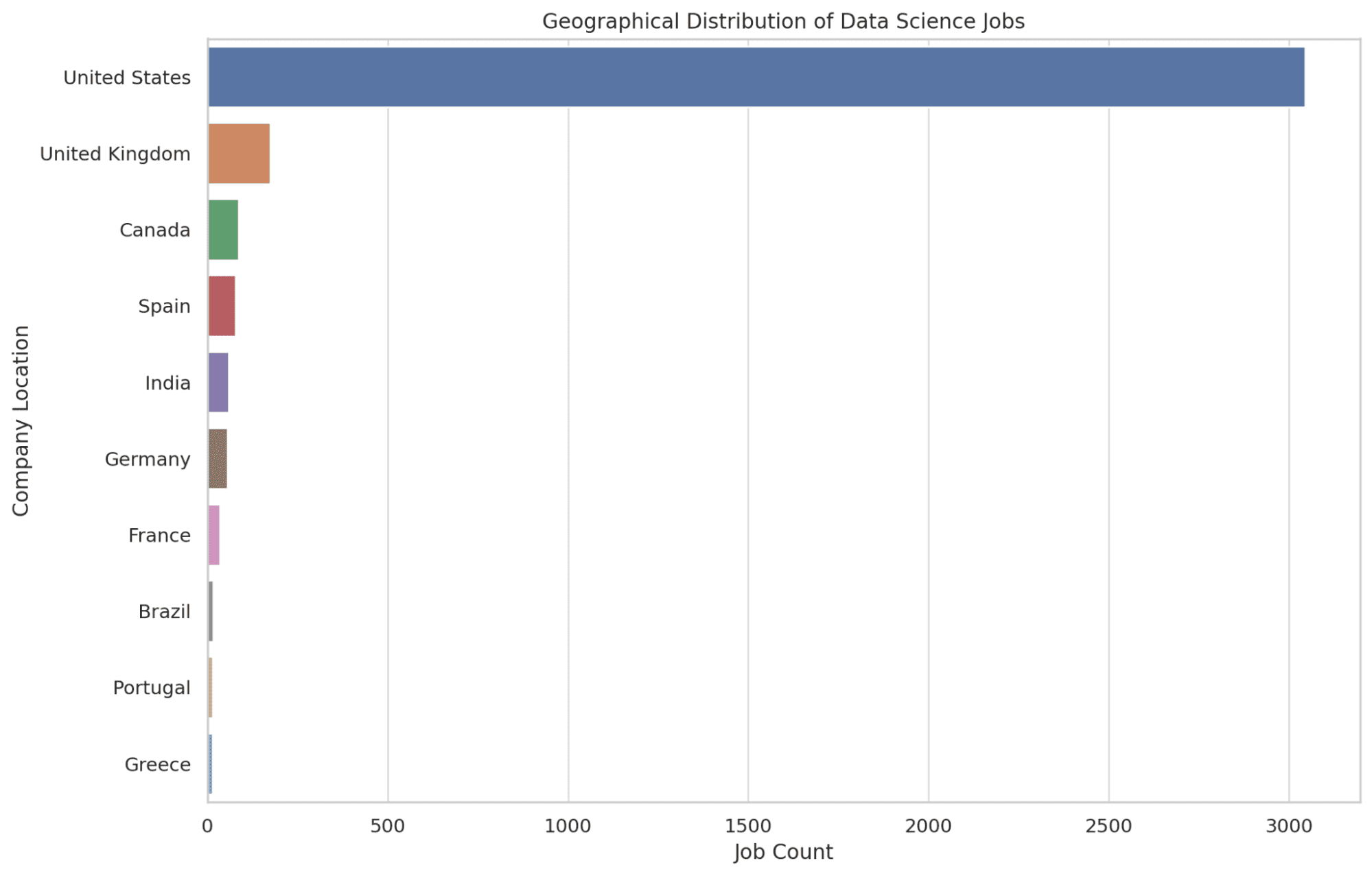
4. データサイエンスの仕事は主にどの地域に位置していますか?
ここでは、データサイエンスの求人数が最も多い上位10の地域を特定します。各地域の求人数を数えるためにCOUNT関数を使用し、求人数で降順に並べ替えて、最も求人数の多い地域を強調します。
この情報により、データサイエンスの役割の中心地を知ることができ、潜在的な転居の決定に役立ちます。コードを見てみましょう。
SELECT company_location, COUNT(*) AS job_count
FROM salary_data
GROUP BY company_location
ORDER BY job_count DESC
LIMIT 10;
さて、Pythonを使用してこのクエリをグラフ化しましょう。
plt.figure(figsize=(12, 8))
sns.countplot(y='company_location', data=df, order=df['company_location'].value_counts().index[:10])
plt.title('データサイエンスの求人の地理的分布')
plt.xlabel('求人数')
plt.ylabel('企業の場所')
graphs.append(plt.gcf())
plt.show()
以下に示すグラフを見てみましょう。
5. データサイエンスで最高の給与を提供する職種はどれですか?
ここでは、データサイエンスセクターにおける給与が最も高いトップ10の職種を特定しています。AVGを使用して、各職種の平均給与を計算し、平均給与に基づいて降順で並べ替え、最も収益性の高いポジションを強調しています。
このデータを見ることで、キャリアの道のりで目指すことができます。次に、このデータに対してPythonの可視化を作成する方法を理解しましょう。
SELECT job_title, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY job_title
ORDER BY avg_salary DESC
LIMIT 10;
以下は出力結果です。
(ここでは写真を使用することができません。なぜなら、上記に4つの写真を追加し、サムネイル用に1つの写真を残しているためです。以下のような表を使用して出力を示すチャンスはありますか?)
| 順位 | 職種 | 平均給与(USD) |
| 1 | データサイエンステックリード | 375,000.00 |
| 2 | クラウドデータアーキテクト | 250,000.00 |
| 3 | データリード | 212,500.00 |
| 4 | データ分析リード | 211,254.50 |
| 5 | 主任データサイエンティスト | 198,171.13 |
| 6 | データサイエンスディレクター | 195,140.73 |
| 7 | 主任データエンジニア | 192,500.00 |
| 8 | 機械学習ソフトウェアエンジニア | 192,420.00 |
| 9 | データサイエンスマネージャー | 191,278.78 |
| 10 | 応用科学者 | 190,264.48 |
この時は、自分でグラフを作成してみましょう。
ヒント: ChatGPTで次のプロンプトを使用して、与えられたSQLクエリから得られた洞察と同様のデータサイエンスで最高の給与を持つトップ10の職種を可視化するためのPythonのコードを生成することができます。
<SQLクエリをここに入力>
上記のSQLクエリと同様に、データサイエンスで最高の給与を持つトップ10の職種を可視化するためのPythonのグラフを作成してください。
最後の考え
データサイエンスキャリアの多様な領域を巡る旅を終えるにあたり、SQLが信頼できるガイドとなり、キャリアの意思決定をサポートするための洞察の宝物を発掘するお手伝いができることを願っています。
今では、キャリアパスをマッピングするだけでなく、SQLを使用して生のデータを強力なナラティブに形成する際にも、より装備されていることを願っています。だから、データがあなたの羅針盤であり、SQLがあなたの導く力となる未来への一歩を踏み出すことを祝しています!
お読みいただきありがとうございます!Nate Rosidiはデータサイエンティストであり、プロダクト戦略においても活躍しています。彼はまた、アナリティクスを教える兼任教授でもあり、トップ企業の実際の面接問題を使用してデータサイエンティストが面接に備えるためのプラットフォーム「StrataScratch」の創設者でもあります。彼とはTwitter(StrataScratch)またはLinkedInでつながってください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
