カーネル密度推定器のステップバイステップの説明
カーネル密度推定器の説明
KDE公式の直感的な導出
導入
データ分布の感覚を掴むために、確率密度関数(PDF)を描画します。データが正規分布、ポアソン分布、幾何分布などの一般的な密度関数に適合する場合、最尤推定手法を使用して密度関数をデータにフィットさせることができます。

残念ながら、データ分布は時には非常に不規則で、通常のPDFとは異なります。そのような場合、カーネル密度推定(KDE)はデータ分布の合理的かつ視覚的に快適な表現を提供します。
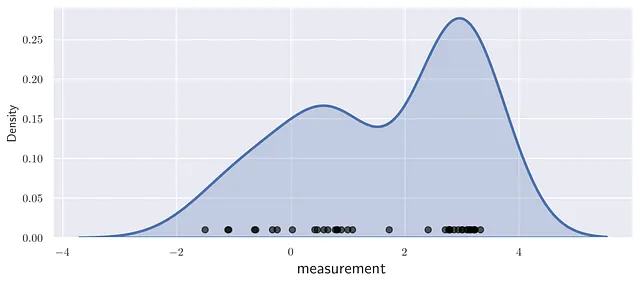
厳密な数学的導出ではなく、あなたの直感に頼ってKDEの構築手順を説明します。
カーネル関数
KDEの理解の鍵は、それを異なるオブジェクトがレゴブロックで構成されるような構成要素からなる関数と考えることです。KDEの特徴的な特徴は、カーネルと呼ばれる一種のブロックのみを使用することです(「すべてのブロックに支配される1つのブロック」)。このブロックの主な特性は、シフトおよび伸縮/収縮の能力です。各データポイントには1つのブロックが与えられ、KDEはすべてのブロックの合計です。
KDEは、カーネル関数と呼ばれる一種の構成要素からなる合成関数です。
カーネル関数は、各データポイントに対して個別に評価され、これらの部分結果がKDEを形成するために合計されます。
KDEへの第一歩は、単一のデータポイントに焦点を当てることです。単一のデータポイントに対してPDFを作成すると求められた場合、どうしますか?まず、x = 0 として考えます。最も論理的なアプローチは、その点に正確にピークを持ち、距離に応じて減衰するPDFを使用することです。以下の関数はその役割を果たします。
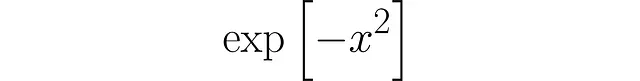
ただし、PDFは曲線の下に単位面積を持つ必要があるため、結果を再スケーリングする必要があります。したがって、この関数は2πの平方根で割り、√2の倍率で伸縮する必要があります(3Blue1Brownではこれらの係数の優れた導出を提供しています):

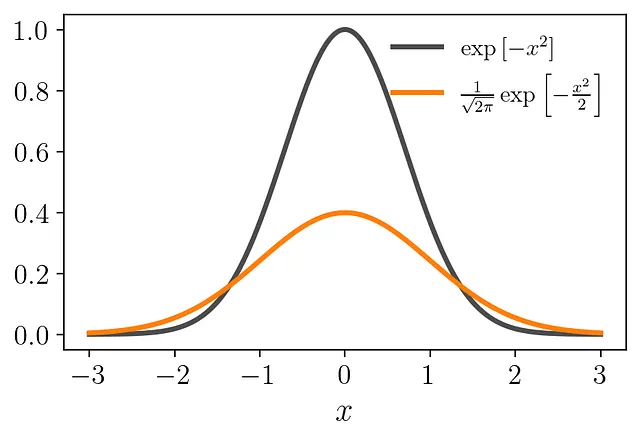
最終的に、カーネル関数として知られるレゴブロックに到達します。これは有効なPDFです:

このカーネルは、平均がゼロで分散が1のガウス分布に相当します。
しばらく遊んでみましょう。まずはx軸を移動する方法を学びます。
単一のデータポイント xᵢ(データセット X に属するi番目のポイント)を取ります。シフトは引数の減算によって実現できます:
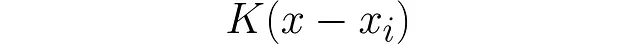
カーネルの幅(いわゆるカーネルバンド幅)を引数に追加することで、曲線を広げたり狭めたりすることができます。通常、分母として定数hが導入されます:
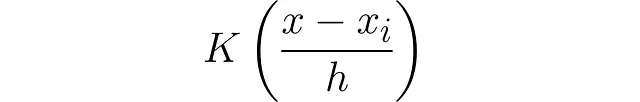
ただし、カーネル関数の下の面積は結果としてhで乗算されます。したがって、単位面積に戻すためにhで除算する必要があります:

希望するhの値を選択できます。以下はその動作の例です。
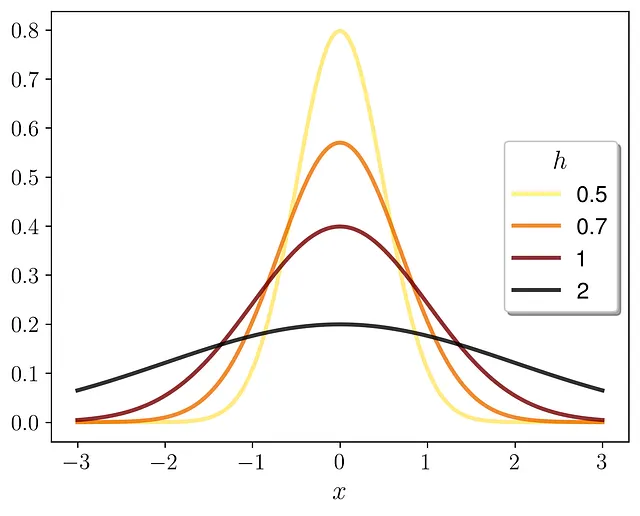
hが大きいほどPDFが広くなり、hが小さいほどPDFが狭くなります。
カーネル密度推定
複数の点に対してこの手法を拡張する方法を見るために、ダミーデータを考えてみましょう。
# datasetx = [1.33, 0.3, 0.97, 1.1, 0.1, 1.4, 0.4]# bandwidthh = 0.3最初のデータポイントに対しては、単純に次のように使用します:
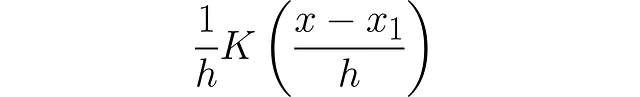

2番目のデータポイントに対しても同様に行います:
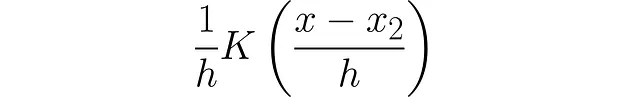
最初の2つの点のために1つのPDFを得るために、これら2つのPDFを結合する必要があります:
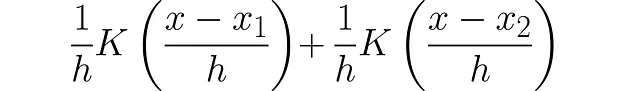
単位面積を持つ2つのPDFを追加したため、曲線の下の面積は2になります。これを1に戻すために、2で除算します:
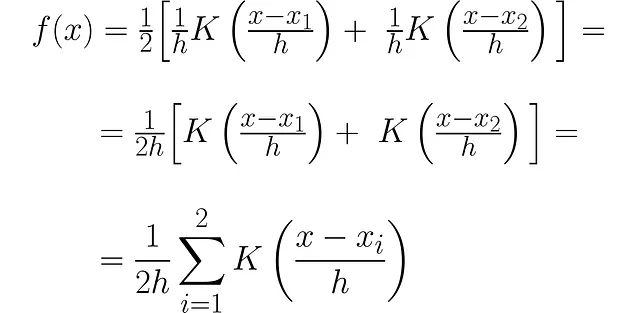
関数fの完全なシグネチャを使用することもできますが、読みやすくするためにf(x)を使用します。
これが2つのデータポイントに対して機能する方法です:
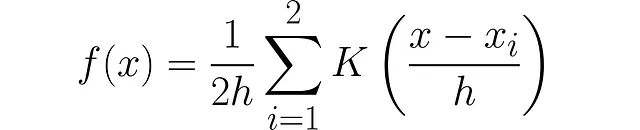
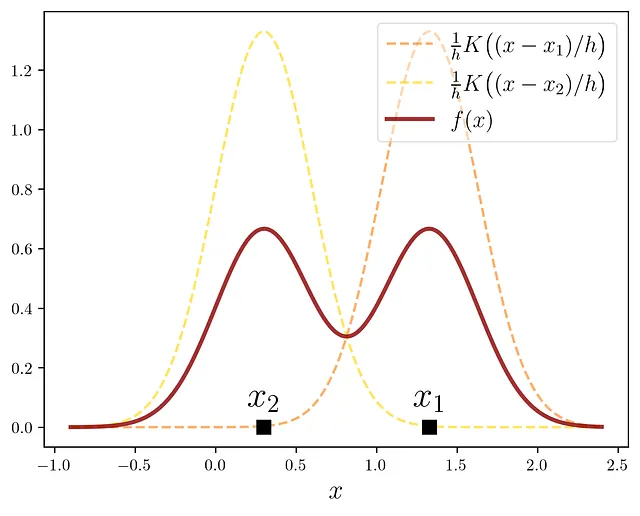
KDEへの最終的なステップは、n個のデータポイントを考慮に入れることです。
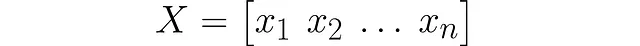
カーネル密度推定器は次のようになります:
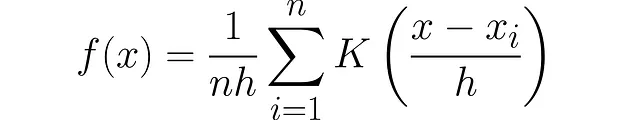
さあ、再び見つけたKDEで楽しんでみましょう。
import numpy as npimport matplotlib as plt# カーネル関数def K(x): return np.exp(-x**2/2)/np.sqrt(2*np.pi)# ダミーデータdataset = np.array([1.33, 0.3, 0.97, 1.1, 0.1, 1.4, 0.4])# KDEをプロットするためのx値の範囲x_range = np.linspace(dataset.min()-0.3, dataset.max()+0.3, num=600)# 実験のためのバンド幅の値H = [0.3, 0.1, 0.03]n_samples = dataset.size# 異なるバンド幅値の線のプロパティcolor_list = ['goldenrod', 'black', 'maroon']alpha_list = [0.8, 1, 0.8]width_list = [1.7,2.5,1.7]plt.figure(figsize=(10,4))# バンド幅値でループfor h, color, alpha, width in zip(H, color_list, alpha_list, width_list): total_sum = 0 # データポイントでループ for i, xi in enumerate(dataset): total_sum += K((x_range - xi) / h) plt.annotate(r'$x_{}$'.format(i+1), xy=[xi, 0.13], horizontalalignment='center', fontsize=18, ) y_range = total_sum/(h*n_samples) plt.plot(x_range, y_range, color=color, alpha=alpha, linewidth=width, label=f'{h}') plt.plot(dataset, np.zeros_like(dataset) , 's', markersize=8, color='black') plt.xlabel('$x$', fontsize=22)plt.ylabel('$f(x)$', fontsize=22, rotation='horizontal', labelpad=20)plt.legend(fontsize=14, shadow=True, title='$h$', title_fontsize=16)plt.show()
ここではガウシアンカーネルを使用していますが、他のカーネルも試してみることをお勧めします。一般的なカーネル関数の種類についてのレビューについては、この論文を参照してください。ただし、データセットが十分に大きい場合、カーネルの種類は最終的な出力にほとんど影響を与えません。
Pythonライブラリを使用したKDE
seabornライブラリは、データ分布の素敵な可視化を提供するためにKDEを使用しています。
import seaborn as snssns.set()fig, ax = plt.subplots(figsize=(10,4))sns.kdeplot(ax=ax, data=dataset, bw_adjust=0.3, linewidth=2.5, fill=True)# データポイントのプロットax.plot(dataset, np.zeros_like(dataset) + 0.05, 's', markersize=8, color='black')for i, xi in enumerate(dataset): plt.annotate(r'$x_{}$'.format(i+1), xy=[xi, 0.1], horizontalalignment='center', fontsize=18, )plt.show()
Scikit-learnは、同様の作業を行うためのKernelDensity関数を提供しています。
from sklearn.neighbors import KernelDensitydataset = np.array([1.33, 0.3, 0.97, 1.1, 0.1, 1.4, 0.4])# KernelDensityには2次元配列が必要ですdataset = dataset[:, np.newaxis]# データセットにKDEをフィットkde = KernelDensity(kernel='gaussian', bandwidth=0.1).fit(dataset)# プロットのためのx値の範囲x_range = np.linspace(dataset.min()-0.3, dataset.max()+0.3, num=600)# 各サンプルの対数尤度を計算log_density = kde.score_samples(x_range[:, np.newaxis])plt.figure(figsize=(10,4))# データポイントにラベルを付けるための処理for i, xi in enumerate(dataset): plt.annotate(r'$x_{}$'.format(i+1), xy=[xi, 0.07], horizontalalignment='center', fontsize=18)# KDE曲線の描画plt.plot(x_range, np.exp(log_density), color='gray', linewidth=2.5)# データポイントを表すボックスの描画plt.plot(dataset, np.zeros_like(dataset) , 's', markersize=8, color='black') plt.xlabel('$x$', fontsize=22)plt.ylabel('$f(x)$', fontsize=22, rotation='horizontal', labelpad=24)plt.show()
Scikit-learnのソリューションは、合成データサンプルを生成するための生成モデルとして使用することができるという利点があります。
# モデルからランダムなサンプルを生成synthetic_data = kde.sample(100)plt.figure(figsize=(10,4))# KDE曲線の描画plt.plot(x_range, np.exp(log_density), color='gray', linewidth=2.5)# データポイントを表すボックスの描画plt.plot(synthetic_data, np.zeros_like(synthetic_data) , 's', markersize=6, color='black', alpha=0.5) plt.xlabel('$x$', fontsize=22)plt.ylabel('$f(x)$', fontsize=22, rotation='horizontal', labelpad=24)plt.show()
結論
要約すると、KDEは基礎となるプロセスについての任意のデータから視覚的に魅力的なPDFを作成することができます。
KDEの特徴:
- これはカーネル関数と呼ばれる単一のタイプの構成要素からなる関数です。
- これはノンパラメトリックな推定量であり、その機能的な形式はデータポイントによって決定されます。
- 生成されるPDFの形状は、カーネルの帯域幅hの値に大きく影響を受けます。
- データセットに合わせるために、最適化技術は必要ありません。
KDEを多次元データに適用することは簡単です。しかし、これは別の話題です。
特に断りがない限り、すべての画像は著者によるものです。
参考文献
[1] S. Węglarczyk, Kernel density estimation and its application (2018), ITM web of conferences, vol. 23, EDP Sciences.
[2] Y. Soh, Y. Hae, A. Mehmood, R. H. Ashraf, I. Kim: Performance Evaluation of Various Functions for Kernel Density Estimation (2013), Open Journal of Applied Sciences, vol. 3, pp. 58–64.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
