オブジェクト指向データサイエンス:コードのリファクタリング
オブジェクト指向データサイエンス:コードのリファクタリング
効率的なコードとPythonのクラスで機械学習モデルとデータサイエンス製品を向上させる。
データサイエンティストにとって、コードは分析と意思決定のバックボーンです。機械学習モデルがソフトウェアに埋め込まれたり、膨大な情報を編成する複雑なデータパイプラインになるにつれて、クリーンで整理された、保守性の高いコードの開発が重要になってきます。オブジェクト指向プログラミング(OOP)は、データサイエンティストが変化する要件に敏捷に対応できる柔軟性と効率性を提供します。OOPはクラスという概念を導入し、データとそれを操作する操作をカプセル化するオブジェクトの設計図となります。このパラダイムの変化により、データサイエンティストは従来の関数型アプローチを超えて、モジュール化の設計とコードの再利用性を促進することができます。
この記事では、クラスの作成とオブジェクト指向のテクニックを使用してデータサイエンスのコードをリファクタリングすることの利点、およびこのアプローチがモジュール化と再利用性を向上させる方法について探っていきます。
データサイエンスにおけるクラスの力
従来のデータサイエンスのワークフローでは、関数がロジックをカプセル化する方法として使用されてきました。関数は繰り返しコードを最小化することができるため、しばしば十分です。しかし、プロジェクトが進化するにつれて、多数の関数を保守することは、ナビゲーション、デバッグ、スケーリングが困難なコードにつながる可能性があります。
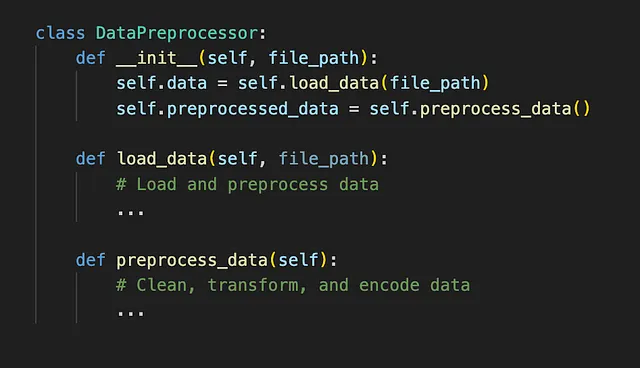
ここでクラスが重要な役割を果たします。クラスはオブジェクトを作成するための設計図であり、データとそれに作用する関数(メソッドと呼ばれる)をバンドルします。コードをクラスにまとめることで、開発者はいくつかの利点を得ることができます:
- ランダムウォークタスクにおける時差0(Temporal-Difference(0))と定数αモンテカルロ法の比較
- データ、効率化された:より良い製品、ワークフロー、チームの構築方法
- 「データパイプラインにおけるデータ契約の役割」
- モジュール化とカプセル化:関連する機能をまとめることで、クラスはモジュール化を促進します。各クラスは独自の属性(データ)とメソッド(関数)をカプセル化し、グローバル変数の汚染や名前の衝突のリスクを減らします。これにより、関心事の明確な分離が維持され、コードが理解や修正が容易になります。
- 再利用性:クラスは類似のタスクに対して一貫したインターフェースを提供することで再利用性を促進します。異なる部分で同様のタスクを実行する際に、クラスを使用することでコードの再利用が容易になります。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
