オフラインでのアクティブなポリシー選択
オフラインポリシー選択
強化学習(RL)は、最近では実際の問題に取り組むために非常に進歩を遂げており、オフラインRLによりさらに実用的になりました。環境との直接的な相互作用の代わりに、1つの事前に記録されたデータセットから多くのアルゴリズムを訓練することができます。しかし、手元のポリシーを評価する際には、オフラインRLのデータ効率の実用的な利点が失われます。
例えば、ロボットの操作装置を訓練する場合、ロボットのリソースは通常限られており、1つのデータセットでオフラインRLで多くのポリシーを訓練することは、オンラインRLと比較してデータ効率の利点をもたらします。各ポリシーの評価は高コストなプロセスであり、ロボットと何千回もの相互作用を必要とします。最適なアルゴリズム、ハイパーパラメータ、トレーニングステップ数を選択する際に、問題はすぐに扱いにくくなります。
ロボティクスなどの現実世界のアプリケーションにRLをより適用可能にするために、事前に記録されたデータセットを使用してポリシーを選択するための知的な評価手順であるアクティブオフラインポリシーセレクション(A-OPS)を提案します。A-OPSでは、事前に記録されたデータセットを活用し、現実の環境との限られた相互作用を使用して選択の品質を向上させます。
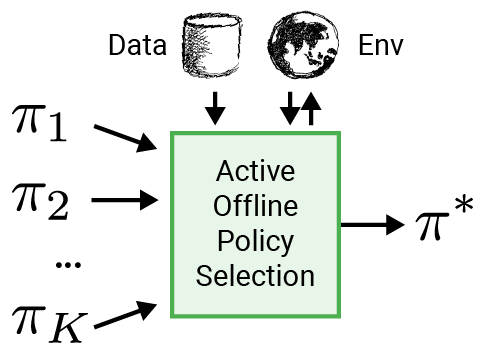
実際の環境との相互作用を最小限に抑えるために、3つの主要な機能を実装しています:
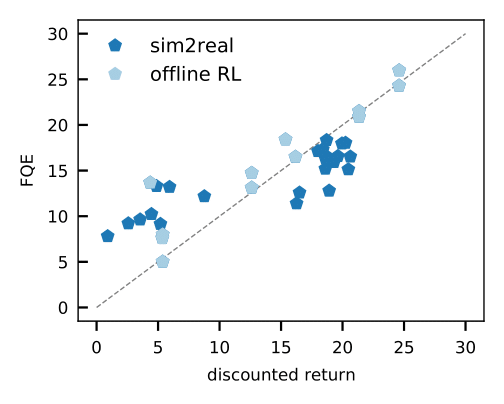
- FQE(Fitted Q-evaluation)などのオフポリシー評価を使用することで、オフラインデータセットに基づいて各ポリシーのパフォーマンスについて初期の推測を行うことができます。これは、実世界のロボット工学を含む多くの環境で、グランドトゥルースのパフォーマンスとよく相関しています。
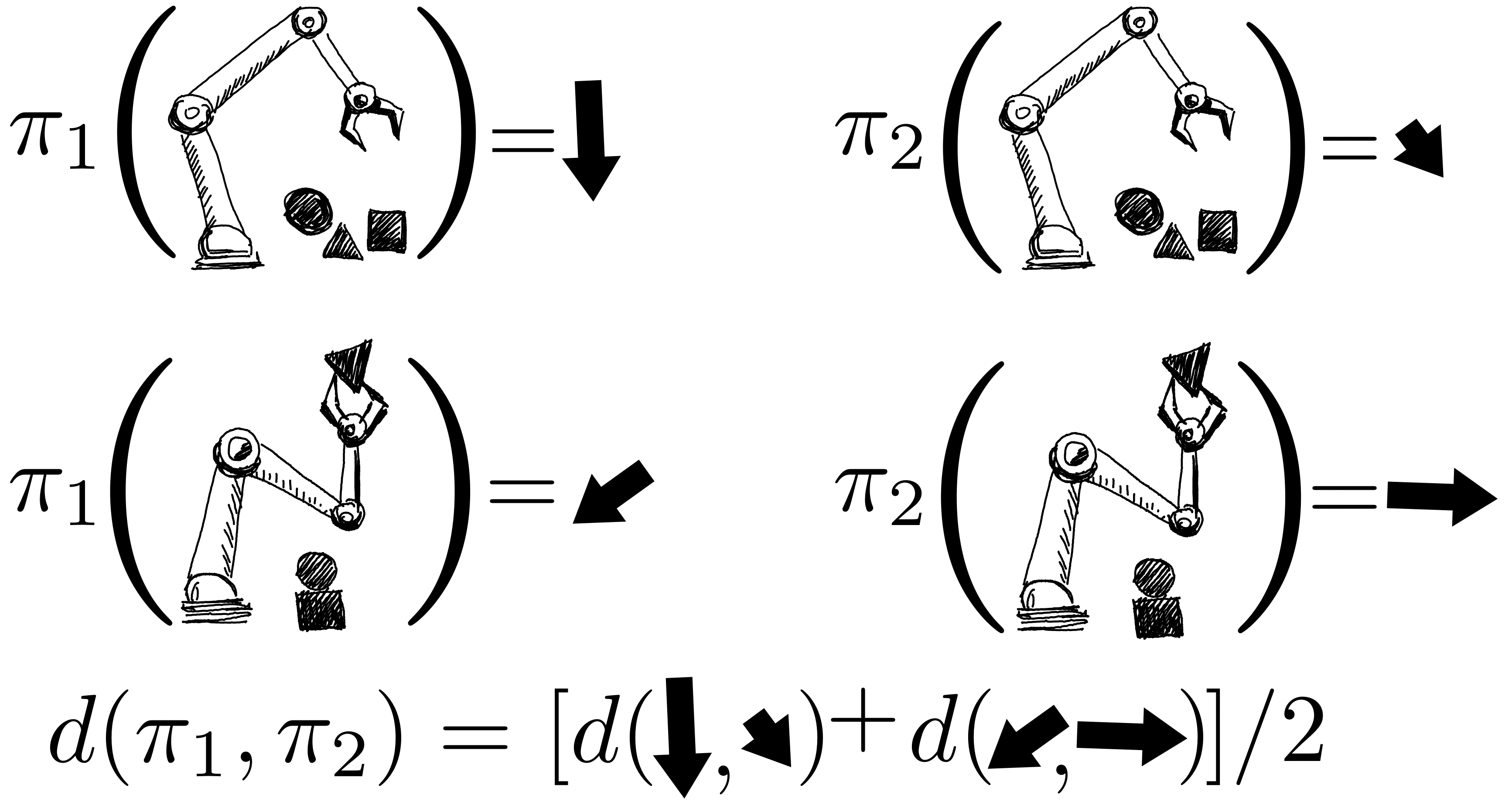
ポリシーのリターンは、ガウス過程を使用して共同モデル化されます。その観測値には、FQEスコアとロボットから収集された少数の新しいエピソードリターンが含まれます。1つのポリシーを評価すると、すべてのポリシーについての知識を得ることができます。なぜなら、ポリシーのペア間のカーネルを介してそれらの分布が相関していると仮定しているからです。カーネルは、ポリシーが似たようなアクション(例:ロボットのグリッパーを似たような方向に動かすなど)を取る場合、それらのポリシーは類似したリターンを持つ傾向があると仮定しています。
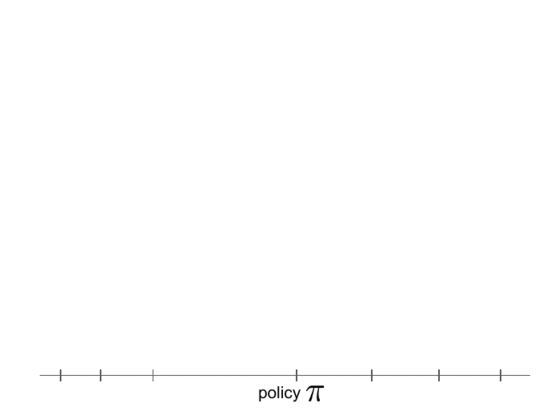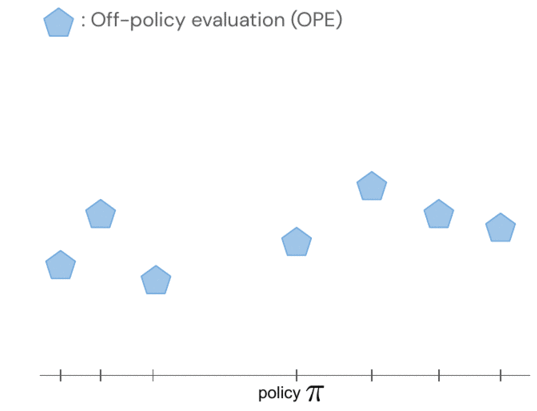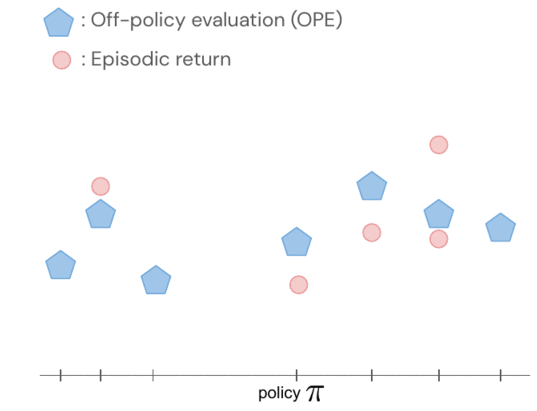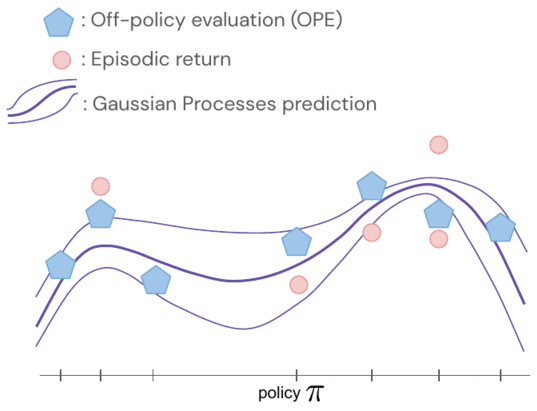
- よりデータ効率を向上させるために、ベイズ最適化を適用し、予測されたパフォーマンスが高く分散が大きい有望なポリシーを優先的に評価します。
私たちはdm-control、Atari、シミュレートされた環境、および実際のロボティクスなど、いくつかのドメインのいくつかの環境でこの手順を実証しました。A-OPSを使用すると、迅速に後悔を減らし、適度な数のポリシー評価で最適なポリシーを特定することができます。
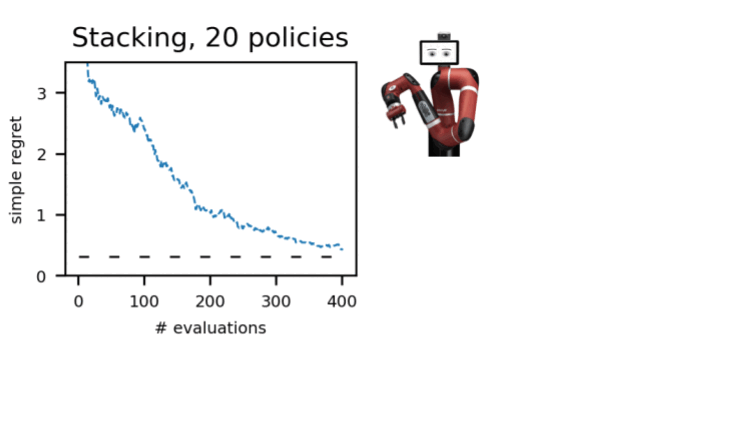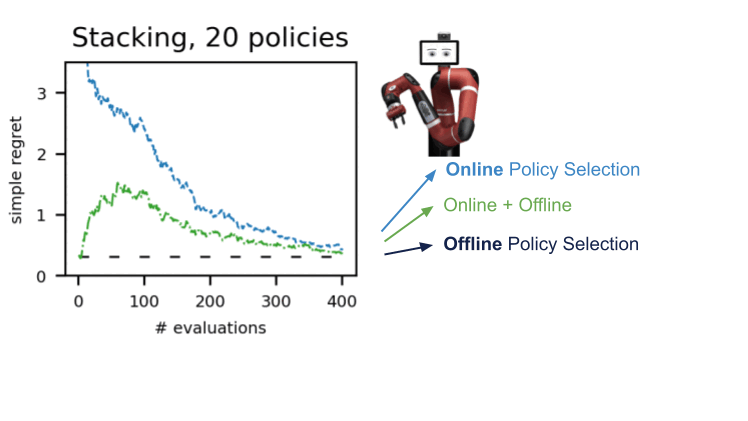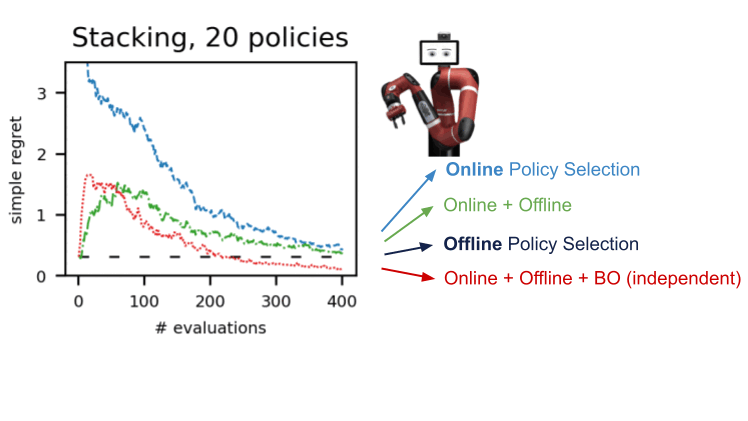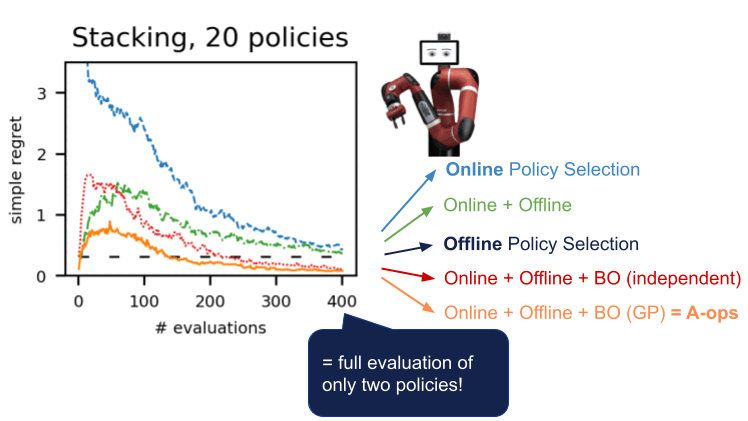
私たちの結果は、オフラインデータ、特別なカーネル、およびベイズ最適化を利用して、環境との少数の相互作用だけで効果的なオフラインポリシーの選択が可能であることを示唆しています。A-OPSのコードはオープンソースで、GitHubで利用可能で、試すためのサンプルデータセットも提供されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles




