自己対戦を通じて単純なゲームをマスターするエージェントのトレーニング
エージェントのトレーニング:自己対戦で単純なゲームをマスターする
ゲームをシミュレーションして結果を予測します。

はじめに
完全情報ゲームで優れるために必要なすべてが、ゲームのルールにすべて公開されていることは驚くべきことではありませんか?
残念ながら、私のような凡人にとっては、新しいゲームのルールを読むことは、複雑なゲームをプレイするための旅のごく一部に過ぎません。ほとんどの時間は、理想的には同じくらいの強さを持つプレーヤー(または私たちの弱点を露呈させるのに十分な忍耐力を持つより優れたプレーヤー)と対戦することに費やされます。頻繁に負け、できれば時々勝つことは、私たちが徐々に上手くプレイするように導く心理的な罰と報酬を提供します。
おそらく、それほど遠くない将来、言語モデルがチェスなどの複雑なゲームのルールを読み、最初から最高のレベルでプレイすることができるようになるでしょう。それまでの間に、私はより控えめな挑戦を提案します:自己対戦による学習。
このプロジェクトでは、以前のバージョンの自身がプレイした試合の結果を観察することで、エージェントをトレーニングして、完全情報の2プレーヤーゲームをプレイするように学習させます。エージェントは、任意のゲームの状態に対して値(ゲームの予想結果)を近似します。さらなる挑戦として、複雑なゲームには管理できないため、エージェントは状態空間のルックアップテーブルを保持することは許されません。
- メタAIは、122の言語に対応した初の並列読解評価ベンチマーク「BELEBELE」をリリースしました
- 機械学習:中央化とスケーリングの目的を理解する
- 「AIは本当に低品質な画像から顔の詳細を復元できるのでしょうか? DAEFRとは何か:品質向上のためのデュアルブランチフレームワークに出会う」
SumTo100の解決
ゲーム
今回取り上げるゲームはSumTo100です。このゲームの目標は、1から10の数値を足して合計が100になることです。以下がルールです:
- 合計を0に初期化します。
- 最初のプレーヤーを選択します。2人のプレーヤーが交互にプレイします。
- 合計が100未満の間:
- プレーヤーは1から10までの数値を選択します。選択した数値は100を超えないように合計に追加されます。
- 合計が100未満の場合、もう一方のプレーヤーがプレイします(つまり、ポイント3の最初に戻ります)。
4. 最後の数値を追加したプレーヤー(合計が100に到達)が勝ちます。

このようなシンプルなゲームから始めることには多くの利点があります:
- 状態空間には101個の可能な値しかありません。
- 状態は1Dグリッド上にプロットすることができます。この特異性により、エージェントが学習した状態価値関数を1D棒グラフとして表現することができます。
- 最適な戦略が既知です:n ∈ {0, 1, 2, …, 9} に対して合計が11n + 1になるようにする
最適戦略の状態価値を視覚化することができます:
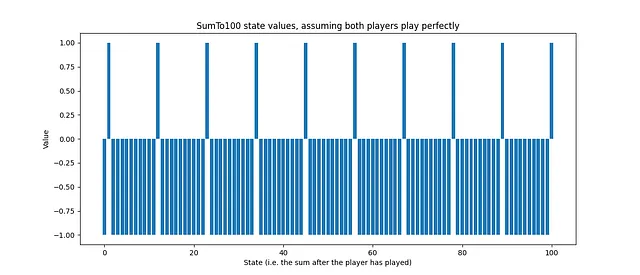
ゲームの状態は、エージェントがターンを終えた後の合計です。値が1.0の場合、エージェントは勝つことが確実です(または勝ちました)、-1.0の場合、エージェントは負けることが確実です(対戦相手が最適にプレイすると仮定した場合)。中間の値は推定されたリターンを表します。たとえば、状態値が0.2の場合、わずかにプラスの状態を示し、状態値が-0.8の場合は、負ける可能性が高いことを示します。
コードに入りたい場合、全体のトレーニング手順を実行するスクリプトは、このリポジトリ内のlearn_sumTo100.shです。そうでない場合は、エージェントが自己対戦によって学習する方法の高レベルな説明をご覧ください。
ランダムプレーヤーによってプレイされるゲームの生成
エージェントには、それ自体の以前のバージョンによってプレイされたゲームから学習してもらいたいのですが、最初のイテレーションでは、エージェントはまだ何も学んでいないため、ランダムプレーヤーによってプレイされるゲームをシミュレートする必要があります。各ターンで、プレーヤーはゲームのルールをエンコードするゲーム権限(ゲームルールをエンコードするクラス)から現在のゲーム状態を与えられ、合法な手のリストを受け取ります。ランダムプレーヤーは、このリストからランダムに手を選択します。
図2は、2人のランダムプレーヤーによってプレイされたゲームの例です:

この場合、2番目のプレーヤーが100の合計に到達して勝ちました。
エージェントは、ゲームの状態を入力とし、このゲームの予想されるリターンを出力するニューラルネットワークにアクセスできるようにします。エージェントは、与えられた状態(エージェントがプレーする前の状態)に対して、合法な行動とそれらに対応する候補状態のリストを取得します(確定的な遷移を持つゲームのみ考慮します)。
図3は、エージェント、対戦相手(移動選択メカニズムが不明な相手)、およびゲーム権限の相互作用を示しています:

この設定では、エージェントは回帰ニューラルネットワークに依存してゲームの状態の予測されるリターンを予測します。ニューラルネットワークがどの候補手が最も高いリターンをもたらすかを予測できるほど良い場合、エージェントのプレイはより良くなります。
ランダムにプレイされた対戦のリストは、最初のトレーニングのデータセットを提供します。図2の例のゲームを取ると、プレーヤー1が行った手を罰することが目的です。なぜなら、その行動が敗北につながったからです。最後のアクションによって生じる状態は-1.0の値を持ちます。なぜなら、それが相手に勝つことを許したからです。その他の状態は、エージェントが到達した最後の状態との距離dに応じて、γᵈという割引率で負の値を割り引かれます。γ(ガンマ)は割引率であり、[0, 1]の範囲内の数値であり、ゲームの進化における不確実性を表します。初期の決定を最後の決定ほど厳しく罰することはしたくありません。図4は、プレーヤー1が行った決定に関連する状態値を示しています:

ランダムなゲームは、その目標となる予想リターンを持つ状態を生成します。たとえば、合計が97に達すると、目標となる予想リターンは-1.0であり、合計が73になると、目標となる予想リターンは-γ³です。状態の半分はプレーヤー1の視点を持ち、もう半分はプレーヤー2の視点を持ちます(ただし、SumTo100の場合は関係ありません)。エージェントが勝利で終わるゲームでは、対応する状態は同様に割引された正の値を取得します。
ゲームのリターンを予測するエージェントのトレーニング
トレーニングを開始するために必要なものはすべて揃っています:ニューラルネットワーク(2層のパーセプトロンを使用します)と(状態、予測されるリターン)のペアのデータセット。予測される予想リターンの損失の進化を見てみましょう:

ランダムなプレイヤーによって行われたゲームの結果に対して、ニューラルネットワークがあまり予測力を示さないことに驚く必要はありません。
ニューラルネットワークは何も学んでいないのでしょうか?
幸いにも、状態は0から100の間の数値の1次元グリッドとして表現することができるため、最初のトレーニングラウンド後のニューラルネットワークの予測リターンをプロットし、図1の最適な状態値と比較することができます:
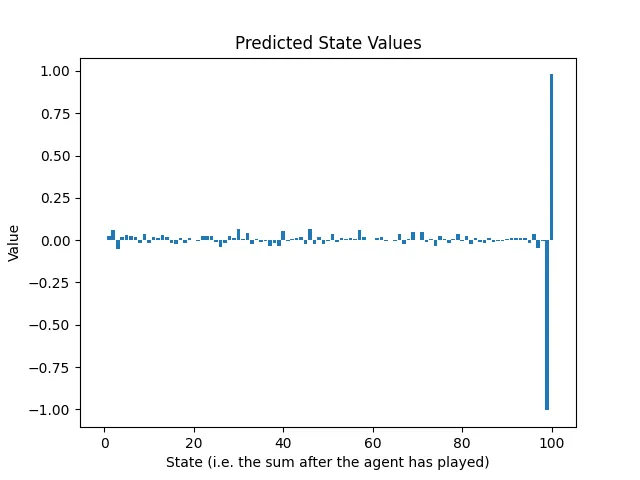
実際には、ランダムなゲームの混沌の中で、ニューラルネットワークは2つのことを学びました:
- 合計が100に達することができるなら、それを行いなさい。それはゲームの目標であるため、良い知識です。
- 合計が99になると、必ず負けます。実際、この状況では、相手は唯一の合法的な行動を持ち、その行動はエージェントにとっての敗北につながります。
ニューラルネットワークは基本的にゲームを終了することを学びました。
もう少し上手にプレイするためには、エージェントのコピー同士でプレイされたゲームをシミュレーションして、データセットを再構築する必要があります。同じゲームが生成されないように、プレーヤーは少しランダムにプレイします。うまく機能するアプローチは、ε-グリーディアルゴリズムを使用してムーブを選択し、最初のムーブではε = 0.5、ゲームの残りではε = 0.1を使用することです。
より良くなるためにトレーニングループを繰り返す
両方のプレーヤーは今や100に達する必要があることを知っているため、90から99の間の合計は罰せられるべきです。なぜなら、相手はその機会を利用して試合に勝つことができるからです。この現象は、2回目のトレーニング後の予測状態値で見ることができます:
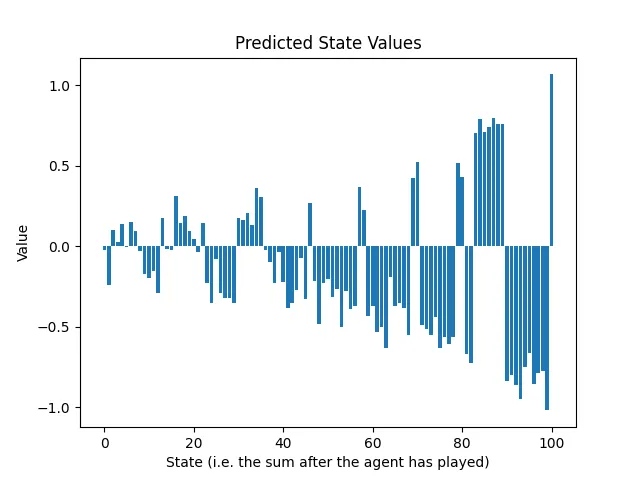
パターンが浮かび上がっています。最初のトレーニングラウンドはニューラルネットワークに最後のアクションについて情報を提供し、2回目のトレーニングラウンドはその前のアクションについて情報を提供します。ゲーム内のアクションの数だけ、ゲームの生成と予測へのトレーニングのサイクルを繰り返す必要があります。
以下のアニメーションは、25回のトレーニングラウンド後の予測状態値の進化を示しています:
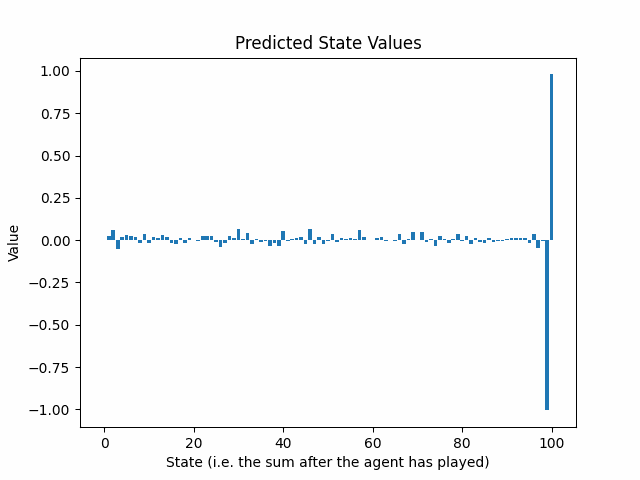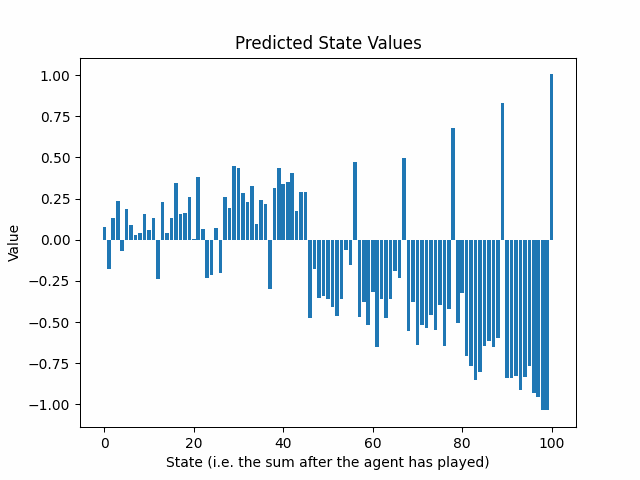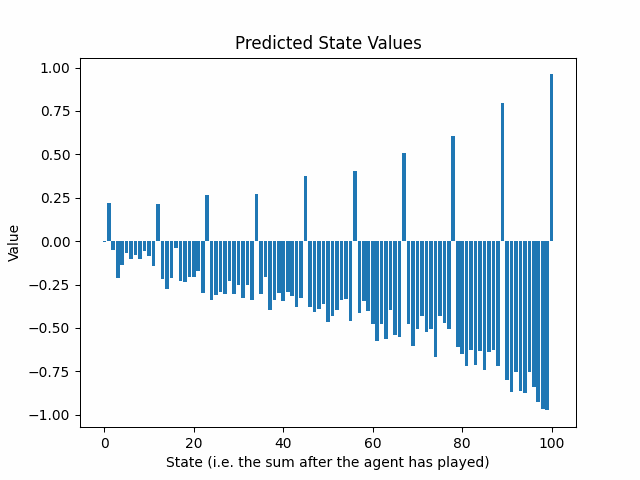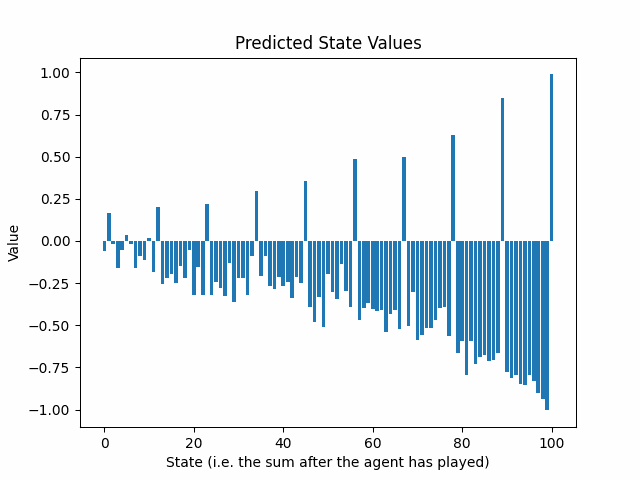
予測リターンの信頼区間はゲームの終わりから始まる方向に指数的に減少しています。これは問題ですか?
この現象には2つの要素が寄与しています:
- γはゲームの終わりから離れるにつれて、目標の期待リターンを直接減衰させます。
- ε-グリーディアルゴリズムはプレーヤーの行動にランダム性を導入し、結果を予測しにくくします。非常に高い損失の場合に備えてゼロに近い値を予測するインセンティブがあります。ただし、ランダム性は望ましいです。ニューラルネットワークが単一のプレイラインを学習することは望ましくありません。エージェントと相手の両方からのミスや予期しない良いムーブを目撃させたいのです。
実際には、ゲームSumTo100において、与えられた状態の合法な手の中で、比較可能なスケールを共有する値を比較するため、これは問題ではないはずです。値のスケールは、貪欲な手を選択する際には問題ではありません。
結論
私たちは、二人のプレイヤーが関与し、状態から次の状態への遷移が確定的で、アクションが与えられる完全情報のゲームをマスターできるエージェントを作成することに挑戦しました。手動での戦略や戦術のコーディングは許されませんでした:すべてはセルフプレイによって学習する必要がありました。
私たちは、エージェント同士を対戦させ、生成されたゲームの予測されるリターンを予測するための回帰ニューラルネットワークのトレーニングを行うことで、SumTo100というシンプルなゲームを解決することができました。
得られた洞察は、ゲームの複雑さの次の段階に向けて私たちをよく準備してくれましたが、それについては次の投稿でお話しします! 😊
お時間いただき、ありがとうございました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「マイクロソフトが、自社の新しい人工知能搭載スマートバックパックに関する特許を申請」
- このAI論文は、大規模な言語モデルにおける長期的な会話の一貫性を向上させるための再帰的なメモリ生成手法を提案しています
- 「フラミンゴとDALL-Eはお互いを理解しているのか?イメージキャプションとテキストから画像生成モデルの相互共生を探る」
- 自動小売りチェックアウトは、ラベルのない農産物をどのように認識するのか? PseudoAugmentコンピュータビジョンアプローチとの出会い
- 専門家モデルを用いた機械学習:入門
- 「Amazon SageMakerでのRayを使用した効果的な負荷分散」
- 『ご要望に合わせたチャット:ソフトウェア要件に応用した生成AI(LLM)の旅』





