エンティティの解決実装の複雑さ
エンティティ解決の複雑さ
データマッチング作業時の典型的な課題の実践例

エンティティの解決とは、データセット内の2つ以上のレコードが同じ実世界のエンティティ(通常は人物や会社)を参照するかどうかを判断するプロセスです。一見、エンティティの解決は比較的単純なタスクのように見えるかもしれません。例えば、同じ人の2つの写真が与えられた場合、小さな子供でもかなり高い精度で同じ人物かどうかを判断できます。コンピュータでも同じです。名前、住所、メールアドレスなどの属性を含む2つのレコードを比較することは簡単に行えます。しかし、このトピックを掘り下げれば掘り下げるほど、より困難になります。様々なマッチングアルゴリズムを評価する必要があり、数百万または数十億のレコードを扱うことは二次の複雑さを意味します。リアルタイムやデータ削除のユースケースについては言及するまでもありません。
曖昧なテキストマッチング
まずは、有名な画家ビンセント・ファン・ゴッホの2つのレコードを比較してみましょう。それともファン・ゴーだったのでしょうか?

2つ目のレコードにはいくつかのエラーがあります(1世紀後に生まれたことやメールアドレスなど)。名前のスペルが間違っていたり、生年月日が入れ替わっていたり、郵便番号が欠落していたり、メールアドレスがわずかに異なっていたりします。
- 「S4 HANAとDomoでSQLを使用してデータ分析を超高速化する:機械学習の視点から」
- 「研究者がオンラインプライバシーについて子供たちと話すためのベストプラクティスを探求する」
- ハッカーは、主要なセキュリティテストでAIを悪用する方法を探索しています
では、これらの値を比較するにはどうすればよいでしょうか?例えば、名前が等しい場合、これらの値の単純な文字列比較で十分です。しかし、それは事実ではないため、より高度な曖昧なマッチングが必要です。テキストベースの曖昧なマッチングには多くの異なるアルゴリズムがあり、大まかに3つのグループに分けることができます。音韻アルゴリズムは、テキストの発音の類似性に焦点を当てます。最も有名なアルゴリズムはSoundexとMetaphoneで、主に英語のテキストに使用されますが、ドイツ語の場合はケルン音韻学(Kölner Phonetik)などのバリエーションも存在します。テキスト距離アルゴリズムは、テキストが他のテキストに到達するために変更する必要がある文字数を定義します。Levenshtein距離とハミング距離は、このグループのよく知られたアルゴリズムです。コサイン類似度やジャカード指数などの類似度アルゴリズムは、テキストの構造的な類似性を計算し、類似性をパーセンテージで表します。
この記事では、名前に対してLevenshtein距離のみを使用する非常にシンプルなアプローチを使用します。この例および以下の例では、プログラミング言語としてgolangを使用し、可能な限り既存のライブラリを使用します。これをPython、Java、または他の言語に変換することは簡単です。また、名前属性のマッチングのみを行います。この記事の目的では、属性を追加したり、設定可能にすることはありません。
package mainimport ( "fmt" "github.com/hbollon/go-edlib")type Record struct { ID int Name string City string}func matches(a, b Record) bool { distance := edlib.LevenshteinDistance(a.Name, b.Name) return distance <= 3 && a.City == b.City}func main() { a := Record{ Name: "Vincent Van Gogh", City: "Paris", } b := Record{ Name: "Vince Van Gough", City: "Paris", } if matches(a, b) { fmt.Printf("%s と %s はおそらく同一の人物です\n", a.Name, b.Name) } else { fmt.Printf("%s と %s はおそらく同一の人物ではありません\n", a.Name, b.Name) }}Go Playgroundで試す: https://go.dev/play/p/IJtanpXEdyu
2つの名前間のLevenshtein距離は正確に3です。これは、最初の名前に「en」、最後の名前に「u」という3つの追加文字があるためです。ただし、これは特定の入力に対しては機能します。しかし、完璧とは言えません。例えば、名前が「Joe Smith」と「Amy Smith」の場合、Levenshtein距離も3ですが、明らかに同じ人物ではありません。距離アルゴリズムと音韻アルゴリズムを組み合わせることで問題を解決できるかもしれませんが、それはこの記事の範囲外です。
ルールベースのアプローチでは、MLベースのアプローチではなく、ビジネスの成功に最も重要なのは、使用ケースに最適な結果をもたらすアルゴリズムを選ぶことです。ここに、ほとんどの時間を費やすべきです。残念ながら、私たちが今発見するように、エンティティ解決エンジンを自分で開発する場合、それらのルールを最適化することからあなたを邪魔する他の多くの要素があります。
ナイーブエンティティ解決
2つのレコードを比較する方法を知ったので、互いに一致するすべてのレコードを見つける必要があります。最も簡単なアプローチは、単に各レコードを他のすべてのレコードと比較することです。この例では、ランダムに選択した名前と都市で作業します。名前には最大3つのエラーを強制します(任意の文字をxで置き換えます)。
var firstNames = [...]string{"Wade", "Dave", "Seth", "Ivan", "Riley", "Gilbert", "Jorge", "Dan", "Brian", "Roberto", "Daisy", "Deborah", "Isabel", "Stella", "Debra", "Berverly", "Vera", "Angela", "Lucy", "Lauren"}var lastNames = [...]string{"Smith", "Jones", "Williams", "Brown", "Taylor"}func randomName() string { fn := firstNames[rand.Intn(len(firstNames))] ln := lastNames[rand.Intn(len(lastNames))] name := []byte(fmt.Sprintf("%s %s", fn, ln)) errors := rand.Intn(4) for i := 0; i < errors; i++ { name[rand.Intn(len(name))] = 'x' } return string(name)}var cities = [...]string{"Paris", "Berlin", "New York", "Amsterdam", "Shanghai", "San Francisco", "Sydney", "Cape Town", "Brasilia", "Cairo"}func randomCity() string { return cities[rand.Intn(len(cities))]}func loadRecords(n int) []Record { records := make([]Record, n) for i := 0; i < n; i++ { records[i] = Record{ ID: i, Name: randomName(), City: randomCity(), } } return records}func compare(records []Record) (comparisons, matchCount int) { for _, a := range records { for _, b := range records { if a == b { continue // don't compare with itself } comparisons++ if matches(a, b) { fmt.Printf("%s と %s はおそらく同じ人です\n", a.Name, b.Name) matchCount++ } } } return comparisons, matchCount}func main() { records := loadRecords(100) comparisons, matchCount := compare(records) fmt.Printf("%d 回の比較を行い、%d 件の一致を見つけました\n", comparisons, matchCount)}Go Playgroundで試す:https://go.dev/play/p/ky80W_hk4S3
次のような出力が表示されるはずです(ランダムなデータに一致がない場合は複数回実行する必要がある場合があります):
Daisy Williams と Dave Williams はおそらく同じ人ですDeborax Browx と Debra Brown はおそらく同じ人ですRiley Brown と RxxeyxBrown はおそらく同じ人ですDan Willxams と Dave Williams はおそらく同じ人です9900 回の比較を行い、16 件の一致を見つけました運が良ければ、「Daisy」と「Dave」などの一致しないものも取得できます。これは、短い名前に対する単一の曖昧なアルゴリズムとしては高すぎるLevenshtein距離を使用しているためです。自由に改善してください。
パフォーマンス的には、結果を得るために必要な9,900回の比較が実際の問題です。入力の量を倍にすると、必要な比較の量はおおよそ4倍になります。200レコードには39,800回の比較が必要です。わずか100,000レコードの少量の場合、約100億回の比較が必要になります。システムのサイズに関係なく、データの量が増えるにつれて、システムが受け入れ可能な時間でこれを完了できなくなるポイントがあります。
素早いですがほとんど役に立たない最適化は、すべての組み合わせを2回比較しないことです。AとBを比較するか、BとAを比較するかは問題ではありません。ただし、これにより必要な比較の量が2倍になるだけで、二次的な成長による影響は無視できます。
ブロッキングによる複雑さの削減
作成したルールを見てみると、都市が異なる場合は一致しないことがすぐにわかります。これらの比較は完全に無駄であり、防止すべきです。似ていると思われるレコードを共通のバケットに入れ、それ以外のレコードを別のバケットに入れることは、エンティティ解決においてブロッキングと呼ばれます。私たちは都市をブロッキングキーとして使用したいので、実装は非常にシンプルです。
func block(records []Record) map[string][]Record { blocks := map[string][]Record{} for _, record := range records { blocks[record.City] = append(blocks[record.City], record) } return blocks}func main() { records := loadRecords(100) blocks := block(records) comparisons := 0 matchCount := 0 for _, blockRecords := range blocks { c, m := compare(blockRecords) comparisons += c matchCount += m } fmt.Printf("比較を%d回行い、%d個の一致を見つけました\n", comparisons, matchCount)}Go Playgroundで試してみる: https://go.dev/play/p/1z_j0nhX-tU
結果は同じですが、先ほどよりも比較は約10分の1になっています。これは、10個の異なる都市があるためです。実際のアプリケーションでは、都市のバリアンスがはるかに高いため、この効果は非常に大きくなります。さらに、各ブロックは他のブロックとは独立して処理できます。たとえば、同じサーバーまたは異なるサーバーで並列に処理できます。
適切なブロッキングキーを見つけることはそれ自体の課題です。都市のような属性を使用すると、均等な分布にならない可能性があります。その結果、巨大なブロック(例:大都市)が他のすべてのブロックよりもはるかに長い時間がかかる場合や、都市に微小なスペルの誤りが含まれているために有効な一致と見なされなくなる場合があります。複数の属性を使用したり、音韻キーまたはq-gramをブロッキングキーとして使用したりすることで、これらの問題を解決できますが、ソフトウェアの複雑さが増します。
一致からエンティティへ
これまでのところ、レコードについて言えることは、2つのレコードが一致しているかどうかだけです。非常に基本的なユースケースではこれで十分かもしれません。ただし、ほとんどの場合、同じエンティティに属するすべての一致を知りたいと思うでしょう。これは、AがB、C、Dと一致する単純なスターパターンから、AがBと一致し、BがCと一致し、CがDと一致するチェーンパターン、非常に複雑なグラフパターンまでさまざまなものです。このようなトランジティブなレコードリンケージは、データ全体が単一のサーバーのメモリに収まる場合には、連結成分アルゴリズムを使用して簡単に実装できます。再び、実世界のアプリケーションでは、これははるかに困難です。
func compare(records []Record) (comparisons int, edges [][2]int) { for _, a := range records { for _, b := range records { if a == b { continue // 自分自身との比較はスキップ } comparisons++ if matches(a, b) { edges = append(edges, [2]int{a.ID, b.ID}) } } } return comparisons, edges}func connectedComponents(edges [][2]int) [][]int { components := map[int][]int{} nextIdx := 0 idx := map[int]int{} for _, edge := range edges { a := edge[0] b := edge[1] aIdx, aOk := idx[a] bIdx, bOk := idx[b] switch { case aOk && bOk && aIdx == bIdx: // 同じ連結成分内 continue case aOk && bOk && aIdx != bIdx: // 2つの連結成分をマージ components[nextIdx] = append(components[aIdx], components[bIdx]...) delete(components, aIdx) delete(components, bIdx) for _, x := range components[nextIdx] { idx[x] = nextIdx } nextIdx++ case aOk && !bOk: // bをaの連結成分に追加 idx[b] = aIdx components[aIdx] = append(components[aIdx], b) case bOk && !aOk: // aをbの連結成分に追加 idx[a] = bIdx components[bIdx] = append(components[bIdx], a) default: // aとbで新しい連結成分を作成 idx[a] = nextIdx idx[b] = nextIdx components[nextIdx] = []int{a, b} nextIdx++ } } cc := make([][]int, len(components)) i := 0 for k := range components { cc[i] = components[k] i++ } return cc}func main() { records := loadRecords(100) blocks := block(records) comparisons := 0 edges := [][2]int{} for _, blockRecords := range blocks { c, e := compare(blockRecords) comparisons += c edges = append(edges, e...) } cc := connectedComponents(edges) fmt.Printf("比較を%d回行い、%d個の一致と%d個のエンティティを見つけました\n", comparisons, len(edges), len(cc)) for _, component := range cc { names := make([]string, len(component)) for i, id := range component { names[i] = records[id].Name } fmt.Printf("次のエンティティを見つけました: %s(%sから)\n", strings.Join(names, ", "), records[component[0]].City) }}Go Playgroundで試してみてください:https://go.dev/play/p/vP3tzlzJ2LN
接続されたコンポーネント関数は、すべてのエッジを反復処理し、新しいコンポーネントを作成したり、既存のコンポーネントに新しいIDを追加したり、2つのコンポーネントを1つにマージしたりします。結果は次のようになります:
1052回の比較が行われ、6つの一致が見つかり、2つのエンティティが見つかりました。次のエンティティが見つかりました:カイロ出身のイヴァン・スミス、イクサン・スミス、イヴァックス・スミック。次のエンティティが見つかりました:ケープタウン出身のブライアン・ウィリアムズ、ブライアン・ウィリアムズ。これらのエッジを保持することで、いくつかの利点が得られます。これらを使用して、エンティティを理解可能かつ説明可能にし、エンティティのレコードがどのように接続されているかを示す素晴らしいUIで説明することができます。また、リアルタイムのエンティティ解決システムで作業している場合、データが削除された場合にエンティティを分割するためにこれらを使用することができます。また、レコードだけでなく、グラフニューラルネットワーク(GNN)を構築する際にも使用でき、より良いML結果をもたらします。
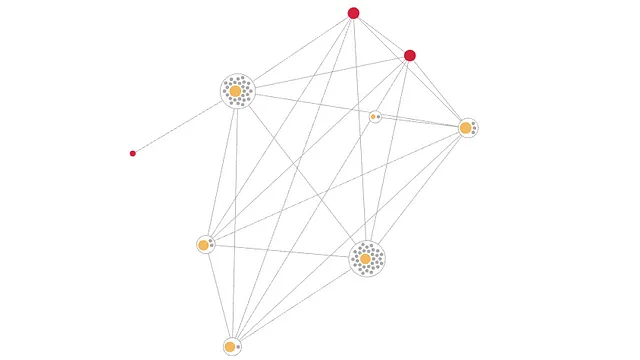
エッジから生じる問題の1つは、非常に類似したレコードが多い場合に発生することです。たとえば、AがBと一致し、BがCと一致する場合、使用されるルールによっては、CもAと一致する場合があります。D、E、Fなども既存のレコードと一致する場合、エッジの数が増えて処理しにくくなる問題が再び発生します。
ブロッキングバケットを構築した方法を覚えていますか?驚きです!非常に類似したデータの場合、すべてが数個の巨大なバケットに入るため、計算のパフォーマンスが再び劇的に低下します。複数の属性からバケットを作成するという前のアドバイスに従った場合でも同じです。
このような非同一の重複の典型的な例は、同じ店で定期的に注文するが、ゲストアクセス(申し訳ありません、素敵な顧客IDはありません)を使用している人です。その人はほとんど常に同じ配送先住所を使用し、自分の名前を正しく書けることができます。したがって、これらのレコードは安定したシステムパフォーマンスを確保するために特別な方法で扱われるべきですが、それはそれ自体のトピックです。
獲得した知識にあまり興奮しすぎて、自分で解決策を実装し始めたいと思う前に、さっと夢を打ち砕きましょう。これをリアルタイムで行う際の課題についてまだ話していません。常に最新のエンティティが必要ではないと思っている場合でも、リアルタイムなアプローチはさらなる価値を提供します:同じ計算を何度も繰り返す必要がなく、新しいデータのみに対して行うことができます。一方で、実装ははるかに複雑になります。ブロッキングを行いたいですか?新しいレコードを所属するバケットのすべてのレコードと比較しますが、それには時間がかかり、むしろインクリメンタルバッチと考えられるかもしれません。また、それが最終的に完了するまでには、すでに処理待ちの多くの新しいレコードがあります。接続されたコンポーネントを使用してエンティティを計算したいですか?もちろん、全体のグラフをメモリに保持し、新しいエッジを追加するだけです。ただし、新しいレコードによりマージされた2つのエンティティを追跡するのを忘れないでください。
ですので、まだ自分でこれを実装しようとする意欲があります。そして、(この場合)賢明な決断として、エッジを保存せず、リアルタイムをサポートしないという決断をしました。したがって、すべてのデータで最初のエンティティ解決バッチジョブを正常に実行しました。時間がかかりましたが、1か月に1回しか行わないので、問題ありません。おそらく、あなたがデータ保護責任者を見かけ、GDPRのクレームに基づいてデータセットからその1人を削除するように言われるのはその時です。したがって、単一の削除されたエンティティについて再びすべてのバッチジョブを実行します。
結論
エンティティの解決は最初は比較的簡単に見えるかもしれませんが、重要な技術的な課題が含まれています。これらの課題のいくつかは簡略化および/または無視できますが、他の課題はパフォーマンスの向上のために解決する必要があります。
元の記事はhttps://tilores.ioで公開されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
