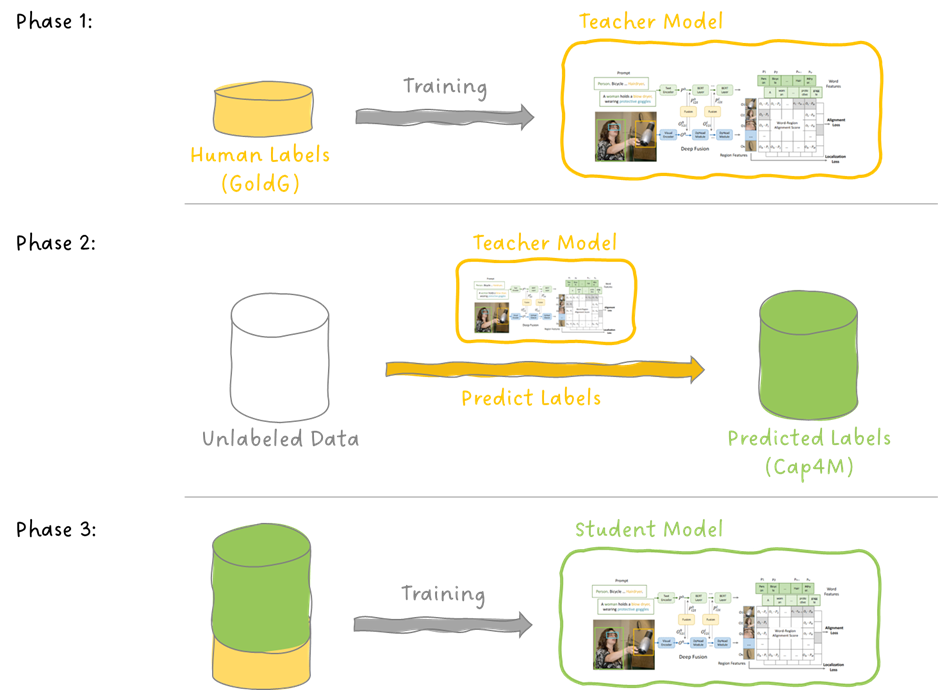
エンコーダー・デコーダーモデルのための事前学習済み言語モデルチェックポイントの活用
エンコーダー・デコーダーモデルの学習済み言語モデルチェックポイントの活用
![]()
Transformerベースのエンコーダーデコーダーモデルは、Vaswani et al.(2017)で提案され、最近ではLewis et al.(2019)、Raffel et al.(2019)、Zhang et al.(2020)、Zaheer et al.(2020)、Yan et al.(2020)などにおいて大きな関心を集めています。
BERTやGPT2と同様に、大規模な事前学習済みエンコーダーデコーダーモデルは、Lewis et al.(2019)、Raffel et al.(2019)などのさまざまなシーケンス対シーケンスのタスクにおいて性能を大幅に向上させることが示されています。しかし、エンコーダーデコーダーモデルの事前学習には膨大な計算コストがかかるため、そのようなモデルの開発は主に大企業や研究所に限定されています。
Sascha Rothe、Shashi Narayan、Aliaksei Severynによる「シーケンス生成タスクのための事前学習済みチェックポイントの活用」(2020)では、事前学習済みのエンコーダーやデコーダーのみのチェックポイント(例:BERT、GPT2)でエンコーダーデコーダーモデルを初期化して、コストのかかる事前学習をスキップする方法が紹介されています。著者らは、このようなウォームスタートされたエンコーダーデコーダーモデルが、T5やPegasusなどの大規模な事前学習済みエンコーダーデコーダーモデルと比較して、複数のシーケンス対シーケンスのタスクで競争力のある結果をもたらすことを示しています。
このノートブックでは、エンコーダーデコーダーモデルをウォームスタートする方法の詳細を説明し、Rothe et al.(2020)に基づいた実用的なヒントを提供し、最後に🤗Transformersを使用してエンコーダーデコーダーモデルをウォームスタートするための完全なコード例を説明します。
このノートブックは以下の4つのパートに分かれています:
- イントロダクション – NLPにおける事前学習言語モデルとエンコーダーデコーダーモデルのウォームスタートの必要性についての短い概要。
- エンコーダーデコーダーモデルのウォームスタート(理論) – エンコーダーデコーダーモデルがどのようにウォームスタートされるかについての具体的な説明。
- エンコーダーデコーダーモデルのウォームスタート(分析) – 「シーケンス生成タスクのための事前学習済みチェックポイントの活用」の要約
-
- エンコーダーデコーダーモデルをウォームスタートするために効果的なモデルの組み合わせは何か?タスクごとにどのように異なるか?
-
- 🤗Transformersを使用したエンコーダーデコーダーモデルのウォームスタート(実践) –
EncoderDecoderModelフレームワークを使用して、Transformerベースのエンコーダーデコーダーモデルをウォームスタートする方法を詳細に説明した完全なコード例。
Transformerベースのエンコーダーデコーダーモデルについてのこのブログ記事を読んでいただくことを強くお勧めします。
エンコーダーデコーダーモデルのウォームスタートに関する背景について説明することから始めましょう。
イントロダクション
最近、事前学習言語モデル1 {}^1 1が自然言語処理(NLP)の分野で革命を起こしました。
最初の事前学習言語モデルは、再帰ニューラルネットワーク(RNN)に基づいており、Dai et al.(2015)で提案されました。Daiらは、ラベルのないデータをRNNベースのモデルで事前学習し、その後、特定のタスクで微調整2 {}^2 2することで、ランダムに初期化されたモデルを直接そのタスクにトレーニングするよりも良い結果が得られることを示しました。しかし、事前学習言語モデルがNLPで広く受け入れられるようになったのは2018年のことです。PetersらによるELMOとHowardらによるULMFitは、自然言語理解(NLU)のさまざまなタスクで最先端の成果を大幅に改善した最初の事前学習言語モデルでした。数か月後、OpenAIとGoogleは、RadfordらによるGPTとDevlinらによるBERTという名前の、トランスフォーマーベースの事前学習言語モデルを公開しました。トランスフォーマーベースの言語モデルの効率の向上により、GPT2とBERTは大量の未ラベルのテキストデータで事前学習することができました。事前学習されたBERTとGPTは、ごくわずかな微調整しか必要とせず、3 {}^3 3以上のNLUタスクで最先端の結果を達成することが示されました。
事前学習言語モデルがタスクに依存しない知識を効果的にタスク固有の知識に転送する能力は、NLUにとって大きな促進剤となりました。以前はエンジニアや研究者がゼロから言語モデルをトレーニングする必要がありましたが、今では大規模な事前学習言語モデルの公開チェックポイントをごく少ないコストと時間で微調整することができます。これにより、産業界で数百万ドルを節約することができ、研究においてもより速いプロトタイピングとより良いベンチマークが可能となります。
事前学習済みの言語モデルは、NLUタスクにおいて新たなパフォーマンスレベルを確立し、ますますそのような事前学習済みの言語モデルを活用した改善されたNLUシステムの研究が行われています。ただし、単独のBERTやGPTモデルは、シーケンス間タスク(例:テキスト要約、機械翻訳、文の言い換えなど)においてはあまり成功していません。
シーケンス間タスクは、入力シーケンスX 1 : n \mathbf{X}_{1:n} X 1 : n から予め不明な出力長さm m m の出力シーケンスY 1 : m \mathbf{Y}_{1:m} Y 1 : m へのマッピングと定義されます。したがって、シーケンス間モデルは、入力シーケンスX 1 : n \mathbf{X}_{1:n} X 1 : n に対して出力シーケンスY 1 : m \mathbf{Y}_{1:m} Y 1 : m の条件付き確率分布を定義する必要があります:
p θ モデル(Y 1 : m ∣ X 1 : n) . p_{\theta_{\text{モデル}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n}). p θ モデル (Y 1 : m ∣ X 1 : n ) .
一般性を失うことなく、n n n 単語の入力単語列はベクトルシーケンスX 1 : n = x 1 , … , x n \mathbf{X}_{1:n} = \mathbf{x}_1, \ldots, \mathbf{x}_n X 1 : n = x 1 , … , x n で表され、m m m 単語の出力単語列はY 1 : m = y 1 , … , y m \mathbf{Y}_{1:m} = \mathbf{y}_1, \ldots, \mathbf{y}_m Y 1 : m = y 1 , … , y m と表されます。
BERTとGPT2がシーケンス間タスクのモデリングにどのように適合するかを見てみましょう。
BERT
BERTはエンコーダーのみのモデルであり、入力シーケンスX 1 : n \mathbf{X}_{1:n} X 1 : n をコンテキスト化された符号化されたシーケンスX ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n にマッピングします:
f θ BERT : X 1 : n → X ‾ 1 : n . f_{\theta_{\text{BERT}}}: \mathbf{X}_{1:n} \to \mathbf{\overline{X}}_{1:n}. f θ BERT : X 1 : n → X 1 : n .
BERTのコンテキスト化された符号化されたシーケンスX ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n は、NLU分類タスク(感情分析、自然言語推論など)のための分類層によってさらに処理することができます。これを行うために、分類層(通常はプーリング層に続くフィードフォワード層)がBERTの上に最終層として追加され、コンテキスト化された符号化されたシーケンスX ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n をクラスc c c にマッピングします:
f θ p,c : X ‾ 1 : n → c . f_{\theta{\text{p,c}}}: \mathbf{\overline{X}}_{1:n} \to c. f θ p,c : X 1 : n → c .
事前学習済みのBERTモデルθ BERT \theta_{\text{BERT}} θ BERT の上にプーリング層と分類層(θ p,c \theta_{\text{p,c}} θ p,c と定義される)を追加し、その後モデル全体{ θ p,c , θ BERT } \{\theta_{\text{p,c}}, \theta_{\text{BERT}}\} { θ p,c , θ BERT } を微調整することで、さまざまなNLUタスクで最先端のパフォーマンスを発揮することが示されています。DevlinらによるBERTを参照してください。
BERTを可視化しましょう。
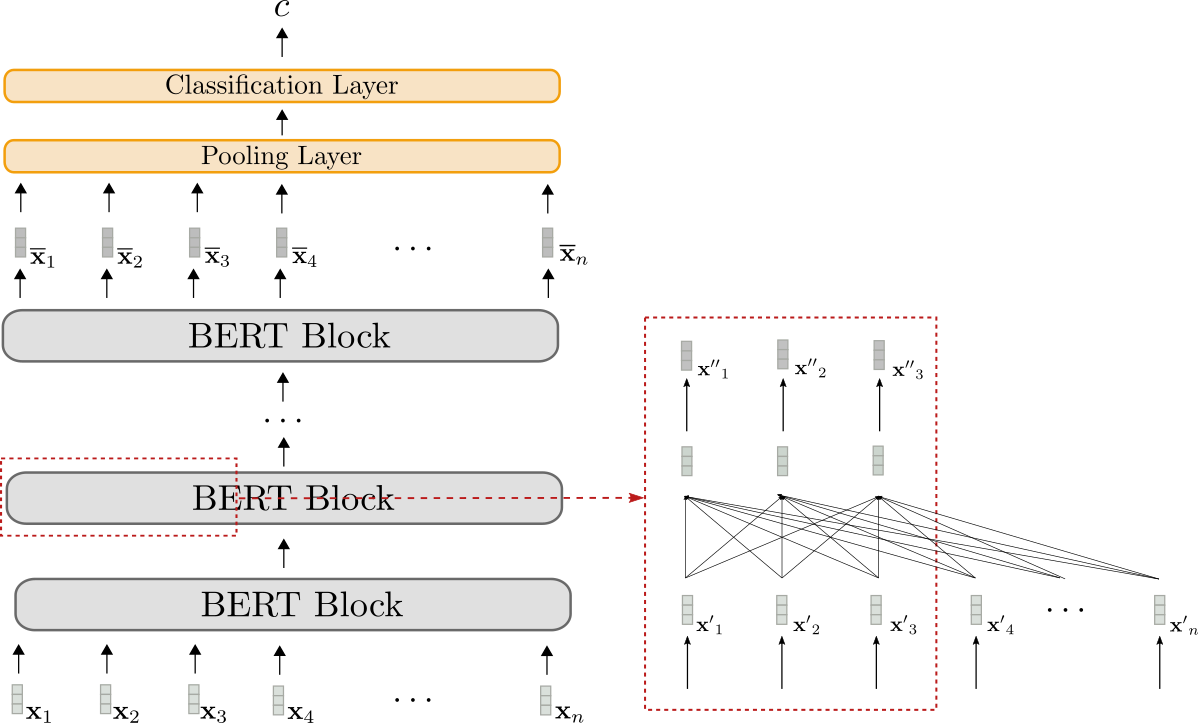
モデルBERTはグレーで表示されます。モデルは複数のBERTブロックを積み重ねます。各ブロックは双方向の自己注意層(赤いボックスの下部に表示されます)と2つの順伝播層(赤いボックスの上部に短く表示されます)で構成されています。
各BERTブロックは、入力シーケンスx ′ 1 , … , x ′ n \mathbf{x’}_1, \ldots, \mathbf{x’}_n x ′ 1 , … , x ′ n (薄いグレーで表示されます)をより「洗練された」コンテキスト化された出力シーケンスx ′ ′ 1 , … , x ′ ′ n \mathbf{x”}_1, \ldots, \mathbf{x”}_n x ′ ′ 1 , … , x ′ ′ n (やや濃いグレーで表示されます)に変換するために双方向の自己注意を使用します 4 {}^4 4 。最終的なBERTブロックのコンテキスト化された出力シーケンス、つまりX ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n は、上述のようにタスク固有の分類層(オレンジで表示されます)を追加することで単一の出力クラスc c cにマッピングできます。
エンコーダのみのモデルは、入力シーケンスを事前に既知の出力長の出力シーケンスにマッピングすることしかできません。結論として、出力次元は入力シーケンスに依存しないため、シーケンス間の変換タスクにエンコーダのみのモデルを使用することは不利であり、実用的ではありません。
エンコーダのみのモデルについては、BERTのアーキテクチャは、エンコーダ-デコーダモデルのエンコーダ部分のアーキテクチャとまったく対応しています。詳細については、「エンコーダ」セクションを参照してください。
GPT2
GPT2はデコーダのみのモデルであり、単方向(つまり「因果的」)の自己注意を使用して、入力シーケンスY 0 : m − 1 \mathbf{Y}_{0: m – 1} Y 0 : m − 1 1 {}^1 1から「次の単語」のロジットベクトルシーケンスL 1 : m \mathbf{L}_{1:m} L 1 : m を定義します:
f θ GPT2 : Y 0 : m − 1 → L 1 : m . f_{\theta_{\text{GPT2}}}: \mathbf{Y}_{0: m – 1} \to \mathbf{L}_{1:m}. f θ GPT2 : Y 0 : m − 1 → L 1 : m .
ロジットベクトルL 1 : m \mathbf{L}_{1:m} L 1 : m をsoftmax操作で処理することにより、モデルは単語シーケンスY 1 : m \mathbf{Y}_{1:m} Y 1 : m の確率分布を定義できます。正確には、単語シーケンスY 1 : m \mathbf{Y}_{1:m} Y 1 : m の確率分布は、m − 1 m-1 m − 1 の条件付き「次の単語」の分布に因数分解できます:
p θ GPT2 ( Y 1 : m ) = ∏ i = 1 m p θ GPT2 ( y i ∣ Y 0 : i − 1 ) . p_{\theta_{\text{GPT2}}}(\mathbf{Y}_{1:m}) = \prod_{i=1}^{m} p_{\theta_{\text{GPT2}}}(\mathbf{y}_i | \mathbf{Y}_{0:i-1}). p θ GPT2 ( Y 1 : m ) = i = 1 ∏ m p θ GPT2 ( y i ∣ Y 0 : i − 1 ) . p θ GPT2 ( y i ∣ Y 0 : i − 1 ) p_{\theta_{\text{GPT2}}}(\mathbf{y}_i | \mathbf{Y}_{0:i-1}) p θ GPT2 ( y i ∣ Y 0 : i − 1 )は、前のすべての単語y 0 , … , y i − 1 \mathbf{y}_0, \ldots, \mathbf{y}_{i-1} y 0 , … , y i − 1 3 {}^3 3を与えたときの次の単語y i \mathbf{y}_i y i の確率分布であり、ロジットベクトルl i \mathbf{l}_i l i に適用されるsoftmax操作で定義されます。まとめると、以下の式が成り立ちます。
p θ gpt2 ( y i ∣ Y 0 : i − 1 ) = Softmax ( l i ) = Softmax ( f θ GPT2 ( Y 0 : i − 1 ) ) .
詳細については、エンコーダーデコーダーブログ記事のデコーダーセクションを参照してください。
さて、GPT2を可視化してみましょう。
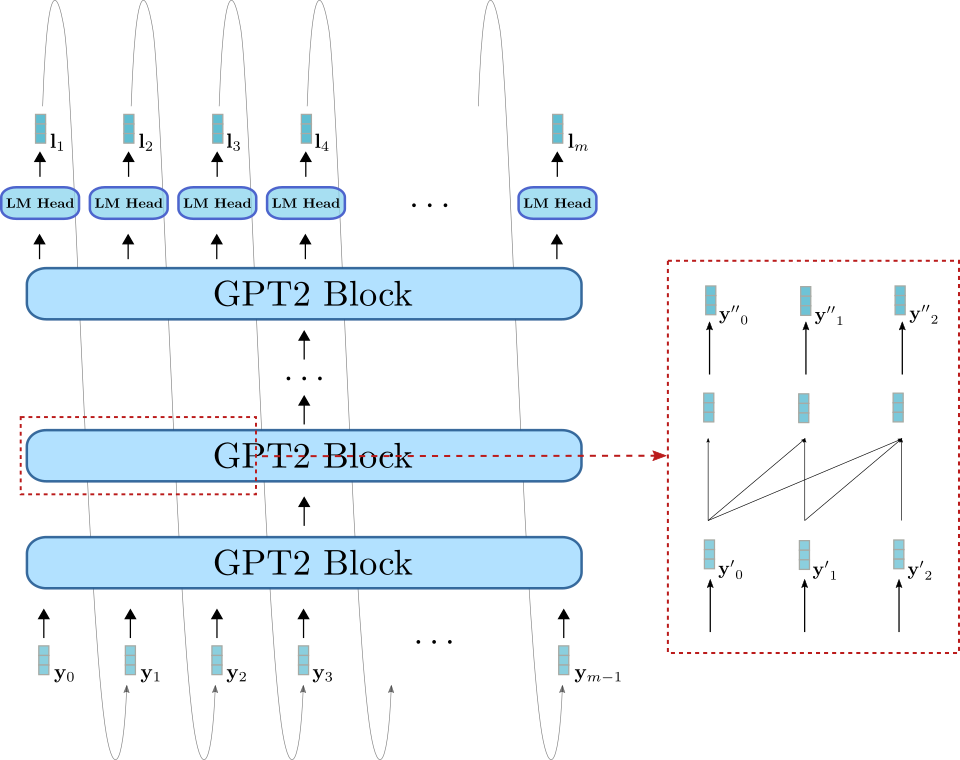
BERTと同様に、GPT2はGPT2ブロックのスタックで構成されています。ただし、BERTブロックとは異なり、GPT2ブロックは一方向の自己注意を使用して、いくつかの入力ベクトル y ′ 0 , … , y ′ m − 1 \mathbf{y’}_0, \ldots, \mathbf{y’}_{m-1} y ′ 0 , … , y ′ m − 1 (右下のライトブルーで表示)を出力ベクトルシーケンス y ′ ′ 0 , … , y ′ ′ m − 1 \mathbf{y”}_0, \ldots, \mathbf{y”}_{m-1} y ′ ′ 0 , … , y ′ ′ m − 1 (右上の濃い青で表示)に変換します。GPT2ブロックスタックに加えて、LMヘッドと呼ばれる線形層もあります。この層は、最終的なGPT2ブロックの出力ベクトルをロジットベクトル l 1 , … , l m \mathbf{l}_1, \ldots, \mathbf{l}_m l 1 , … , l m にマッピングします。先ほど説明したように、ロジットベクトル l i \mathbf{l}_i l i は新しい入力ベクトル y i \mathbf{y}_i y i のサンプリングに使用できます。
GPT2は主にオープンドメインのテキスト生成に使用されます。まず、入力プロンプト Y 0 : i − 1 \mathbf{Y}_{0:i-1} Y 0 : i − 1 がモデルに与えられ、条件付き分布 p θ gpt2 ( y ∣ Y 0 : i − 1 ) p_{\theta_{\text{gpt2}}}(\mathbf{y} | \mathbf{Y}_{0:i-1}) p θ gpt2 ( y ∣ Y 0 : i − 1 )が生成されます。次に、次の単語 y i \mathbf{y}_i y i が分布からサンプリングされ(グラフ上の灰色の矢印で表されます)、その結果が入力に追加されます。自己回帰的な方法で、単語 y i + 1 \mathbf{y}_{i+1} y i + 1 は p θ gpt2 ( y ∣ Y 0 : i ) p_{\theta_{\text{gpt2}}}(\mathbf{y} | \mathbf{Y}_{0:i}) p θ gpt2 ( y ∣ Y 0 : i )からサンプリングされます。
したがって、GPT2は言語生成に非常に適していますが、条件付き生成にはあまり適していません。入力プロンプト Y 0 : i − 1 \mathbf{Y}_{0: i-1} Y 0 : i − 1 をシーケンス入力 X 1 : n \mathbf{X}_{1:n} X 1 : n と同じに設定することで、GPT2は条件付き生成に非常に適して使用できます。ただし、モデルのアーキテクチャには、Raffel et al.(2019)の17ページで説明されているように、エンコーダーデコーダーアーキテクチャと比較して基本的な欠点があります。要するに、一方向の自己注意は、シーケンス入力 X 1 : n \mathbf{X}_{1:n} X 1 : n のモデルの表現を不必要に制限するため、x i \mathbf{x}_i x i は x i + 1 , ∀ i ∈ { 1 , … , n } \mathbf{x}_{i+1}, \forall i \in \{1,\ldots, n\} x i + 1 , ∀ i ∈ { 1 , … , n } に依存することはできません。
エンコーダーデコーダー
エンコーダーのみのモデルは、出力の長さをあらかじめ知る必要があるため、シーケンス間のタスクには適していないと思われます。デコーダーのみのモデルは、シーケンス間のタスクには適していますが、上記で説明したように特定のアーキテクチャ上の制約もあります。
シーケンス間のタスクに対処するための現在の主流なアプローチは、トランスフォーマーベースのエンコーダーデコーダーモデルです。これはしばしばseq2seqトランスフォーマーモデルとも呼ばれます。エンコーダーデコーダーモデルは、Vaswani et al. (2017)で導入され、それ以来、単体の言語モデル(つまり、デコーダーのみのモデル)よりもシーケンス間のタスクで優れたパフォーマンスを発揮することが示されています(例:Raffel et al. (2020))。基本的に、エンコーダーデコーダーモデルは、BERTなどの単体のエンコーダーと、GPT2などの単体のデコーダーモデルの組み合わせです。トランスフォーマーベースのエンコーダーデコーダーモデルの正確なアーキテクチャの詳細については、このブログ記事を参照してください。
今では、BERTやGPTなどの大規模な事前学習済みの単体のエンコーダーとデコーダーモデルの無料のチェックポイントが利用可能であり、多くのNLUタスクのパフォーマンスを向上させ、トレーニングコストを削減できることがわかっています。また、エンコーダーデコーダーモデルは、基本的には単体のエンコーダーとデコーダーモデルの組み合わせです。これは自然に、単体のモデルのチェックポイントをエンコーダーデコーダーモデルにどのように活用できるか、および特定のシーケンス間のタスクで最もパフォーマンスが優れているモデルの組み合わせが何かという問題を提起します。
2020年、Sascha Rothe、Shashi Narayan、Aliaksei Severynは、彼らの論文シーケンス生成タスクに事前学習済みのチェックポイントを活用するで、まさにこの問題を調査しました。この論文は、さまざまなエンコーダーデコーダーモデルの組み合わせとファインチューニングの技術について、後で詳しく学びます。
事前学習済みの単体のモデルのチェックポイントを使用してエンコーダーデコーダーモデルを構成することは、エンコーダーデコーダーモデルのウォームスタートと定義されます。次のセクションでは、エンコーダーデコーダーモデルのウォームスタートが理論上どのように機能するか、理論を🤗Transformersで実践する方法、さらにはパフォーマンスを向上させるための実践的なヒントについて説明します。
1 {}^1 事前学習済み言語モデルは、次のように定義されます:
- 非ラベル付きのテキストデータでトレーニングされた、つまりタスクに依存しない非教示的な方法で、
- 入力単語のシーケンスをコンテキスト依存の埋め込みに変換するニューラルネットワークです。例えば、Mikolov et al. (2013)の連続単語の袋モデルやskip-gramモデルは、埋め込みがコンテキストに依存しないため、事前学習済み言語モデルとは見なされません。
2 {}^2 ファインチューニングは、事前学習済み言語モデルの重みで初期化されたモデルのタスク固有のトレーニングとして定義されます。
3 {}^3 入力ベクトル y 0 \mathbf{y}_0 y 0 は、最初の出力単語 y 1 \mathbf{y}_1 y 1 を予測するために必要なBOS \text{BOS} BOS 埋め込みベクトルに対応します。
4 {}^4 一般性を失わないために、方程式と図を混乱させないために、正規化層は除外します。
5 {}^5 「デコーダーのみ」モデル(GPT2など)ではなぜ単方向のセルフアテンションが使用され、サンプリングが正確にどのように機能するかの詳細については、エンコーダーデコーダーブログ記事のデコーダーセクションを参照してください。
エンコーダーデコーダーモデルのウォームスタート(理論)
イントロダクションを読んだ後、エンコーダーのみモデルとデコーダーのみモデルについて理解しました。エンコーダーデコーダーモデルアーキテクチャは、基本的には単体のエンコーダーモデルと単体のデコーダーモデルの組み合わせであることに気付きました。これが、単体のモデルのチェックポイントからエンコーダーデコーダーモデルをウォームスタートする方法についての疑問を引き起こしました。
エンコーダーデコーダーモデルをウォームスタートするための複数の可能性があります。以下の方法があります:
- エンコーダーとデコーダーの両方をエンコーダーのみモデルのチェックポイント(例:BERT)から初期化する
- エンコーダーの部分をエンコーダーのみモデルのチェックポイント(例:BERT)から初期化し、デコーダーの部分をデコーダーのみのチェックポイント(例:GPT2)から初期化する
- エンコーダーの部分のみをエンコーダーのみモデルのチェックポイントで初期化する
- デコーダーの部分のみをデコーダーのみモデルのチェックポイントで初期化する
以下では、可能性1と2に焦点を当てます。可能性3と4は、最初の2つを理解した後は自明です。
エンコーダー-デコーダーモデルの復習
まず、エンコーダー-デコーダーアーキテクチャの簡単な復習をしましょう。
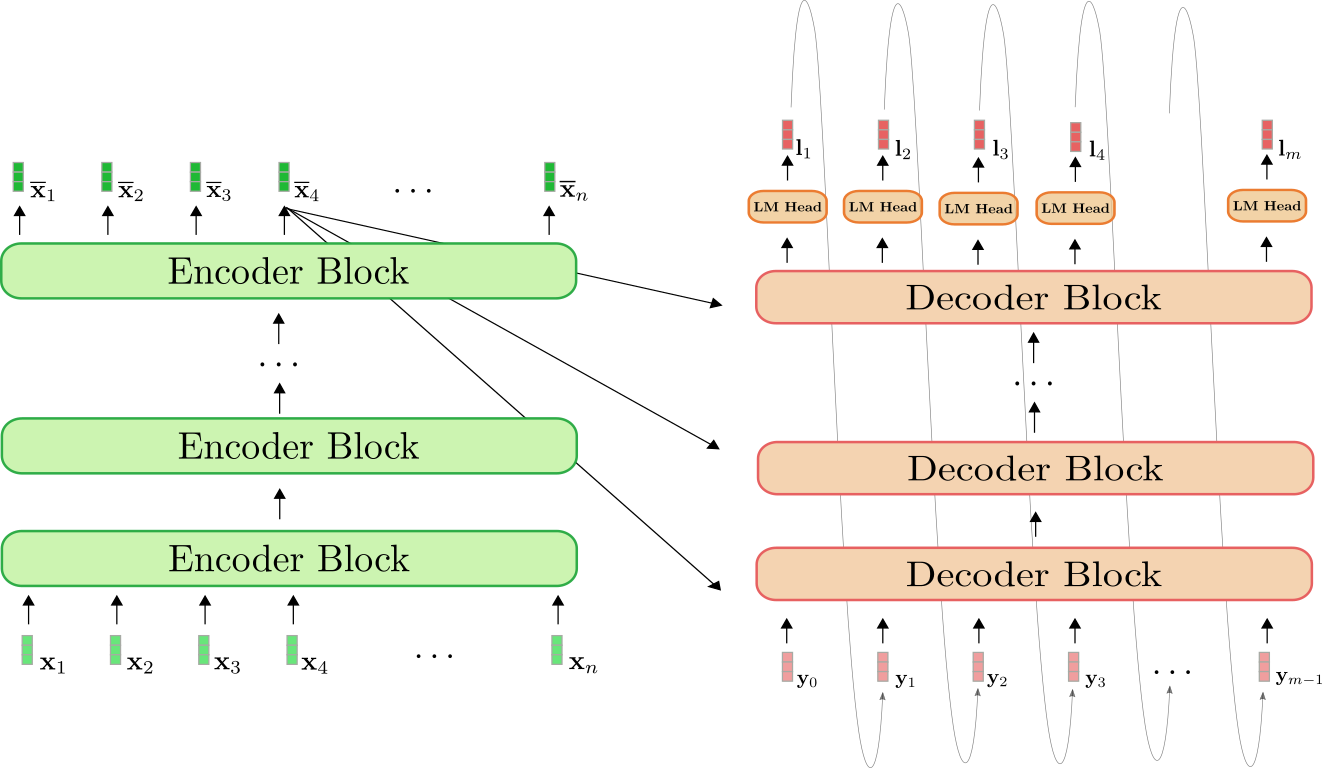
エンコーダー(緑色で表示)は、エンコーダーブロックのスタックです。各エンコーダーブロックは、双方向の自己注意層と2つの順伝播層1 {}^1 1 から構成されています。デコーダー(オレンジ色で表示)は、デコーダーブロックのスタックであり、LMヘッドと呼ばれる密な層に続きます。各デコーダーブロックは、単方向の自己注意層、クロス注意層、および2つの順伝播層から構成されています。
エンコーダーは、入力シーケンス X 1 : n \mathbf{X}_{1:n} X 1 : n をBERTと同じ方法でコンテキスト化された符号化されたシーケンス X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n にマッピングします。デコーダーは、コンテキスト化された符号化されたシーケンス X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n と目標シーケンス Y 0 : m − 1 \mathbf{Y}_{0:m-1} Y 0 : m − 1 を使用して、ロジットベクトル L 1 : m \mathbf{L}_{1:m} L 1 : m にマッピングします。GPT2に類似して、ロジットは、ソフトマックス操作を用いて入力シーケンス X 1 : n \mathbf{X}_{1:n} X 1 : n に依存する目標シーケンス Y 1 : m \mathbf{Y}_{1:m} Y 1 : m の分布を定義するために使用されます。
<p数学的な用語で言うと、まず、条件付き分布はBayesの法則により次のように m − 1 m – 1 m − 1 個の次の単語 y i \mathbf{y}_i y i の条件付き分布に分解されます。
p θ enc, dec ( Y 1 : m ∣ X 1 : n ) = p θ dec ( Y 1 : m ∣ X ‾ 1 : n ) = ∏ i = 1 m p θ dec ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) , with X ‾ 1 : n = f θ enc ( X 1 : n ) . p_{\theta_{\text{enc, dec}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n}) = p_{\theta_{\text{dec}}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^m p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i -1}, \mathbf{\overline{X}}_{1:n}), \text{ with } \mathbf{\overline{X}}_{1:n} = f_{\theta_{\text{enc}}}(\mathbf{X}_{1:n}). p θ enc, dec ( Y 1 : m ∣ X 1 : n ) = p θ dec ( Y 1 : m ∣ X 1 : n ) = i = 1 ∏ m p θ dec ( y i ∣ Y 0 : i − 1 , X 1 : n ) , with X 1 : n = f θ enc ( X 1 : n ) .
<p"次の単語"の各条件付き分布は、以下のようにロジットベクトルのソフトマックスによって定義されます。
p θ dec ( y i ∣ Y 0 : i − 1 , X ‾ 1 : n ) = Softmax ( l i ) . p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i -1}, \mathbf{\overline{X}}_{1:n}) = \textbf{Softmax}(\mathbf{l}_i). p θ dec ( y i ∣ Y 0 : i − 1 , X 1 : n ) = Softmax ( l i ) .
詳細については、Encoder-Decoderノートブックを参照してください。
BERTを使用したウォームスタートのエンコーダー・デコーダー
では、事前学習済みのBERTモデルをエンコーダー・デコーダーモデルのウォームスタートにどのように使用できるかを説明します。 BERTの事前学習済みの重みパラメータは、エンコーダーとデコーダーの重みパラメータの両方の初期化に使用されます。そのため、BERTのアーキテクチャとエンコーダーのアーキテクチャを比較し、BERTにも存在するエンコーダーのすべてのレイヤーは、対応するBERTブロックの事前学習済みの重みパラメータで初期化されます。BERTに存在しないエンコーダーのレイヤーは、重みパラメータがランダムに初期化されます。
可視化してみましょう。
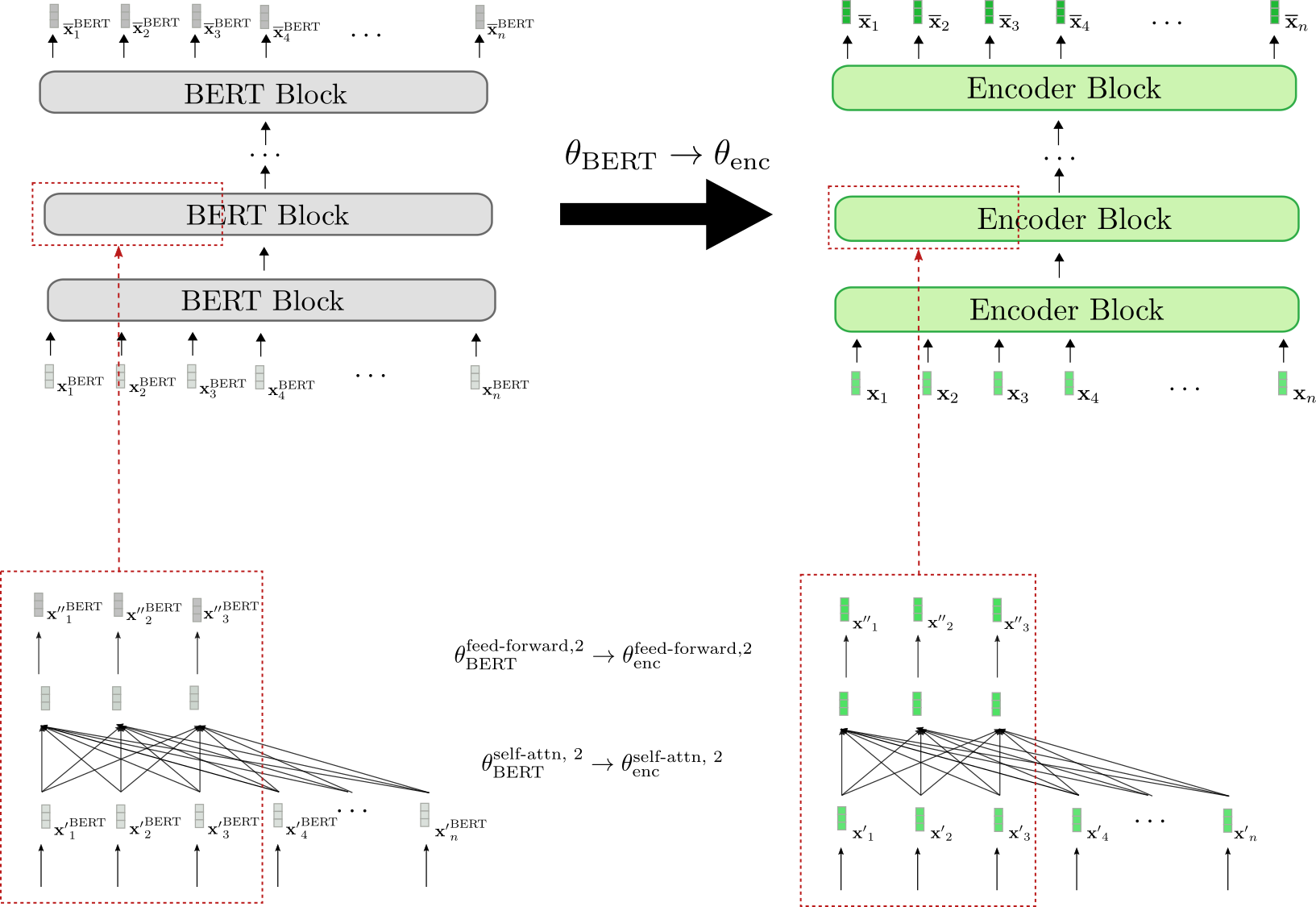
エンコーダーのアーキテクチャはBERTのアーキテクチャと1対1に対応していることがわかります。バイダイレクショナル自己注意層と2つのフィードフォワード層の重みパラメータは、すべてのエンコーダーブロックの重みパラメータとして、対応するBERTブロックの事前学習済みの重みパラメータで初期化されます。これは、2番目のエンコーダーブロックの場合に例示されています(下部の赤いボックス)。例えば、θ enc self-attn, 2 \theta_{\text{enc}}^{\text{self-attn}, 2} θ enc self-attn, 2 および θ enc feed-forward, 2 \theta_{\text{enc}}^{\text{feed-forward}, 2} θ enc feed-forward, 2 の重みパラメータがBERTの重みパラメータである θ BERT feed-forward, 2 \theta_{\text{BERT}}^{\text{feed-forward}, 2} θ BERT feed-forward, 2 および θ BERT self-attn, 2 \theta_{\text{BERT}}^{\text{self-attn}, 2} θ BERT self-attn, 2 に初期化されることが示されています。
ファインチューニングの前に、エンコーダーは事前学習済みのBERTモデルとまったく同じように動作します。エンコーダーに渡される入力シーケンス x 1 , … , x n \mathbf{x}_1, \ldots, \mathbf{x}_n x 1 , … , x n (緑で表示)が BERT に渡される入力シーケンス x 1 BERT , … , x n BERT \mathbf{x}_1^{\text{BERT}}, \ldots, \mathbf{x}_n^{\text{BERT}} x 1 BERT , … , x n BERT (灰色で表示)と等しいと仮定すると、それぞれの出力ベクトルシーケンス x ‾ 1 , … , x ‾ n \mathbf{\overline{x}}_1, \ldots, \mathbf{\overline{x}}_n x 1 , … , x n (濃い緑で表示)と x ‾ 1 BERT , … , x ‾ n BERT \mathbf{\overline{x}}_1^{\text{BERT}}, \ldots, \mathbf{\overline{x}}_n^{\text{BERT}} x 1 BERT , … , x n BERT (濃い灰色で表示)も等しくなる必要があります。
次に、デコーダーのウォームスタートを説明します。
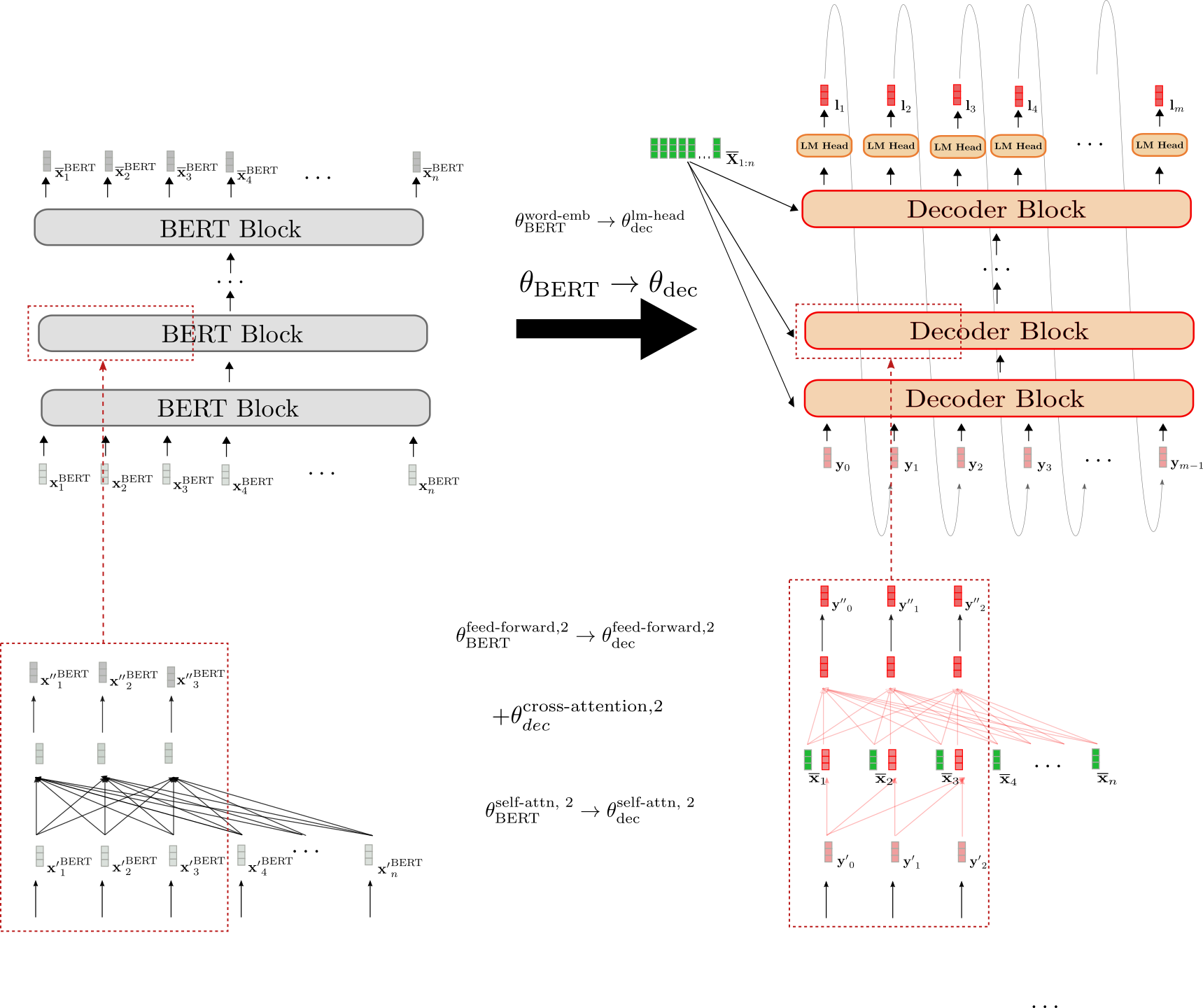
デコーダーのアーキテクチャはBERTのアーキテクチャと3つの点で異なります。
-
まず、デコーダーはコンテキスト化されたエンコードされたシーケンス X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n に依存する必要があります。そのため、各BERTブロックの自己注意層と2つのフィードフォワード層の間にランダムに初期化されたクロスアテンション層が追加されます。これは、右下の赤いボックス内の新たに追加された完全連結グラフで示されています。これにより、変更された各BERTブロックの動作が変わり、例えば、入力ベクトル y ′ 0 \mathbf{y’}_0 y ′ 0 がランダムな出力ベクトル y ′ ′ 0 \mathbf{y”}_0 y ′ ′ 0 を生成するようになります(赤い枠で強調表示)。
-
次に、BERTのバイダイレクショナル自己注意層をユニダイレクショナル自己注意層に変更する必要があります。これは、自己回帰的な生成に準拠するためです。バイダイレクショナル自己注意層とユニダイレクショナル自己注意層の両方が同じキー、クエリ、値の射影重みを使用しているため、デコーダーの自己注意層の重みはBERTの自己注意層の重みで初期化することができます。たとえば、デコーダーのユニダイレクショナル自己注意層のクエリ、キー、値の重みパラメータは、BERTのバイダイレクショナル自己注意層のそれらの重みパラメータで初期化されます(θ BERT self-attn, 2 = { W BERT , k self-attn, 2 , W BERT , v self-attn, 2 , W BERT , q self-attn, 2 } → θ dec self-attn, 2 = { W dec , k self-attn, 2 , W dec , v self-attn, 2 , W dec , q self-attn, 2 })。
-
最後に、デコーダーは確率分布 p θ dec ( Y 1 : n ∣ X ‾ ) p_{\theta_{\text{dec}}}(\mathbf{Y}_{1:n} | \mathbf{\overline{X}}) p θ dec ( Y 1 : n ∣ X ) を定義するためのロジットベクトルのシーケンス L 1 : m \mathbf{L}_{1:m} L 1 : m を出力します。その結果、最後のデコーダーブロックの上にLM Head層が追加されます。LM Head層の重みパラメータは通常、単語埋め込みの重みパラメータに対応しており、ランダムに初期化されません。これは、上部で示されている初期化 θ BERT word-emb → θ dec lm-head です。
- エンコーダーデコーダーモデルの容量はMTにおいて重要な要素であり、
- エンコーダーとデコーダーは異なる文法と語彙を扱わなければならない
-
すべてのタスクで、ウォームスタートされたエンコーダーパートは、ランダムに初期化されたエンコーダーを持つエンコーダーデコーダーモデルと比較して、大幅なパフォーマンス向上をもたらすことが観察されました。一方、デコーダーのウォームスタートはそれほど重要ではないようで、ほとんどのタスクでBERT2BERTとBERT2Rndが同じレベルのパフォーマンスを示しています。直感的な理由としては、BERTまたはRoBERTaで初期化されたエンコーダーパートは、どちらの重みパラメータもランダムに初期化されていないため、エンコーダーはBERTまたはRoBERTaの事前学習済みチェックポイントで獲得した知識を完全に活用できるということです。対照的に、ウォームスタートされたデコーダーは常に一部の重みパラメータがランダムに初期化されているため、デコーダーの初期化に使用されるチェックポイントで獲得した知識を効果的に活用することが非常に困難になる可能性があります。
-
次に、エンコーダーとデコーダーの重みを共有することは、しばしば有益であることがわかりました。特に、ターゲットの分布が入力の分布に類似している場合(例:BBC XSum)には特に有益です。ただし、ターゲットデータの分布が入力データの分布とより大きく異なるデータセットや、モデル容量が重要な役割を果たすことが知られているデータセット(例:WMT14)に対しては、エンコーダーデコーダーの重み共有は不利に働くようです。
-
最後に、シーケンスツーシーケンスのタスクを解決するために必要な「スタンドアロン」のチェックポイントの語彙が、事前学習済みのBERT2GPT2エンコーダーデコーダーよりも劣るパフォーマンスを示すことが非常に重要です。たとえば、ウォームスタートされたBERT2GPT2エンコーダーデコーダーは、GPT2が英語で事前学習されているのに対して、対象の言語がドイツ語であるため、En → De MTでは性能が低下するでしょう。BERT2GPT2、Rnd2GPT2、およびRoBERTa2GPT2の全体的なパフォーマンスは、BERT2BERT、BERTShared、およびRoBERTaSharedと比較して非常に劣っていることを示しています。また、これは、デコーダーパートを事前学習済みのGPT2チェックポイントで初期化することが、事前学習済みのBERTチェックポイントで初期化することよりも効果的ではないことを示しています。なお、GPT2はデコーダーのアーキテクチャにより類似しています。
- RoBERTaShared(large)- Wikisplit : google/roberta2roberta_L-24_wikisplit
- RoBERTaShared(large)- Discofuse : google/roberta2roberta_L-24_discofuse
- BERT2BERT(large)- WMT en → de : google/bert2bert_L-24_wmt_en_de
- BERT2BERT(large)- WMT de → en : google/bert2bert_L-24_wmt_de_en
- RoBERTaShared(large)- CNN/Dailymail : google/roberta2roberta_L-24_cnn_daily_mail
- RoBERTaShared(large)- BBC XSum : google/roberta2roberta_L-24_bbc
- RoBERTaShared(large)- Gigaword : google/roberta2roberta_L-24_gigaword
- CNN/DailymailのBERT2BERT(このノートブックの簡略版)は、こちらをクリックしてください。
- BBC XSumのRoBERTaShareは、こちらをクリックしてください。
- WMT14 En → DeのBERT2Rndは、こちらをクリックして
入力データは短いニュース記事のようです。興味深いことに、ラベルは箇条書きのような要約のようです。この段階では、データの感触を得るためにいくつかの他の例を見るべきです。
また、ここでテキストは大文字と小文字を区別します。これは、大文字と小文字を区別しないモデルを使用したい場合に注意する必要があることを意味します。CNN/Dailymailは要約のデータセットであり、ROUGEメトリックを使用してモデルを評価します。🤗datasetsのROUGEの説明を確認すると、メトリックは大文字と小文字を区別しないことがわかります。つまり、評価中に大文字は小文字に正規化されます。したがって、
bert-base-uncasedなどの大文字を含まないチェックポイントを安全に活用することができます。すごい!次に、入力データとラベルの長さを把握しましょう。
モデルはトークン長で長さを計算するため、
bert-base-uncasedトークナイザを使用して記事と要約の長さを計算します。まず、トークナイザをロードします。
from transformers import BertTokenizerFast tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")次に、
.map()を使用して記事と要約の長さを計算します。bert-base-uncasedが処理できる最大長が512であることがわかっているため、最大長より長い入力サンプルの割合も興味があります。同様に、64トークンを超える要約の割合と128トークンを超える要約の割合も計算します。以下のように
.map()関数を定義できます。# articleとsummaryの長さを辞書にマップし、512トークンよりも長いサンプルの場合も含める def map_to_length(x): x["article_len"] = len(tokenizer(x["article"]).input_ids) x["article_longer_512"] = int(x["article_len"] > 512) x["summary_len"] = len(tokenizer(x["highlights"]).input_ids) x["summary_longer_64"] = int(x["summary_len"] > 64) x["summary_longer_128"] = int(x["summary_len"] > 128) return x最初の10000サンプルを見ることで十分です。
num_proc=4を使用して複数のプロセスを使用することで、マッピングを高速化することができます。sample_size = 10000 data_stats = train_data.select(range(sample_size)).map(map_to_length, num_proc=4)最初の10000サンプルの長さを計算したので、それらを平均化する必要があります。これには、
.map()関数をbatched=Trueおよびbatch_size=-1とともに使用して、.map()関数内ですべての10000サンプルにアクセスできるようにします。def compute_and_print_stats(x): if len(x["article_len"]) == sample_size: print( "Article Mean: {}, %-Articles > 512:{}, Summary Mean:{}, %-Summary > 64:{}, %-Summary > 128:{}".format( sum(x["article_len"]) / sample_size, sum(x["article_longer_512"]) / sample_size, sum(x["summary_len"]) / sample_size, sum(x["summary_longer_64"]) / sample_size, sum(x["summary_longer_128"]) / sample_size, ) ) output = data_stats.map( compute_and_print_stats, batched=True, batch_size=-1, ) OUTPUT: ------- Article Mean: 847.6216, %-Articles > 512:0.7355, Summary Mean:57.7742, %-Summary > 64:0.3185, %-Summary > 128:0.0平均して、記事は平均して848トークンを含み、記事の約3/4がモデルの
max_length512よりも長いことがわかります。要約は平均して57トークンです。10000サンプルのうち30%以上の要約は64トークンを超えていますが、128トークンを超えるものはありません。bert-base-casedは512トークンに制限されているため、記事から可能性のある重要な情報をカットする必要があります。重要な情報のほとんどは記事の冒頭にあるため、計算効率を考慮して、このノートブックではbert-base-casedとmax_length512を使用することにします。この選択肢は最適ではありませんが、CNN/Dailymailで良い結果を出すことがわかっています。また、エンコーダとして使用するためにLongformerなどの長距離シーケンスモデルを活用することもできます。概要の長さに関しては、128の長さは既にすべての概要ラベルを含んでいることがわかります。128は
bert-base-casedの制限内に簡単に収まるため、生成を128に制限することにします。再び、
.map()関数を使用します。今回は、各トレーニングバッチをモデル入力のバッチに変換するために使用します。"article"と"highlights"はトークン化され、エンコーダの"input_ids"とデコーダの"decoder_input_ids"として準備されます。"labels"は自動的に左にシフトされ、言語モデリングのトレーニングに使用されます。最後に、パディングされたラベルの損失を無視することは非常に重要です。 🤗Transformersでは、これをラベルを-100に設定することで行うことができます。さて、マッピング関数を書きましょう。
encoder_max_length=512 decoder_max_length=128 def process_data_to_model_inputs(batch): # 入力とラベルをトークン化する inputs = tokenizer(batch["article"], padding="max_length", truncation=True, max_length=encoder_max_length) outputs = tokenizer(batch["highlights"], padding="max_length", truncation=True, max_length=decoder_max_length) batch["input_ids"] = inputs.input_ids batch["attention_mask"] = inputs.attention_mask batch["labels"] = outputs.input_ids.copy() # BERTはラベルを自動的にシフトするため、ラベルは`decoder_input_ids`と完全に対応している必要があります。 # PADトークンが無視されるようにする必要があります batch["labels"] = [[-100 if token == tokenizer.pad_token_id else token for token in labels] for labels in batch["labels"]] return batchこのノートブックでは、デモンストレーションのためにわずかなトレーニング例でモデルのトレーニングと評価を行い、メモリ不足の問題を防ぐために
batch_sizeを4に設定します。以下の行は、トレーニングデータを最初の
32の例に制限します。フルトレーニングの実行の場合、このセルはコメントアウトされるか実行されません。batch_sizeが16の場合、良い結果が得られました。train_data = train_data.select(range(32))さて、トレーニングデータを準備しましょう。
# batch_size = 16 batch_size=4 train_data = train_data.map( process_data_to_model_inputs, batched=True, batch_size=batch_size, remove_columns=["article", "highlights", "id"] )処理されたトレーニングデータセットを見てみると、
article、highlights、idの列名がEncoderDecoderModelが期待する引数で置き換えられていることがわかります。train_data OUTPUT: ------- Dataset(features: {'attention_mask': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), 'decoder_attention_mask': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), 'decoder_input_ids': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), 'input_ids': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), 'labels': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None)}, num_rows: 32)ここまで、データはPythonの
List形式を使用して操作されていました。データをGPUでトレーニングするために、データをPyTorchのテンソルに変換しましょう。train_data.set_format( type="torch", columns=["input_ids", "attention_mask", "labels"], )素晴らしいですね、トレーニングデータのデータ処理が完了しました。同様に、検証データにも同じことができます。
まず、検証データセットの10%をロードします:
val_data = datasets.load_dataset("cnn_dailymail", "3.0.0", split="validation[:10%]")デモンストレーションの目的のために、検証データは8つのサンプルに減らされます,
val_data = val_data.select(range(8))マッピング関数が適用されます,
val_data = val_data.map( process_data_to_model_inputs, batched=True, batch_size=batch_size, remove_columns=["article", "highlights", "id"] )そして、最後に、検証データもPyTorchのテンソルに変換されます。
val_data.set_format( type="torch", columns=["input_ids", "attention_mask", "labels"], )素晴らしい!では、
EncoderDecoderModelのウォームスタートに移りましょう。エンコーダーデコーダーモデルのウォームスタート
このセクションでは、
bert-base-casedのチェックポイントを使用してエンコーダーデコーダーモデルをウォームスタートする方法について説明します。まず、
EncoderDecoderModelをインポートしましょう。詳細な情報については、EncoderDecoderModelクラスのドキュメントを参照してください。from transformers import EncoderDecoderModel🤗Transformersの他のモデルクラスとは異なり、
EncoderDecoderModelクラスには2つの事前学習済み重みをロードするためのメソッドがあります。-
「標準的な」
.from_pretrained(...)メソッドは、一般的なPretrainedModel.from_pretrained(...)メソッドから派生しており、他のモデルクラスと同様に動作します。この関数は単一のモデル識別子(例:.from_pretrained("google/bert2bert_L-24_wmt_de_en"))を期待し、単一の.ptチェックポイントファイルをEncoderDecoderModelクラスにロードします。 -
特別な
.from_encoder_decoder_pretrained(...)メソッドは、エンコーダーとデコーダーの2つのモデル識別子を使用してエンコーダーデコーダーモデルをウォームスタートするために使用できます。最初のモデル識別子はエンコーダーをロードするために使用されます(AutoModel.from_pretrained(...)を参照してください)、そして2番目のモデル識別子はデコーダーをロードするために使用されます(AutoModelForCausalLMを参照してください)。
それでは、BERT2BERTモデルをウォームスタートしましょう。先に述べたように、エンコーダーとデコーダーの両方を
"bert-base-cased"のチェックポイントでウォームスタートします。bert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-uncased", "bert-base-uncased") 出力: ------- """Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertLMHeadModel: ['cls.seq_relationship.weight', 'cls.seq_relationship.bias'] - This IS expected if you are initializing BertLMHeadModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPretraining model). - This IS NOT expected if you are initializing BertLMHeadModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model). Some weights of BertLMHeadModel were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['bert.encoder.layer.0.crossattention.self.query.weight', 'bert.encoder.layer.0.crossattention.self.query.bias', 'bert.encoder.layer.0.crossattention.self.key.weight', 'bert.encoder.layer.0.crossattention.self.key.bias', 'bert.encoder.layer.0.crossattention.self.value.weight', 'bert.encoder.layer.0.crossattention.self.value.bias', 'bert.encoder.layer.0.crossattention.output.dense.weight', 'bert.encoder.layer.0.crossattention.output.dense.bias', 'bert.encoder.layer.0.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.0.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.1.crossattention.self.query.weight', 'bert.encoder.layer.1.crossattention.self.query.bias', 'bert.encoder.layer.1.crossattention.self.key.weight', 'bert.encoder.layer.1.crossattention.self.key.bias', 'bert.encoder.layer.1.crossattention.self.value.weight', 'bert.encoder.layer.1.crossattention.self.value.bias', 'bert.encoder.layer.1.crossattention.output.dense.weight', 'bert.encoder.layer.1.crossattention.output.dense.bias', 'bert.encoder.layer.1.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.1.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.2.crossattention.self.query.weight', 'bert.encoder.layer.2.crossattention.self.query.bias', 'bert.encoder.layer.2.crossattention.self.key.weight', 'bert.encoder.layer.2.crossattention.self.key.bias', 'bert.encoder.layer.2.crossattention.self.value.weight', 'bert.encoder.layer.2.crossattention.self.value.bias', 'bert.encoder.layer.2.crossattention.output.dense.weight', 'bert.encoder.layer.2.crossattention.output.dense.bias', 'bert.encoder.layer.2.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.2.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.3.crossattention.self.query.weight', 'bert.encoder.layer.3.crossattention.self.query.bias', 'bert.encoder.layer.3.crossattention.self.key.weight', 'bert.encoder.layer.3.crossattention.self.key.bias', 'bert.encoder.layer.3.crossattention.self.value.weight', 'bert.encoder.layer.3.crossattention.self.value.bias', 'bert.encoder.layer.3.crossattention.output.dense.weight', 'bert.encoder.layer.3.crossattention.output.dense.bias', 'bert.encoder.layer.3.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.3.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.4.crossattention.self.query.weight', 'bert.encoder.layer.4.crossattention.self.query.bias', 'bert.encoder.layer.4.crossattention.self.key.weight', 'bert.encoder.layer.4.crossattention.self.key.bias', 'bert.encoder.layer.4.crossattention.self.value.weight', 'bert.encoder.layer.4.crossattention.self.value.bias', 'bert.encoder.layer.4.crossattention.output.dense.weight', 'bert.encoder.layer.4.crossattention.output.dense.bias', 'bert.encoder.layer.4.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.4.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.5.crossattention.self.query.weight', 'bert.encoder.layer.5.crossattention.self.query.bias', 'bert.encoder.layer.5.crossattention.self.key.weight', 'bert.encoder.layer.5.crossattention.self.key.bias', 'bert.encoder.layer.5.crossattention.self.value.weight', 'bert.encoder.layer.5.crossattention.self.value.bias', 'bert.encoder.layer.5.crossattention.output.dense.weight', 'bert.encoder.layer.5.crossattention.output.dense.bias', 'bert.encoder.layer.5.crossattention.output.LayerNorm.weight', 'bert.encoder.layer.5.crossattention.output.LayerNorm.bias', 'bert.encoder.layer.6.crossattention.self.query.weight', 'bert.encoder.layer.6.crossattention.self.query.bias', 'bert.encoder.layer.6.crossattention.self.key.weight', 'bert.encoder.layer.6.crossattention.self.key.bias', 'bert.encoder.layer.6.crossattention.self.value.weight', 'bert.encoder.layer.6.crossattention.self.value.bias', 'bert.encoder.layer.6.crossattention.output.dense.weight', 'bert.encoder.layer.6.crossattention.output.dense.bias',一度、ここで警告をよく見てみましょう。
"cls"レイヤーに対応する2つの重みが使用されていません。これは問題ではありません。なぜなら、シーケンス対シーケンスのタスクではBERTのCLSレイヤーは必要ないからです。また、多くの重みが「新しく」またはランダムに初期化されていることに気付きます。よく見ると、これらの重みはすべてクロスアテンションレイヤーに対応しており、これは上記の理論を読んだ後に予想される正確なものです。モデルを詳しく見てみましょう。
bert2bert OUTPUT: ------- EncoderDecoderModel( (encoder): BertModel( (embeddings): BertEmbeddings( (word_embeddings): Embedding(30522, 768, padding_idx=0) (position_embeddings): Embedding(512, 768) (token_type_embeddings): Embedding(2, 768) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) (encoder): BertEncoder( (layer): ModuleList( (0): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ), ... , (11): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) ) ) (pooler): BertPooler( (dense): Linear(in_features=768, out_features=768, bias=True) (activation): Tanh() ) ) (decoder): BertLMHeadModel( (bert): BertModel( (embeddings): BertEmbeddings( (word_embeddings): Embedding(30522, 768, padding_idx=0) (position_embeddings): Embedding(512, 768) (token_type_embeddings): Embedding(2, 768) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) (encoder): BertEncoder( (layer): ModuleList( (0): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (crossattention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ), ..., (11): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (crossattention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1, inplace=False) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) ) ) ) ) (cls): BertOnlyMLMHead( (predictions): BertLMPredictionHead( (transform): BertPredictionHeadTransform( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) ) (decoder): Linear(in_features=768, out_features=30522, bias=True) ) ) ) )bert2bert.encoderはBertModelのインスタンスであり、bert2bert.decoderはBertLMHeadModelの一つです。ただし、両方のインスタンスはtorch.nn.Moduleに結合され、単一の.ptチェックポイントファイルとして保存することができます。標準の
.save_pretrained(...)メソッドを使用して試してみましょう。bert2bert.save_pretrained("bert2bert")同様に、標準の
.from_pretrained(...)メソッドを使用してモデルを再読み込みすることもできます。bert2bert = EncoderDecoderModel.from_pretrained("bert2bert")素晴らしいです。構成もチェックポイントとして保存しましょう。
bert2bert.config OUTPUT: ------- EncoderDecoderConfig { "_name_or_path": "bert2bert", "architectures": [ "EncoderDecoderModel" ], "decoder": { "_name_or_path": "bert-base-uncased", "add_cross_attention": true, "architectures": [ "BertForMaskedLM" ], "attention_probs_dropout_prob": 0.1, "bad_words_ids": null, "bos_token_id": null, "chunk_size_feed_forward": 0, "decoder_start_token_id": null, "do_sample": false, "early_stopping": false, "eos_token_id": null, "finetuning_task": null, "gradient_checkpointing": false, "hidden_act": "gelu", "hidden_dropout_prob": 0.1, "hidden_size": 768, "id2label": { "0": "LABEL_0", "1": "LABEL_1" }, "initializer_range": 0.02, "intermediate_size": 3072, "is_decoder": true, "is_encoder_decoder": false, "label2id": { "LABEL_0": 0, "LABEL_1": 1 }, "layer_norm_eps": 1e-12, "length_penalty": 1.0, "max_length": 20, "max_position_embeddings": 512, "min_length": 0, "model_type": "bert", "no_repeat_ngram_size": 0, "num_attention_heads": 12, "num_beams": 1, "num_hidden_layers": 12, "num_return_sequences": 1, "output_attentions": false, "output_hidden_states": false, "pad_token_id": 0, "prefix": null, "pruned_heads": {}, "repetition_penalty": 1.0, "return_dict": false, "sep_token_id": null, "task_specific_params": null, "temperature": 1.0, "tie_encoder_decoder": false, "tie_word_embeddings": true, "tokenizer_class": null, "top_k": 50, "top_p": 1.0, "torchscript": false, "type_vocab_size": 2, "use_bfloat16": false, "use_cache": true, "vocab_size": 30522, "xla_device": null }, "encoder": { "_name_or_path": "bert-base-uncased", "add_cross_attention": false, "architectures": [ "BertForMaskedLM" ], "attention_probs_dropout_prob": 0.1, "bad_words_ids": null, "bos_token_id": null, "chunk_size_feed_forward": 0, "decoder_start_token_id": null, "do_sample": false, "early_stopping": false, "eos_token_id": null, "finetuning_task": null, "gradient_checkpointing": false, "hidden_act": "gelu", "hidden_dropout_prob": 0.1, "hidden_size": 768, "id2label": { "0": "LABEL_0", "1": "LABEL_1" }, "initializer_range": 0.02, "intermediate_size": 3072, "is_decoder": false, "is_encoder_decoder": false, "label2id": { "LABEL_0": 0, "LABEL_1": 1 }, "layer_norm_eps": 1e-12, "length_penalty": 1.0, "max_length": 20, "max_position_embeddings": 512, "min_length": 0, "model_type": "bert", "no_repeat_ngram_size": 0, "num_attention_heads": 12, "num_beams": 1, "num_hidden_layers": 12, "num_return_sequences": 1, "output_attentions": false, "output_hidden_states": false, "pad_token_id": 0, "prefix": null, "pruned_heads": {}, "repetition_penalty": 1.0, "return_dict": false, "sep_token_id": null, "task_specific_params": null, "temperature": 1.0, "tie_encoder_decoder": false, "tie_word_embeddings": true, "tokenizer_class": null, "top_k": 50, "top_p": 1.0, "torchscript": false, "type_vocab_size": 2, "use_bfloat16": false, "use_cache": true, "vocab_size": 30522, "xla_device": null }, "is_encoder_decoder": true, "model_type": "encoder_decoder" }設定は、エンコーダー設定とデコーダー設定の両方で構成されており、いずれも
BertConfigのインスタンスです。ただし、全体の設定はEncoderDecoderConfigのタイプであり、したがって単一の.jsonファイルとして保存されます。結論として、
EncoderDecoderModelオブジェクトがインスタンス化されると、🤗Transformersの他のエンコーダー・デコーダーモデル(例:BART、T5、ProphetNetなど)と同じ機能が提供されます。唯一の違いは、EncoderDecoderModelが追加のfrom_encoder_decoder_pretrained(...)関数を提供しており、モデルクラスをエンコーダーとデコーダーのチェックポイントからウォームスタートできる点です。余談ですが、共有エンコーダー・デコーダーモデルを作成する場合、パラメータ
tie_encoder_decoder=Trueを以下のように追加で渡すこともできます:shared_bert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-cased", "bert-base-cased", tie_encoder_decoder=True)比較のために、結合モデルのパラメータ数が予想どおり少ないことがわかります。
print(f"\n\nNum Params. Shared: {shared_bert2bert.num_parameters()}, Non-Shared: {bert2bert.num_parameters()}") OUTPUT: ------- Num Params. Shared: 137298244, Non-Shared: 247363386このノートブックでは、共有されていないBert2Bertモデルを学習するため、
bert2bertを使用し、shared_bert2bertではなく続行します。# メモリを解放 del shared_bert2bertbert2bertモデルはウォームスタートされていますが、ビームサーチデコーディングに使用される関連するパラメータはまだ定義されていません。まず、特殊トークンを設定しましょう。
bert-base-casedにはdecoder_start_token_idまたはeos_token_idがないため、それぞれcls_token_idとsep_token_idを使用します。また、configにpad_token_idを定義し、正しいvocab_sizeが設定されていることを確認する必要があります。bert2bert.config.decoder_start_token_id = tokenizer.cls_token_id bert2bert.config.eos_token_id = tokenizer.sep_token_id bert2bert.config.pad_token_id = tokenizer.pad_token_id bert2bert.config.vocab_size = bert2bert.config.encoder.vocab_size次に、ビームサーチデコーディングに関連するすべてのパラメータを定義しましょう。
bart-large-cnnはCNN / Dailymailで良い結果を出すため、そのビームサーチデコーディングパラメータを単にコピーします。これらのパラメータの詳細については、このブログ投稿またはドキュメントを参照してください。
bert2bert.config.max_length = 142 bert2bert.config.min_length = 56 bert2bert.config.no_repeat_ngram_size = 3 bert2bert.config.early_stopping = True bert2bert.config.length_penalty = 2.0 bert2bert.config.num_beams = 4さて、ウォームスタートされたBERT2BERTモデルのファインチューニングを開始しましょう。
ウォームスタートされたエンコーダー・デコーダーモデルのファインチューニング
このセクションでは、ウォームスタートされたエンコーダー・デコーダーモデルをファインチューニングするために
Seq2SeqTrainerの使用方法を示します。まず、
Seq2SeqTrainerとそのトレーニング引数Seq2SeqTrainingArgumentsをインポートしましょう。from transformers import Seq2SeqTrainer, Seq2SeqTrainingArgumentsさらに、
Seq2SeqTrainerを動作させるためにいくつかのPythonパッケージが必要です。!pip install git-python==1.0.3 !pip install rouge_score !pip install sacrebleuSeq2SeqTrainerは、エンコーダー・デコーダーモデル用に🤗TransformerのTrainerを拡張しています。要するに、サマリゼーションなどのほとんどのシーケンス・トゥ・シーケンスタスクでエンコーダー・デコーダーモデルのパフォーマンスを検証するためには、評価中にgenerate(...)関数を使用できる必要があります。詳細については、
Trainerに関する情報は、この短いチュートリアルを読むことをお勧めします。まず、
Seq2SeqTrainingArgumentsを設定します。predict_with_generate引数はTrueに設定する必要があります。これにより、Seq2SeqTrainerは検証データ上でgenerate(...)を実行し、生成された出力をpredictionsとしてcompute_metric(...)関数に渡します。この関数は後で定義します。その他の引数はTrainingArgumentsから派生しており、ここで読むことができます。完全なトレーニングランを行うには、これらの引数を必要に応じて変更する必要があります。デフォルトの良い値は以下にコメントアウトされています。さらに、
Seq2SeqTrainerに関する詳細については、コードを参照することをお勧めします。training_args = Seq2SeqTrainingArguments( predict_with_generate=True, evaluation_strategy="steps", per_device_train_batch_size=batch_size, per_device_eval_batch_size=batch_size, fp16=True, output_dir="./", logging_steps=2, save_steps=10, eval_steps=4, # logging_steps=1000, # save_steps=500, # eval_steps=7500, # warmup_steps=2000, # save_total_limit=3, )また、検証中に正確にROUGEスコアを計算するための関数を定義する必要があります。
predict_with_generateを有効にしたため、compute_metrics(...)関数はgenerate(...)関数を使用して取得されたpredictionsを期待します。ほとんどの要約タスクと同様に、CNN/Dailymailは通常、ROUGEスコアを使用して評価されます。まず、🤗datasetsライブラリを使用してROUGEメトリックをロードします。
rouge = datasets.load_metric("rouge")次に、
compute_metrics(...)関数を定義します。rougeメトリックは2つの文字列リストからスコアを計算します。したがって、predictionsとlabelsの両方をデコードし、-100が正しくpad_token_idで置き換えられ、skip_special_tokens=Trueによってすべての特殊文字が削除されるようにします。def compute_metrics(pred): labels_ids = pred.label_ids pred_ids = pred.predictions pred_str = tokenizer.batch_decode(pred_ids, skip_special_tokens=True) labels_ids[labels_ids == -100] = tokenizer.pad_token_id label_str = tokenizer.batch_decode(labels_ids, skip_special_tokens=True) rouge_output = rouge.compute(predictions=pred_str, references=label_str, rouge_types=["rouge2"])["rouge2"].mid return { "rouge2_precision": round(rouge_output.precision, 4), "rouge2_recall": round(rouge_output.recall, 4), "rouge2_fmeasure": round(rouge_output.fmeasure, 4), }素晴らしいですね、これですべての引数を
Seq2SeqTrainerに渡してファインチューニングを開始できます。以下のセルを実行すると、約10分かかります☕。完全なCNN/Dailymailトレーニングデータ上でBERT2BERTのファインチューニングには、単一のTITAN RTX GPUで約8時間かかります。
# トレーナーのインスタンス化 trainer = Seq2SeqTrainer( model=bert2bert, tokenizer=tokenizer, args=training_args, compute_metrics=compute_metrics, train_dataset=train_data, eval_dataset=val_data, ) trainer.train()素晴らしいですね、ウォームスタートされたエンコーダーデコーダーモデルのファインチューニングの結果を確認するために、保存されたチェックポイントを見てみましょう。
!ls OUTPUT: ------- bert2bert checkpoint-20 runs seq2seq_trainer.py checkpoint-10 __pycache__ sample_data seq2seq_training_args.py最後に、通常通りに
EncoderDecoderModel.from_pretrained(...)メソッドを使用してチェックポイントをロードできます。dummy_bert2bert = EncoderDecoderModel.from_pretrained("./checkpoint-20")評価
最後に、テストデータでBERT2BERTモデルを評価したいかもしれません。
まず、ダミーモデルを読み込む代わりに、完全なトレーニングデータセットでファインチューニングされたBERT2BERTモデルを読み込みましょう。また、そのトークナイザーも読み込みます。トークナイザーは、
bert-base-casedのトークナイザーのコピーです。from transformers import BertTokenizer bert2bert = EncoderDecoderModel.from_pretrained("patrickvonplaten/bert2bert_cnn_daily_mail").to("cuda") tokenizer = BertTokenizer.from_pretrained("patrickvonplaten/bert2bert_cnn_daily_mail")次に、CNN/Dailymailのテストデータのうち、わずか2%を読み込みます。完全な評価にはもちろん100%のデータを使用するべきです。
test_data = datasets.load_dataset("cnn_dailymail", "3.0.0", split="test[:2%]")これで、再度🤗datasetの便利な
map()関数を活用して、各テストサンプルの要約を生成することができます。各データサンプルに対して以下の処理を行います:
- まず、
"article"をトークン化します。 - 次に、出力トークンIDを生成します。
- 最後に、出力トークンIDをデコードして予測された要約を取得します。
def generate_summary(batch): # BERTの最大長512でカットオフ inputs = tokenizer(batch["article"], padding="max_length", truncation=True, max_length=512, return_tensors="pt") input_ids = inputs.input_ids.to("cuda") attention_mask = inputs.attention_mask.to("cuda") outputs = bert2bert.generate(input_ids, attention_mask=attention_mask) output_str = tokenizer.batch_decode(outputs, skip_special_tokens=True) batch["pred_summary"] = output_str return batch次に、マップ関数を実行して、各サンプルの予測要約が格納された結果の辞書を取得しましょう。以下のセルを実行すると、約10分かかる場合があります ☕。
batch_size = 16 # 完全な評価の場合は64に変更 results = test_data.map(generate_summary, batched=True, batch_size=batch_size, remove_columns=["article"])最後に、ROUGEスコアを計算します。
rouge.compute(predictions=results["pred_summary"], references=results["highlights"], rouge_types=["rouge2"])["rouge2"].mid OUTPUT: ------- Score(precision=0.10389454113300968, recall=0.1564771201053348, fmeasure=0.12175271663717585)以上です。BERT2BERTモデルのウォームスタートとCNN/Dailymailデータセットでのファインチューニング/評価方法を示しました。
完全にトレーニングされたBERT2BERTモデルは、🤗モデルハブのpatrickvonplaten/bert2bert_cnn_daily_mailにアップロードされています。
このモデルは、完全な評価データでROUGE-2スコア18.22を達成しており、論文で報告されている以上の性能です。
要約の例については、モデルのオンライン推論APIを使用することをお勧めします(こちらをご覧ください)。
Google ResearchのSascha Rothe、Shashi Narayan、Aliaksei Severyn、および🤗Hugging FaceのVictor Sanh、Sylvain Gugger、Thomas Wolfによる校正と非常に有益なフィードバックに感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
-
</
結論として、事前学習済みのBERTモデルからデコーダをウォームスタートする場合、クロスアテンション層の重みのみがランダムに初期化されます。セルフアテンション層とLMヘッドの重みなど、他の重みはBERTの事前学習済み重みパラメータで初期化されます。
エンコーダ・デコーダモデルをウォームスタートした後、重みはシーケンス対シーケンスの下流タスク(要約など)で微調整されます。
BERTとGPT2を使用したエンコーダ・デコーダのウォームスタート
エンコーダとデコーダの両方をBERTチェックポイントでウォームスタートする代わりに、エンコーダにはBERTチェックポイントを使用し、デコーダにはGPT2チェックポイントを使用することもできます。デコーダのみのGPT2チェックポイントは、因果言語モデリングで事前にトレーニングされ、単方向のセルフアテンション層を使用しているため、デコーダのウォームスタートにはより適しているように見えます。
どのようにGPT2チェックポイントを使用してデコーダをウォームスタートするかを説明しましょう。
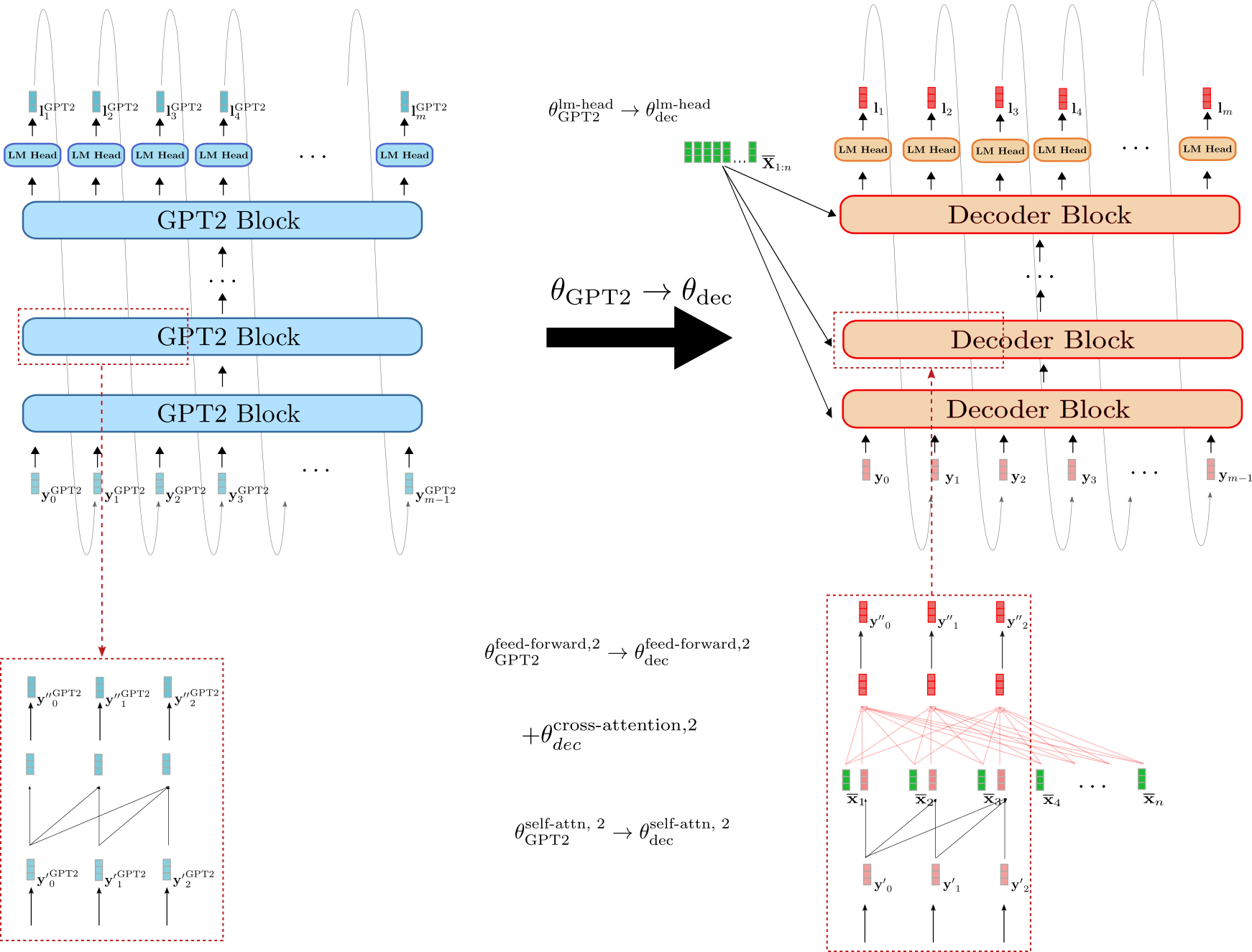
デコーダはBERTよりもGPT2に似ていることがわかります。デコーダのLMヘッドの重みパラメータは直接、GPT2のLMヘッドの重みパラメータで初期化することができます、例えば θ GPT2 lm-head → θ dec lm-head \theta_{\text{GPT2}}^{\text{lm-head}} \to \theta_{\text{dec}}^{\text{lm-head}} θ GPT2 lm-head → θ dec lm-head 。また、デコーダとGPT2のブロックはどちらも単方向のセルフアテンションを使用しているため、デコーダのセルフアテンション層の出力ベクトルは、入力ベクトルが同じであると仮定すれば、GPT2の出力ベクトルと等価です、例えば y ′ 0 GPT2 = y ′ 0 \mathbf{y’}_0^{\text{GPT2}} = \mathbf{y’}_0 y ′ 0 GPT2 = y ′ 0 。BERTで初期化されたデコーダとは異なり、GPT2で初期化されたデコーダはセルフアテンション層の因果関連グラフを保持していることが、下部の赤いボックスで確認できます。
ただし、GPT2で初期化されたデコーダも X ‾ 1 : n \mathbf{\overline{X}}_{1:n} X 1 : n にデコーダを条件付ける必要があります。BERTで初期化されたデコーダと同様に、クロスアテンション層のランダムに初期化された重みパラメータが各デコーダブロックに追加されます。これは、例えば2番目のエンコーダブロックの + θ dec cross-attention, 2 +\theta_{\text{dec}}^{\text{cross-attention, 2}} + θ dec cross-attention, 2 で示されています。
GPT2はBERTよりもエンコーダ・デコーダモデルのデコーダ部分に似ているものの、GPT2で初期化されたデコーダは、ランダムに初期化されたクロスアテンション層により、微調整せずにランダムなロジットベクトル L 1 : m \mathbf{L}_{1:m} L 1 : m を生成します。GPT2で初期化されたデコーダがより良い結果を生み出すか、または効率的に微調整できるかどうかを調査することは興味深いでしょう。
エンコーダ・デコーダの重み共有
Raffel et al. (2020)では、エンコーダとデコーダの重みを共有するランダムに初期化されたエンコーダ・デコーダモデルが、メモリの使用量を半分に減らすことができ、その「非共有」バージョンとほとんど変わらない性能を発揮することを示しています。エンコーダの重みをデコーダと共有することは、エンコーダと同じ位置にあるデコーダのすべての層が同じ重みパラメータを共有することを意味します。つまり、ネットワークの計算グラフの同じノードです。例えば、エンコーダの第3ブロックのセルフアテンション層のクエリ、キー、値の射影行列である W Enc , k self-attn , 3 \mathbf{W}^{\text{self-attn}, 3}_{\text{Enc}, k} W Enc , k self-attn , 3 、 W Enc , v self-attn , 3 \mathbf{W}^{\text{self-attn}, 3}_{\text{Enc}, v} W Enc , v self-attn , 3 、 W Enc , q self-attn , 3 \mathbf{W}^{\text{self-attn}, 3}_{\text{Enc}, q} W Enc , q self-attn , 3 は、第3デコーダブロックのセルフアテンション層の対応するクエリ、キー、値の射影行列と同じです。
W k self-attn , 3 = W enc , k self-attn , 3 ≡ W dec , k self-attn , 3 , W k self-attn , 3 = W enc , k self-attn , 3 ≡ W dec , k self-attn , 3 , W k self-attn , 3 = W enc , k self-attn , 3 ≡ W dec , k self-attn , 3 ,
W q self-attn , 3 = W enc , q self-attn , 3 ≡ W dec , q self-attn , 3 , W q self-attn , 3 = W enc , q self-attn , 3 ≡ W dec , q self-attn , 3 , W q self-attn , 3 = W enc , q self-attn , 3 ≡ W dec , q self-attn , 3 ,
W v self-attn , 3 = W enc , v self-attn , 3 ≡ W dec , v self-attn , 3 , W v self-attn , 3 = W enc , v self-attn , 3 ≡ W dec , v self-attn , 3 , W v self-attn , 3 = W enc , v self-attn , 3 ≡ W dec , v self-attn , 3 ,
その結果、キー射影の重み W k self-attn , 3、W v self-attn , 3、W q self-attn , 3 は、各逆伝播パスごとに2回更新されます- 一度は勾配が第3のデコーダブロックを通過する際、もう一度は勾配が第3のエンコーダブロックを通過する際です。
同様に、エンコーダ-デコーダモデルをウォームスタートさせることも可能です。そのためには、デコーダアーキテクチャ(クロスアテンションの重みを除く)がエンコーダアーキテクチャと同一である必要があります。したがって、エンコーダ-デコーダの重み共有は、シングルエンコーダのみを事前学習したチェックポイントからウォームスタートされた場合にのみ関連します。
素晴らしいです!これがエンコーダ-デコーダモデルのウォームスタートに関する理論でした。次に、いくつかの結果を見ていきましょう。
1 {}^1 1 一般性を失うことなく、方程式と図を混乱させないように、正規化層を除外しています。2 {}^2 2 セルフアテンション層の動作についての詳細は、トランスフォーマーベースのエンコーダ-デコーダモデルのブログ記事のこのセクション(エンコーダの部分)およびこのセクション(デコーダの部分)を参照してください。
エンコーダ-デコーダモデルのウォームスタート(解析)
このセクションでは、Sascha Rothe、Shashi Narayan、Aliaksei Severynによって発表された「シーケンス生成タスクの事前学習チェックポイントの活用」で提案されたエンコーダ-デコーダモデルのウォームスタートに関する結果をまとめます。著者たちは、ウォームスタートされたエンコーダ-デコーダモデルのパフォーマンスを、複数のシーケンス対シーケンスタスク(要約、翻訳、文章分割、文章結合など)でランダムに初期化されたエンコーダ-デコーダモデルと比較しました。
より具体的には、BERT、RoBERTa、GPT2の公開されている事前学習済みチェックポイントを異なるバリエーションで活用し、エンコーダ-デコーダモデルをウォームスタートさせました。例えば、BERTで初期化されたエンコーダとBERTで初期化されたデコーダをペアにして、BERT2BERTモデルを作成したり、RoBERTaで初期化されたエンコーダとGPT2で初期化されたデコーダをペアにしてRoBERTa2GPT2モデルを作成したりしました。また、エンコーダとデコーダの重みを共有する効果(前のセクションで説明したように)をRoBERTaに対して調査しました。すなわち、RoBERTaShare とBERTに対しても調査しました。ランダムまたは部分的にランダムに初期化されたエンコーダ-デコーダモデルは、ベースラインとして使用されました。完全にランダムに初期化されたエンコーダ-デコーダモデルはRnd2Rnd と呼ばれ、BERTで初期化されたデコーダとランダムに初期化されたエンコーダをペアにしたモデルはRnd2BERT と定義されました。
以下の表は、ランダムに初期化された重みの数、すなわち「ランダム」、およびそれぞれの事前学習済みチェックポイントから初期化された重みの数、すなわち「利用された」との関連付けを含む、すべての調査されたモデルバリアントの完全なリストを示しています。すべてのモデルは、768次元の隠れ層埋め込みを持つ12層のアーキテクチャに基づいており、🤗Transformersモデルハブのbert-base-cased、bert-base-uncased、roberta-base、およびgpt2のチェックポイントに対応しています。
BERT2BERTアーキテクチャに基づくモデルRnd2Rndは、221Mの重みパラメータを持ちますが、すべてランダムに初期化されます。他の2つの「BERTベース」のベースラインであるRnd2BERTとBERT2Rndは、おおよそ半分の重み、すなわち112Mのパラメータがランダムに初期化されます。残りの109Mの重みパラメータは、エンコーダまたはデコーダの一部として事前学習済みのbert-base-uncasedのチェックポイントから利用されます。モデルBERT2BERT、BERT2GPT2、およびRoBERTa2GPT2は、エンコーダの重みパラメータすべてが利用されます(bert-base-uncased、roberta-baseそれぞれから)、そして多くのデコーダの重みパラメータも(gpt2、bert-base-uncasedそれぞれから)。12のクロスアテンションレイヤに対応する26Mのデコーダの重みパラメータは、ランダムに初期化されます。RoBERTa2GPT2とBERT2GPT2は、ベースラインのRnd2GPT2と比較されます。また、共有モデルのバリアントであるBERTShareとRoBERTaShareは、エンコーダの重みパラメータが対応するデコーダの重みパラメータと共有されているため、かなり少ないパラメータを持っていることに注意してください。
実験
上記のモデルは、文レベルの結合、文レベルの分割、翻訳、および要約生成という、複雑さの増加する4つのシーケンス対シーケンスのタスクでトレーニングおよび評価されました。以下の表は、各タスクに使用されたデータセットを示しています。
タスクによっては、やや異なるトレーニングの方法が使用されました。たとえば、データセットのサイズや特定のタスクに応じて、トレーニングステップの数は200Kから500Kの範囲で、バッチサイズは128または256に設定され、入力長は128から512の範囲で、出力長は32から128に変化します。ただし、各タスク内では、公平な比較を確保するために、すべてのモデルは同じハイパーパラメータを使用してトレーニングおよび評価されました。タスク固有のハイパーパラメータ設定の詳細については、論文の「実験」セクションを参照してください。
それでは、各タスクの結果の簡単な概要を示します。
文の結合と分割(DiscoFuse、WikiSplit)
文の結合は、複数の文を単一の一貫した文に組み合わせるタスクです。たとえば、次の2つの文:
As a run-blocker, Zeitler moves relatively well. Zeitler too often struggles at the point of contact in space.
は、次のような適切な連結語とともに結合されるべきです:
As a run-blocker, Zeitler moves relatively well. However, he too often struggles at the point of contact in space.
上記の例では、連結語「however」が最初の文から2番目の文への論理的な移行を提供しています。このような連結語を生成できるモデルは、おそらく上記の2つの文が互いに対比関係にあることを推測することを学習していると言えます。
逆のタスクは文の分割と呼ばれ、単一の複雑な文を、意味を保持したまま複数のより単純な文に分割することから成り立ちます。文の分割は、テキストの簡素化において重要なタスクとされています(Botha et al. (2018) 参照)。
例えば、次の文:
Street Rod is the first in a series of two games released for the PC and Commodore 64 in 1989
は、次のように簡素化できます:
Street Rod is the first in a series of two games . It was released for the PC and Commodore 64 in 1989
上記の例では、長い文が2つの重要な情報を伝えようとしています。1つは、ゲームがPC向けにリリースされた2つのゲームの最初であることであり、2つ目はリリースされた年です。したがって、文の分割では、モデルが文のどの部分を2つの文に分割する必要があるかを理解する必要があり、文の結合よりもタスクが難しくなります。
文章の結合および分割タスクのモデルのパフォーマンスを評価するための一般的な指標は、SARIです(Wu et al.(2016))。この指標は、ラベルとモデルの出力のF1スコアに基づいています。
結合および分割のタスクでモデルのパフォーマンスを見てみましょう。
最初の2つの列は、エンコーダーデコーダーモデルのDiscoFuse評価データでのパフォーマンスを示しています。最初の列は、トレーニングデータのすべて(100%)でトレーニングされたエンコーダーデコーダーモデルの結果を示しており、2番目の列は、トレーニングデータの10%のみでトレーニングされたモデルの結果を示しています。ウォームスタートされたモデルは、ランダムに初期化されたベースラインモデル Rnd2Rnd、Rnd2Bert、および Rnd2GPT2 よりも明らかに優れたパフォーマンスを発揮します。トレーニングデータの10%のみでトレーニングされたウォームスタートされた RoBERTa2GPT2 モデルは、トレーニングデータの100%でトレーニングされた Rnd2Rnd モデルと同等のパフォーマンスを発揮します。興味深いことに、Bert2Rnd ベースラインは、完全にウォームスタートされた Bert2Bert モデルと同等のパフォーマンスを発揮します。これは、エンコーダーパートのウォームスタートがデコーダーパートのウォームスタートよりも効果的であることを示しています。最良の結果は RoBERTa2GPT2 によって得られ、次に RobertaShare が続きます。エンコーダーとデコーダーの重みパラメータを共有することは、モデルのパフォーマンスをわずかに向上させるようです。
より困難な文の分割タスクでも、同様のパターンが現れます。ウォームスタートされたエンコーダーデコーダーモデルは、エンコーダーがランダムに初期化されたエンコーダーデコーダーモデルよりも明らかに優れたパフォーマンスを発揮し、重みパラメータを共有するエンコーダーデコーダーモデルは、それらの非連結の重みパラメータよりも良い結果を示します。文の分割では、BertShare モデルが最も優れたパフォーマンスを発揮し、その次に RobertaShare が続きます。
12層モデルのバリエーションに加えて、著者は24層のRobertaShare(large)モデルもトレーニングして評価しました。このモデルは、すべての12層モデルよりも明らかに優れたパフォーマンスを発揮します。
機械翻訳(WMT14)
次に、著者はウォームスタートされたエンコーダーデコーダーモデルを、おそらく最も一般的な機械翻訳(MT)のベンチマークである En → \to → De および De → \to → En WMT14 データセットで評価しました。このノートブックでは、newstest2014 eval データセットの結果を示します。このベンチマークでは、モデルが英語とドイツ語の語彙を理解する必要があるため、BERT-initialized エンコーダーデコーダーモデルは、多言語事前学習済みのチェックポイント bert-base-multilingual-cased からウォームスタートされました。公開されている多言語のRoBERTaチェックポイントは存在しないため、MTのためのRoBERTa-initialized エンコーダーデコーダーモデルは除外されました。GPT2-initialized モデルは、前の実験と同様に gpt2 の事前学習済みチェックポイントから初期化されました。翻訳結果は、BLUE-4 スコアメトリック 1 {}^1 1 を使用して報告されます。
再び、エンコーダーパートのウォームスタートによる明らかなパフォーマンス向上が見られます。BERT2RndとBERT2BERTは、En → \to → De および De → \to → En の両方のタスクで最良の結果を示します。GPT2で初期化されたモデルは、En → \to → De ではさえ Rnd2Rnd ベースラインよりも明らかに劣ったパフォーマンスを発揮します。gpt2 のチェックポイントが英語のテキストのみでトレーニングされたことを考慮すると、BERT2GPT2とRnd2GPT2 モデルはドイツ語の翻訳を生成するのに困難を抱えているのは非常に驚くことではありません。これは、BERT2GPT2 の De → \to → En タスクでの競争力のある結果(例:31.4 vs. 32.7)が、GPT2の語彙が英語の出力形式に適合していることを示しています。文の結合と文の分割で得られた結果とは異なり、エンコーダーとデコーダーの重みパラメータを共有することは、MTでのパフォーマンス向上にはつながりません。著者によると、これには次のような理由が考えられます。
bert-base-multilingual-cased のチェックポイントは100以上の言語でトレーニングされているため、その語彙は En → \to → De および De → \to → En のMTには望ましくないほど大きい可能性があります。そのため、著者は英語とドイツ語のサブセットで大規模なBERTエンコーダーのみのチェックポイントを事前トレーニングし、それを使用してBERT2RndおよびBERTShareエンコーダーデコーダーモデルをウォームスタートしました。改善された語彙のおかげで、BERT2Rnd(large, custom)は他のすべてのモデルを明らかに上回るパフォーマンスを発揮します。
要約(CNN/Dailymail、BBC XSum、Gigaword)
最後に、エンコーダーデコーダーモデルは、おそらく最も困難なシーケンスツーシーケンスのタスクである要約について評価されました。著者は、評価のために特性が異なる3つの要約データセットを選びました:Gigaword(見出し生成)、BBC XSum(極端な要約)、およびCNN/Dailymayl(抽象的な要約)。
Gigawordデータセットには、文章レベルの抽象的な要約が含まれており、モデルは文章レベルの理解、抽象化、そして最終的には言い換えを学習する必要があります。Gigawordの典型的なデータサンプルは次のようなものです。
「*ベネズエラの大統領ヒューゴ・チャベスは木曜日、現役および退役軍人を巻き込むとされるクーデターの陰謀を調査するように命じた。*」
このデータサンプルには、対応する見出しのラベルがあります。例えば:
「チャベス、クーデターの疑いについて調査を命じる」。
BBC XSumデータセットは、ほとんどが1文の要約である、はるかに長い記事のようなテキスト入力で構成されています。このデータセットでは、モデルはドキュメントレベルの推論だけでなく、高いレベルの抽象的な言い換えも学習する必要があります。BBC XSumデータセットのいくつかのデータサンプルはこちらに示されています。
CNN/Dailmailデータセットでは、BBC XSumデータセットと同じ長さのドキュメントを要約して、箇条書きのストーリーハイライトにする必要があります。したがって、ラベルはしばしば複数の文で構成されています。CNN/Dailymailデータセットでは、ドキュメントレベルの理解に加えて、モデルが最も重要な情報をコピーする能力が求められます。いくつかの例はこちらでご覧いただけます。
モデルはRougeメトリックを使用して評価され、Rouge-2スコアが以下に示されています。
さて、結果を見てみましょう。
再度、エンコーダーパートをウォームスタートすることで、ランダムに初期化されたエンコーダーを持つモデルよりも大幅な改善が見られます。これは特にドキュメントレベルの抽象化タスク、つまりCNN/DailymailとBBC XSumに対して顕著です。これは、高いレベルの抽象化を必要とするタスクは、文レベルの抽象化のみを必要とするタスクよりも、事前学習されたエンコーダーパートの利用がより有益であることを示しています。Gigaword以外では、GPT2ベースのエンコーダーデコーダーモデルは要約には適していないようです。
さらに、共有エンコーダーデコーダーモデルは要約において最も優れたパフォーマンスを示しています。RoBERTaShareとBERTShareはすべてのデータセットで最も優れたモデルですが、BBC XSumデータセットでは特に顕著な差があります。例えば、RoBERTaShare(large)はBERT2BERTとBERT2Rndよりも3 Rouge-2ポイント以上、Rnd2Rndよりも8 Rouge-2ポイント以上優れています。著者によって述べられたように、「これはおそらく、BBCの要約文はドキュメントの文と似た分布に従うためであり、これはGigawordの見出しやCNN/DailyMailの箇条書きと必ずしも同じではないからである」ということです。直感的には、BBC XSumでは、エンコーダーで処理される入力文がデコーダーで処理される単文要約と非常に似た構造を持っており、つまり同じ長さ、似た選択の単語、似た構文を持っているということです。
結論
さて、結論を出し、いくつかの実用的なヒントを導き出してみましょう。
上記のタスクのそれぞれについて、性能が最も優れたモデルが🤗Transformersに移植され、以下からアクセスできます:
1 {}^1 1 BLEU-4スコアを取得するためには、Tensorflow公式トランスフォーマーの実装(https://github.com/tensorflow/models/tree master/official/nlp/transformer)からスクリプトを使用しました。注意点として、Vaswani et al.(2017)が使用したtensor2tensor/utils/ get_ende_bleu.shとは異なり、このスクリプトでは複合名詞を分割しませんが、前処理済みのトレーニングセットにはASCIIクォートのみが含まれていることがわかった後、UTF-8クォートはASCIIクォートに正規化されました。
2 {}^2 2 モデルの容量とは、モデルが複雑なパターンをモデリングするのにどれだけ優れているかを非公式に定義したものです。また、モデルがより多くのデータから学習する能力とも定義されることがあります。モデルの容量は、訓練可能なパラメータの数によって大まかに測定されます – パラメータが多いほど、モデルの容量が高くなります。
エンコーダーデコーダーモデルのウォームスタートの理論を説明し、複数のデータセットでの経験的な結果を分析し、実用的な結論を導出しました。次に、BERT2BERTモデルをウォームスタートし、その後CNN/Dailymail要約タスクで微調整するための完全なコード例を紹介します。🤗datasetsと🤗Transformersライブラリを活用します。
さらに、以下のリストは、エンコーダーデコーダーモデルの他の組み合わせのウォームスタートに関するこのノートブックと他のノートブックの簡略版を提供します。