ウィンドウ関数の使用ガイド
ウィンドウ関数の使用ガイド
BigQueryで簡単に累積合計、移動平均、順位を作成します。
もし「面接で必要な6つのSQLスキル」や「昔知っていたかったSQLの概念」といった記事を検索したことがあるのなら、ウィンドウ関数がそのリストのどこかで十分に言及されているはずです。
ウィンドウ関数は素晴らしいものです。
この記事では、ウィンドウ関数とその使い方について理解を深めることを目指します。チュートリアルをカバーした後、公開データを使用したいくつかの使用例を用意しましたので、プロジェクトで試してみてください。
カバーする内容:
- ウィンドウ関数とは何か
- ウィンドウ関数の構文(パーティション、オーダー バイ、フレームの部分)
- 7日間移動平均の作成とその動作の詳細
- 利用可能な集計とウィンドウ関数
- 最後に、ウィンドウ関数の適用例をいくつか実行します。
ウィンドウ関数とは何ですか?
「ウィンドウ」という用語は、SQL(またはコンピューティング全般)で使われるのは少し奇妙に思えるかもしれません。通常、関数の種類の名前は、その関数がどのように使用されるかを示唆しています。例えば:
- 集計関数 – 複数の要素を受け取り、それらを要約した結果を返す
- 文字列関数 – 単語や文章を操作するためのツールボックス
- 配列関数 – 複数のアイテムを一度に操作する
などです。
では、SQLにおけるウィンドウ関数とは何でしょうか?まるで現実の世界の窓のように、ウィンドウ関数は特定の範囲を表示し、その他の範囲は見えなくします。つまり、ウィンドウに表示されているものにだけ集中します。
データの世界に戻りましょう。例えば、IOWAの酒屋の月間売上データを含むテーブルがあるとします。
この例で使用するデータセットはパブリックにアクセス可能で、Googleが提供しており、BigQueryに既に存在しているため、これらの例を自分で試すことができます(リンク)。
bigquery-public-data.iowa_liquour_sales.sales
以下の例では、年と月ごとの売上のシンプルなビューが提供されています。
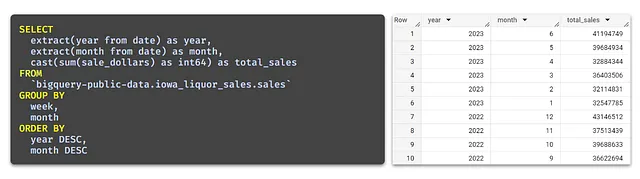
上記のものをビューとして保存して、将来のクエリを可能な限り最小限に抑え、ウィンドウ関数の適用に集中するようにします。
このビューを使用する場合は、spreadsheep-20220603.Dashboard_Datasets.iowa_liqour_monthly_salesを使用できます。
もし、各年の月間平均も別の列として表示したい場合はどうでしょうか?これを達成する方法はいくつかありますが、ウィンドウ関数を使用すると、サブクエリなしで同じ結果に到達できます!
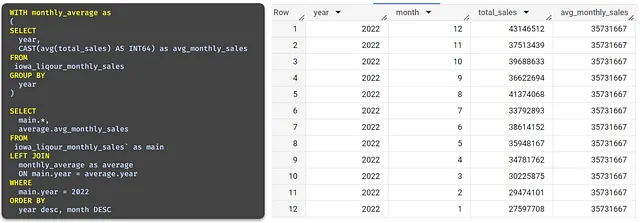
これは完璧に機能しますが、ウィンドウ関数を使用すると、サブクエリなしで同じ結果に到達できます!
上記のウィンドウ関数は、特定の年ごとのグループを定義し、そのグループに対してavg関数などの集計関数を実行することを可能にします。
先に述べたウィンドウのアナロジーを考えると、partition byの部分がそのシナリオでのウィンドウです。データセット全体が目の前にあることは確かですが、パーティションは私たちのビューを年だけに制限します。
それでは構文に入ってみましょう。
ウィンドウの構文
上記の例では、関数を2つの部分に分割することができます。関数名とウィンドウです。
この場合、関数名はAVGというおなじみの集計関数です。ただし、ウィンドウの部分は少し異なります。
関数を指定したら、overキーワードでウィンドウ関数を開始し、その後に括弧()を続ける必要があります。

括弧の中では、partition byキーワードを使用して集計を実行するウィンドウを指定できます。指定する列のリストを含める必要があります。ここでは、yearの列のみを含めていますが、後で別の列を追加します。
partition byはオプションです。もしpartition byを含めない場合、集計はデータセットのすべての行で行われます。これはSELECT文に存在するため、WHERE句はこのウィンドウ関数の前に実行されることに注意してください。
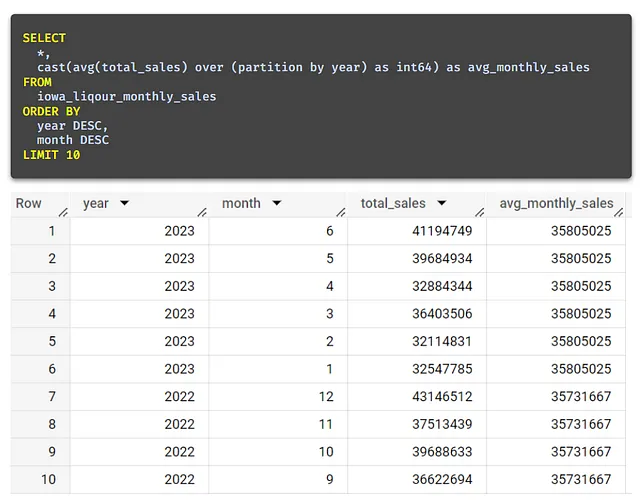
これはどういう意味ですか?先に共有した例を使用して説明しますが、partition by yearを使用してウィンドウを指定しました。しかし、WHERE句では、year = 2022の行のみを返すようにフィルタを設定しています。
これはデータセットには1年だけが表示されることを意味します-2022年、ウィンドウ関数が実行されるときです。したがって、partition by yearウィンドウは冗長ですし、以下の行を使用すると、このシナリオでは同じ結果が得られます。

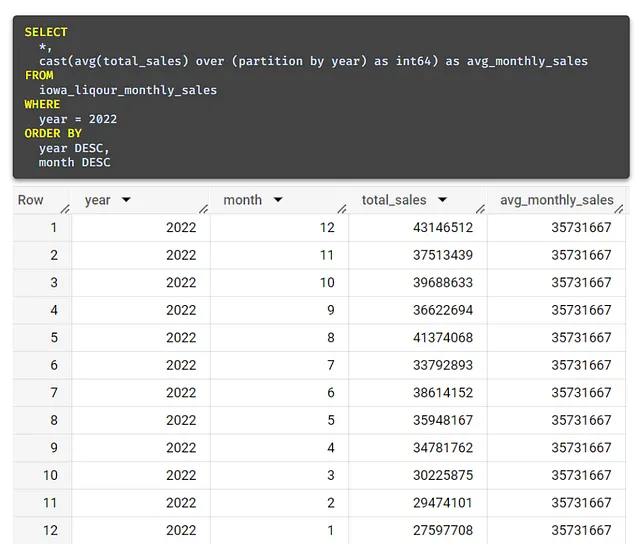
では、前回のクエリを再実行して、今回はWHERE句を削除しましょう。
ここでは、2023年と2022年の異なる値が表示されます。これは、各年の平均月間売上を示しています。
たとえば、7行目には2022年の平均月間売上が3,570万円あり、2023年の平均月間売上(現時点で)は3,580万円です。
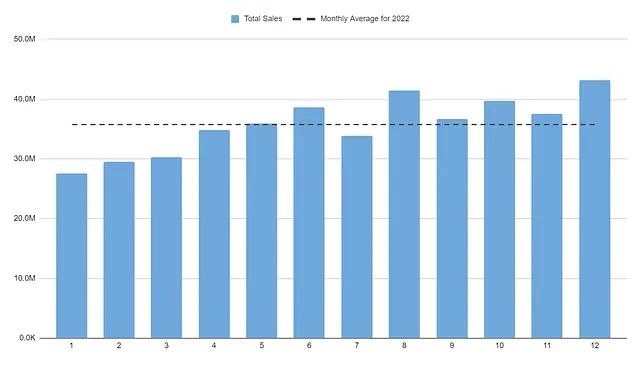
月間平均データにアクセスすることで、売上の傾向を視覚化し、分析することがより容易になります。具体的には、年間の後半が売上に大きく貢献していることが明らかになります。
私たちは、各年の平均月間売上を求めるためにウィンドウ関数を使用しました。そして、この関数はその年のすべての行に結果を適用しました。これは、以前に見た左結合のサブクエリのようなものです。
Order By
これまで主に集計関数とウィンドウの指定方法に焦点を当ててきましたが、ウィンドウがタスクを実行する順序も指定できます。これはランキングやランニングトータル/平均ソリューションの重要な部分です。
アイオワのデータセットに戻り、store_nameを含めたビューを拡大し、店舗ごとの月間総売上に基づいて店舗に番号付けされた月間ランキングを付けましょう。
新しいビュー
spreadsheep-20220603.Dashboard_Datasets.iowa_liqour_monthly_sales_inc_store
集約とは異なり、ウィンドウ関数にのみ存在するランク関数では、関数そのものの内部で列を指定しません。

ただし、上記のように実行しようとすると、エラーが表示されます。

問題は、Bigqueryに結果をランク付けするよう指示したが、どのようにランク付けするかを指定していないことです。これは、ORDER BYを使用して達成できます。

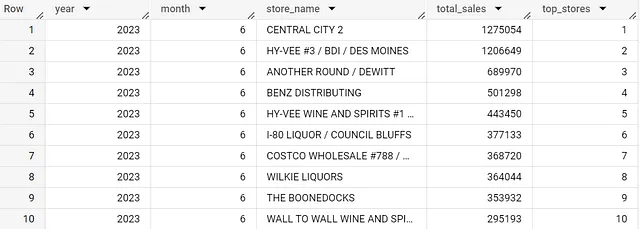
これにより、店舗レベルでの月間売上とランキングが表示されます。その後、2022年の各月のトップ3の店舗など、他の質問にも答えることができます。
この記事の最後の例の1つでは、QUALIFYという新しい節を使用し、ウィンドウ関数が簡単に提供する結果にフィルタをかけることができます。
これまでのウィンドウ関数は、各パーティション内のすべての行に適用されていましたが、パーティションの一部のみを対象とする場合はどうでしょうか?たとえば、直近7日間の平均日次売上ですか?その場合、ウィンドウフレームを指定する必要があります。
ウィンドウフレーム
新しいデータセット、シカゴのタクシーを取り込む時間です!これは、実験したい場合に使用できる別のパブリックデータセット(CC0ライセンス)です。 (リンク)
bigquery-public-data.chicago_taxi_trips.taxi_tripsこのパブリックデータセットは75GBもあり、無料の100GBの月間クエリ割り当てをすばやく消費します。そのため、膨大な請求を発生させずにデータを操作できるように、2023年のデータのみを保持する新しいテーブルを作成しました。
このテーブルは公開されているため、テストには私のデータセットをおすすめします。
spreadsheep-case-studies-2023.chicago_taxies_2023.trip_dataとにかく、話題に戻りましょう…ウィンドウフレームとは何でしょうか?この節により、パーティション内で使用する行または範囲を定義できます。一般的な使用例は、移動平均の作成です。
SELECT date(trip_start_timestamp) as trip_start_date, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-05-01" and "2023-06-30"GROUP BY trip_start_dateORDER BY trip_start_date DESCこのクエリは、2023年5月から6月までの日付ごとの収益を提供します。
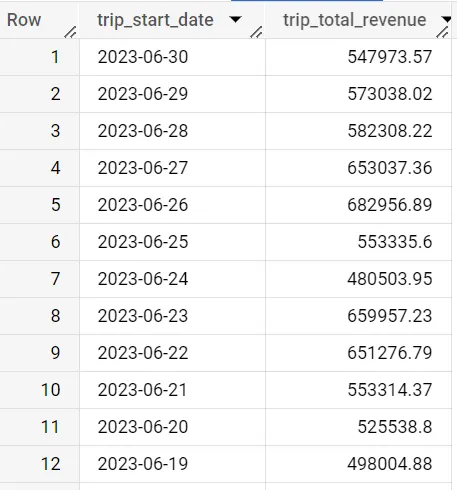
移動平均は、時系列データで非常に一般的であり、特定の日またはイベント月のパフォーマンスを、特定の期間に通常見られる結果と簡単に比較できるようにします。
まず、単純な移動平均を作成しましょう。また、日付の変換と収益の丸めを繰り返すのを防ぐために、初期クエリをCTE内に配置しました。
WITH daily_data as(SELECT date(trip_start_timestamp) as trip_start_date, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-05-01" and "2023-06-30"GROUP BY trip_start_dateORDER BY trip_start_date DESC)SELECT trip_start_date, trip_total_revenue, avg(trip_total_revenue) over (order by trip_start_date asc) as moving_averageFROM daily_data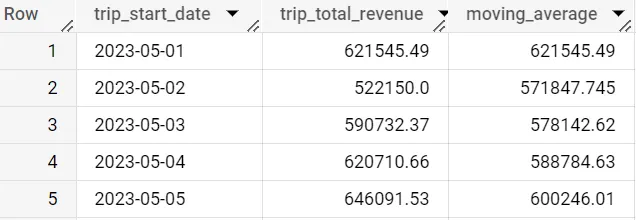
最初の5行を見ると、最初の平均値がtrip_total_revenueに等しいことがわかります。これは、データをtrip_start_dateで昇順に並べ替えたため、ウィンドウの開始部分だからです。したがって、まだ平均化する対象はありません。
しかし、2行目では1行目と2行目の間の日平均があります。3行目では1行目、2行目、3行目の間の日平均があります。
これは動作していることを示す良いスタートですが、さらに進めましょう。収益の過去7日間の移動平均だけを含む移動平均を作成し、ウィンドウに7日間が含まれていない場合はnull値を表示します。
ウィンドウ範囲を指定するには、次の3つのキーワードを覚えておく必要があります:
- current row
- preceding
- following
次に、行または範囲でウィンドウを構築し、between <<start>> と <<end>> を続けます。
rows between 7 preceding and one preceding上記の例は、この問題に必要なウィンドウフレームです。ウィンドウを現在の行の7行前から終了して1行前まで指定しています。
以下は、このウィンドウフレームとsum集計を使用した単純な例です。
select numbers, sum(numbers) over ( order by numbers asc rows between 7 preceding and one preceding ) as moving_sum_sevenfrom test_data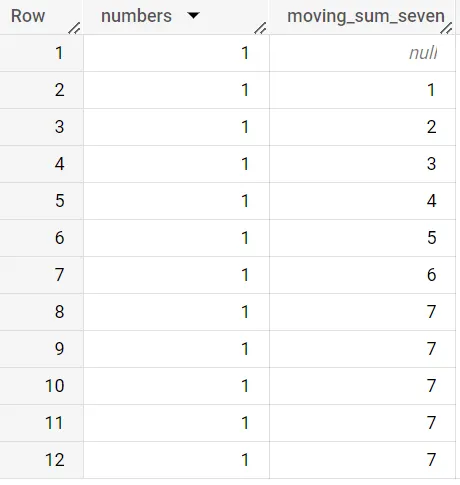
8行目に到達すると、移動合計の値は7になります。この時点でウィンドウには7行のデータが含まれています。ウィンドウを6行前と現在の行に切り替えると、ウィンドウは現在の行を含むようにシフトします。
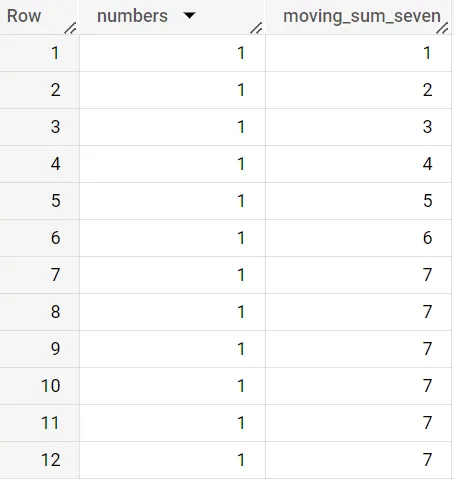
このセクションの最後に、使用例をいくつか示して、どのように使用できるかを強調しますが、とりあえず手元のタスクに戻りましょう!
では、移動平均にウィンドウ範囲を組み込みましょう。
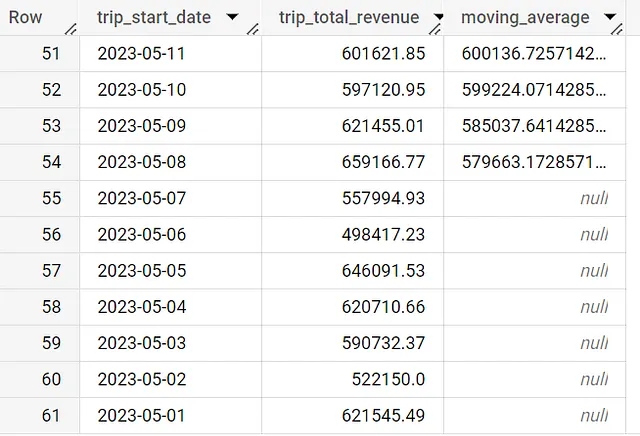
with daily_data as (SELECT date(trip_start_timestamp) as trip_start_date, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-05-01" and "2023-06-30"GROUP BY trip_start_dateORDER BY trip_start_date DESC)SELECT trip_start_date, trip_total_revenue, avg(trip_total_revenue) over (order by trip_start_date asc rows between 7 preceding and one preceding) as moving_averageFROM daily_dataORDER BY trip_start_date DESC最後の課題は、ウィンドウに7行未満のデータが含まれる場合に値をnullにする方法です。これには、IFステートメントを使用してチェックすることができます。
if ( COUNT(*) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 7 PRECEDING AND 1 PRECEDING) = 7, AVG(trip_total_revenue) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 7 PRECEDING AND 1 PRECEDING), NULL ) AS moving_averageウィンドウフレーム内に存在する行数を数える2番目のウィンドウ関数を追加しました。この関数は、7と等しい場合に移動平均の結果を提供します。
ROWSとRANGEの違い
SQLでは、ROWSおよびRANGE句の両方が、グループ内のウィンドウ関数で使用される行を制御するのに役立ちます。
ROWS句は、固定数の行と一緒に動作します。現在の行の前後に、特定の数の行を取得し、その値に関係なくウィンドウ関数に含めます。
RANGE句は、行の値に基づいて動作します。現在の行に対して特定の範囲内の値を持つ行を考慮します。実際の値によって、ウィンドウ関数の計算に含まれる行が決まります。
つまり、ROWS句は行の物理的な位置に焦点を当てていますが、RANGE句は行の論理的な値を考慮してウィンドウ関数への含まれるかどうかを決定します。
これを実際に動作させるための例として、次のコードを試してみてください。
with sales_data as (SELECT'2023-01-01' AS DATE, 100 AS SALESUNION ALLSELECT'2023-01-02' AS DATE, 50 AS SALESUNION ALLSELECT'2023-01-03' AS DATE, 250 AS SALESUNION ALLSELECT'2023-01-03' AS DATE, 200 AS SALESUNION ALLSELECT'2023-01-04' AS DATE, 300 AS SALESUNION ALLSELECT'2023-01-05' AS DATE, 150 AS SALES)SELECT *, SUM(SALES) OVER (ORDER BY DATE ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS running_total_rows, SUM(SALES) OVER (ORDER BY DATE RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS running_total_rangeFROM sales_data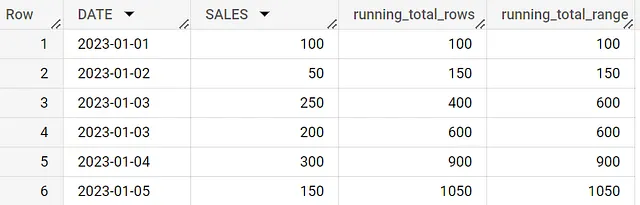
2つの句を比較するために、行3と行4に注目してください。ROWS句では、売上日付が重複していても各行が合計に追加されます。しかしRANGE句では、売上日付が同じ行が1つの範囲としてグループ化されます。例えば、この場合、2023年01月03日の日付を持つすべての行は1つの範囲として扱われます。
ウィンドウ関数とは何ですか?
ウィンドウ関数にはさまざまな関数があります。
集約関数には、次のようなものがあります:
- SUM: 数値列の合計を計算します。
- AVG: 数値列の平均を計算します。
- MIN: 列から最小値を取得します。
- MAX: 列から最大値を取得します。
- COUNT: 列内の行数をカウントします。
- COUNT DISTINCT: 列内の重複しない値の数をカウントします。
そして、ウィンドウ関数専用の新しい関数、解析関数があります:
- ROW_NUMBER: ウィンドウフレーム内の各行に一意の番号を割り当てます。
- RANK: ウィンドウフレーム内の順序に基づいて各行にランクを割り当てます。
- DENSE_RANK: ウィンドウフレーム内の順序に基づいて、ギャップなしで各行にランクを割り当てます。
- LAG: ウィンドウフレーム内の前の行の値を取得します。
- LEAD: ウィンドウフレーム内の次の行の値を取得します。
- FIRST_VALUE: ウィンドウフレーム内の最初の行の値を取得します。
- LAST_VALUE: ウィンドウフレーム内の最後の行の値を取得します。
上記の関数は、BigQueryのドキュメントにハイパーリンクされています。
動作例
毎日の累積合計
ウィンドウ関数のよりシンプルな使用例の一つは、累積合計です。シカゴのタクシーデータセットでは、月次の収益があるかもしれませんが、年間の累積収益を追跡する新しい列が必要です。
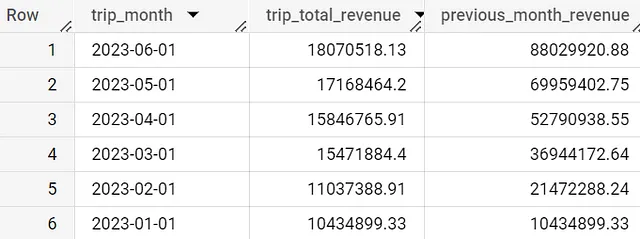
with daily_data as (SELECT date(timestamp_trunc(trip_start_timestamp,month)) as trip_month, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-01-01" and "2023-06-30"GROUP BY trip_monthORDER BY trip_month DESC)SELECT trip_month, trip_total_revenue, round(sum(trip_total_revenue) over (order by trip_month asc),2) AS running_total_revenue,FROM daily_dataORDER BY trip_month DESC12週間移動平均
この記事のチュートリアルでは、移動平均は時系列データを扱う際に非常に一般的です。
with daily_data as (SELECT date(timestamp_trunc(trip_start_timestamp,week(monday))) as trip_week, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-01-01" and "2023-06-30"GROUP BY trip_weekORDER BY trip_week DESC)SELECT trip_week, trip_total_revenue, if ( COUNT(*) OVER (ORDER BY trip_week ASC ROWS BETWEEN 12 PRECEDING AND 1 PRECEDING) = 12, AVG(trip_total_revenue) OVER (ORDER BY trip_week ASC ROWS BETWEEN 12 PRECEDING AND 1 PRECEDING), NULL ) AS moving_averageFROM daily_dataORDER BY trip_week DESC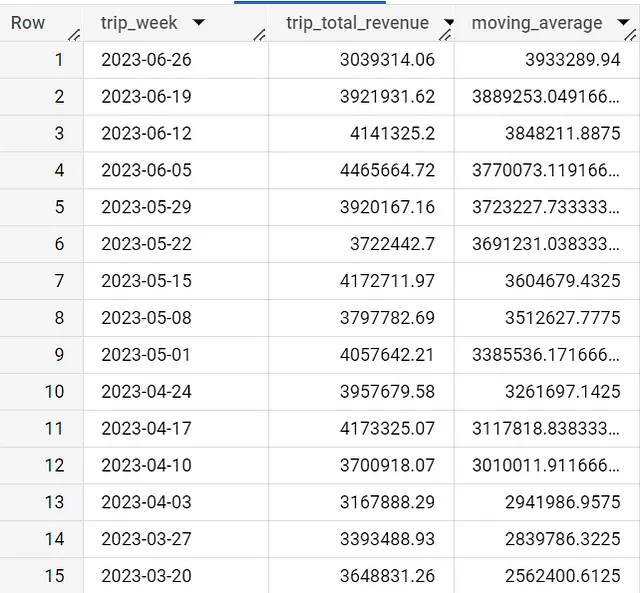
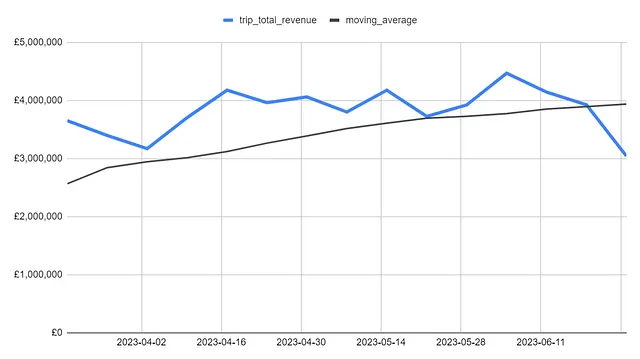
収益を移動平均とともにプロットすると、移動平均が4月以降毎週上昇し続けていることが分かります。移動平均がなければ、低収益の週に目が行きがちで、全体像が見えにくくなるでしょう。
異常検出のためのZスコアの計算
Zスコアの計算 = (x – 平均) / 標準偏差
Zスコアは、他の数値群と比較して特定の数値がどれだけ普通であるかを測定する方法です。標準偏差に基準化して、特定の数値が群の平均からどれくらいの標準偏差離れているかを示します。
if ( COUNT(*) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 30 PRECEDING AND 1 PRECEDING) = 30, round ( ( trip_total_revenue - AVG(trip_total_revenue) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 30 PRECEDING AND 1 PRECEDING) ) / stddev(trip_total_revenue) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 30 PRECEDING AND 1 PRECEDING) ,1), NULL ) AS z_score_30_dayこの例では、trip_total_revenueの実際の値から過去30日間の平均日次収益を引きました。
そして、それを30日間の標準偏差で割りました。これにより、特定の収益日が平均値にどれだけ近いか、またはその値が平均値からどれだけの標準偏差離れているかがわかります。
以下のように、チャートに表示されると便利なメトリックです。データに文脈を与えるためです。表示されているのは過去30日間のデータですが、zスコアは前の30日間と比較して容易に比較できるため、ピークやディップの場所が重要ではないように見える箇所でも、zスコアがその日のパフォーマンスが通常とどれほど異なるかを強調してくれます。
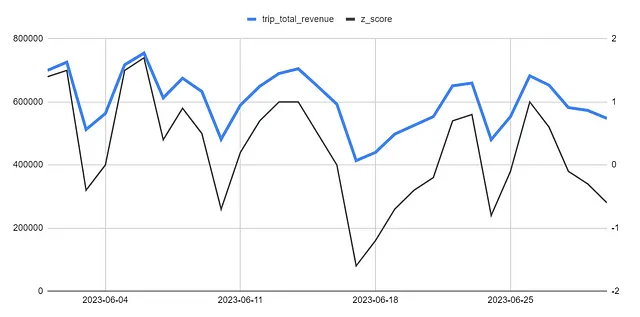
このようなレポートでは、異常なイベントが発生したと示す値を設定する必要があります。上記のチャートでは、どの日付も異常ではないと言えますが、一般的な値は3(つまり3つの標準偏差)です。ただし、これはデータの変動性に完全に依存します。
完全なクエリ
with daily_data as (SELECT (trip_start_timestamp) as trip_start_date, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-01-01" and "2023-06-30"GROUP BY trip_start_dateORDER BY trip_start_date DESC)SELECT trip_start_date, trip_total_revenue, if ( COUNT(*) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 30 PRECEDING AND 1 PRECEDING) = 30, round ( ( trip_total_revenue - AVG(trip_total_revenue) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 30 PRECEDING AND 1 PRECEDING) ) / stddev(trip_total_revenue) OVER (ORDER BY trip_start_date ASC ROWS BETWEEN 30 PRECEDING AND 1 PRECEDING) ,1), NULL ) AS z_score_30_dayFROM daily_dataORDER BY trip_start_date DESC月間トップランキングのパフォーマンス
シカゴタクシーデータセットには数多くのタクシー会社があり、毎月のトップ3のパフォーマンスを示すのは誰かと自問することができます。
これを実現するために、ランキング分析関数を使用し、trip_monthでパーティション化し、trip_total_revenueで降順に並べ替えます。
rank() over (partition by trip_month order by trip_total_revenue desc) AS rankingただし、これは各月のデータセット内のすべての会社の結果を提供するため、上位3社のみではありません。したがって、データをフィルタリングするためにQUALIFY句を使用できます。これはWHERE句と同様に機能し、セレクト文で作成したウィンドウ関数を参照することができます。詳細はこちら。
以下の結果からは、3つの主要な会社がタクシーリングを支配していることが明確になります。
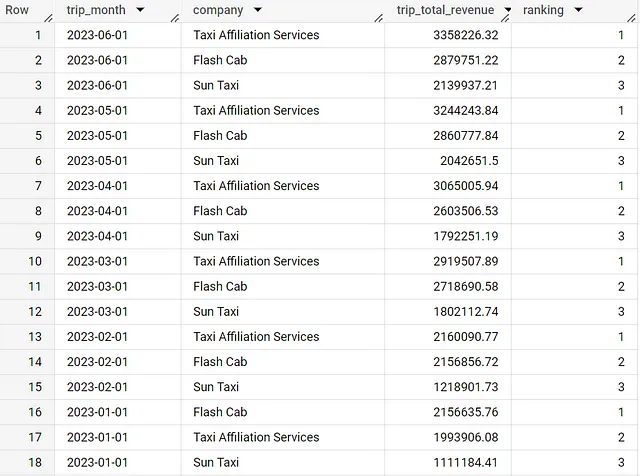
with daily_data as (SELECT date(timestamp_trunc(trip_start_timestamp,month)) as trip_month, company, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-01-01" and "2023-06-30"GROUP BY trip_month, companyORDER BY trip_month DESC)SELECT trip_month, company, trip_total_revenue, rank() over (partition by trip_month order by trip_total_revenue desc) AS rankingFROM daily_dataQUALIFY ranking <= 3ORDER BY trip_month DESC月次/四半期比較
月次および四半期ごとのレポートは、KPIの追跡やビジネスの進行方向の判断に不可欠です。ただし、BigQueryでレポートを作成することは、月ごとの変化を提供することが難しい場合があります。
以下の例のように、月次などのデータを取得した後は、LAG関数またはLEAD関数を使用して前月の収益を返すことができます。これにより、%の差を計算することができます。
LAGまたはLEADのどちらを使用しても同じ結果が得られますが、データの並べ替え方によって異なります。前月の収益を取得するため、ここではlagを使用するのが適切です。
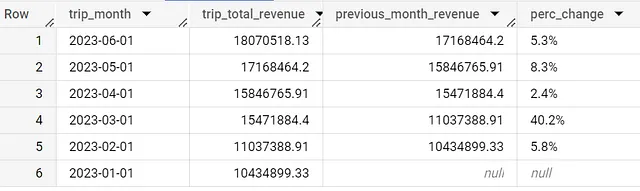
with daily_data as (SELECT date(timestamp_trunc(trip_start_timestamp,month)) as trip_month, round(sum(trip_total),2) as trip_total_revenueFROM `spreadsheep-case-studies-2023.chicago_taxies_2023.trip_data`WHERE date(trip_start_timestamp) between "2023-01-01" and "2023-06-30"GROUP BY trip_monthORDER BY trip_month DESC)SELECT trip_month, trip_total_revenue, lead(trip_total_revenue) over (order by trip_total_revenue asc) AS previous_month_revenue, round ( ( ( trip_total_revenue - lag(trip_total_revenue) over (order by trip_total_revenue asc) ) / lag(trip_total_revenue) over (order by trip_total_revenue asc) ) * 100 , 1) || "%" AS perc_changeFROM daily_dataORDER BY trip_month DESC以上でこの記事を終わります。ご質問や課題があれば、お気軽にコメントしてください。できるだけ早くお答えいたします。
私はBigQueryとLooker Studioのために頻繁に記事を執筆しています。興味があれば、VoAGIで私をフォローしてください。
すべての画像は、特に記載がない限り、著者によるものです。
皆さん、おしゃれでいてください!Tom
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
