インクから洞察:ブックショップの分析を使用してSQLとPythonのクエリを比較する
インクから洞察:ブックショップの分析を使用して、SQLとPythonのクエリを比較する
どのアプローチが探索的データ分析に適していますか?
SQLは、任意のデータサイエンティストのツールボックスの中核であり、大量のデータを扱っている人にとって、データを素早く分析するための能力は必須のスキルです。この記事では、SQLで使用するいくつかの基本クエリの例を示し、それらのクエリをPythonの類似スクリプトと比較して、同じ出力を生成する方法を比較します。
この分析では、架空の書店チェーン(Total Fiction Bookstore)の昨年の最高評価書籍に関する合成データを使用します。このプロジェクトのGitHubフォルダへのリンクはこちらから見つけることができます。詳細な分析の実行方法については、リンク先のJupyterノートブックをご覧ください。
ちなみに、この記事では主にSQLクエリに焦点を当てていますが、これらのクエリは、pandaSQLライブラリを使用してPythonと非常にシームレスに統合することもできます(このプロジェクトでは実際に行っています)。このクエリの構造についての詳細は、このプロジェクトのGitHubリンクのJupyterノートブックで詳しく説明していますが、このクエリの構造は一般的に以下のようになります:
query = """SELECT * FROM DATA"""output = sqldf(query,locals())outputpandaSQLは、通常のPandasデータセット操作よりもSQLクエリによりなじみのある人々にとって非常に実用的なライブラリであり、読みやすさも向上しています。
データセット
データセットの一部を以下に示します。書籍のタイトルと出版年、ページ数、ジャンル、書籍の平均評価、著者、販売部数、および書籍の収益の列があります。
年代別収益分析
書店で最も収益性の高い書籍がどの年代に発売されたかを知りたいとしましょう。元のデータセットには、書籍が発行された年代を示す列はありませんが、これは比較的簡単にデータに入力することができます。年を割り算の商で割り、10を乗じて年代データを取得するために、年を割り算の商で割り、10を乗じて年代データを取得するためのサブクエリを実行します。その後、年代別に収益を集計し、収益の合計によって最も収益性の高い書店の年代を取得します。
WITH bookshop AS(SELECT TITLE, YEARPUBLISHED,(YEARPUBLISHED/10) * 10 AS DECADE,NUMPAGES, GENRES, RATING, AUTHOR, UNITSSOLD,REVENUEfrom df)SELECT DECADE, SUM(REVENUE) AS TOTAL_REVENUE,ROUND(AVG(REVENUE),0) AS AVG_REVENUEFROM bookshopGROUP BY DECADEORDER BY TOTAL_REVENUE DESC比較すると、Pythonで同等の出力は以下のコードスニペットのようになります。フロア除算を実行して年代を出力するラムダ関数を適用し、そこから年代別に集計し、結果を収益の合計でソートします。
# creating df bookshopbookshop = df.copy()bookshop['Decade'] = (bookshop['YearPublished'] // 10) * 10# group by decade, agg revenue by sum and meanresult = bookshop.groupby('DECADE') \ .agg({'Revenue': ['sum', 'mean']}) \ .reset_index()result.columns = ['Decade', 'Total_Revenue', 'Avg_Revenue']# sorting by decaderesult = result.sort_values('Total_Revenue')Pythonスクリプトでは、同じ結果を得るためにより多くの独立したステップが必要であり、関数は初めの一目では分かりにくくて扱いにくいです。それに比べて、SQLスクリプトはプレゼンテーションがはるかに明確で、読みやすいです。
次に、このクエリを使用して、年代ごとの書籍の収益トレンドを視覚化し、以下のスクリプトを使用してmatplotlibのグラフを設定できます。棒グラフは年代別の総収益を示し、散布図は平均書籍収益をセカンダリ軸に表示します。
# 主軸(総収益)の作成fig、ax1 = plt.subplots(figsize=(15, 9))ax1.bar(agg_decade['DECADE'], agg_decade['TOTAL_REVENUE'], width = 0.4, align='center', label='総収益(ドル)')ax1.set_xlabel('年代')ax1.set_ylabel('総収益(ドル)', color='blue')# 主軸のグリッド線の調整ax1.grid(color='blue', linestyle='--', linewidth=0.5, alpha=0.5)# セカンダリ軸(平均収益)の作成ax2 = ax1.twinx()ax2.scatter(agg_decade['DECADE'], agg_decade['AVG_REVENUE'], marker='o', color='red', label='平均収益(ドル)')ax2.set_ylabel('平均収益(ドル)', color='red')# セカンダリ軸のグリッド線の調整ax2.grid(color='red', linestyle='--', linewidth=0.5, alpha=0.5)# ax1とax2のy軸の範囲を同じに設定ax1.set_ylim(0, 1.1*max(agg_decade['TOTAL_REVENUE']))ax2.set_ylim(0, 1.1*max(agg_decade['AVG_REVENUE']))# 両方の軸の凡例を結合lines、labels = ax1.get_legend_handles_labels()lines2, labels2 = ax2.get_legend_handles_labels()ax2.legend(lines + lines2, labels + labels2, loc='upper left')# タイトルの設定plt.title('年代別の総収益と平均収益')# グラフの表示plt.show()以下に、可視化結果が表示されます。1960年代に出版された書籍は、Total Fiction Bookstoreで19万2,000ドル以上の収益を生み出しているようです。それに対して、1900年代のリストに載っている書籍は平均的にはより収益性が高いものの、1960年代の書籍ほどよく売れていません。

平均書籍収益は、出版された書籍の全ての年代において総収益と同様の傾向を示しています。ただし、平均的には1900年代と1980年代の書籍はより収益性が高いものの、全体的には売れていません。
著者分析
次に、リストに含まれる上位10人の著者のデータを取得し、それらの著者が生成した総収益で並べ替えるというクエリを考えます。このクエリでは、リストに含まれる書籍の総数、それらの書籍が生成した総収益、書籍ごとの平均収益、および書店での書籍の平均評価を知りたいとします。この質問はSQLを使用して簡単に回答できます。COUNTステートメントを使用して著者が作成した書籍の総数を取得し、AVGステートメントを使用して平均収益と評価を著者ごとに取得することができます。その後、これらのステートメントをディレクターでグループ化します。
SELECT AUTHOR,COUNT(TITLE) AS NUM_BOOKS,SUM(REVENUE) AS TOTAL_REVENUE,ROUND(AVG(REVENUE),0) AS AVG_REVENUE,ROUND(AVG(RATING),2) AS AVG_RATING_PER_BOOKFROM bookshopGROUP BY AUTHORORDER BY TOTAL_REVENUE DESCLIMIT 10同等のPythonスクリプトは次のようになります。長さはほぼ同じですが、同じ出力に対してははるかに複雑です。agg関数で各列の集計方法を指定する前に、著者ごとに値をグループ化し、その後、総収益で値をソートします。再び、SQLスクリプトは比較してもはるかに明確です。
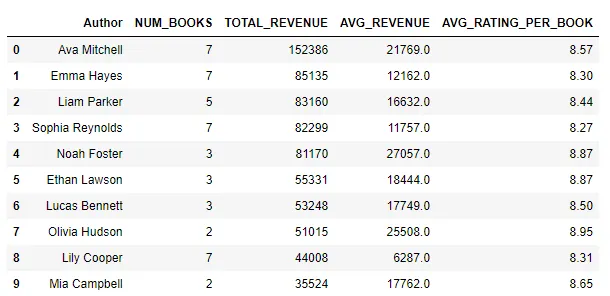
result = bookshop.groupby('Author') \ .agg({ 'Title': 'count', 'Revenue': ['sum', 'mean'], 'Rating': 'mean' }) \ .reset_index()result.columns = ['Author', 'Num_Books', 'Total_Revenue', 'Avg_Revenue', 'Avg_Rating_per_Book']# 総収益でソートresult = result.sort_values('Total_Revenue', ascending=False)# 上位10件result_top10 = result.head(10)以下のクエリの出力結果は、Ava Mitchellがトップであり、彼女の著書の売上高は15万2000ドルを超えています。Emma Hayesは2位で、売上高は8万5000ドルを超えています。Liam Parkerも8万3000ドルを超えており、2位に迫っています。
次のスクリプトを使用してmatplotlibでこの結果を可視化すると、総売上高の棒グラフが生成され、データポイントには平均売上高が表示されます。平均評価も2次軸にプロットされます。
# フィギュアと軸を作成fig1, ax1 = plt.subplots(figsize=(15, 9))# 総売上高の棒グラフをプロットax1.bar(agg_author['Author'], agg_author['TOTAL_REVENUE'], width=0.4, align='center', color='silver', label='総売上高(ドル)')ax1.set_xlabel('著者')ax1.set_xticklabels(agg_author['Author'], rotation=-45, ha='left')ax1.set_ylabel('総売上高(ドル)', color='blue')# 主軸のグリッドラインを調整ax1.grid(color='blue', linestyle='--', linewidth=0.5, alpha=0.5)# 平均売上高の散布図を作成ax1.scatter(agg_author['Author'], agg_author['AVG_REVENUE'], marker="D", color='blue', label='1冊あたりの平均売上高(ドル)')# 平均評価の散布図を2次軸に作成ax2 = ax1.twinx()ax2.scatter(agg_author['Author'], agg_author['AVG_RATING_PER_BOOK'], marker='^', color='red', label='1冊あたりの平均評価')ax2.set_ylabel('平均評価', color='red')# 2次軸のグリッドラインを調整ax2.grid(color='red', linestyle='--', linewidth=0.5, alpha=0.5)# 両方の軸の凡例を結合lines, labels = ax1.get_legend_handles_labels()lines2, labels2 = ax2.get_legend_handles_labels()ax1.legend(lines + lines2, labels + labels2, loc='upper right')# タイトルを設定plt.title('売上高と評価で上位10著者を比較')# グラフを表示plt.show()上記を実行すると、以下のグラフが表示されます:
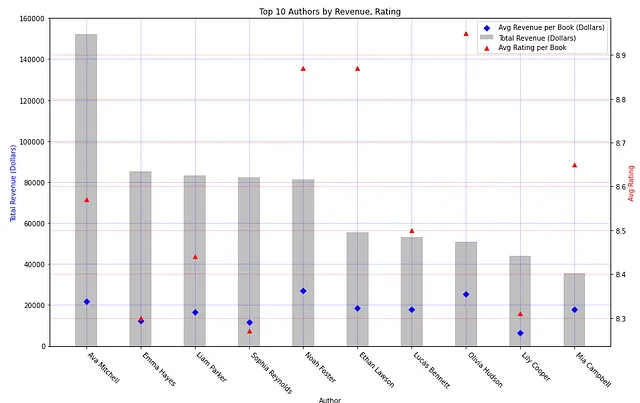
このグラフからは、売上高と著者ごとの平均評価には明確な相関関係がないことがわかります。Ava Mitchellは最も売上高が高いですが、上記の著者の中では評価の中央値に位置しています。Olivia Hudsonは平均評価が最も高いが、総投票数では8位です。著者の売上高と人気の間には明確なトレンドはありません。
書籍の長さと売上高の比較
最後に、書籍の長さに基づいて売上高がどのように異なるかを示したいとします。この質問に答えるために、まず書籍を4つのカテゴリに等分するために、書籍の長さの四分位数に基づいて値を生成し、case when文を使用して書籍をこれらのバケットに分類します。
まず、SQLで四分位数を定義し、サブクエリを使用してこれらの値を生成し、case when文を使用して書籍をこれらのバケットに分類します。
WITH PERCENTILES AS ( SELECT PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY NUMPAGES) AS PERCENTILE_25, PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY NUMPAGES) AS MEDIAN, PERCENTILE_CONT(0.75) WITHIN GROUP (ORDER BY NUMPAGES) AS PERCENTILE_75 FROM bookshop)SELECT TITLE, TITLE, REVENUE, NUMPAGES, CASE WHEN NUMPAGES< (SELECT PERCENTILE_25 FROM PERCENTILES) THEN '四分位数1' WHEN NUMPAGES BETWEEN (SELECT PERCENTILE_25 FROM PERCENTILES) AND (SELECT MEDIAN FROM PERCENTILES) THEN '四分位数2' WHEN NUMPAGES BETWEEN (SELECT MEDIAN FROM PERCENTILES) AND (SELECT PERCENTILE_75 FROM PERCENTILES) THEN '四分位数3' WHEN NUMPAGES > (SELECT PERCENTILE_75 FROM PERCENTILES) THEN '四分位数4' END AS PAGELENGTH_QUARTILEFROM bookshopORDER BY REVENUE DESCまたは(SQLiteなどのパーセンタイル関数をサポートしていないSQL方言の場合)、「case when」ステートメントに手動で入力する前に四分位数を別々に計算することもできます。
--SQLite方言の場合SELECT TITLE, REVENUE, NUMPAGES,CASEWHEN NUMPAGES < 318 THEN 'Quartile 1'WHEN NUMPAGES BETWEEN 318 AND 375 THEN 'Quartile 2'WHEN NUMPAGES BETWEEN 375 AND 438 THEN 'Quartile 3'WHEN NUMPAGES > 438 THEN 'Quartile 4'END AS PAGELENGTH_QUARTILEFROM bookshopORDER BY REVENUE DESC同じクエリをPythonで実行する場合、numpyを使用してパーセンタイルを定義し、カット関数を使用して本をバケットに分類し、その後ページの長さで値をソートします。前述のように、このプロセスはSQLの同等のスクリプトよりも複雑です。
# numpyを使用してパーセンタイルを定義percentiles = np.percentile(bookshop['NumPages'], [25, 50, 75])# 計算されたパーセンタイルを使用してビンの境界を定義bin_edges = [-float('inf'), *percentiles, float('inf')]# バケットのラベルを定義bucket_labels = ['Quartile 1', 'Quartile 2', 'Quartile 3', 'Quartile 4']# ビンの境界とラベルに基づいて 'RUNTIME_BUCKET' 列を作成bookshop['RUNTIME_BUCKET'] = pd.cut(bookshop['NumPages'], bins=bin_edges, labels=bucket_labels)result = bookshop[['Title', 'Revenue', 'NumPages', 'PAGELENGTH_QUARTILE']].sort_values(by='NumPages', ascending=False)このクエリの出力は、seabornを使用してボックスプロットとして可視化することができます。ボックスプロットを生成するために使用されるスクリプトの一部を以下で確認することができます。ランタイムのバケットは正しい順序で手動でソートされていることに注意してください。
# プロットのスタイルを設定sns.set(style="whitegrid")# 収益バケットの順序を設定pagelength_bucket_order = ['Quartile 1', 'Quartile 2', 'Quartile 3', 'Quartile 4']# ボックスプロットを作成plt.figure(figsize=(16, 10))sns.boxplot(x='PAGELENGTH_QUARTILE', y='Revenue', data=pagelength_output, order = pagelength_bucket_order, showfliers=True)# ラベルとタイトルを追加plt.xlabel('PageLength Quartile')plt.ylabel('Revenue (Dollars)')plt.title('Boxplot of Revenue by PageLength Bucket')# プロットを表示plt.show()以下のボックスプロットをご覧ください。各本の長さの四分位ごとの中央値収益は、本が長くなるにつれて上昇傾向にあります。これは、本が長いほど書店での収益が高いことを示唆しています。
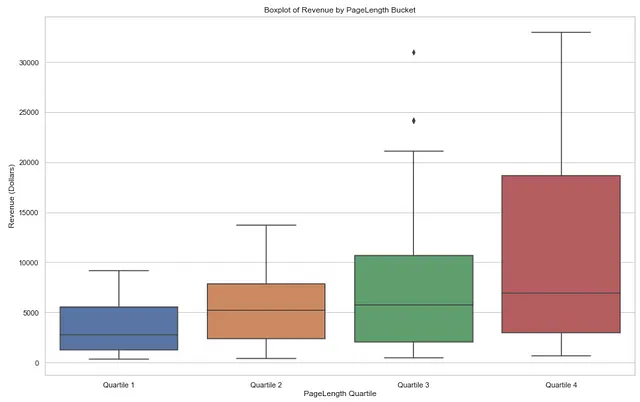
また、4番目の四分位範囲は他の四分位範囲と比べてはるかに広いです。これは、大きな本の価格帯にはより多くの変動があることを示しています。
最終的な考察とさらなる応用
結論として、データ解析クエリにおけるSQLの使用は、同等の操作をPythonで行う場合よりも一般にはるかに簡単です。SQLのクエリはPythonのクエリよりも書きやすく、同じ結果を広く生成することができます。どちらが優れていると主張するつもりはありません。この分析では両方の言語の組み合わせを使用しています。むしろ、両方の言語を組み合わせて使用することで、より効率的かつ効果的なデータ解析が可能になると考えています。
したがって、Pythonクエリに比べてSQLクエリの書きやすさが高いため、プロジェクトの初期のEDAを実行する際にはSQLを使用することが自然です。この記事で示したように、SQLは読み書きがはるかに簡単であり、特に初期の探索的なタスクには特に有利です。私はプロジェクトを開始するときによく使用し、SQLクエリの十分な理解力を持っている人にはこのアプローチをお勧めします。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
