「なぜOpenAIのAPIは英語以外の言語に対してより高価なのか」
なぜOpenAIのAPIは英語以外の言語に対して高価なのか
言葉を超えて: バイトペアエンコーディングと Unicode エンコーディングが価格格差にどのように影響するか

OpenAIのAPIのコストを推定する方法について最近の記事を公開した後、中国語、日本語、韓国語(CJK文字を使用する言語)など、英語よりもOpenAI APIの価格がはるかに高いことに気づいたという興味深いコメントを受け取りました。
私はこの問題については知りませんでしたが、すぐにこれは活発な研究分野であることに気づきました。今年の初めに、Petrovらによる「言語モデルトークナイザーによる言語間の公平性の低下」という論文[2]が、「同じテキストを異なる言語に翻訳すると、トークン化の長さが劇的に異なることがあり、一部の場合には15倍の違いがある」と示しています。
トークン化とは、テキストをトークンのリストに分割するプロセスであり、トークンはテキスト内の一般的な文字の連続です。
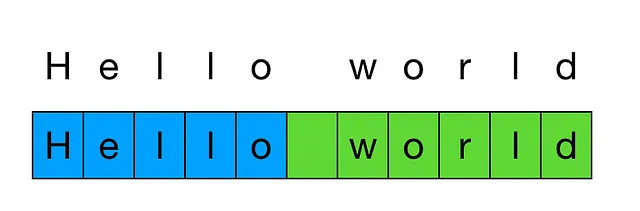
トークン化の長さの違いは問題です。なぜなら、OpenAIのAPIは1,000トークンの単位で請求されるからです。したがって、同等のテキストにおいて15倍のトークンがある場合、APIのコストは15倍になります。
実験: 異なる言語でのトークン数
フレーズ「Hello world」を日本語に翻訳(こんにちは世界)し、ヒンディー語に転写(हैलो वर्ल्ड)してみましょう。OpenAIのGPTモデルで使用されるcl100k_baseトークナイザーで新しいフレーズをトークン化すると、次の結果が得られます(これらの実験に使用したコードは記事の最後にあります)。
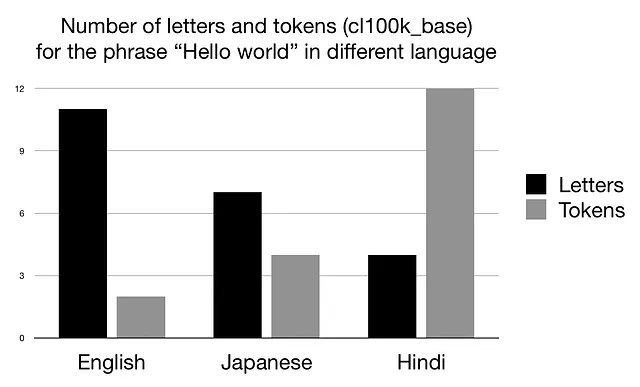
上記のグラフから、2つの興味深い観察ができます:
- 文字数は…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「文書理解の進展」
- ビッグテックと生成AI:ビッグテックが生成AIを制御するのか?
- なぜ特徴スケーリングは機械学習において重要なのか?6つの特徴スケーリング技術についての議論
- 「ミケランジェロのAIいとこ:ニューランジェロは高精度な3D表面再構築が可能なAIモデルです[コードも含まれています]」
- 「ゴリラ – API呼び出しの使用能力を向上させる大規模言語モデルの強化」 翻訳結果はこちらです
- このAI論文は、古典的なコンピュータによって生成される敵対的攻撃に対して、量子マシンラーニングモデルがより良く防御される可能性があることを示唆しています
- 「自己修正手法を通じて、大規模言語モデル(LLM)の強化」