「なぜデータパイプラインには閉ループフィードバック制御が必要なのか」
なぜデータパイプラインには閉ループフィードバック制御が必要か
企業とクラウドの複雑さの現実は、ビジネスの目標を達成するために新たなレベルの制御と自律性が必要です
データチームがクラウド上でスケールアップするにつれて、データプラットフォームチームは責任を持つワークロードがビジネス目標に適合していることを確認する必要があります。数十人のデータエンジニアが数百の本番ジョブを構築するスケールでは、パフォーマンスの制御は技術的な問題から人的な問題まで様々な理由で不可能です。
現在の問題は、パイプラインインフラストラクチャをビジネスの目標に向かって自動的に推進するための閉ループフィードバックシステムの確立です。これについて具体的に詳しく説明しましょう。
現在のデータプラットフォームチームの問題
データプラットフォームチームは、経営陣からエンジニアまで、基本的に異なるステークホルダーを管理する必要があります。これらの2つのチームの目標はしばしば反対であり、プラットフォームマネージャーは両方から圧力を受けることがあります。
私たちが実際にプラットフォームマネージャーやデータエンジニアと行った多くの会話は、通常次のようになります:
「CEOはクラウドコストを下げ、SLAを遵守して顧客を満足させるように言っています」
では、問題は何ですか?
「問題は、私が直接何も変えることができないことです。他の人の助けが必要で、それがボトルネックになっています」
つまり、プラットフォームチームは手かせをかけられ、実際に改善を実施しようとすると非常に困難に直面します。次に、その理由について詳しく見てみましょう。
プラットフォームチームを邪魔しているものは何ですか?
- データチームは技術的な範囲外です — クラスタの調整や複雑な設定(Databricks、Snowflake)は時間のかかる作業であり、データチームは実際のパイプラインやSQLコードに集中したいと考えています。多くのエンジニアは、自分のジョブのスキルセットやサポート構造、さらにはコストについても知りません。原因を特定し問題を解決することも難しい作業であり、機能的なパイプラインの構築を妨げます。
- 抽象化のレイヤーが多すぎる — 1つのスタックに焦点を当ててみましょう:Databricksは独自のApache Sparkを実行し、クラウドプロバイダーの仮想化されたコンピューティング(AWS、Azure、GCP)上で動作し、さまざまなネットワークオプションとストレージオプション(DBFS、S3、Blob)があります。さらに、すべては独立してランダムに更新することができます。選択肢の数は圧倒的であり、プラットフォームの担当者がすべてが最新かつ最適であることを保証することは不可能です。
- レガシーコード — 残念な現実の1つは、単にレガシーコードです。会社内のチームは変更されることがあり、人々は来たり去ったりするため、時間の経過とともに特定のジョブに関する知識が薄れていくことがあります。特定のジョブを調整または最適化することはさらに困難になります。
- 変更は怖い — 変更に対する恐怖心があります。本番のジョブが順調に進行している場合、調整するリスクを冒したいと思うでしょうか?古い格言が思い浮かびます。「壊れていないなら修正しないでください」。この恐怖心は現実のものであり、ジョブが冪等でない場合や他の下流の影響がある場合、失敗したジョブは本当の頭痛の原因となります。ジョブのパフォーマンスを改善しようとすることに対する心理的な障壁が生じます。
- スケールするとジョブが多すぎる — 一般的に、プラットフォームマネージャーは数百、場合によっては数千の本番ジョブを監視します。企業の成長により、この数は増加するばかりです。上記のすべてのポイントを考慮しても、ローカルの専門家がいたとしても、一度に1つずつジョブを調整することは現実的ではありません。これは一部の優先度の高いジョブに対しては機能するかもしれませんが、会社の大部分のワークロードにはあまり手をつけられません。
明らかに、データプラットフォームチームがスケールで効率的なシステムを迅速に作ることは困難です。私たちは、パイプラインの構築方法におけるパラダイムシフトが解決策だと考えています。パイプラインには、人間が介在せずに常にビジネスの目標に向かって推進するための閉ループ制御システムが必要です。詳しく見てみましょう。
パイプラインのための閉ループフィードバック制御とは何ですか?
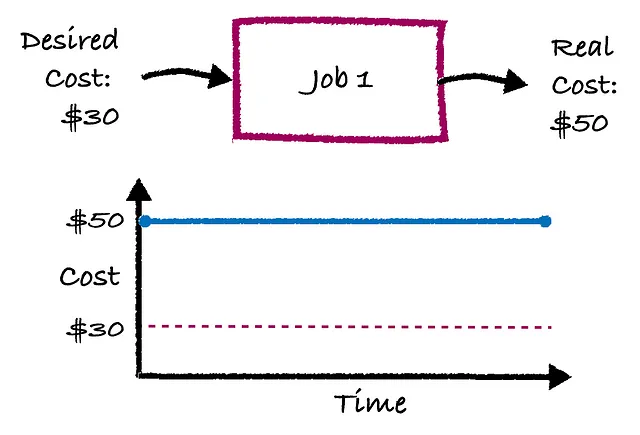
今日のパイプラインは、フィードバックのない「オープンループ」システムとして知られています。私が言っていることを説明するために、下の図は「ジョブ1」が毎日実行され、実行ごとに50ドルのコストがかかるというものです。ビジネスの目標は、そのジョブのコストを30ドルにすることです。しかし、誰かが実際に何かをするまで、そのコストは将来も50ドルのままです。コスト対時間のプロットで確認できるように。
代わりに、実際にジョブの出力統計をフィードバックするシステムがあったらどうでしょうか?次の日の展開を改善するために。それは次のようなものになるでしょう:
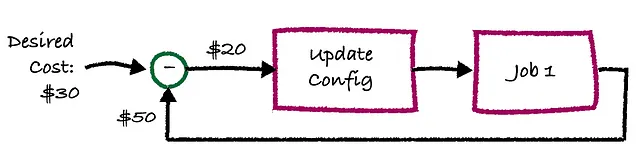
ここで見ているのは、この場合、望ましい「設定値」が30ドルのコストであるクラシックなフィードバックループです。このジョブは毎日実行されるため、実際のコストのフィードバックを取り、コストの差(この場合は20ドル)を受け取り、「ジョブ1」の設定の変更を適用します。たとえば、「設定の更新」ブロックは、Databricksクラスターのノード数を減らすかもしれません。
それは実際にはどのように見えるのですか?
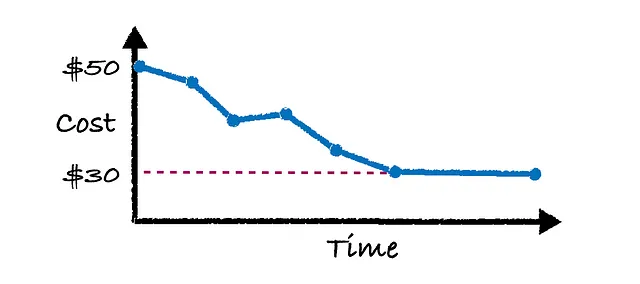
現実には、これは一度に起こるものではありません。 「設定の更新」モデルは、インフラストラクチャを微調整してコストを30ドルまで下げる責任があります。時間が経つにつれて、システムは改善され、最終的に以下の画像に示すように望ましいコスト30ドルに達するでしょう。
これはすべて素晴らしく聞こえるかもしれませんが、「設定の更新」ブロックとは何でしょうか?それは具体的な手法です。そのブロックは、数値目標のデルタを入力し、インフラストラクチャの設定またはコードの変更を出力する数学モデルです。
それは簡単に作成することはできず、目標によって異なります(例:コスト vs. 実行時間 vs. 利用率)。このモデルは、インフラストラクチャの変更がビジネス目標に与える影響を予測する必要があります。これは簡単なことではありません。
誰も未来を予測することはできません
1つの微妙な点は、「設定の更新」モデルは100%正確ではないということです。4番目の青い点では、コストが一時的に上昇することが実際に見られます。これは、モデルがコストを下げる設定の変更を予測しようとしているが、100%の正確さで予測することはできないためです。したがって、システムが「トレーニング」中である間、一度の実行でコストが上昇する場合があります。
しかし、時間の経過とともに、総コストが実際に減少していることがわかります。これは、設定の変更の影響を100%の正確さで予測することが不可能であるため、知的な試行錯誤プロセスと考えることができます。
重要なことは何ですか?- 任意の目標を設定して実行する
上記の手法は、コスト削減に限定されない一般的な戦略です。上記の「設定値」は、データプラットフォームの担当者が入力する目標であり、例えば実行時間がそれに当たります。
ジョブを1時間以内の実行時間(またはSLA)にしたいとします。上記のシステムに設定を調整させ、SLAが達成されるまで繰り返します。また、より複雑な場合は、コストとSLAの目標を同時に達成する必要がある場合はどうでしょうか?全く問題ありません。システムは、多くのパラメータに対して目標を達成するために最適化することができます。コストと実行時間に加えて、他のビジネスユースケースの目標もあります。
- リソース利用: コストやランタイムに関係なく、私は持っているリソースを適切に使用していますか?
- エネルギー効率: 炭素排出を最小限に抑えるために、可能な限り少ないリソースを消費していますか?
- 耐障害性: 私のジョブは実際には耐障害性がありますか?つまり、私は先取りされる可能性がある場合や、SPOT インスタンスが利用できない場合に過剰仕様にする必要がありますか?
- スケーラビリティ: 私のジョブはスケールしますか?入力データが10倍に急増した場合、私のジョブはクラッシュしますか?
- レイテンシ: 私のジョブはレイテンシの目標を達成していますか?応答時間の目標は達成されていますか?
理論的には、データプラットフォームの担当者は目標を設定するだけで、自動システムがインフラストラクチャを繰り返し改善し、目標を達成するまで進化させることができます。人間は関与せず、エンジニアも必要ありません。プラットフォームチームは、利害関係者から受け取った目標を設定するだけです。夢のようなものです。
これまではかなり抽象的な話をしてきました。ここからは、人々にとって魅力的な具体的なユースケースについて詳しく見ていきましょう。
例題1: ビジネス目標に基づいてジョブをグループ化する
データプラットフォームのマネージャーであり、数百の本番ジョブの運用を管理しているとします。現在、それぞれのジョブには独自のコストとランタイムがあります。以下は、ジョブがコストとランタイムのグラフ上にランダムに散らばっているカートゥーンの例を示す簡単なグラフです。
大規模なコスト削減が必要な場合はどうでしょうか?多くのジョブのランタイム(またはSLA)を一度に変更したい場合はどうでしょうか?現在のところ、すべてのジョブを変更するためにエンジニアに協力をお願いする必要があります(幸運を祈ります)。
ここで、すべてのジョブに対して上記の閉ループ制御システムが実装されていると想像してみてください。高レベルのビジネス目標(この場合はSLAランタイムの要件)を設定するだけで、フィードバック制御システムが目標を達成するのに最適なインフラストラクチャを見つけるために最善を尽くします。最終的な状態は次のようになります。
ここでは、各ジョブの色がSLAによって定義される異なるビジネス目標を表しています。バックグラウンドで動作する閉ループフィードバック制御システムは、クラスタ/ウェアハウスのサイズを変更したり、さまざまな設定を調整したり、さらにはパイプライン全体を調整したりして、最低のコストでSLAランタイムの目標を達成しようとします。通常、ジョブのランタイムが長いほど、コスト削減の機会が増えます。
例題2: ジョブの自動回復
ほとんどのデータプラットフォームの担当者が確認できるように、データパイプラインでは常に変化が起こっています。非常に一般的なシナリオとしては、データサイズが時間とともに増加することや、コードの変更があります。これらの変化は、コストやランタイムの乱れを引き起こすことがあります。
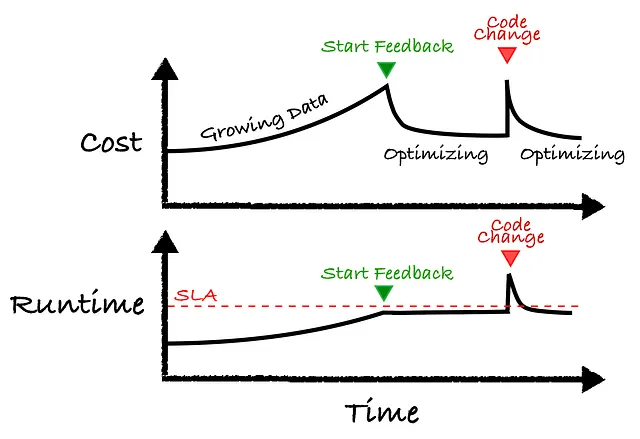
以下のイラストは基本的なコンセプトを示しています。左から右に例を進めてみましょう。
- 開始: ジョブがあり、時間とともにデータサイズが増加します。通常、クラスタは同じままで、それによってコストとランタイムが増加します。
- 開始時のフィードバック: 時間とともにランタイムがSLAの要件に近づき、フィードバック制御システムが緑の矢印で作動します。この時点で、制御システムはコストを最小化しながら赤い点線以下にクラスタを変更します。
- コードの変更: ある時点で開発者がコードの新しい更新をプッシュすると、コストとランタイムが急増します。フィードバック制御システムが作動し、クラスタを新しいコードの変更に適したように調整します。
これらの2つの例は、閉ループ制御パイプラインの潜在的な利点を説明しています。もちろん、実際には多くの詳細が省かれており、企業が遵守する必要がある設計原則もあります。
1つは、何か問題が発生した場合に設定を以前の状態に戻す方法です。繰り返しの回数が多くなる場合には、冪等性のあるパイプラインが理想的です。
結論
データパイプラインは複雑なシステムであり、他のどんな複雑なシステムと同様に、安定したパフォーマンスを確保するためにフィードバックと制御が必要です。これにより、技術的またはビジネス上の問題を解決するだけでなく、データプラットフォームやエンジニアリングチームが実際にパイプラインの構築に集中できるように大いに役立ちます。
前述したように、これのパフォーマンスは「更新構成」ブロックに依存しています。これはフィードバックループの成功に必要な重要な要素です。このブロックを構築することは容易ではなく、現在の主要な技術的な障壁です。これはアルゴリズムや機械学習モデルであり、過去のデータを利用することができます。過去数年間にわたり、私たちが取り組んできた主要な技術的要素です。
次の投稿では、このシステムをDatabricks Jobsに適用した実際の実装を紹介しますので、私たちの話が現実的であることを信じることができます!
Databricksパイプラインのクローズドループ制御についてもっと学びたいですか?Jeff ChouさんやSyncチームの他のメンバーにお問い合わせください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
