このAI論文では、COLT5という新しいモデルを提案していますこのモデルは、より高品質かつ高速な処理のために条件付き計算を使用する、長距離入力のためのものです
このAI論文では、COLT5という新しいモデルを提案していますこのモデルは、高品質かつ高速な処理のために条件付き計算を使用し、長距離入力に対応します


様々な自然言語処理タスクにおいて、長い文章をエンコードするためには、機械学習モデルが必要です。例えば、長い文書の要約や質問に対する回答などです。Transformerモデルを使用して長いテキストを処理すると、入力の長さに比例して注意コストが二次的に増加し、各入力トークンに対してフィードフォワードやプロジェクション層を適用する必要があり、計算コストが高くなります。近年、長い入力の注意機構の負荷を軽減するための「効率的なTransformer」戦略がいくつか提案されています。しかし、フィードフォワードやプロジェクション層は、特に大きなモデルの場合には計算負荷の大部分を占め、長い入力の解析が不可能になることがあります。本研究では、COLT5という新しいモデルファミリーを紹介します。COLT5は、注意機構とフィードフォワード層の両方にアーキテクチャの改良を組み込むことで、LONGT5をベースにして長い入力の高速処理を可能にします。
COLT5の基盤となる考え方は、特定のトークンが他のトークンよりも重要であるということ、そして重要なトークンにより多くの計算リソースを割り当てることで、より高品質な結果を低コストで得ることができるということです。例えば、COLT5は、各フィードフォワード層と各注意層を、すべてのトークンに適用する軽いブランチと、その入力と要素に特に選ばれた重要なトークンのために使用される重いブランチに分けています。通常のLONGT5に比べて、軽いフィードフォワードブランチの隠れ次元は重いフィードフォワードブランチよりも小さくなっています。また、重要なトークンの割合は文書の長さに応じて減少し、長いテキストの処理を可能にします。
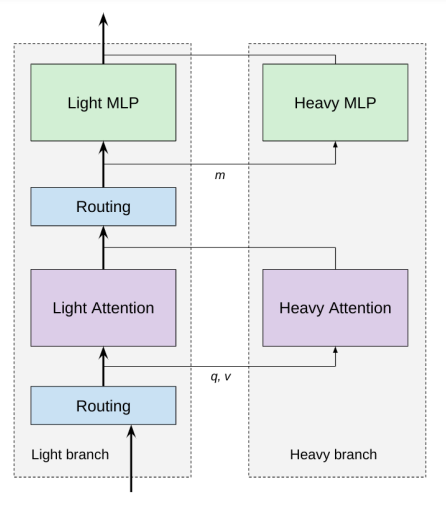
図1にはCOLT5の条件付きメカニズムの概要が示されています。COLT5のおかげで、LONGT5アーキテクチャはさらに2つの変更が加わりました。重い注意ブランチは、慎重に選ばれた重要なトークンの異なるセットに対して完全な注意を行い、軽い注意ブランチはより少ないヘッドを持ち、ローカルな注意を適用します。COLT5が導入するマルチクエリクロスアテンションは、推論を劇的に高速化します。さらに、COLT5はUL2の事前学習ターゲットを使用し、長い入力にわたる文脈における学習を可能にします。
- メタAIは、CM3leonを紹介します:最先端のテキストから画像生成を提供し、比類のない計算効率を実現するマルチモーダルのゲームチェンジャー
- 「DERAに会ってください:対話可能な解決エージェントによる大規模言語モデル補完を強化するためのAIフレームワーク」
- マルチモーダル言語モデル:人工知能(AI)の未来
Google Researchの研究者たちは、パフォーマンスと高速処理のために条件付き計算を使用する遠隔入力向けの新しいモデルであるCOLT5を提案しています。彼らは、COLT5がarXivの要約データセットやTriviaQAの質問応答データセットでLONGT5を上回り、SCROLLSベンチマークでもSOTAに達することを示しています。COLT5は「フォーカス」トークンの非線形スケーリングにより、長い入力の品質とパフォーマンスを大幅に向上させます。COLT5は、同じまたは優れたモデル品質で、非常に高速なファインチューニングと推論を行うことも可能です。COLT5の軽いフィードフォワード層と注意層はすべての入力に適用されますが、重いブランチは学習済みのルータによって選択された重要なトークンにのみ影響を与えます。彼らは、COLT5がさまざまな長い入力データセットでLONGT5を上回り、64kトークンまで非常に長い入力を効果的かつ効率的に処理できることを示しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- マイクロソフトAIは、高度なマルチモーダルな推論と行動のためにChatGPTとビジョンエキスパートを組み合わせたシステムパラダイム「MM-REACT」を提案しています
- 「自動推論とツールの利用(ART)を紹介します:凍結された大規模言語モデル(LLM)を使用して、推論プログラムの中間段階を迅速に生成するフレームワーク」
- Concrete MLと出会ってください:プライバシーの保護と安全な機械学習を可能にするオープンソースのFHEベースのツールキット
- 新たなディープ強化学習(DRL)フレームワークは、シミュレートされた環境で攻撃者に対応し、サイバー攻撃がエスカレートする前に95%をブロックすることができます
- 『AI論文によると、大規模な言語モデルの一般的なパターンマシンとしての異なるレベルの専門知識を説明します』
- 「AIのテスト:ChatGPTと他の大規模言語モデルの偽ニュース検出における詳細な評価」
- このAIニュースレターは、あなたが必要とするすべてです #56