倫理と社会のニュースレター#3:Hugging Faceにおける倫理的なオープンさ
『倫理と社会のニュースレター#3:Hugging Faceにおける倫理的なオープンさ』
ミッション:オープンで良い機械学習
私たちのミッションは、良い機械学習(ML)を民主化することです。MLコミュニティの活動を支援することで、潜在的な害の検証と予防も可能になります。オープンな開発と科学は、権力を分散させ、多くの人々が自分たちのニーズと価値観を反映したAIに共同で取り組むことができるようにします。オープンさは研究とAI全体に広範な視点を提供する一方で、リスクコントロールの少ない状況に直面します。
MLアーティファクトのモデレーションには、これらのシステムのダイナミックで急速に進化する性質による独自の課題があります。実際、MLモデルがより高度になり、ますます多様なコンテンツを生成する能力を持つようになると、有害なまたは意図しない出力の可能性も増大し、堅牢なモデレーションと評価戦略の開発が必要になります。さらに、MLモデルの複雑さと処理するデータの膨大さは、潜在的なバイアスや倫理的な懸念を特定し対処する課題を悪化させます。
ホストとして、私たちはユーザーや世界全体に対して潜在的な害を拡大する責任を認識しています。これらの害は、特定の文脈に依存して少数派コミュニティに不公平に影響を与えることが多いです。私たちは、各文脈でプレイしている緊張関係を分析し、会社とHugging Faceコミュニティ全体で議論するアプローチを取っています。多くのモデルが害を増幅する可能性がありますが、特に差別的なコンテンツを含む場合、最もリスクの高いモデルを特定し、どのような対策を取るべきかを判断するための一連の手順を踏んでいます。重要なのは、さまざまなバックグラウンドを持つアクティブな視点が、異なる人々のグループに影響を与える潜在的な害を理解し、測定し、緩和するために不可欠であるということです。
私たちは、オープンソースの科学が個人を力付け、潜在的な害を最小限に抑えるために、ツールや保護策を作成するとともに、ドキュメンテーションの実践を改善しています。
- フリーティアのGoogle Colabで🧨ディフューザーを使用してIFを実行中
- Hugging Faceは、Microsoftとの協力により、Azure上でHugging Faceモデルカタログを開始します
- Amazon SageMakerのHugging Face LLM推論コンテナをご紹介します
倫理的なカテゴリ
私たちの仕事の最初の重要な側面は、価値観とステークホルダーへの配慮を優先するML開発のツールとポジティブな例を促進することです。これにより、ユーザーは具体的な手順を踏むことで未解決の問題に対処し、ML開発の標準的な実践に代わる可能性のある選択肢を提示することができます。
ユーザーが倫理に関連するMLの取り組みを発見し、関わるために、私たちは一連のタグを編纂しました。これらの6つの高レベルのカテゴリは、コミュニティメンバーが貢献したスペースの分析に基づいています。これらは、倫理的な技術について無専門用語の方法で考えるための設計されています:
- 厳密な作業は、ベストプラクティスを考慮して開発することに特に注意を払います。MLでは、これは失敗事例の検証(バイアスや公正性の監査を含む)、セキュリティ対策によるプライバシーの保護、および潜在的なユーザー(技術的および非技術的なユーザー)がプロジェクトの制約について知らされることを意味します。
- コンセントフルな作業は、これらの技術を使用し、影響を受ける人々の自己決定を支援します。
- 社会的に意識の高い作業は、技術が社会、環境、科学の取り組みを支援する方法を示しています。
- 持続可能な作業は、機械学習を生態学的に持続可能にするための技術を強調し、探求します。
- 包括的な作業は、機械学習の世界でビルドし、利益を享受する人々の範囲を広げます。
- 探求的な作業は、コミュニティに技術との関係を再考させる不公正さと権力構造に光を当てます。
詳細はhttps://huggingface.co/ethicsをご覧ください。
これらの用語を探してください。新しいプロジェクトで、コミュニティの貢献に基づいてこれらのタグを使用し、更新していきます!
セーフガード
オープンリリースを「全てか無し」の視点で見ることは、MLアーティファクトのポジティブまたはネガティブな影響を決定する広範な文脈の多様性を無視しています。MLシステムの共有と再利用の方法に対するより多くの制御レバーがあることで、有害な使用や誤用を促進するリスクを減らすことができ、共同開発と分析をサポートします。よりオープンでイノベーションに参加できる環境を提供します。
私たちは、直接貢献者と関わり、緊急の問題に対処してきました。さらに進めるために、私たちはコミュニティベースのプロセスを構築しています。このアプローチにより、Hugging Faceの貢献者と貢献に影響を受ける人々の両方が、プラットフォームで利用可能なモデルとデータに関して制限、共有、追加のメカニズムについて情報提供することができます。私たちは、アーティファクトの起源、開発者によるアーティファクトの取り扱い、アーティファクトの使用状況について特に注意を払います。具体的には、次のような取り組みを行っています:
- コミュニティがMLアーティファクトやコミュニティコンテンツ(モデル、データセット、スペース、または議論)がコンテンツガイドラインに違反しているかどうかを判断するためのフラッグ機能を導入しました。
- ハブのユーザーが行動規範に従っているかを確認するために、コミュニティのディスカッションボードを監視しています。
- 最もダウンロードされたモデルについて、社会的な影響やバイアス、意図された使用法と範囲外の使用法を詳細に説明するモデルカードを堅牢に文書化しています。
- リポジトリのカードメタデータに追加できる「全ての視聴者に対してではない」タグなど、視聴者を尋ねられていない暴力的なコンテンツや性的なコンテンツを回避するためのタグを作成しています。
- モデルに対してOpen Responsible AI Licenses(RAIL)の使用を推進しており、LLMs(BLOOM、BigCode)などで使用しています。
- ミスユースや悪用の可能性が最も高いモデルやデータセットを分析する研究を行っています。
フラグ機能の使い方: 任意のモデル、データセット、スペース、またはディスカッションのフラグアイコンをクリックしてください:
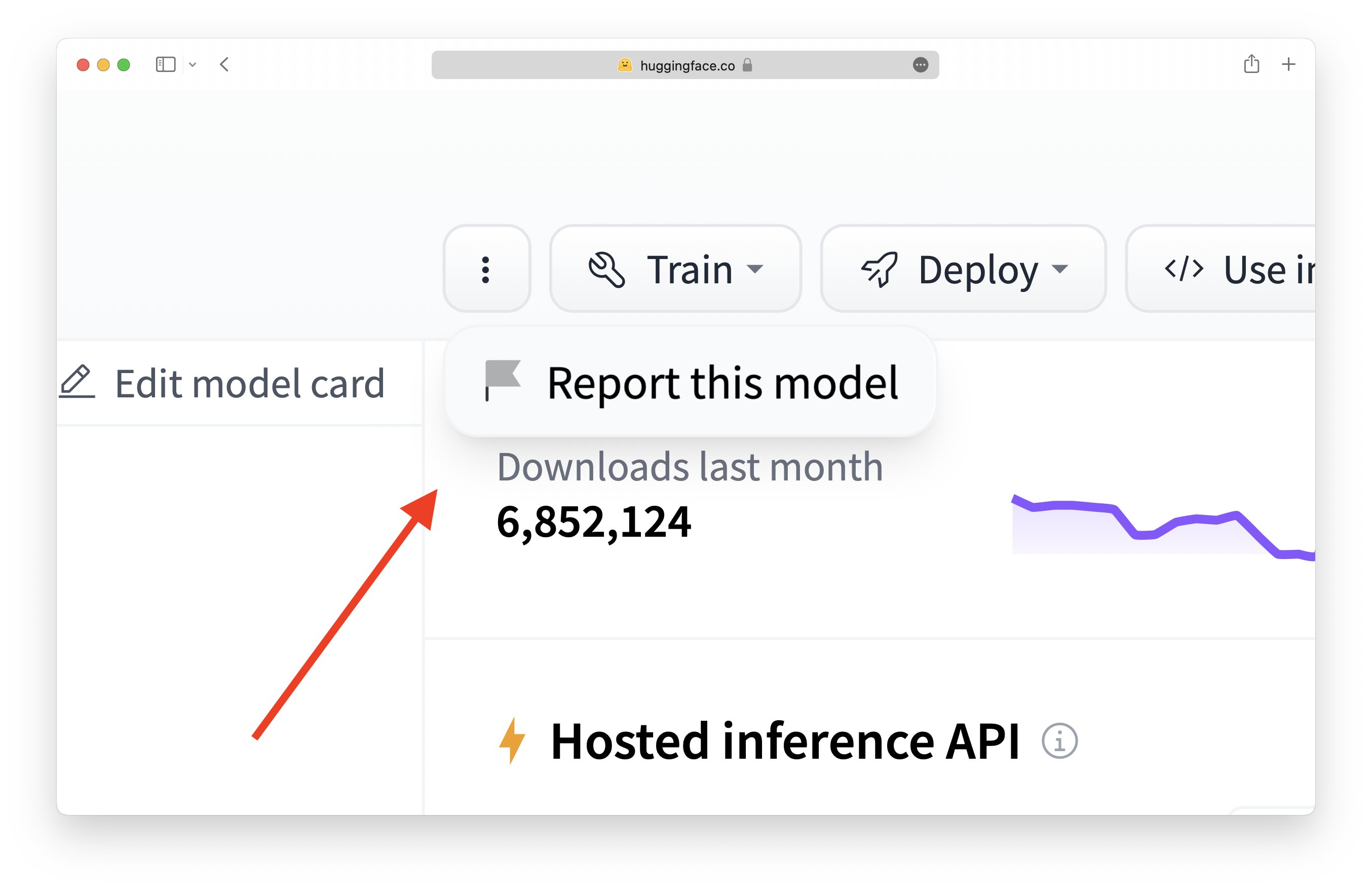 ログインしている場合は、”3つの点”ボタンをクリックしてリポジトリを報告(またはフラグ)する機能を表示することができます。これにより、リポジトリのコミュニティタブで会話が開始されます。
ログインしている場合は、”3つの点”ボタンをクリックしてリポジトリを報告(またはフラグ)する機能を表示することができます。これにより、リポジトリのコミュニティタブで会話が開始されます。
なぜこのアイテムをフラグしたのかを共有してください:
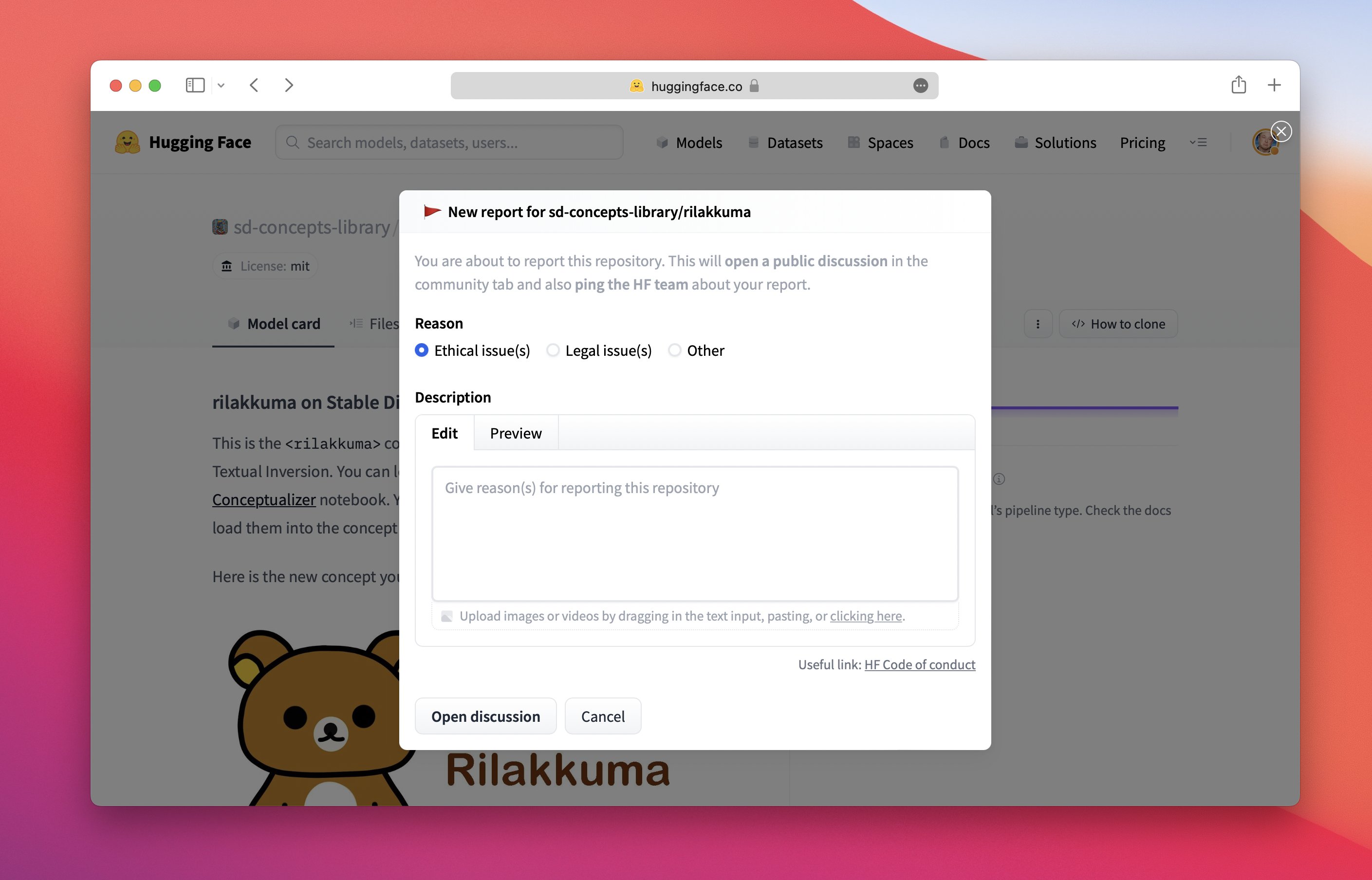 レポートに関連する文脈をできるだけ提供してください!これにより、リポジトリのオーナーやHFチームが対策を始めるのが容易になります。
レポートに関連する文脈をできるだけ提供してください!これにより、リポジトリのオーナーやHFチームが対策を始めるのが容易になります。
オープンサイエンスを優先するため、潜在的なハームについてはケースバイケースで検討し、共同学習と共有責任の機会を提供しています。ユーザーがシステムをフラグすると、開発者は懸念に直接かつ透明に対応することができます。この精神に則り、レポジトリのオーナーには報告に対して合理的な対応を行っていただくことをお願いしています。特に報告者が問題の説明を提供するために時間をかけた場合は、さらに重要です。また、レポートとディスカッションはプラットフォームの他のコミュニケーションの規範と同じく適用されることを強調します。モデレーターは、行動が憎悪的または虐待的になった場合にはディスカッションから離れるか終了することができます(行動規範を参照)。
コミュニティによって特定のモデルが高リスクとしてフラグされた場合、以下のことを検討します:
- ハブ全体でのMLアーティファクトの表示性の低下、トレンディングタブおよびフィードでの表示性の低下
- MLアーティファクトへのアクセスを管理するためのゲーティング機能の有効化(モデルとデータセットのドキュメントを参照)
- モデルをプライベートにする要求
- アクセスの無効化
「全ての対象者に適さない」タグの追加方法:
モデル/データのカードを編集 → タグセクションにnot-for-all-audiencesを追加 → PRを作成し、著者がマージするのを待ちます。マージされると、リポジトリに以下のタグが表示されます:

not-for-all-audiencesタグが付いたリポジトリは、訪れた際に以下のポップアップが表示されます:
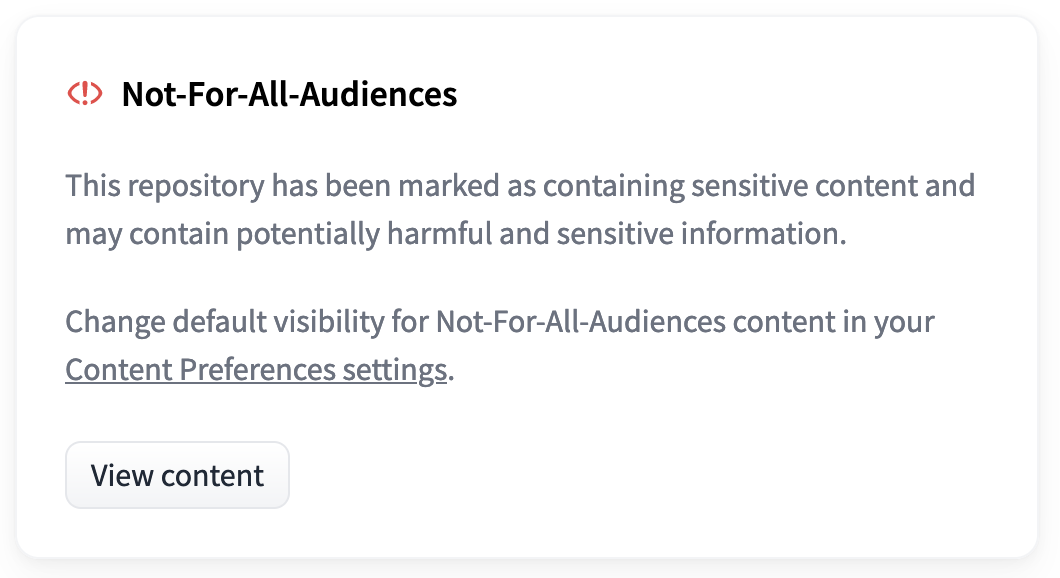
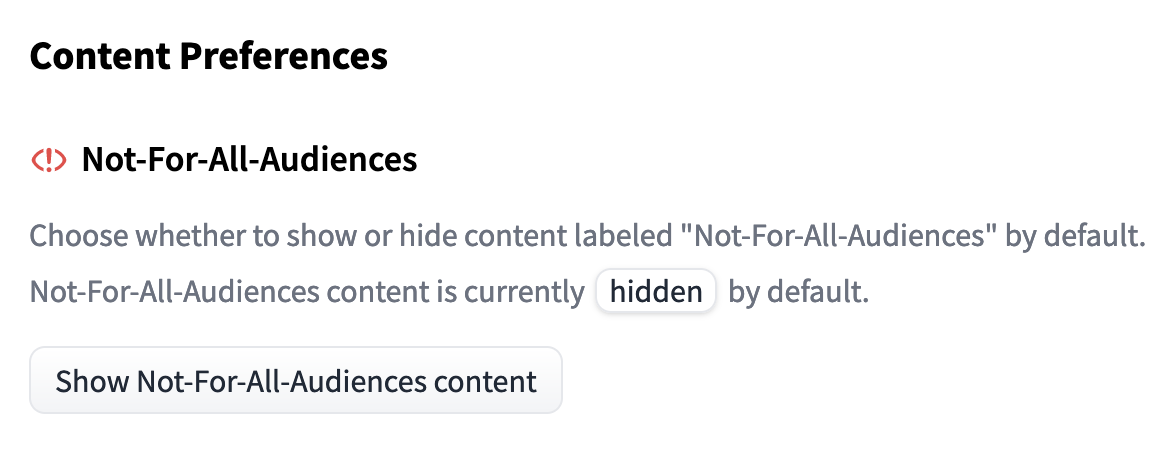
“コンテンツを表示”をクリックすると、通常通りリポジトリを表示することができます。もしnot-for-all-audiencesタグのついたリポジトリを常にポップアップなしで表示したい場合は、ユーザーのコンテンツ設定を変更することができます
オープンサイエンスには保護策が必要であり、私たちの目標の一つは、異なる価値観とのトレードオフに基づいた環境を作り出すことです。モデルのホスティングとアクセス提供に加えて、コミュニティとディスカッションの育成により、さまざまなグループが社会的な影響を評価し、良い機械学習を導くことができるようになります。
保護策に取り組んでいますか? Hugging Face Hubで共有しましょう!
Hugging Faceの最も重要な部分はコミュニティです。特にオープンサイエンスのためにMLの安全性を向上させる研究者の方々をサポートし、その成果を紹介したいと考えています!
Hugging Faceコミュニティの研究者による最近のデモやツールは以下のとおりです:
- John Kirchenbauer、Jonas Geiping、Yuxin Wen、Jonathan Katz、Ian Miers、Tom GoldsteinによるLLMのウォーターマーク(論文)
- Hugging Faceチームによるモデルカード生成ツール
- Ram Ananthによる画像の改ざんから保護するPhotoguard
お読みいただきありがとうございます! 🤗
〜Irene、Nima、Giada、Yacine、Elizabeth(Ethics and Societyメンバー代表)
このブログ記事を引用する場合は、以下をご利用ください(貢献の降順):
@misc{hf_ethics_soc_blog_3,
author = {Irene Solaiman and
Giada Pistilli and
Nima Boscarino and
Yacine Jernite and
Elizabeth Allendorf and
Margaret Mitchell and
Carlos Muñoz Ferrandis and
Nathan Lambert and
Alexandra Sasha Luccioni
},
title = {Hugging Face Ethics and Society Newsletter 3: Ethical Openness at Hugging Face},
booktitle = {Hugging Face Blog},
year = {2023},
url = {https://doi.org/10.57967/hf/0487},
doi = {10.57967/hf/0487}
}We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





