「Skill-it」とは、言語モデルの理解とトレーニングのためのデータ駆動型スキルフレームワークです
「Skill-it」 is a data-driven skill framework for language model understanding and training.


大規模言語モデル(LM)は、ソースコードの作成、オリジナルの芸術作品の作成、人との対話など、非常に能力が高いです。モデルの訓練に使用されるデータによって、これらのタスクを実行できるようになります。この訓練データを強化することで、特定のスキルを自然に引き出すことができます。訓練トークンの数が限られている場合、巨大なコーパスからこれらの能力に適したデータを選択する方法は明確ではありません。なぜなら、既存の最先端のLMデータ選択アルゴリズムのほとんどは、フィルタリングやさまざまなデータセットの組み合わせに関するヒューリスティックに依存しているからです。データがモデルの能力にどのように影響を与えるか、またこのデータを使用してLMのパフォーマンスを向上させる方法を記述するための形式的なフレームワークが必要です。
彼らは、人々が学ぶ方法からこのフレームワークを作成するためのヒントを得ました。学習階層を構成する能力という概念は、教育文献でよく知られています。たとえば、研究によって、数学や科学の概念を特定の順序で提示することが、生徒がそれらをより迅速に理解するのに役立つことが明らかになりました。彼らは、LMの訓練にどれだけ類似したスキルベースの順序付けが存在するかを知りたいと考えています。もし類似した順序付けが存在する場合、データ効率の良いトレーニングとLMのより深い理解を提供するかもしれません。たとえば、スペイン語の文法や英語の質問作成など、似たようなが容易なタスクからトレーニングを開始することが、スペイン語の質問生成のためのLMのトレーニングに役立つのかを知りたいと考えています。
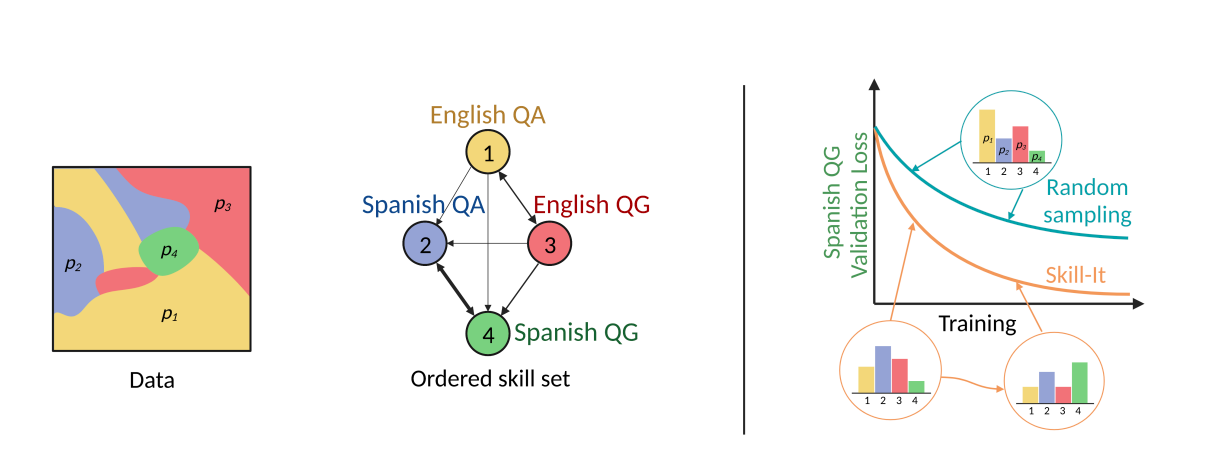
彼らは、スキルの順序付けの概念がデータとLMの訓練および振る舞いを結び付けるためのフレームワークの開発に役立つ可能性があるかどうかを調査しています。これを行うためには、データとスキルの相互作用に関連する2つの問題を解決する必要があります。まず、LMのスキルとスキルの順序の操作的な定義を定義し、データを使用してテストする必要があります。これにより、LMが特定の順序で最も効果的に学習する能力のセットが存在することが示されます。初期の研究では、メタデータのプロパティや埋め込みクラスタなどの意味的なグループ化がスキルを適切に表現し、モデルの学習プロセスを説明できるかどうかを調査しました。

たとえば、Alpacaデータセットを指示の種類で分割してデータの多様性を捉えました。しかし、指示の種類に基づいてサンプリングする方法とランダムサンプリングは、類似したパフォーマンスのモデルを生成することがわかりました。つまり、単に既存のデータグループのアイデアではスキルを特徴付けることはできません。モデルのトレーニングを本当に向上させるには、これらのスキルの定義を使用してサンプルの分布を構築する必要があります。単純な選択技術が直面する困難に着目し、スキルを効果的に学ぶデータ選択アルゴリズムの基準を作成します。能力のバランスや順序が従来のランダム一様サンプリングの技術では考慮されていないため、スキルの学習は最適化されていません。
たとえば、スペイン語と質問生成(QG)は、Natural Instructionsデータセットのそれぞれ5%と4%を占めていますが、スペイン語QGはわずか0.2%です。スキルはデータ内で均等に分布しておらず、より複雑なスキルは稀です。また、ランダムサンプリングは特定のトレーニングシーケンスやスキルの依存構造を考慮する方法を提供しません。サンプルレベルの順序付けは、カリキュラム学習などのより高度な戦略によって考慮されますが、スキルやその依存関係によっては考慮されません。能力の不均衡や順序の問題は、彼らの目標のフレームワークによって考慮される必要があります。スキルベースのシステムとして、モデルが関連するデータのスライスを使用して学習することができる行動の単位としてスキルを定義します。
順序付けられたスキルセットは、フルでも空でもない有向スキルグラフを持つスキルのグループです。前提となるスキルからスキルへのエッジが存在する場合、前提スキルも学習されることでスキルの学習に必要なトレーニング時間を短縮できます(図1の左、中央)。この操作的な定義を使用して、人工および実データセットに順序付けられたスキルセットが存在することを実証します。興味深いことに、これらの順序付けられたスキルセットは、スキルだけでなく必要なスキルもトレーニングすることで、才能を迅速に学ぶ必要があることを明らかにします。
彼らの観察によると、モデルが英語QGとスペイン語を追加して学習すると、総合的なトレーニングステップの予算を使って単にスペイン語QGでトレーニングするよりも、検証損失が4%低くなる場合があります。その後、彼らの理論に基づいて、LMがスキルをより速く学習するための2つのアプローチを提供しています:スキル層別サンプリングとオンライン汎化、SKILL-IT。スタンフォード大学、ウィスコンシン大学マディソン校、Together AI、シカゴ大学の研究者たちは、スキル層別選択を提案しています。これは、データセット内のスキルの不均等な分布の問題を解決するために、関連スキル(目標スキルや微調整のための必要スキルなど)を均等にサンプリングすることで学習スキルを明示的に最適化する直接的な方法です。
スキル層別サンプリングは静的であり、トレーニングの進行に伴う順序を考慮しませんので、トレーニングプロセスの初期段階で獲得された能力を過剰にサンプリングします。彼らはSKILL-ITを提案し、トレーニングスキルの組み合わせを選択するためのオンラインデータ選択技術を提供して、まだ学習していないスキルや影響力のある前提スキルにより高い重みを与えることで、この問題に対処します(図1 右)。データの予算とスキルグラフを仮定した場合、SKILL-ITは評価スキルの損失を最小化するためのトレーニングスキル上のオンライン最適化問題から開発されます。
評価スキルセットとトレーニングスキルセットの関連を基に、SKILL-ITは進行中の事前学習、微調整、またはドメイン外評価に適応することができます。これはオンラインミラーディセントに触発されたものです。人工データセットと実データセット上で、彼らは2つのモデルスケール(125Mと1.3Bパラメータ)でSKILL-ITを評価します。LEGOシミュレーションでは、ランダムにトレーニングデータとカリキュラム学習を選択する場合と比べて、連続的な事前トレーニングシナリオにおいて35.8ポイントの精度向上を実証します。同じ総合的なトレーニング予算の場合、スキルの組み合わせによる彼らのアルゴリズムは、微調整の設定で単独のスキルだけでトレーニングするよりも最大13.6%低い損失を達成することを示しています。
彼らのアルゴリズムは、自然な指示テストタスクデータセットのタスクカテゴリに対応する12の評価スキルのうち11つでランダムサンプリングやスキル層別サンプリングに比べて最も低い損失を達成することができます。これはトレーニングスキルが評価スキルと完全に一致しないドメイン外の設定でのトレーニングデータに対して行われます。最後に、彼らは最新のRedPajama 1.2兆トークンデータセットを使用した事例研究を提供しています。彼らはSKILL-ITによって生成されたデータ混合物を利用して3Bパラメータモデルを連続的に事前トレーニングします。彼らは、1Bトークンにおける精度に関して、SKILL-ITが3Bトークンのデータソース上の均等なサンプリングを上回ることを発見しました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 『ゴミ科学者にならない方法』
- データセットの凝縮の潜在能力を解き放つ:SRe^2LがImageNet-1Kで記録的な精度を達成
- シンガポール国立大学の研究者が提案するMind-Video:脳のfMRIデータを使用してビデオイメージを再現する新しいAIツール
- UTオースティンとUCバークレーの研究者が、アンビエントディフュージョンを紹介します:入力としての破損したデータのみを使用してディフュージョンモデルをトレーニング/微調整するためのAIフレームワーク
- 「LLMsを使用したモバイルアプリの音声と自然言語の入力」
- CDPとAIの交差点:人工知能が顧客データプラットフォームを革新する方法
- LangChainによるAIの変革:テキストデータのゲームチェンジャー
