「Seaborn KDE プロット上のデータポイントを自動的に抽出してラベル付けする方法」
「Seaborn KDE プロットのデータポイントを自動的にラベル付けする方法」

カーネル密度推定プロットは、データポイントの分布を視覚化するための方法です。ヒストグラムと同様に、カーネル密度推定プロットは、ガウスカーネルを使用してデータをスムージングします。ヒストグラムの代わりとして、カーネル密度推定は、比較しやすく、データ分布のパターンを強調するのにより適していると言えます。
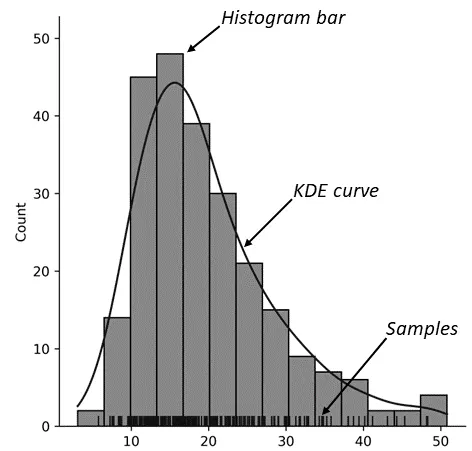
平均値、中央値、モードなどの統計的指標をカーネル密度推定プロットに注釈として追加することで、より意味のある情報を得ることができます。これらの指標の線を追加することは簡単ですが、きれいで整然とした見た目にするのは難しいです。
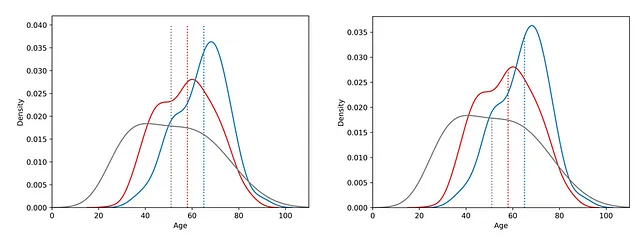
このクイックサクセスデータサイエンスプロジェクトでは、米国国勢調査と議会データセットを使用して、中央値の値をプログラムで複数のカーネル密度推定プロットに注釈として追加します。このアプローチにより、データセットの更新に自動的に適応するプロット注釈が保証されます。
KDEプロットの詳細については、以前の記事をご覧ください。
- エッジコンピューティングにおけるAI:リアルタイムを向上させるアルゴリズムの実装
- 「KafkaとRisingwaveを使用したFormula 1のストリーミングデータパイプラインの構築」
- オラクルと一緒にXRを開発しよう、エピソード6 AIサマライザー+ジェネレーター
データセット
合衆国には候補者の年齢法があるため、議会のメンバーの誕生日は公開されています。便宜上、現在の議会のメンバーの氏名、誕生日、政府の分野、政党のCSVファイルをすでに編纂し、このGistに保存しました。
米国の人口については、2023年7月の国勢調査局の月次公民人口表を使用します。前のデータセットと同様に、これは公開情報であり、このGistにCSVファイルとして保存しました。
ライブラリのインストール
このプロジェクトでは、プロットにseabornを、データ分析にpandasを使用する必要があります。これらのライブラリは、次のようにインストールできます:
condaを使用する場合:conda install pandas seaborn
pipを使用する場合:pip install pandas seaborn
コード
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
