「pandasのCopy-on-Writeモードの深い探求-パートII」
「pandasのCopy-on-Writeモードの深い探求-パートII」
Copy-on-Writeによるパフォーマンスの最適化の説明

はじめに
最初の投稿では、Copy-on-Writeメカニズムの動作について説明しました。コピーがワークフローに導入されるいくつかの箇所を強調しています。この投稿では、平均的なワークフローの遅延を防ぐための最適化に焦点を当てます。
私たちは、pandasの内部で使用されているテクニックを利用して、必要ない場合にはDataFrame全体をコピーせずにパフォーマンスを向上させる方法を利用しています。
私はpandasのコアチームの一員であり、これまでにCoWの実装と改善に大きく関与してきました。私はCoiledのオープンソースエンジニアであり、pandasの統合の改善やDaskのCoWへの準拠を確保するためにDaskに取り組んでいます。
防御的なコピーの削除
まず、最も影響力のある改善から始めましょう。多くのpandasのメソッドは、後でのインプレースの変更に対する副作用を避けるために、防御的なコピーを実行していました。
df = pd.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]})df2 = df.reset_index()df2.iloc[0, 0] = 100reset_indexではデータをコピーする必要はありませんが、結果を変更すると副作用が発生するため、ビューを返すことはできません。したがって、reset_indexでは防御的なコピーが実行されます。
Copy-on-Writeが有効になると、これらの防御的なコピーは不要になります。これは多くのメソッドに影響を与えます。完全なリストはこちらで確認できます。
さらに、DataFrameの列の一部を選択する場合、以前はコピーではなくビューが常に返されるようになります。
これらのメソッドのいくつかを組み合わせた場合のパフォーマンスについて見てみましょう:
import pandas as pdimport numpy as npN = 2_000_000int_df = pd.DataFrame( np.random.randint(1, 100, (N, 10)), columns=[f"col_{i}" for i in range(10)],)float_df = pd.DataFrame( np.random.random((N, 10)), columns=[f"col_{i}" for i in range(10, 20)],)str_df = pd.DataFrame( "a", index=range(N), columns=[f"col_{i}" for i in range(20, 30)],)df = pd.concat([int_df, float_df, str_df], axis=1)これにより、30の列、3つの異なるデータ型、200万行のDataFrameが作成されます。次のメソッドチェーンをこのDataFrameで実行しましょう:
%%timeit( df.rename(columns={"col_1": "new_index"}) .assign(sum_val=df["col_1"] + df["col_2"]) .drop(columns=["col_10", "col_20"]) .astype({"col_5": "int32"}) .reset_index() .set_index("new_index"))これらのメソッドは、CoWが無効な場合にはすべて防御的なコピーを実行します。
CoWなしのパフォーマンス:
2.45 s ± 293 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)CoWありのパフォーマンス:
13.7 ms ± 286 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)約200倍の改善です。CoWの潜在的な利点を示すために、わざとこの例を選びました。すべてのメソッドが同じくらい高速になるわけではありません。
インプレースの変更によってトリガされるコピーの最適化
前のセクションでは、防御的なコピーが不要になるメソッドが多数示されました。CoWは、同じデータが2つのDataFrameで参照される場合には同時に2つのオブジェクトを変更できないことを保証します。したがって、同じデータが2つのDataFrameで参照される場合には、できるだけ効率的なコピーを導入する必要があります。
前の投稿では、次の操作がコピーをトリガーする可能性があることが示されました:
df.iloc[0, 0] = 100コピーは、dfが別のDataFrameによって参照されているデータをバックアップしている場合にトリガーされます。私たちのDataFrameは、例えば整数の列nを持つと仮定しています。つまり、単一のブロックにバックアップされています。
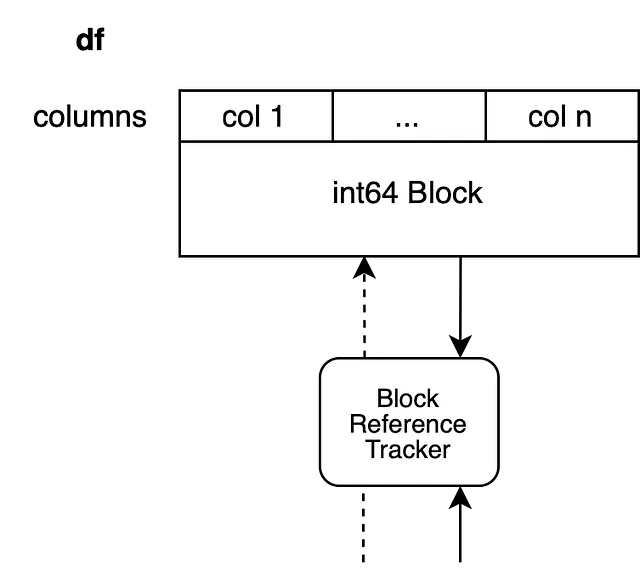
私たちの参照トラッキングオブジェクトはまた別のブロックを参照しているため、別のオブジェクトを変更せずにDataFrameをインプレースで変更することはできません。素朴なアプローチは、ブロック全体をコピーして終わりにすることです。
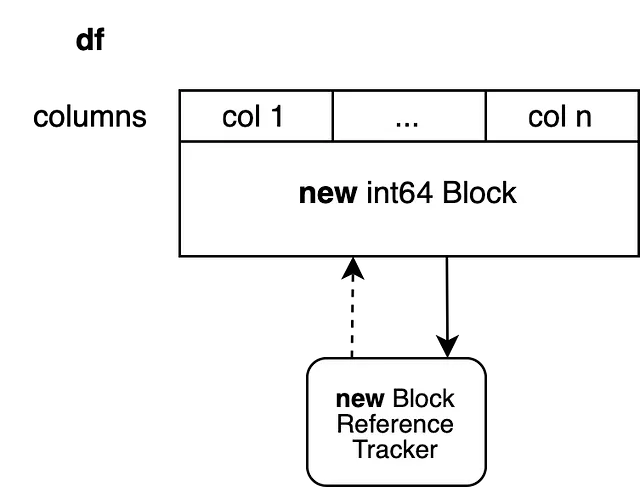
これにより、新しい参照トラッキングオブジェクトが設定され、新鮮なNumPy配列でバックアップされた新しいブロックが作成されます。このブロックには他の参照がありませんので、別の操作が再びインプレースで修正できます。このアプローチでは、コピーする必要のないn-1列がコピーされます。この問題を回避するために、ブロック分割と呼ぶテクニックを利用しています。
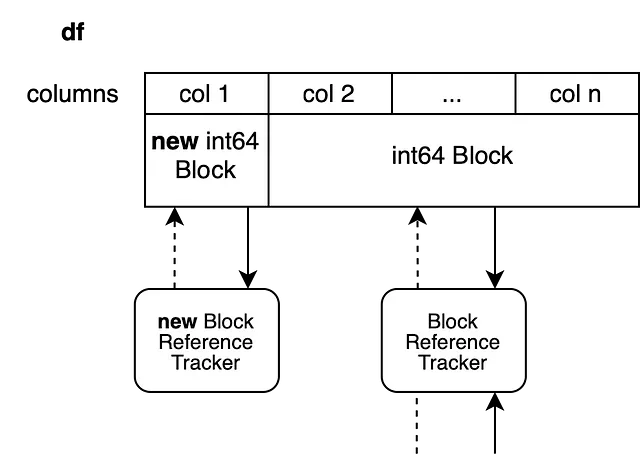
内部的には、最初の列のみがコピーされます。他のすべての列は前の配列上のビューとして取得されます。新しいブロックは他の列と参照を共有しません。古いブロックは前の値のビューであるため、他のオブジェクトと参照を共有します。
このテクニックには1つの欠点があります。最初の配列にはn列があります。列2からnのビューを作成しましたが、これにより全体の配列が生き残ります。また、最初の列に1つの列の新しい配列を追加しました。これにより、必要以上にメモリが生き残ることになります。
このシステムは異なるdtypesを持つDataFramesに直接変換されます。変更されないすべてのブロックはそのまま返され、インプレースで変更されるブロックのみが分割されます。
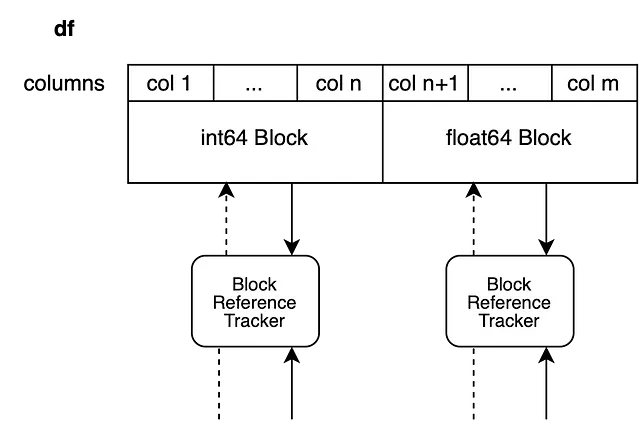
次に、列n+1の浮動小数点ブロックに新しい値を設定して、列n+2からmまでのビューを作成します。新しいブロックは列n+1のみをバックアップします。
df.iloc[0, n+1] = 100.5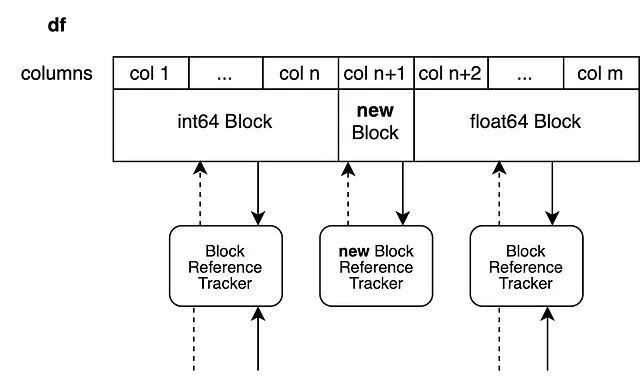
インプレースで動作できるメソッド
前述のインデックス操作は一般に新しいオブジェクトを作成せず、既存のオブジェクトをインプレースで変更します。また、DataFrameのデータ自体には触れないpandasのメソッドのもう一つのグループもあります。その中でも代表的な例がrenameです。Renameはラベルのみを変更します。これらのメソッドは上記で説明したレイジーコピーのメカニズムを利用できます。
replaceやfillnaのように、実際にインプレースで行うことができるメソッドのさらに別の三番目のグループもあります。これらは常にコピーをトリガーします。
df2 = df.replace(...)コピーをトリガーせずにデータをインプレースで変更すると、dfとdf2が変更され、CoWのルールに違反します。これは、これらのメソッドに対してinplaceキーワードを維持する理由の一つです。
df.replace(..., inplace=True)これにより、この問題は解消されます。これはまだ開かれた提案であり、異なる方向に進む可能性もあります。ただし、これは実際に変更された列にのみ適用されます。他のすべての列は常にビューとして返されます。つまり、値が1つの列にしか存在しない場合、1つの列のみがコピーされます。
結論
CoWがpandasの内部動作にどのように影響するか、およびこれがコードの改善にどのように反映されるかを調査しました。CoWにより、多くのメソッドが高速化されますが、一部のインデックス関連の操作では遅延が発生することもあります。以前はこれらの操作は常にインプレースで実行され、副作用が生じる可能性がありました。CoWではこれらの副作用がなくなり、1つのDataFrameオブジェクトの変更は他のオブジェクトに影響しません。
このシリーズの次の投稿では、CoWに準拠するためにコードを更新する方法と、将来的に避けるべきパターンについて説明します。
お読みいただきありがとうございました。Copy-on-Writeに関するご意見やフィードバックをお寄せいただければ幸いです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
