「Llama 2内のストップ生成の課題」
「Llama 2内のストップ生成の課題」
潜在的な解決策による探索

MetaによるLlama 2の発売は、以前は企業独自のAPIを介してのみアクセス可能であった、高性能な大規模言語モデルの時代の幕開けを告げ、コミュニティ内で興奮を引き起こしました。
しかし、これらのモデルには内在するいくつかの欠点を認識することが重要です。その中でも、停止生成の問題が目立ちます。私の個人的な経験では、これらのモデルはしばしば適切な「停止」ポイントを決定するのに苦労し、テキスト生成を終了するタイミングが不確定になることが多いです。
このブログ記事では、最小のLlama 2モデルであるLlama 2–7bモデルにおける停止生成の問題について詳しく調査し、いくつかの潜在的な解決策について議論します。次のセクションでの実装は、このGoogle ColabのノートブックでT4ランタイプを使用して見つけることができます。
停止生成の失敗
このセクションでは、Google ColabのT4 GPU(2.21クレジット/時間)を使用して、T4 GPUには十分な高RAMリソースが搭載されているLlama 2–7bモデルのパワーを利用します。T4 GPUには16 GBのVRAM容量があり、Llama 2–7bの重み(7b × 2バイト = 14 GBのFP16)を保持するのにちょうど十分です。
VRAMの使用量を効率的に管理するために、量子化という技術を使用します。量子化は、重みとアクティベーションを低精度のデータ型を使用して表現することにより、推論中の計算とメモリの要件を最小化するアプローチです。
では、以下のコードスニペットに詳しく入ってみましょう。ここでは、「meta-llama/Llama-2–7b-chat-hf」というモデルをBite and Byteの構成でロードし、このロードされたモデルに基づいたテキスト生成パイプラインを設定する方法を示します。
# bit and byte configurationbnb_config = transformers.BitsAndBytesConfig( load_in_4bit=True, # 4-bit quantization bnb_4bit_quant_type='nf4', # Normalized float 4 bnb_4bit_use_double_quant=True, # Second quantization after the first bnb_4bit_compute_dtype=bfloat16 # Computation type)model_id= "meta-llama/Llama-2-7b-chat-hf"device = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'# Llama 2のトークナイザtokenizer =transformers.AutoTokenizer.from_pretrained(model_id)# Llama 2のモデルmodel = transformers.AutoModelForCausalLM.from_pretrained( model_id, trust_remote_code=True, quantization_config=bnb_config, device_map='auto',)model.eval()# パイプラインの定義transformers.pipeline(model=model, tokenizer=tokenizer, return_full_text=True, # langchain expects the full text task='text-generation', # we pass model parameters here too max_new_tokens=500, # max number of tokens to generate in the output temperature=0.1, )この設定により、与えられたプロンプトに対して1分以内でテキストを生成することができます。以下に、簡単な質問「パリで何ができますか?」でテストした結果を示します(温度設定により結果は異なる場合があることに留意してください)。
フランスの首都であるパリは、その見事な建築物、美術館、歴史的な名所、ロマンチックな雰囲気で知られています。誰もが夢見る目的地です。以下は、パリでのおすすめのアクティビティです:1. 有名なランドマークを訪れる:エッフェル塔、ルーブル美術館、ノートルダム大聖堂、凱旋門、シャンゼリゼなどは必見の観光スポットです。2. 博物館や美術館を探索する:ルーブル美術館、ミュージェ・ドルセ、ポンピドゥーセンターなどは世界でも有名な博物館です。3. リバークルーズを楽しむ:セーヌ川クルーズは、都市のランドマークや橋を見ながら、その歴史や文化について学ぶ素晴らしい方法です。4. 街の地区を探検する:シャンゼリゼのおしゃれな通りからモンマルトルの魅力的な地区まで、それぞれのパリの地区には独自の個性と魅力があります。#ここではスペースの制限のために一部のテキストを省略しました#もちろん、数え切れないほどの明らかに、モデルは満足できる応答を生成するのに苦労しており、出力を終了するタイミングがわかりにくいようです。生成されたテキストをトークン化すると、モデルのトークナイザーでのeos(シーケンスの終了)トークンを表す2でないことが明らかになります。
モデルが提供するトークンのスコア(確率)を詳しく調査すると、トークンID 2(eso_token_id)のスコアが「-inf」であることに気付きました。これは、生成される可能性がないことを意味します。
問題の解決の試み
このセクションでは、問題に対処するためのいくつかの潜在的な解決策を探求します。ここで議論される解決策は積極的な取り組みを表していますが、常に問題の解決策を提供するわけではありませんので、頭に入れておくことが重要です。
Logits Processor
Llama 2のような言語モデルは、テキストトークンのシーケンスを入力とし、初期トークンから現在のトークンまでの文脈に基づいて次のトークンの条件付き確率のシーケンスを生成します。このような場合、モデルがeosトークンに出会う確率を高めるために、最大トークン数に近づいた時点でこれらの確率を手動で調整することが考慮される価値があります。これを行うために、eos_token_idとmax_lengthという2つの初期入力を持つカスタマイズされたLogitsProcessorである「EosTokenRewardLogitsProcessor」という名前を定義します:
class EosTokenRewardLogitsProcessor(LogitsProcessor): def __init__(self, eos_token_id: int, max_length: int): if not isinstance(eos_token_id, int) or eos_token_id < 0: raise ValueError(f"`eos_token_id`は正の整数でなければなりませんが、{eos_token_id}です") if not isinstance(max_length, int) or max_length < 1: raise ValueError(f"`max_length`は1より大きい整数でなければなりませんが、{max_length}です") self.eos_token_id = eos_token_id self.max_length=max_length def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor: cur_len = input_ids.shape[-1] # シーケンスの長さに応じてeos_tokenの報酬を80%のmax_lengthから徐々に増やす for cur_len in (max(0,int(self.max_length*0.8)), self.max_length ): ratio = cur_len/self.max_length num_tokens = scores.shape[1] # 語彙のサイズ scores[:, [i for i in range(num_tokens) if i != self.eos_token_id]] =\ scores[:, [i for i in range(num_tokens) if i != self.eos_token_id]]*ratio*10*torch.exp(-torch.sign(scores[:, [i for i in range(num_tokens) if i != self.eos_token_id]])) scores[:, self.eos_token_id] = 1e2*ratio return scoresクラスの「__call__」メソッドでは、シーケンスの長さに基づいてeos_tokenの確率(スコア)を強化します。指定された最大長の80%に近づいた時点で、eos_token_idのスコアを長さ比率に1e2を乗算して設定し、他のトークンのスコアを適切に調整します。
次に、パイプラインの定義でロジットプロセッサを宣言します:
pipe = transformers.pipeline(model=model, tokenizer=tokenizer, return_full_text=True, # langchain expects the full text task='text-generation', # we pass model parameters here too #stopping_criteria=stopping_criteria, # without this model rambles during chat logits_processor=logits_process_list, max_new_tokens=500, # max number of tokens to generate in the output temperature=0.1, )同じプロンプト「パリでできることは何ですか」と再びパイプラインを実行すると、次のような結果が得られます:
フランスの首都パリは、その見事な建築、美術館、歴史的な名所、ロマンチックな雰囲気で知られています。うまくいきました!完全な答えが得られました。短く見えるかもしれませんが、問題ありません。
ファインチューニング
モデルがEOSトークンを生成できない場合、それを指示することを考えてみるのはどうでしょうか?EOSトークンで結ぶ回答を含むデータセットを使用してモデルをファインチューニングすることにより、モデルのパフォーマンスを向上させるというコンセプトは、確かに探求する価値があります。
このセクションでは、QLoRAなどのパラメータ効率のよいファインチューニング(PEFT)メソッドを使用して、Llama 2-7bモデルをファインチューニングするためにこのブログ投稿で提案された基礎を恥ずかしげもなく利用します。前任者のLoRAと同様に、QLoRAは、コアモデルのパラメータを変更せずに、少数の訓練可能なパラメータ(アダプタ)を使用します。QLoRAは、2つの注目すべきイノベーションを導入しています。1つ目は、通常データに対する情報理論的に最適なデータ量子化方法である4ビットNormalFloat(NF4)、2つ目はDouble Quantizationです。詳細な理解については、このトピックにさらなる興味がある場合には、元の論文を参照してください。
まず、’timdettmers/openassistant-guanaco’というデータセットでモデルをトレーニングします。このデータセットは、「###」で人間とアシスタントの会話が区切られています。

トレーニングの前に、データをLlama 2プロンプトテンプレートに変換する必要があります:
<s>[INST] <<SYS>>{your_system_message}<</SYS>> {user_message_1} [/INST]ここではデータセットの変換の詳細は省略します。次に、トレーニングの主要な部分を以下のコードで見てみましょう:
# LoRAの設定を読み込むpeft_config = LoraConfig( lora_alpha=lora_alpha, lora_dropout=lora_dropout, r=lora_r, bias="none", task_type="CAUSAL_LM",)# 監督ファインチューニングのパラメータを設定するtrainer = SFTTrainer( model=model, train_dataset=dataset, peft_config=peft_config, dataset_text_field="text", max_seq_length=max_seq_length, tokenizer=tokenizer, args=training_arguments, packing=packing,)# モデルをトレーニングするtrainer.train()指示と応答から成るデータセットの文脈では、QLoRAメソッドと監督トレーナー(SFTainer)を使用して言語モデル(LLM)内の重みパラメータをファインチューニングしました。主な目的は、生成された回答とグラウンドトゥルースの応答との間の不一致を最小化することでした。
この設定の中で重要なパラメータは「lora r」であり、ランク分解の重み行列の2つの次元に対して比較的小さい値を表しています。トレーニングはこれらの2つの行列にのみ行われ、既存の重みを補完します。
250ステップでモデルをトレーニングし、トレーニングロスを以下のプロットに示します:
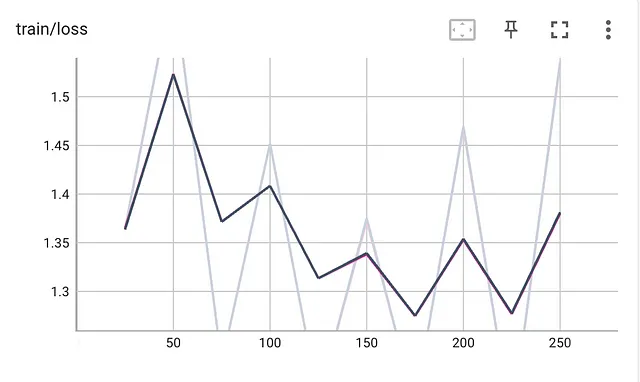
次に、ファインチューニングされたモデルを使用してパイプラインを実行しましょう。今度は以下のようになります:
フランスの首都パリは、その見事な建築物、豊かな歴史、文化的な名所で知られています。以下にパリでの人気のあるアクティビティのいくつかを紹介します:1. 代表的な名所を訪れる:エッフェル塔、トリンフィアーム凱旋門、ノートルダム大聖堂、ルーヴル美術館など、パリで最も有名な名所のいくつかを訪れることができます。2. 博物館や美術館を探索する:パリにはルーヴル美術館、オルセー美術館、ポンピドゥーセンターなど、世界クラスの多くの博物館や美術館があります。3. 庭園や公園を楽しむ:パリにはルクセンブルク庭園、テュイルリー庭園、シャン・ド・マルスなど、美しい庭園や公園がいくつかあります。4. セーヌ川クルーズに参加する:セーヌ川のクルーズは、市内の名所を見る素晴らしい方法であり、その歴史について学ぶことができます。5. シャンゼリゼ通りでショッピングをする:有名なアベニューには高級ブティックやデパート、カフェが並んでいます。6. カバレットショーに参加する:ムーランルージュは有名なカバレットで、活気に満ちたエンターテイニングなショーを提供しています。7. モンマルトルを訪れる:モンマルトルは魅力的な地区で、芸術的な雰囲気、ストリートパフォーマー、市内の素晴らしい景色で知られています。8. フードツアーに参加する:パリは美食で知られており、フードツアーは市内の有名な料理を試食する素晴らしい方法です。9. ヴェルサイユ宮殿を訪れる:ヴェルサイユ宮殿はパリのすぐ外にある美しい王宮です。10. ファッションショーに参加する:パリは世界のファッション首都であり、ファッションショーに参加することで最新のトレンドやスタイルを見ることができます。これはパリでの数多くのアクティビティの一部です。歴史や文化、食べ物やエンターテイメントなど、誰にでも何かがあります。これは非常に美しい回答です!
ボーナス:異なるプロンプトを与える
結局のところ、モデルの冗長性が問題ではない場合、私たちには効果的なトリックがあります。明確にプロンプトで簡潔な回答を求めるという方法です。たとえば、モデルに「パリで何ができますか?5つの文章以下で回答してください」と尋ねると、以下のような回答が得られます。
もちろんです!パリでできることは以下の5つです:1. パリの美しい景色を楽しめる象徴的なランドマーク、エッフェル塔の訪問。2. モナリザなどの有名な美術作品を鑑賞できるルーブル美術館の探索。3. セーヌ川沿いを散策し、美しい橋や魅力的な通りを楽しむ。4. 美しく歴史的なノートルダム大聖堂の訪問。5. 伝統的なビストロやレストランで美味しいフレンチ料理を楽しむ。これは短くても綺麗で完全な回答です。
停止基準:失敗した試み
興味のある方々には、Hugging FaceはStoppingCriteriaという別のAPIを導入しており、シーケンスを停止させるための特定の条件を設定することができます。ただし、特定のトークン(例:’\n’)に遭遇した場合にモデルを停止させるカスタマイズされた基準を定義する場合、このAPIでは十分な解決策を提供できないかもしれません。例えば、StopOnTokensクラスを作成しました:
# カスタム停止基準オブジェクトの定義class StopOnTokens(StoppingCriteria): def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool: for stop_ids in stop_token_ids: if torch.eq(input_ids[0][-len(stop_ids):], stop_ids).all(): return True return Falsestopping_criteria = StoppingCriteriaList([StopOnTokens()])しかし、モデルはまだ完全な回答を提供できません。
結論
このブログ記事では、Llama 2における生成の停止問題を強調し、いくつかの暫定的な解決策を紹介しました。再度言いますが、実装の詳細は省略していますので、ノートブックを詳しくご覧いただくことをおすすめします。

ただし、これらの解決策は短期的には応答の使いやすさを向上させることを目的としていますが、この問題に対する恒久的な修正策を心待ちにしています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
