「Amazon Comprehendのカスタム分類を使用して分類パイプラインを構築する(パートI)」
「Amazon Comprehendのカスタム分類を使用して分類パイプラインを構築する(パートI)」
「テキスト、音声、ソーシャルメディア、およびその他の非構造化データの中には、それを活用する方法を見つけ出した企業にとって競争上の優位性となり得ます。」
Deloitteの2019年の調査によると、組織の中で非構造化データを活用できると報告したのはわずか18%でした。データの大半、80%から90%は非構造化データです。これは未開拓の資源であり、企業に競争上の優位性を与える潜在的な可能性を秘めています。このデータから洞察を見つけ出すことは困難であり、特に分類、タグ付け、ラベル付けの努力が必要です。このような状況でAmazon Comprehendのカスタム分類は役立ちます。Amazon Comprehendは、テキストの中に有益な洞察や関連性を見つけ出すために機械学習を使用する自然言語処理(NLP)サービスです。
文書の分類には、ビジネスドメイン全体で重要な利点があります。
- 検索と取得の改善 – 文書を関連するトピックやカテゴリに分類することで、ユーザーが必要な文書を検索して取得するのが容易になります。特定のカテゴリ内で検索を行うことで結果を絞り込むことができます。
- ナレッジマネジメント – 文書を体系的に分類することは、組織の知識ベースを整理するのに役立ちます。関連する情報を見つけることや関連コンテンツ間の関係を見ることが容易になります。
- 効率化されたワークフロー – 自動文書ソートにより、請求書処理、顧客サポート、規制コンプライアンスなどの多くのビジネスプロセスが効率化されます。文書は自動的に適切な人物またはワークフローにルーティングされます。
- コストと時間の節約 – 手動の文書分類は退屈で時間と労力がかかる作業です。AIの技術を使用することで、低コストで短時間で数千の文書を分類することができます。
- 洞察の生成 – 文書カテゴリのトレンドを分析することで有益なビジネスの洞察を得ることができます。たとえば、製品カテゴリの顧客からの苦情が増えることは、解決すべき問題を示すかもしれません。
- ガバナンスとポリシーの強制 – 文書分類ルールを設定することで、文書が組織のポリシーやガバナンス基準に適切に分類されることを保証できます。これにより、監視と監査が向上します。
- 個別のエクスペリエンス – ウェブサイトのコンテンツなどの文脈では、文書の分類によりユーザーの興味や好みに基づいたカスタマイズされたコンテンツを表示することが可能になります。これによりユーザーのエンゲージメントが向上します。
独自の分類機械学習モデルを開発する複雑さは、データの品質、アルゴリズム、スケーラビリティ、ドメイン知識など、さまざまな要素によって異なります。明確な問題定義、クリーンで関連性のあるデータから始め、モデル開発のさまざまな段階を段階的に進めることが重要です。ただし、ビジネスはAmazon Comprehendのカスタム分類を使用して独自の機械学習モデルを作成し、テキスト文書を自動的にカテゴリやタグに分類することで、ビジネス固有の要件に適合し、ビジネス技術と文書のカテゴリにマッピングすることができます。人間のタグ付けや分類が不要になるため、これにより企業は多くの時間、お金、労力を節約することができます。私たちは、トレーニングパイプライン全体を自動化することで、このプロセスを簡素化しました。
- AWS SageMaker JumpStart Foundation Modelsを使用して、ツールを使用するLLMエージェントを構築し、展開する方法を学びましょう
- 「AIはオーディオブック制作をどのように革新しているのか? ニューラルテキストtoスピーチ技術により、電子書籍から数千冊の高品質なオーディオブックを作成する」
- Amazon SageMakerで@remoteデコレータを使用してFalcon 7Bやその他のLLMを微調整する
このマルチシリーズのブログ投稿の最初の部分では、スケーラブルなトレーニングパイプラインを作成し、Comprehendカスタム分類モデルのトレーニングデータを準備する方法を学びます。BBCニュースのデータセットを使用し、文書が属するクラス(例:政治、スポーツ)を識別する分類器のトレーニングを行います。このパイプラインにより、組織はスクラッチから始めることなく迅速に変更に対応し、新しいモデルをトレーニングすることが可能になります。需要に基づいて簡単にスケールアップし、複数のモデルをトレーニングすることもできます。
前提条件
- アクティブなAWSアカウント(新しいAWSアカウントを作成するにはここをクリックしてください)
- Amazon Comprehend、Amazon S3、Amazon Lambda、Amazon Step Function、Amazon SNS、およびAmazon CloudFormationへのアクセス
- トレーニングデータ(半構造化またはテキスト)が準備されていること
- Pythonと機械学習に関する基本的な知識
トレーニングデータの準備
このソリューションは、テキスト形式(CSVなど)または半構造化形式(PDFなど)の入力を受け付けることができます。
テキスト入力
Amazon Comprehendのカスタム分類は、マルチクラスとマルチラベルの2つのモードをサポートしています。
マルチクラスモードでは、各文書に1つのクラスが割り当てられます。トレーニングデータは、各行に単一のクラスとそのクラスを示すドキュメントのテキストが含まれる2列のCSVファイルとして準備する必要があります。
CLASS、ドキュメント1のテキスト
CLASS、ドキュメント2のテキスト
...BBCニュースデータセットの例:
ビジネス、ヨーロッパは弱いドルのせいで米国を非難...
テク、タクシーがたくさんの携帯電話を集める...
...マルチラベルモードでは、各ドキュメントには少なくとも1つのクラスが割り当てられますが、複数のクラスを持つこともあります。トレーニングデータは、各行に1つ以上のクラスとトレーニングドキュメントのテキストを含む2列のCSVファイルとして提供する必要があります。複数のクラスを指定するには、各クラスの間に区切り記号を使用します。
CLASS、ドキュメント1のテキスト
CLASS|CLASS|CLASS、ドキュメント2のテキスト
...トレーニングモードのCSVファイルには、ヘッダーは含めません。
半構造化入力
2023年から、Amazon Comprehendでは半構造化ドキュメントを使用したモデルのトレーニングがサポートされるようになりました。半構造化入力のトレーニングデータは、ラベル付きドキュメントのセットで構成されます。これは、すでにアクセス権があるドキュメントリポジトリから事前に識別されたドキュメントです。以下は、トレーニングに必要な注釈ファイルのCSVデータの例です(サンプルデータ):
CLASS、document1.pdf、1
CLASS、document1.pdf、2
...注釈のCSVファイルには、3つの列が含まれています。最初の列にはドキュメントのラベルが含まれ、2番目の列にはドキュメント名(つまり、ファイル名)が、最後の列にはトレーニングデータセットに含めるドキュメントのページ番号が含まれています。ほとんどの場合、注釈のCSVファイルが他のすべてのドキュメントと同じフォルダにある場合は、2番目の列にドキュメント名を指定するだけで十分です。ただし、CSVファイルが別の場所にある場合は、2番目の列に場所へのパスを指定する必要があります。たとえば、path/to/prefix/document1.pdfのようにします。
トレーニングデータの準備方法の詳細は、こちらを参照してください。
ソリューションの概要

- Amazon Comprehendのトレーニングパイプラインは、トレーニングデータ(テキスト入力用の.csvファイルおよび半構造化入力用の注釈.csvファイル)が専用のAmazon Simple Storage Service(Amazon S3)バケットにアップロードされると開始されます。
- Amazon S3トリガーによってAWS Lambda関数が呼び出されます。指定されたAmazon S3の場所にオブジェクトがアップロードされるたびに、AWS Lambda関数はアップロードされたオブジェクトのソースバケット名とキー名を取得し、トレーニングステップ関数ワークフローに渡します。
- トレーニングステップ関数では、トレーニングデータのバケット名とオブジェクトキー名を入力パラメータとして受け取った後、以下のように一連のラムダ関数を使用してカスタムモデルのトレーニングワークフローが開始されます:
StartComprehendTraining:このAWS Lambda関数は、入力ファイルのタイプ(テキストまたは半構造化)に応じてComprehendClassifierオブジェクトを定義し、create_document_classifier APIを呼び出してAmazon Comprehendのカスタム分類トレーニングタスクを開始します。このAPIはトレーニングジョブのAmazonリソースネーム(ARN)を返します。次に、この関数はdescribe_document_classifier APIを呼び出してトレーニングジョブのステータスを確認します。最後に、トレーニングジョブのARNとステータスを次のトレーニングワークフローの出力として返します。GetTrainingJobStatus:このAWS Lambdaは、describe_document_classifier APIを呼び出して15分ごとにトレーニングジョブのステータスをチェックし、トレーニングジョブのステータスがCompleteまたはFailedに変わるまで繰り返します。GenerateMultiClassまたはGenerateMultiLabel:スタックの起動時にパフォーマンスレポートに「はい」を選択した場合、これらの2つのAWS LambdaのいずれかがAmazon Comprehendモデルの出力に基づいて分析を実行し、クラスごとのパフォーマンス分析を生成し、Amazon S3に保存します。GenerateMultiClass:入力がMultiClassでパフォーマンスレポートに「はい」を選択した場合、このAWS Lambdaが呼び出されます。GenerateMultiLabel:入力がMultiLabelでパフォーマンスレポートに「はい」を選択した場合、このAWS Lambdaが呼び出されます。
- トレーニングが正常に完了したら、ソリューションは次の出力を生成します:
- カスタム分類モデル:トレーニングされたモデルのARNは、将来の推論作業で利用できます。
- 混同行列[オプション]:混同行列(
confusion_matrix.json)は、ユーザーが定義した出力Amazon S3パスに保存されます。これは、ユーザーが選択したものによります。 - Amazon Simple Notification Service通知[オプション]:初期のユーザー選択に応じて、トレーニングジョブのステータスに関する通知メールが購読者に送信されます。
ウォークスルー
ソリューションの起動
パイプラインを展開するには、以下の手順を完了してください:
- スタックを起動ボタンを選択します:

- 次を選択します
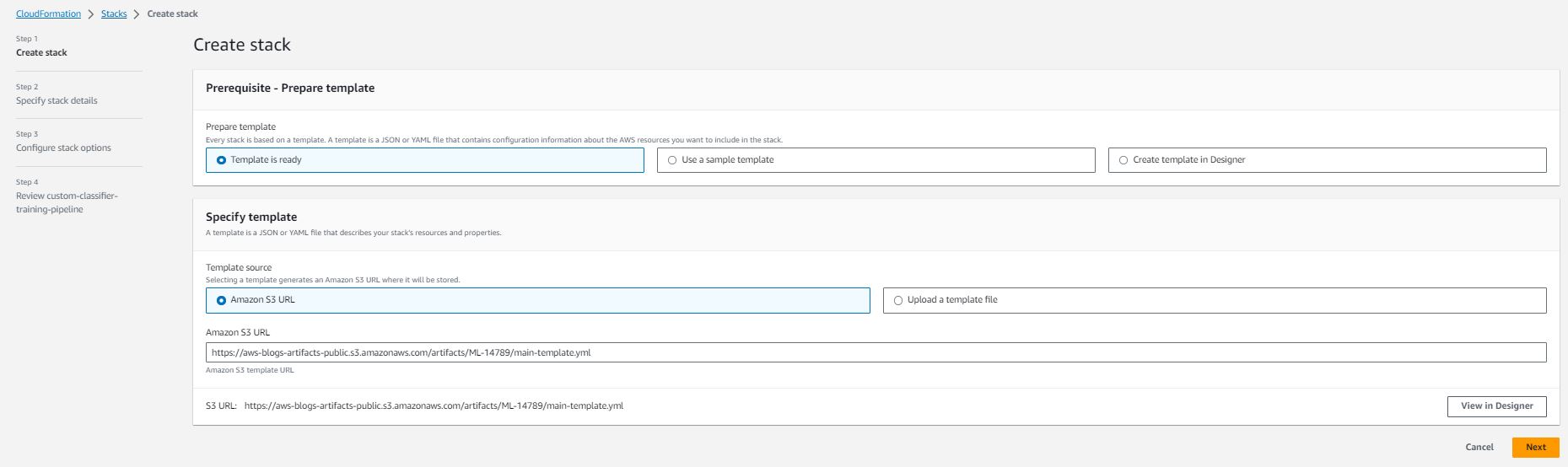
- 使用ケースに合わせてオプションを指定してパイプラインの詳細を指定します:
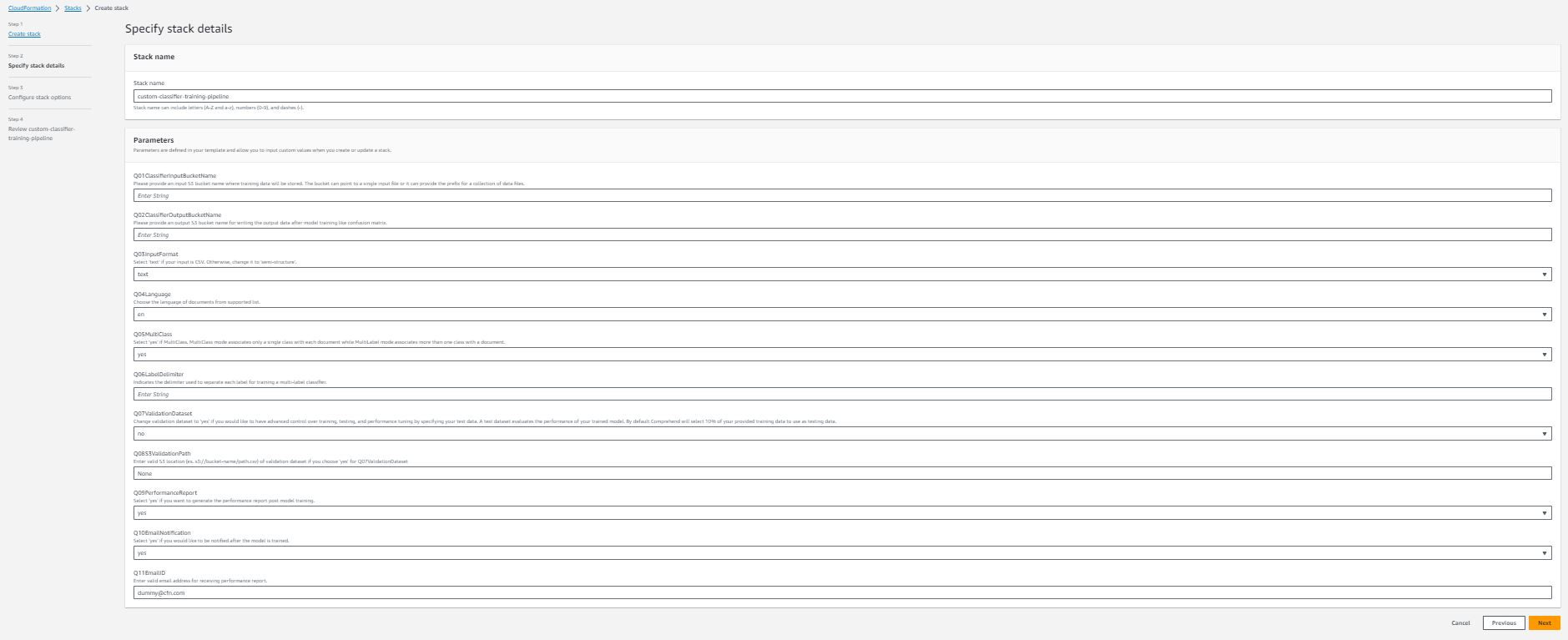
各スタックの詳細情報:
- スタック名(必須) – AWS CloudFormation スタックに指定した名前です。名前は作成するリージョン内で一意である必要があります。
- Q01ClassifierInputBucketName(必須) – 入力データを保存するための Amazon S3 バケット名です。グローバルに一意の名前である必要があり、AWS CloudFormation スタックは起動中にバケットを作成するのに役立ちます。
- Q02ClassifierOutputBucketName(必須) – Amazon Comprehend およびパイプラインからの出力を保存するための Amazon S3 バケット名です。これもグローバルに一意の名前である必要があります。
- Q03InputFormat – ドロップダウン選択肢です。データの入力形式に基づいて、テキスト(トレーニングデータが csv ファイルの場合)または セミストラクチャ(トレーニングデータがセミストラクチャ [PDF ファイルなど] の場合)を選択できます。
- Q04Language – ドロップダウン選択肢です。サポートされている言語リストからドキュメントの言語を選択します。ただし、現在はセミストラクチャの入力形式の場合に限り、英語のみがサポートされています。
- Q05MultiClass – ドロップダウン選択肢です。入力が MultiClass モードの場合は はい を選択します。それ以外の場合は いいえ を選択します。
- Q06LabelDelimiter – Q05MultiClass の回答が いいえ の場合にのみ必要です。このデリミタは、トレーニングデータ内の各クラスを区切るために使用されます。
- Q07ValidationDataset – ドロップダウン選択肢です。トレーニング済みの分類器のパフォーマンスを独自のテストデータでテストする場合は回答を はい に変更します。
- Q08S3ValidationPath – Q07ValidationDataset の回答が はい の場合にのみ必要です。
- Q09PerformanceReport – ドロップダウン選択肢です。モデルのトレーニング後にクラスレベルのパフォーマンスレポートを生成する場合は はい を選択します。レポートは Q02ClassifierOutputBucketName で指定した出力バケットに保存されます。
- Q10EmailNotification – ドロップダウン選択肢です。モデルのトレーニング後に通知を受け取りたい場合は はい を選択します。
- Q11EmailID – パフォーマンスレポートの通知を受け取るための有効なメールアドレスを入力してください。なお、AWS CloudFormation スタックが起動された後、トレーニングが完了した際に通知を受け取るために、メールからの購読を確認する必要があります。
- 「Amazon スタックオプションを構成」セクションで、オプションのタグ、アクセス許可、およびその他の高度な設定を追加します。
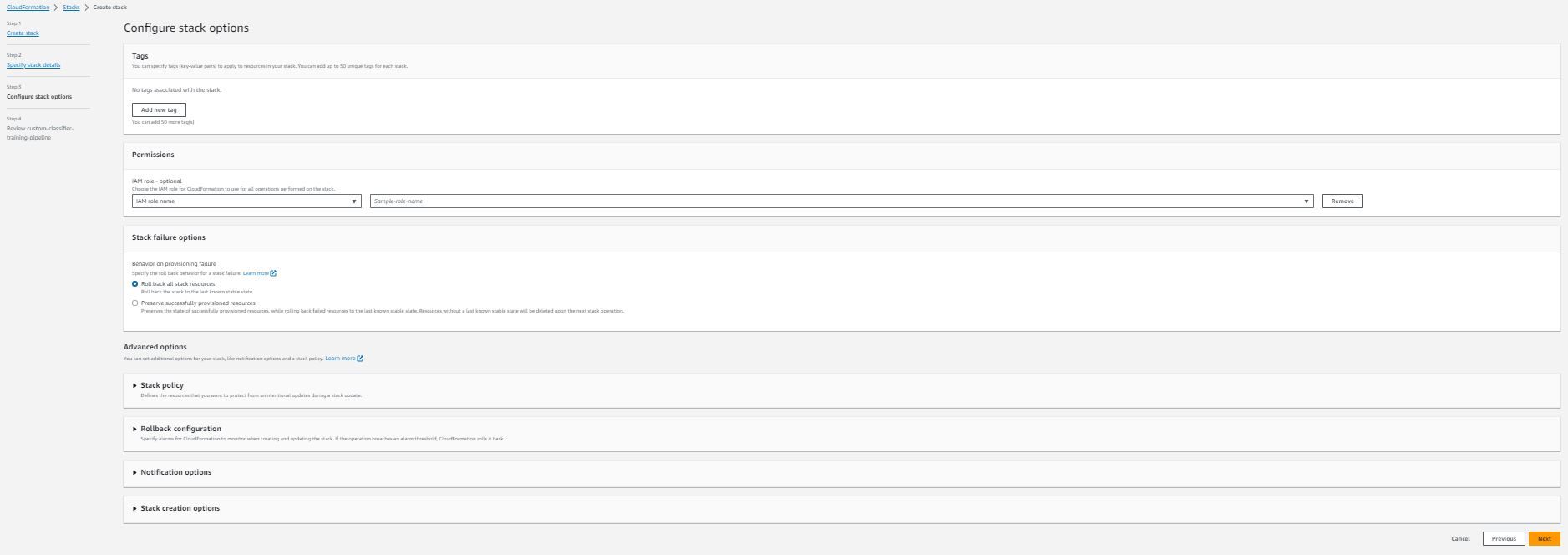
- 次へ を選択します
- スタックの詳細を確認し、AWS CloudFormation が AWS IAM リソースを作成する可能性があることを確認します。
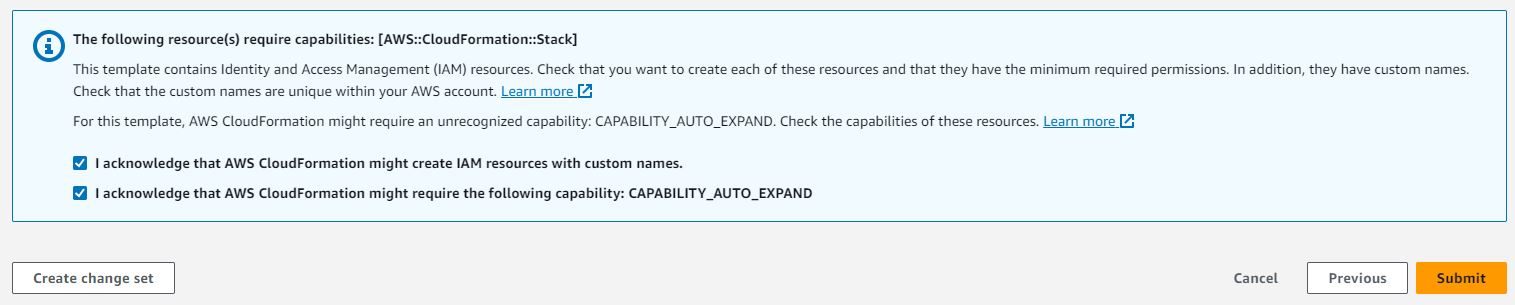
- 提出を選択します。これにより、AWSアカウントでパイプラインの展開が開始されます。
- スタックが正常に展開された後、パイプラインを使用できるようになります。入力のために指定したAmazon S3ロケーションの下に
/training-dataフォルダを作成します。注意:Amazon S3は、異なる暗号化オプションを指定しない限り、新しいオブジェクトごとにサーバーサイド暗号化(SSE-S3)を自動的に適用します。Amazon S3でのデータ保護と暗号化の詳細については、Amazon S3のデータ保護を参照してください。

- フォルダにトレーニングデータをアップロードします(トレーニングデータが半構造の場合は、.csv形式のラベル情報をアップロードする前にすべてのPDFファイルをアップロードします)。
完了です!パイプラインを正常に展開しました。展開されたステップ関数でパイプラインのステータスを確認できます(Amazon Comprehendカスタム分類パネルにトレーニング済みのモデルがあります)。

Amazon Comprehendコンソール内のモデルとそのバージョンを選択すると、トレーニングしたばかりのモデルの詳細を表示できます。選択したモード(オプションQ05MultiClassに対応)、ラベルの数、トレーニングデータ内のトレーニングおよびテストドキュメントの数が含まれています。以下で全体のパフォーマンスも確認できますが、各クラスの詳細なパフォーマンスを確認したい場合は、展開されたパイプラインによって生成されたパフォーマンスレポートを参照してください。
サービスクォータ
Amazon ComprehendとAmazonTextractには、半構造形式の入力の場合、AWSアカウントにデフォルトのクォータがあります。サービスクォータを表示するには、Amazon ComprehendのこちらとAmazonTextractのこちらを参照してください。
クリーンアップ
継続的な料金が発生しないようにするため、このソリューションの一部として作成したリソースを削除してください。
- Amazon S3コンソールで、入力および出力データのために作成したバケット内のコンテンツを手動で削除します。
- AWS CloudFormationコンソールで、ナビゲーションペインでスタックを選択します。
- メインスタックを選択し、削除を選択します。
これにより、展開されたスタックが自動的に削除されます。
- トレーニング済みのAmazon Comprehendカスタム分類モデルはアカウントに残ります。不要な場合は、Amazon Comprehendコンソールで作成したモデルを削除してください。
結論
この記事では、Amazon Comprehendカスタム分類モデルのスケーラブルなトレーニングパイプラインの概念と、新しいモデルの効率的なトレーニングのための自動化ソリューションを紹介しました。提供されるAWS CloudFormationテンプレートにより、需要のスケールに合わせて簡単にテキスト分類モデルを作成することができます。このソリューションは、最近発表されたユークリッド機能を採用し、テキストまたは半構造形式の入力を受け入れます。
さあ、読者の皆さん、これらのツールをテストしてみることをお勧めします。トレーニングデータの準備の詳細やカスタム分類器のメトリクスについてさらに詳しく知ることができます。ぜひ試してみて、モデルのトレーニングプロセスを効率化する方法を直接体験してください。ご意見をお聞かせください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





