「生成AIゴールドラッシュで誰がお金を稼ぐのか?」
「生成AIゴールドラッシュで誰がお金を稼ぐのか?」' Condensed 生成AIゴールドラッシュで誰が稼ぐのか?
ジェネラティブAIのゴールドラッシュはすでに本格的に始まっています。ジェネラティブAI(GenAI)は、人間が作成するのと区別がつかないことが多い言葉、画像、ビデオ、およびオーディオなどのコンテンツを作成しています。文章執筆、ビジュアルデザイン、コーディング、マーケティング、ゲーム制作、音楽作曲、製品設計など、人間の創造性の領域は、GenAIの影響を受けて急速に変化しています。クリエイティブサービスは、Microsoft Office 365、Slack、Discord、Salesforce Cloud、Gmailなどの製品に統合されることで、GenAIは私たちが気づかないうちに数十億人の生産性を向上させるでしょう。私たちはすぐにGenAIを使ってあらゆるものの最初のドラフトを作成するようになるでしょう。
では、GenAIから誰がお金を稼ぐのでしょうか? 私はOpenAIのDall-E-2テキストから画像へのサービスにその質問をしましたが、以下の画像を生成しました。なかなかいい出来です。

2018年、私はAIでお金を稼ぐのは誰かという人気のあるブログ記事を書きました。ここでは、数千もの新しいユースケース全体にわたってGenAIへの投資が行われていることについてフォローアップ記事を書いています。要するに、このゴールドラッシュには以下の5つの「レイヤー」における潜在的な価値の獲得があります。
1. インフラストラクチャ:大規模なGenAIコンピュータモデルを実行するチップやクラウドインフラストラクチャを提供する企業。
2. 基盤モデル:クリエイティブな出力を生成する大規模なテキスト、画像、音声などのモデルを構築する企業。
3. アプリケーション:消費者、企業、政府がクリエイティブなタスクに使用するアプリを開発する大規模および小規模な企業。
4. 産業と組織:クリエイティブな活動の一環として、GenAIアプリケーション、ツール、プラットフォームから価値を抽出する企業や組織。
5. 国家:国内外でGenAI技術を作成、輸出、展開する国。
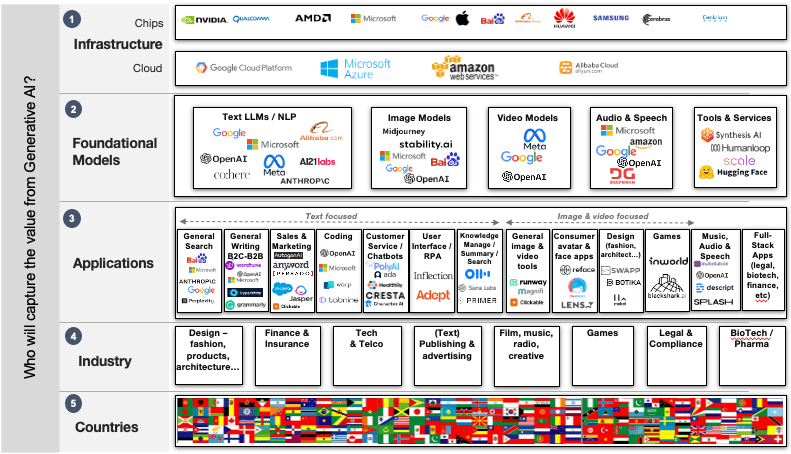
これらのレイヤーの中で、勝者は誰でしょうか?
1. GenAIインフラストラクチャ
ビッグテック企業はすでにクラウドサービスとハードウェアチップでGenAIインフラストラクチャを支配しています。

マイクロソフトとGoogleは米国のクラウド市場で有利な立場にあり、BaiduとAlibabaは中国で有利な立場にあります。彼らの巨大なスーパーコンピュータクラウドインフラストラクチャは、GenAIの複雑で高価な大規模なテキスト、ビジュアル、音声の基盤モデルを実行するために設計されています。すでに多くの開発者が彼らのクラウドAI APIサービスとツールを使用してアプリを開発しており、このトレンドは事実上限りないGenAIのユースケースに対応するために起業家たちが急きょ動くことが予想されています。Amazonは基盤モデルについてはあまり話題になっていませんので、彼らがどのように対応するかは大きな問題です。
GenAIは巨大な計算能力を使用して創造的な出力を生成します。OpenAIのCEOであるSam Altmanは次のように述べています。
「(ChatGPTとDall-E-e)いずれかのタイミングでそれをいくらか利益を上げなければならない。コンピュータのコストは目を見張るものです。」
噂によれば、OpenAIのGPT-3のトレーニングには1,200万ドルのエネルギー料金がかかったとされています。Microsoftから2023年初頭に100億ドルの投資を受けたOpenAIは、そのほとんどをMicrosoft Azureのスーパーコンピューティングインフラストラクチャへのアクセスクレジットの形で受け取ることになっています。
チップメーカーはスーパーコンピュータのパワーの需要にわくわくしています。NVIDIA(NASDAQ:NVDA)の株価は市場価値が5兆ドルを超え、2018年には60ドルから2023年初頭には240ドルに上昇しました。ビッグテック企業も独自のAI最適化チップに投資しています。最近の中国への先進的なAIチップの輸出禁止措置は、中国の国家援助と国内投資を加速させる(および地政学的な緊張を高める)でしょう。必要な投資額を考えると、この領域での勝者は大手企業または大手企業の支援を受けた企業になるでしょう。
2. 基礎モデル
ビッグテックの規模と範囲は、GenAIの基礎モデルの開発において競争力を持っています。これらのモデルは、ビッグテックの広範な計算リソースを利用して、膨大な量のデータでトレーニングされています。たとえば、OpenAIのGPT-3テキストモデル(Large Language Model(LLM))は、英語圏のインターネットから「回収された」数兆語に相当するテキストデータの約45テラバイトでトレーニングされました。同様に、OpenAIのDall-E-2テキストから画像へのモデルは、6.5億の画像キャプションペアでトレーニングされました。
ビッグテックは、将来のこれらの基礎モデルの数十億のエンドユーザーによって生成される巨大な収益を捉えることに失敗することなく、クラウドサービスでのリーダーシップを維持したいと考えています。MicrosoftはOpenAIと提携し、Googleは最近、入力テキストから写真のようなリアルなイメージを作成するBard言語チャットボットを発表しました。
中国のビッグテックも立ち止まることはありません。Alibabaは独自のチャットサービスをテストしています。Baiduはすでにテキストから画像に変換するパラメータモデルERNIE-ViLGを提供しており、新しいチャットボットサービスのテストも行っています。ビッグテックの規模は、スタートアップが複製するのが困難ないくつかの利点を持っています。

ビッグテックは、真実、バイアス、および基礎モデルの有害性の問題に対処するための規模の利点を持っています
ビッグテックは、GenAIの暗い側面に対処できる唯一のプレーヤーかもしれません。GenAIはまだ幼児期ですが、基礎モデルに関する問題が明らかになってきています。これらの問題は真実(GenAIが単純に間違ったコンテンツを生成すること)、バイアス(特定のグループに対する偏見)、および有害性(人種差別的、女性差別的、または憎悪的な発言など)までさまざまです。2023年初頭、GoogleのBardチャットボットサービスが誤った不快な回答をしたため、Alphabetの時価総額には1000億ドルの損失が発生しました。Microsoftの限定リリースBingチャットボットも、保護策を回避するユーザーからの問題のある(さらには人種差別的な)回答を表示しましたが、株価は急落しませんでした。さらに、悪意のある命令を注入することによってガードレールを回避するプロンプトインジェクションという新しいタイプのサイバー攻撃も存在します。
これらの基礎モデルを開発する人々にとっての課題は、彼らの出力が責任を持って正確であることを保証することです。基礎モデルは、単にインターネットの広範な範囲からスクレイピングされたバイアスのある有害なコンテンツを再現することはできません。これらのモデルはまた幻視的です。つまり、事実に反する質問に対しても自信を持ってよく構築された雄弁な回答を提供します。Noam Shazeer、Character.AIの共同創設者は、ニューヨーク・タイムズで次のように述べています。
「…これらのシステムは真実のために設計されていません。それらは、可能性のある会話のために設計されています。」
または、彼らは自信を持って嘘をつく芸術家です。
ビッグテックは、モデルの失敗がもたらす評判、財務、戦略的リスクを負うことはできません。彼らは、ガードレールとモデルの調整を含む監督的な監視システムを構築しています。ユーザーとの信頼を築き、規制要件を満たすために、ビッグテックはモデルの透明性、説明可能性、およびソースの引用のためのソリューションを設計する必要があります。人間のフィードバックによる強化学習(RLFH)では、膨大な数の人々がモデルの質問に対する回答をレビューし評価する必要があります。これらは規模で解決するのが簡単な問題ではありません。再び、ビッグテックは、資本、エンジニアリングの才能、データセット、数十億のユーザーを持つ人間のフィードバックループの規模へのアクセスという点で有利に位置しています。
BigTechのモデルはすべての状況に適しているわけではありません
サイズとスケールにもかかわらず、BigTechは全ての基本モデルのゴールドラッシュを制御することはできません。彼らのモデルは基本的に水平であり、正確であるかどうかに関係なく、あらゆる消費者の質問に適しています。しかし、彼らのモデルは常に企業の垂直なタスクには適しているわけではありません。なぜなら、BigTechの水平モデルは(1)専門的なタスクでのパフォーマンスが常に良いわけではなく、(2)企業の独自データを保護しないことが多いため、(3)非英語の言語で訓練されていないため、(4)透明性や説明可能性が不足していたり、(5)エッジデバイスやオンプレミスでの使用に適していなかったり、(6)クラウドでの運用コストが高いため、(7)企業がBigTechに依存する可能性があるためです。
ごくわずかな非常に資金力のあるスタートアップ企業がBigTechの基本モデルに代わる選択肢を提供しています
BigTechの基本モデルはすべての人に向けたものではありません。これには、何十億ドルもの資金を調達しているごくわずかな非常に資金力のあるスタートアップ企業に余地があります。
- Anthropicは2021年に設立され、より信頼性の高い、説明可能で操縦可能なLLMに焦点を当てており、Googleから最新の3億ドルの投資を含む10億ドル以上を調達しています。
- AI21labsはJurassic-1テキストモデルに1億1900万ドルを調達しています。Jurassic-1は1780億のパラメータを持ち、GPT-3とほぼ同じサイズです。
- CohereはLLMと自然言語処理(NLP)のために1億6500万ドルを調達しています。
- BLOOMは、プライベートセクターのHugging Faceとヨーロッパの研究機関によって支援された、1760億のパラメータを持つオープンソースLLMの研究プロジェクトです。それは46の人間の言語、特に多くのLLMでは十分に扱われていない20のアフリカの言語で訓練されています。
- イギリスのベースのStability AIは、オープンソースの画像生成サービスStable Diffusionのために1億ドル以上を調達し、10億ドル以上の評価額を持っています。
BigTechは自社のモデルの制限について認識しており、特に最近、Microsoftは企業がプロプライエタリデータが共有されることを心配せずにモデルを「微調整」できるようにすると発表しました。
しかし、これらの手続きはすべての人を満足させるものではありません。ドイツのスタートアップ企業Adelph Alphaは3,100万ドルを調達し、BigTechの基本モデルに関する企業の懸念に対処していますが、大規模な競争に参加できるかどうかは不明です。
BigTechは水平の基本モデルのレースに勝利し、数少ない高資本のスタートアップ企業の選択肢に余地を残します。おそらく、BLOOMやStable Diffusionなどのオープンソースのモデルはスケールを拡大するか、少なくともニッチな存在を見つけるでしょう。通常どおり、これらの基本モデルとの作業を容易にするために利益を得るツールやサービスプロバイダも存在するでしょう。しかし、全体的には以下のようになります:
BigTechの市場支配力は、彼らの基本モデルを無料で提供できる能力によって増幅されます。なぜなら、彼らは主に基礎となるクラウドサービスから大部分の収益を得るからです。
3. 生成型AIアプリケーション
BigTechはGenAIゴールドラッシュの採掘道具を獲得しますが、アプリケーション層はより公平な競争の場です。既存の企業ソフトウェア企業、フルスタックのスタートアップ企業、およびこれらの基本モデルによって可能にされる数千のスタートアップ企業が新しいGenAIアプリケーションを提供します。
従来の企業ソフトウェア企業、SalesforceやMicrosoftなどは、自社の数十億のユーザーにGenAIの機能を有機的に統合するか、買収を通じてもたらします。Microsoftはまた、GenAIチャットボットサービスをBing検索アプリケーションに統合し、直接的にGoogleの検索の覇権に挑戦しています。
一部の資金豊かなスタートアップ企業が、専門的な「フルスタック」アプリケーションを提供します。特化されたデータ、シーケンス、および計算要件を持つドメインでは、これらの企業は独自の基盤モデルを開発します。たとえば、GenAIは自社のモデルを応用して、薬物探索や材料科学を革新する可能性があります。これらのスタートアップは、大きな経済的報酬や強力な競争力を提供できるため、投資家の関心を引きます。
Adept AIは、例えば$65Mを調達して、LLMsに基づいた自然言語インターフェースを持つ次世代のロボティックプロセスオートメーション(RPA)の開発に取り組んでいます。非公開モードで、Inflection.aiも同様の取り組みを行っています。Character.AIは、キャラクターの声と知識を採用したチャットボットで、$200M〜$250Mの資金調達を行い、専門的なLLMsのフルスタック実装をサポートしています。
GenAIの採用は非常に速いでしょう。たとえば、AIによるマーケティングプレゼンテーションの初稿が完璧でない場合、編集することは簡単です。ChatGPTは、ローンチ後わずか2か月余りで月間アクティブユーザー数1億人以上を獲得した、歴史上最も急成長した消費者向けアプリケーションです。これは、GenAIの創造的なアプリケーションの数がほぼ無限であるため、競争が激しく、速いことを意味します。

あらゆる想定されるユースケースに対応する「Copilot」GenAIアプリが存在するでしょう
GenAIの活用により、世界中の消費者、ビジネス、組織が、これらの基盤モデルを利用したスタートアップによって作成されたアプリケーションを利用することができます。多くのGenAIスタートアップは、「Copilot for X」というビジネスモデルを採用しており、ユーザーを「クリエイティブ」なタスク(例:文章作成やコーディング)だけでなく、データ入力やフォーム入力などの繰り返しタスクにも支援します。以下に、さまざまな垂直ユースケースで収益を上げようとするいくつかのスタートアップを示します。
- 一般的なテキストの執筆スタートアップは、メールの作成、文書作成、テキストフォームの入力などの日常的な執筆作業をリアルタイムでユーザーを支援しています。AI21labsのWordtuneは、「プロのコピーライターのようにテキストを書き直します。」文書作成の王者であるGrammarlyは、$400 million以上の資金調達をしています。執筆スタートアップのリストには、Lex、HyperWrite、Compose AI、Rytrなどが含まれます。
- 販売とマーケティングスタートアップには、巨大な資金調達を行ったJasper.ai($145M)やAnyword($45 million以上)などがあります。Persadoは$66 million以上を調達し、言語生成により「最高のコピーを96%の確率で上回ります。」スタートアップは、書き込み製品マーケティングの説明など、特定のタスクに特化する傾向が増しています。
- 画像生成スタートアップは、Open AIのDALL-E-2、Stability AIのStable Diffusion、Midjourneyのテキストから画像への基盤モデルを利用しています。Art Breederは、ユーザーがコラージュを作成するのを支援します。
- 顔認識とアバターの消費者向けスタートアップには、Instagramの「完璧な」イメージを作成するのを支援するLightricksのFacetuneアプリがあります。Lightricksは$350 million以上の資金調達をしています。個別の「マジックアバター」は、非常に人気のあるLensa AIアプリのユーザーによって作成されることができます。Refaceは、ユーザーが異なる設定に自分の顔を交換することができる$5.5 millionの資金調達をしています。
- 製品デザインスタートアップには、モデルが高品質な衣服を身に着けた状態で様々なシチュエーションで撮影された超リアルな画像でファッション撮影を再発明するBotikaがあります。Maketは、テキストプロンプトから建築プランを「数
では、どのスタートアップが勝利するのでしょうか?
GenAIアプリケーションのスタートアップには資金が流入しています。 フルスタックのスタートアップは、薬剤探索などの垂直領域で大量の資金を調達し、高度に専門化されたモデルとアプリケーションを作成します。 より広範なB2Bスペースでは、競争は水平および垂直になります。中心には共同運転ビジネスモデルがあります。 一方、水平のスタートアップは、Jasperの営業およびマーケティングアシスタントなど、業界全体でサービスを提供します。 一方、スタートアップは、業界、機能、およびタスクによって垂直に焦点を当てています。
勝者は、以下の要素を実装することで規模と守備力を実現します:
- 強力なROI – ユースケースおよび価値の証明までの時間が短いこと。
- 独自およびカスタマイズされた基礎モデル – ローカライズ、専門化、および独自の企業データを使用して特定のターゲットに合わせて「微調整」されたモデル。
- ワークフロー – 顧客プロセスへの利用性と深い統合の証明。インストールした後に削除するのが困難になります。
- フィードバックループ – たとえば、人間のフィードバックからの強化学習(RLFH)によるモデルのユーザー意図との整合性の向上。
- フライホイールダイナミクス – RLFHおよびその他のフィードバックが増えれば増えるほど、「微調整」によるモデルのパフォーマンスが向上し、使用量が増加し、勢いが増します。
- 投資の規模とスピード – ファウンデーションモデルに多くの知的財産が存在するため、利益率が低くなります。ゲームはすべて規模に関わります。フライホイールを速く回転させるために、ブランドを迅速に構築し、多数のユーザーと顧客を引き付けることができる企業がカテゴリリーダーとして繁栄します。
B2C GenAIコンシューマースペースでは、スピードと大量の顧客獲得予算を持つ水平プレーヤーが競争に勝利する可能性が高いです。
イギリスに拠点を置くAutogenAIは、入札管理共同運転士のカテゴリで勝利するために十分なポジションに立っているB2Bのスタートアップ企業の例です。彼らは過去2年間にわたり、企業のウェブサイトのコンテンツ、営業入札の勝敗、マーケティングコピー、および年次報告書の例を使用してOpenAI LLMを「微調整」しました。彼らはまた、生成されたコンテンツと事実のソースと正確さを確認するための人間-機械の監督ユーザーインターフェースを提供しています。これにより、使用回数が増えることで重要な人間の強化学習のループも提供されます。顧客は、次世代の知識管理および検索ツールとして彼らのアプリケーションを使用する傾向があり、それにより固定化されます。
一部のGenAIスタートアップは、大企業およびコンシューマーアプリケーションの機能として買収されます。たとえば、数百万人のユーザーを持つ大規模なソーシャルメディア企業は、最新の顔とアバター作成のスタートアップを買収します。既存のグラフィックデザインソフトウェア企業は、最も有望な画像およびビデオ編集のスタートアップを買収するでしょう。たとえば、マイクロソフトはGenAI「Microsoft Dynamics 365 Copilot」をCRMおよびERPアプリケーションの一部として提供しています。
つまり、一部の幸運で勇敢なスタートアップは、共同運転のユースケースに対して迅速に規模とフライホイールを構築することができれば、大成功を収めるでしょう。同様に、薬剤探索などの特化したユースケースでは、一部のフルスタックのスタートアップが繁栄するでしょう。大規模な資金調達ラウンド、均一な市場、および人々、企業、政府による革新の迅速な採用により、米国のスタートアップが主導権を握ります。しかし、ほとんどのスタートアップは、このゴールドラッシュのツールプロバイダーの利益に貢献しながら手ぶらで帰宅するでしょう – 主にアメリカのBigTech企業です。
これはGenerative AIからお金を稼ぐための一連の投稿の最初です。次の投稿では、GenAIから最も恩恵を受ける組織、およびこの技術から最も恩恵を受ける国と市民についても議論します。
皆様のフィードバックをお待ちしております。
Simon Greenmanは、人工知能と技術革新のパイオニアです。 MapQuestの共同創設者として、最初のインターネットとAIブランドの一つを立ち上げるのに貢献しました。 現在はBest Practice AIのパートナーとして、AI戦略、技術、およびガバナンスに関するアドバイスを提供しています。彼は最近、世界経済フォーラムのグローバルAI評議会に参画し、彼らの取締役会およびCスイートAIツールキットに貢献しました。 Simonは、ディレクトリ会社のデジタル変革を10年以上リードする最高デジタル責任者として活動し、トレードパーソン向けのトップ市場を提供するHomeAdvisor EuropeのCEOでもありました。彼はBowers& Wilkins、AOL、Accentureなどの有名企業と協力しています。彼は英国のスタートアップエコシステムで活動し、ハーバードビジネススクールでMBAを取得し、サセックス大学でコンピューティングと人工知能の学士号を取得しました。彼は王立地理学協会のフェローです。
オリジナル。許可を得て再掲載しました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






