企業がOpenAIのChatGPTに類似した自社の大規模言語モデルを構築する方法
「企業が自社の大規模言語モデルを作る方法」
自分自身のChatGPTを構築したいですか? 以下に、それを行う3つの方法をご紹介します
イントロダクション
近年、言語モデルは自然言語処理、コンテンツ生成、バーチャルアシスタントなどのさまざまな分野を革新し、大きな注目を集めています。もっとも顕著な例の1つがOpenAIのChatGPTです。これは、人間のようなテキストを生成し、対話的な会話を行うことができる大規模な言語モデルです。これにより、企業の関心が高まり、彼ら自身の大規模言語モデル(LLM)の構築のアイデアを探求することにつながりました。
ただし、LLMの構築には注意深く検討する必要があります。それには計算能力とデータの提供の両方において大きなリソースが必要です。企業は利益とコストを比較し、必要な技術的な専門知識を評価し、長期的な目標との整合性を評価する必要があります。
本記事では、OpenAIのChatGPTに似た自身のLLMを構築する3つの方法を紹介します。本記事の最後まで読むことで、自身の大規模言語モデルを構築する際の課題、要件、潜在的な報酬についてより明確な理解を得ることができるでしょう。それでは、さっそく始めましょう!
企業は自身のLLMを構築すべきでしょうか?
企業が自身のLLMを構築すべきかどうかを理解するために、それらがこのようなモデルを活用する3つの主な方法を探ってみましょう。
- トップ7の列操作でより効果的にPandasデータフレームを使用する
- Taipy:ユーザーフレンドリーな本番用データサイエンティストアプリケーションを構築するためのツール
- 次のLangChainプロジェクトのための基本を学ぶ

1. クローズドソースのLLM: 企業はOpenAIのChatGPTやGoogleのBardなどの既存のLLMサービスを利用することができます。これらのサービスは使いやすいソリューションを提供し、企業が大規模言語モデルの力を利用するために大規模なインフラ投資や技術的な専門知識を必要としません。
メリット:
- 迅速かつ簡単な展開で、時間と労力を節約できます。
- 一般的なテキスト生成タスクにおいて性能が良いです。
デメリット:
- モデルの振る舞いや応答に対する制御が制限されます。
- ドメインや企業固有のデータに対しては正確性が低下します。
- データはサービスをホストするサードパーティに送信されるため、データプライバシーの懸念があります。
- サードパーティのプロバイダに依存し、価格変動の可能性があります。
2. ドメイン固有のLLMの利用: 別のアプローチとして、金融分野のBloombergGPT、バイオメディカルアプリケーション向けのBioMedLM、マーケティングアプリケーション向けのMarketingGPT、eコマースアプリケーション向けのCommerceGPTなど、ドメイン固有の言語モデルを使用する方法があります。これらのモデルはドメイン固有のデータで訓練されており、それぞれの分野でより正確でターゲットに合った応答を可能にします。
メリット:
- 関連するデータで訓練されているため、特定のドメインにおいて精度が向上します。
- 特定の業界に合わせた事前訓練モデルが利用可能です。
デメリット:
- 指定されたドメインを超えてモデルを適応させる柔軟性が制限されます。
- プロバイダのアップデートやドメイン固有のモデルの利用可能性に依存します。
- わずかに向上した精度ですが、企業データに特化していないために制限があります。
- データはサービスをホストするサードパーティに送信されるため、データプライバシーの懸念があります。
3. カスタムLLMの構築とホスティング: 企業が最も包括的なオプションとして、独自のデータを使用してカスタムLLMを構築してホスティングする方法があります。このアプローチは生成されたコンテンツについての最高レベルのカスタマイズとプライバシーコントロールを提供します。組織はモデルを独自の要件に合わせて微調整することで、ドメイン固有の精度とブランドの声に合わせることができます。
メリット:
- 完全なカスタマイズと制御:カスタムモデルにより、ビジネスはブランドの声や業界固有の用語、独自の要件に正確に一致する応答を生成することができます。
- コスト効果的:適切にセットアップすれば(微調整のコストは数百ドルのオーダー)、コスト効果的です。
- 透明性:データとモデル全体が企業に知られています。
- 最高の精度:企業固有のデータと要件に基づいてモデルを訓練することで、企業固有のクエリに対してより正確で文脈に即した出力が得られます。
- プライバシーに配慮:データとモデルは企業の環境に留まります。カスタムモデルを使用することで、企業は機密データの制御を保持し、データプライバシーやセキュリティ侵害に関連する懸念を最小限に抑えることができます。
- 競争上の優位性:カスタム大規模言語モデルは、パーソナライズされた正確な言語処理が重要な役割を果たす産業において、重要な差別化要素となることがあります。
デメリット:
- カスタムの大規模言語モデルを構築するには、相当な機械学習と自然言語処理の専門知識が必要です
カスタムの大規模言語モデルを構築するアプローチは、企業の予算、時間制約、必要な精度、および望まれる制御レベルなどのさまざまな要素に依存します。しかし、上記のように、企業固有のデータを使用してカスタムの大規模言語モデルを構築することには多くの利点があります。
カスタムの大規模言語モデルは、特定のドメイン、ユースケース、および企業の要件に対して、前例のないカスタマイズ、制御、および精度を提供します。したがって、企業は自身の固有のカスタムの大規模言語モデルを構築し、ニーズ、業界、および顧客基盤に特化した可能性を開放すべきです。
独自のカスタムの大規模言語モデルを構築するための3つの方法
以下の画像に示すように、独自のカスタムの大規模言語モデルを構築するには、3つの方法があります。これらは、低い複雑さから高い複雑さまでの範囲に及びます。
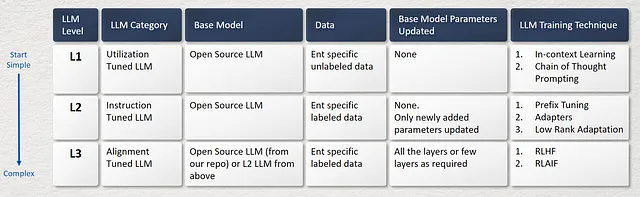
L1. ユーティリゼーション調整型LLM
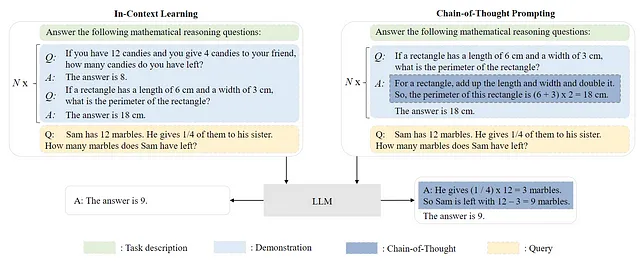
事前学習済みのLLMを活用する一つの一般的な方法は、多様なタスクに対応するための効果的なプロンプト技術を考案することです。一般的なプロンプト手法の例としては、In-Context Learning (ICL) があります。これは、タスクの説明やデモンストレーションを自然言語テキストで表現することを意味します。さらに、Chain-of-Thought (CoT) の活用により、プロンプト内に中間推論ステップのシーケンスを組み込むことで、In-Context Learningを補完することができます。L1 LLMを構築するには、
L1 LLMを構築するには、
- まず、適切な事前学習済みLLMを選択します(Hugging Faceモデルライブラリや他のオンラインリソースで見つけることができます)。ライセンスを確認することで商用利用に適しているかを確認します。
- 次に、特定のドメインまたはユースケースに関連するデータソースを特定し、さまざまなトピックと言語バリエーションを網羅した多様なデータセットを編成します。L1 LLMでは、ラベル付きデータは必要ありません。
- カスタマイズのプロセスでは、選択した事前学習済みLLMのモデルパラメータは変更されません。代わりに、プロンプトエンジニアリング手法が使用され、LLMの応答をデータセットに合わせて調整します。
- 上記で説明したように、In-Context LearningとChain-of-Thought Promptingは、2つの人気のあるプロンプトエンジニアリング手法です。これらの手法は、Resource Efficient Tuning(RET)として知られ、重要なインフラリソースを必要とせずに応答を取得するための効率的な手段を提供します。
L2. インストラクション調整型LLM
インストラクション調整は、自然言語の形式で提供される一連のインスタンスを用いて事前学習済みLLMを微調整するアプローチです。これは、教師あり微調整やマルチタスクプロンプトトレーニングに関連しています。インストラクション調整により、LLMは明示的な例を使用せずに新しいタスクのタスク指示に従うことができるため、ゼロショットの能力と同様に、より高い一般化能力を持つことができます。このインストラクション調整型L2 LLMを構築するには、
- まず、適切な事前学習済みLLMを選択します(Hugging Faceモデルライブラリや他のオンラインリソースで見つけることができます)。ライセンスを確認することで商用利用に適しているかを確認します。
- 次に、ターゲットのドメインまたはユースケースに関連するデータソースを特定します。特定のドメインまたはユースケースに固有の様々なインストラクションを含むラベル付きデータセットが必要です。たとえば、Databricksが提供するdolly-15kデータセットを参照することができます。これは、クローズドQA、オープンQA、分類、情報検索など、さまざまな形式のインストラクションを提供しています。このデータセットは、独自のインストラクションデータセットを構築するためのテンプレートとして使用できます。
- 教師あり微調整プロセスに移ります。ステップ1で選択した基本となるLLMに新しいモデルパラメータを追加します。これらのパラメータを追加することで、指示に従ってモデルを特定のエポック数だけ微調整することができます。このアプローチの利点は、基本となるLLMの数十億のパラメータを更新する必要がなく、代わりに追加のパラメータ(数千または数百万)に焦点を当てることで、望ましいタスクで正確な結果を得ることができる点です。このアプローチはコストも削減できます。
- 次のステップは微調整です。プレフィックス微調整、アダプター、低ランクアテンションなど、これらに関するさまざまな微調整技術については、将来の記事で詳しく説明します。ステップ3で説明した新しいモデルパラメータを追加するプロセスは、これらの技術にも依存します。詳細な情報については、参考文献を参照してください。これらの技術は、基本となるLLMのすべてのパラメータを更新することなく、カスタマイズを可能にするため、パラメータ効率的微調整(PEFT)のカテゴリに属します。
L3. アラインメントチューニングLLM
LLM(言語モデル)は、事前学習コーパスのデータ特性(高品質データと低品質データの両方を含む)を捉えるように訓練されているため、有害な、偏った、または有害なコンテンツを人間のために生成する可能性があります。したがって、LLMを人間の価値観に合わせる必要があるかもしれません。例えば、助けになる、正直な、無害なコンテンツなどです。このアラインメントの目的のために、強化学習と人間のフィードバック(RLHF)の技術を使用します。これは、LLMが期待される指示に従うことを可能にする効果的な調整手法であり、緻密に設計されたラベリング戦略とともに人間をトレーニングループに組み込みます。このアラインメントチューニングLL3 LLMを構築するためには、
- まず、オープンソースの事前学習済みLLM(Hugging Faceモデルライブラリや他のオンラインリソースで見つかることがあります)またはL2 LLMをベースモデルとして選択します。
- アラインメントチューニングLLMを構築するための主な技術はRLHFであり、教師あり学習と強化学習を組み合わせています。まず、特定のドメインまたはインストラクションコーパスに対してファインチューンされたLLM(ステップ1から)を取り、それを使用して応答を生成します。次に、その応答を人間が注釈を付けて教師付き報酬モデルをトレーニングします(通常、別の事前学習済みLLMがベースモデルとして使用されます)。最後に、LLM(ステップ1から)は報酬モデルとの強化学習(PPO)を行うことにより再びファインチューンされ、最終的な応答を生成します。
- したがって、報酬モデルのためのLLMと最終的な応答の生成のためのLLMの2つがトレーニングされます。両方の場合におけるベースモデルのパラメータは、応答の所望の精度に応じて選択的に更新することができます。たとえば、一部のRLHFの手法では、強化学習に関与する特定の層やコンポーネントのパラメータのみを更新して、過学習を回避し、事前学習済みLLMが捉えた一般的な知識を保持します。
このプロセスの興味深い側面は、成功したRLHFシステムは、テキスト生成と比較してさまざまなサイズの報酬言語モデルを使用していることです(例:OpenAIの175B LM、6B報酬モデル、Anthropicは10Bから52BまでのLMと報酬モデル、DeepMindはLMと報酬に70BのChinchillaモデルを使用)。直感的には、これらの優先モデルは、与えられたテキストを理解するためにモデルが必要とする能力と同じ容量を持つ必要があると考えられます。
RLHFの代わりに、RLAIF(AIフィードバック付き強化学習)も使用することができます。ここでの主な違いは、人間のフィードバックの代わりにAIモデルが評価者または評価者として機能し、強化学習プロセス中にAIエージェントにフィードバックを提供することです。
結論
企業は、カスタムLLMの非凡なポテンシャルを活用して、特定のドメイン、ユースケース、組織の要求に合わせた優れたカスタマイズ、制御、および精度を実現することができます。企業固有のカスタムLLMを構築することで、ビジネスは一連の適応した機会を開放し、独自の要件、業界のダイナミクス、顧客基盤に完璧に合うものを実現することができます。
独自のカスタムLLMを構築するための旅は、モデルの複雑性、精度、コストが低いレベルから高いレベルにわたって3つのレベルを持っています。企業は、このトレードオフを調整して、自社のニーズに最適な選択肢を見つけ、LLMの取り組みからROIを抽出する必要があります。

参考文献
- プロンプトエンジニアリングとは何ですか?
- インコンテキストラーニング(ICL)— Q. Dong, L. Li, D. Dai, C. Zheng, Z. Wu, B. Chang, X. Sun, J. Xu, L. Li, and Z. Sui, “A survey for in-context learning,” CoRR, vol. abs/2301.00234, 2023.
- インコンテキストラーニングはどのように機能しますか?従来の教師あり学習との違いを理解するためのフレームワーク| SAILブログ(stanford.edu)
- Chain of Thought Prompting — J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. H. Chi, Q. Le, and D. Zhou, “Chain of thought prompting elicits reasoning in large language models,” CoRR, vol. abs/2201.11903, 2022.
- 言語モデルはチェーンオブソートを通じて推論を実行します — Google AIブログ(googleblog.com)
- インストラクションチューニング — J. Wei, M. Bosma, V. Y. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V. Le, “Fine-tuned language models are zero-shot learners,” in The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25–29, 2022. OpenReview.net, 2022.
- 大規模言語モデルの調査 — Wayne Xin Zhao, Kun Zhou*, Junyi Li*, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie and Ji-Rong Wen, arXiv:2303.18223v4 [cs.CL], April 12, 2023
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
