「データクリーニングでPandasを使用する前にこれを読むべき理由」
「データクリーニングの前にPandasを読むべき理由」
Pandasを使用したマスターデータのクリーニング、処理、および探索

Pandasを使用したデータ操作のクイックチュートリアルへようこそ!
このチュートリアルでは、データフレーム内のテキスト置換からデータフレームの結合まで、幅広いトピックをカバーします。
コンテンツテーブル・ データフレーム内のテキスト置換・ データ型の変換・ データフレームの列名の変更・ 条件を使用したデータのフィルタリング・ データフレームのソート・ データのグループ化と集計・ データフレームの結合・ 最終的な言葉Pandasライブラリは、Pythonで最も重要なデータ操作とクリーニングのライブラリの一つです。
したがって、データ関連のビジネスに関与する予定がある場合、この記事は役立ちます。
- 「データアクセスはほとんどの企業で大きな課題であり、71%の人々が合成データが役立つと考えています」
- 「データを分析するためにOpenAIのコードインタープリタを使う方法」
- データサイエンスにおけるツールに依存しない方向へ:SQLのCase WhenとPandasのWhere
では、日常的にデータサイエンティストとして使用するかもしれないこれらのメソッドを学んで、データを準備しましょう。
しかし、まず、データセットを読み込みましょう。
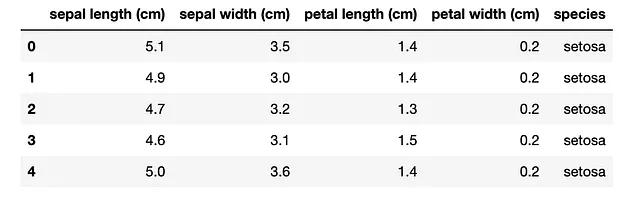
from sklearn.datasets import load_irisimport pandas as pdiris_bunch = load_iris()iris = pd.DataFrame(data=iris_bunch.data, columns=iris_bunch.feature_names)iris['species'] = iris_bunch.targetiris['species'] = iris['species'].map({0: 'setosa', 1: 'versicolor', 2: 'virginica'})iris.head()以下は出力です。
データフレーム内のテキスト置換
しばしば、データフレーム内のデータの内容を置換して、それを望む方向に変更する必要があります。カテゴリデータのクリーニングや標準化などです。
import pandas as pdimport numpy as npiris_replaced = pd.DataFrame(data=iris['data'], columns=iris['feature_names'])iris_replaced['target'] = iris['target']iris_replaced['target'] = np.where(iris_replaced['target'] == 0, 'iris_setosa', iris_replaced['target'])iris_replaced.head()We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「私のデータサイエンスキャリアの2年後に発見した、Jupyter Notebookの5つの裏技」
- 「データサイエンス、機械学習、コンピュータビジョンプロジェクトを強化する 効果的なプロジェクト管理のための必須ツール」
- 「H1 2023 アナリティクス&データサイエンスの支出とトレンドレポート」
- 「2023年の機械学習モデルにおけるトップな合成データツール/スタートアップ」
- 「ChatGPTを活用したデータ探索:データセットの隠れた洞察を解き放つ」
- ジェネレーティブAIツールを使用する際にプライバシーを保護するための6つの手順
- 「ChatGPTが連邦取引委員会によって潜在的な被害の調査を受ける」
