「ステーブル拡散」は実際にどのように機能するのでしょうか?直感的な説明
「ステーブル拡散」の機能はどのようなものですか?直感的な説明
「Stable Diffusion」モデル、一般的にはそう呼ばれているもの、または科学界では「Latent Diffusion Models」として知られているものは、Midjourneyのようなツールが数百万人の注目を集めるなど、世界中で話題になっています。この記事では、これらのモデルに関するいくつかの謎を解き、どのように動作するのかを概念的に理解してもらうことを試みます。いつものように、この記事は詳細な説明には触れませんが、最後にいくつかのリンクを提供します。この記事の主要情報源となる論文は、最初のリンクを含めて提供されます。

動機
画像合成(イメージをゼロから作成する)にはいくつかのアプローチがあります。GANは多様なデータでパフォーマンスが低いです。Autoregressive Transformersはトレーニングと実行が遅く(LLMトランスフォーマーがトークンごとにテキストを生成するのと同様に、パッチごとに画像を生成します)、拡散モデルはこれらの問題の一部を解消するものの、計算コストが非常に高いです。これらを訓練するには依然として何百ものCPU日が必要であり、モデルを利用するにはステップごとに実行して最終的な画像を生成する必要があり、それにもかなりの時間と計算リソースがかかります。
拡散モデルの概要
- 「Amazon SageMaker Pipelinesを使用した機械学習ワークフローの構築のためのベストプラクティスとデザインパターン」
- BYOL(Bootstrap Your Own Latent)— コントラスティブな自己教示学習の代替手段
- 「生成AIにおけるLLMエージェントのデコーディングの機会と課題」
拡散モデルの動作原理を理解するために、まずはトレーニング方法を見てみましょう。トレーニングはやや直感に反する方法で行われます。まず、画像に何度もノイズを適用し、画像の「マルコフ連鎖」を作成します。このような方法で、単一の元の画像から、ノイズが繰り返し適用されたいくつかのT回の画像を得ることができます。
その後、モデルは特定の時間ステップで適用された正確なノイズを予測するように学習し、その出力を使用してその時間ステップでの画像を「除去する」ことができます。これにより、画像Tから画像T-1に移行することができます。繰り返しますが、モデルは、ノイズが時間ステップT-1からTに移行するために適用されたものを、時間ステップTでの画像と一緒に与えられた時に訓練されます!
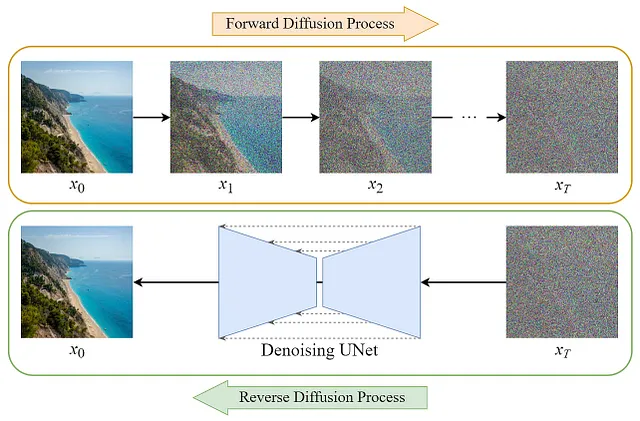
このようなモデルが訓練されたら、ランダムなノイズに繰り返し適用することで、新しい斬新な画像を生成することができます。上記の画像が掲載されている素晴らしいSteins氏の記事は、これについてより詳しく説明しています。
UNetモデル
各時間ステップでノイズを予測するために一般的に使用されるモデルは、「UNet」アーキテクチャモデルです。これは、畳み込み層、プーリング層、スキップ接続を繰り返し適用して、まず画像をダウンスケールし、深さ(特徴マップ)を増やし、次に逆畳み込みを使用して特徴マップを元の画像のサイズにアップサンプリングするタイプのアーキテクチャです。Maurício Cordeiro氏によるこのモデルの詳細については、こちらの素晴らしい記事をご覧ください。
課題
これが従来の拡散モデルの問題が浮かび上がる場所です。まず、トレーニングにかかる時間です。N個の画像があると仮定し、画像にT回ノイズを適用すると、モデルへの入力はN*T通りになります。そして、これらはしばしば高解像度の画像であり、各入力には大きな画像の寸法が含まれるでしょう。だって、Midjourneyがピクセルアートを生成するわけじゃないですから…
そして、モデルをトレーニングした後、ランダムなノイズから画像に戻るために重みをT回繰り返し適用する必要があります!覚えておいてください、私たちのモデルは前の時間ステップの画像しか提供できず、時間ステップTから時間ステップ0に戻る必要があります。
もう1つの課題は、このようなモデルの有用性にあります。気づいたかもしれませんが、入力テキストについてはまだ一度も言及されていません。ただし、私たちはテキストを画像に変換する実装に慣れていますが、ランダムなノイズから画像に変換する実装には慣れていません。では、この機能は具体的にどのようにどこで利用されるのでしょうか?
Latent Diffusion Models
これらの課題を解決するための重要な考え方は、モデルを2つの別々のモデルに分割することです。
最初のモデルは、画像を「潜在空間」にエンコードおよびデコードするためにトレーニングされます。この潜在空間は、画像の「知覚的な」詳細を保持しつつ、データの次元を削減します。直感的に理解するために、私たちは学習する必要のない画像の中のノイズ(色合いがわずかに変化するピクセルを持つ青い空)を考えることができます。
2番目のモデルは、実際のDiffuserであり、この潜在空間表現を画像に変換することができます。ただし、このDiffuserは、テキストなど他のドメインからの入力を「理解」し、それによって指示を受ける特別な修正が施されています。
知覚的画像圧縮
まず、最初のモデルである画像エンコーダー/デコーダーから始めましょう。忘れないでください、アイデアは、重要な情報が保持されている一方で次元が減少するように画像を実際のDiffuser用に準備することです。
この圧縮モデルは実際には「オートエンコーダー」と呼ばれ、再構築された出力と入力の間の差を最小化するようにデータを圧縮された潜在空間にエンコードし、元の形式にデコードするように学習します。このようなモデルの目標は、元の画像とデコードされたバージョンのピクセルの違いではなく、画像の特徴(エッジやテクスチャなど)の違いを最小化することです。画像からこれらを抽出することができる既存のツールがあり、それらを使用することができます。
また、パッチベースの敵対的な目的関数も使用します。これは、パッチごとに画像を分析し、あるパッチが実際のものか偽物かを分類することで、ローカルリアリズムを強制するGAN(異なるタイプのモデルについては以前の記事を参照してください)です。
これにより、ピクセルの違いではなく特徴の違いを最適化しているため、ぼかしを回避するという追加の利点があります。つまり、モデルがピクセルの色付けが若干異なる画像を生成した場合でも、同じ「特徴」を保持している場合はあまり罰せられず、これは望ましい結果です。ただし、ピクセルの色合いが互いに近いが特徴が異なる場合、モデルはかなり罰せられます(したがって、ぼかしの部分)。これにより、デコーダー(およびそれに続く最終のDiffuser)がオリジナルのデータセットに近いピクセル値を持つ画像を「ごまかす」ことなく作成することが防止されます。
テキスト
では、テキストはどこでどのように重要な役割を果たしているのでしょうか?
モデルのトレーニング時に、私たちは画像を拡散させるだけでなく(正確には最初のモデルによって生成されたこれらの画像の潜在空間表現)、テキストを理解し、特定のテキストの一部を使用してこれらの画像を生成することをモデルに学習させます。これは、モデル自体に組み込まれた「クロスアテンション」というメカニズムによるものです。以下にこのメカニズムを示す図があります。
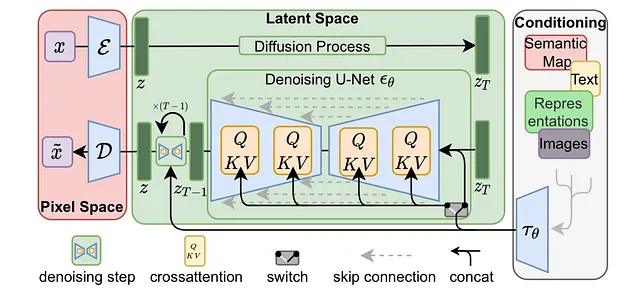
別個のエンコーダーを介して、テキストは「中間表現」に変換されます(テキストのより重要な部分に重みが付けられた表現)。そして、これらの重みはUNetのレイヤーに影響を与え、生成される最終的な画像を制御します。これは、モデルには「クロスアテンション」コンポーネントが組み込まれており、トランスフォーマーと同様に、中間表現の異なる部分が画像の特定の部分に対して少ない影響を与え、他の部分に対して多くの影響を与えることができます。これは、もちろん、標準の順伝播と逆伝播のスキームを通じてトレーニングされます。デノイジングUNetにはテキストといくつかのランダムノイズ(両方がエンコードされたもの)が供給され、その最終出力はオリジナルの画像と比較されます。モデルはテキストを効果的に使用することを学び、同時に効果的にデノイズすることも学びます。順伝播と逆伝播について詳しく知りたい場合は、機械学習の基礎となる重要なトピックなので、これらについて調べることを強くお勧めします。
結論
LDM(Latent Diffusion Models)は、インペインティング、超解像、画像生成など、あらゆる種類のタスクで優れたパフォーマンスを発揮します。この強力なモデルはAIグラフィックスの世界で定番となり、まだ新しいユースケースを発見しています。この記事は概念的な理解を提供するものですが、これに関する詳細はまだまだあります。もっと詳しく知りたい場合は、「High-Resolution Image Synthesis with Latent Diffusion Models」という論文を参照してください。この論文では、私が触れた多くの要素の数学的な解説がされています。
ソース
- https://openaccess.thecvf.com/content/CVPR2022/papers/Rombach_High-Resolution_Image_Synthesis_With_Latent_Diffusion_Models_CVPR_2022_paper.pdf
- https://medium.com/@steinsfu/diffusion-model-clearly-explained-cd331bd41166
- https://medium.com/analytics-vidhya/creating-a-very-simple-u-net-model-with-pytorch-for-semantic-segmentation-of-satellite-images-223aa216e705
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「AIとMLが高い需要になる10の理由」 1. ビッグデータの増加による需要の増加:ビッグデータの処理と分析にはAIとMLが必要です 2. 自動化の需要の増加:AIとMLは、自動化されたプロセスとタスクの実行に不可欠です 3. 予測能力の向上:AIとMLは、予測分析において非常に効果的です 4. パーソナライズされたエクスペリエンスの需要:AIとMLは、ユーザーの行動と嗜好を理解し、パーソナライズされたエクスペリエンスを提供するのに役立ちます 5. 自動運転技術の需要の増加:自動運転技術の発展にはAIとMLが不可欠です 6. セキュリティの需要の増加:AIとMLは、セキュリティ分野で新たな挑戦に対処するために使用されます 7. ヘルスケアの需要の増加:AIとMLは、病気の早期検出や治療計画の最適化など、医療分野で重要な役割を果たします 8. クラウドコンピューティングの需要の増加:AIとMLは、クラウドコンピューティングのパフォーマンスと効率を向上させるのに役立ちます 9. ロボティクスの需要の増加:AIとMLは、ロボットの自律性と学習能力を高めるのに使用されます 10. インターネットオブシングス(IoT)の需要の増加:AIとMLは、IoTデバイスのデータ分析と制御に重要な役割を果たします
- 「ChatGPTを再び視覚させる:このAIアプローチは、リンクコンテキスト学習を探求してマルチモーダル学習を可能にします」
- 「生成AIをめぐる旅」
- 上位10のLLM脆弱性
- 「LLaSMと出会う:音声と言語の指示に従うクロスモーダルな対話能力を持つエンドツーエンドで訓練された大規模なマルチモーダル音声言語モデル」
- 「機械学習のためのソフトウェアエンジニアリングパターン」
- 「生成モデルを活用して半教師あり学習を強化する」






