⚔️AI vs. AI⚔️は、深層強化学習マルチエージェント競技システムを紹介します
'⚔️AI vs. AI⚔️ introduces a deep reinforcement learning multi-agent competition system.'
私たちは新しいツールを紹介するのを楽しみにしています: ⚔️ AI vs. AI ⚔️、深層強化学習マルチエージェント競技システム。
このツールはSpacesでホストされており、マルチエージェント競技を作成することができます。以下の3つの要素で構成されています:
- マッチメイキングアルゴリズムを使用してモデルの戦いをバックグラウンドタスクで実行するスペース。
- 結果を含むデータセット。
- マッチ履歴の結果を取得し、モデルのELOを表示するリーダーボード。
ユーザーが訓練済みモデルをHubにアップロードすると、他のモデルと評価およびランキング付けされます。これにより、マルチエージェント環境で他のエージェントとの評価が可能です。
マルチエージェント競技をホストする有用なツールであるだけでなく、このツールはマルチエージェント環境での堅牢な評価技術でもあると考えています。多くのポリシーと対戦することで、エージェントは幅広い振る舞いに対して評価されます。これにより、ポリシーの品質を良く把握することができます。
最初の競技ホストであるSoccerTwos Challengeでどのように機能するか見てみましょう。
AI vs. AIはどのように機能しますか?
AI vs. AIは、Hugging Faceで開発されたオープンソースのツールで、マルチエージェント環境での強化学習モデルの強さをランク付けするためのものです。
アイデアは、モデルを継続的に互いに対戦させ、その結果を使用して他のすべてのモデルと比較してパフォーマンスを評価し、ポリシーの品質を把握するための相対的なスキルの尺度を得ることです。従来のメトリクスを必要とせずに。
エージェントが特定のタスクや環境に提出される数が増えるほど、ランキングはより代表的になります。
競争環境での試合結果に基づいて評価を生成するために、私たちはELOレーティングシステムを基にランキングを作成することにしました。
コアコンセプトは、試合が終了した後、両プレーヤーのレーティングを結果と前回のゲーム前のレーティングに基づいて更新することです。高いレーティングのユーザーが低いレーティングのユーザーに勝つと、多くのポイントを獲得することはありません。同様に、敗者もこの場合は多くのポイントを失いません。
逆に、低いレーティングのプレーヤーが高いレーティングのプレーヤーに逆転勝利すると、両者のレーティングにはより大きな影響があります。
私たちは、このコンテキストでプレーヤーの開始レーティングに基づいて獲得または失われる量に変更を加えないようにシステムをできるだけシンプルに保ちました。そのため、獲得と損失は常に完全に逆の値(+10 / -10など)であり、平均ELOレーティングは開始レーティングで一定に保たれます。1200 ELOレーティングの開始選択は完全に任意です。
ELOについて詳しく学び、計算例を見たい場合は、当社のDeep Reinforcement Learning Courseの説明を参照してください。
このレーティングを使用すると、強さが同等のモデル間で自動的にマッチを生成することが可能です。マッチメイキングシステムの作成方法はいくつかありますが、ここでは比較的シンプルに保ちながらも、マッチの多様性の最小限の保証と、ほとんどのマッチが対戦相手のレーティングにかなり近いもので行われることを確保することを選択しました。
アルゴリズムの動作は以下の通りです:
- Hubに利用可能なすべてのモデルを収集します。新しいモデルは1200の開始レーティングを持ち、他のモデルは以前の試合で獲得/失ったレーティングを保持します。
- これらのモデルからキューを作成します。
- キューから最初の要素(モデル)をポップし、最初のモデルに最も近いレーティングを持つnモデルの中からランダムに別のモデルをポップします。
- 両方のモデルを環境(Unityの実行可能ファイルなど)にロードし、結果を収集してこの試合をシミュレートします。この実装では、結果をHugging Face Dataset on the Hubに送信しました。
- 受け取った結果とELOの式に基づいて、両モデルの新しいレーティングを計算します。
- 2つずつモデルをポップし、マッチをシミュレートし、キューにモデルが1つまたは0つだけになるまで続けます。
- 結果のレーティングを保存し、ステップ1に戻ります。
このマッチメイキングプロセスを連続的に実行するために、無料のHugging Face Spacesハードウェアとスケジューラを使用してマッチメイキングプロセスをバックグラウンドタスクとして実行し続けています。
Spaces は、既に行われた各モデルの ELO レーティングを取得し、その結果を表示するためのリーダーボードを提供するためにも使用されます。
このプロセスでは、Hugging Face の複数のデータセットが一般的にデータの永続性を提供するために使用されます(ここでは、試合の履歴とモデルの評価)。
このプロセスでは試合の履歴も保存されるため、任意のモデルの結果を正確に見ることができます。たとえば、なぜあなたのモデルが他のモデルと対戦で苦戦するのかを確認することができ、特にこのようなデモ Space を使用して試合の可視化も可能です。
現時点では、この実験は Hugging Face Deep RL コースの MLAgent 環境 SoccerTwos で実行されていますが、一般的には環境に依存しないため、さまざまな対抗的なマルチエージェント設定の評価に無料で使用することができます。
もちろん、再度強調する必要がありますが、この評価は提出されたエージェントの強さの相対的な評価であり、評価自体には他の指標とは異なる客観的な意味はありません。これは、プール内の他のモデルと比較してモデルのパフォーマンスがどれほど良いか悪いかを表すだけです。ただし、十分な数のモデルが存在し、十分な数の試合が行われる場合、この評価はモデルの一般的なパフォーマンスを非常に確かな方法で表すものとなります。
初めての AI vs. AI チャレンジ実験:SoccerTwos チャレンジ ⚽
このチャレンジは、無料の Deep Reinforcement Learning コースの Unit 7 です。2022年2月1日に開始し、4月30日に終了します。
興味がある場合、コースに参加しなくても競技に参加することができます。こちらから始めることができます 👉 https://huggingface.co/deep-rl-course/unit7/introduction
このユニットでは、読者はマルチエージェント強化学習(MARL)の基礎を学び、2vs2 のサッカーチームをトレーニングしました。⚽
使用された環境は Unity ML-Agents チームによって作成されました。目標は単純です:あなたのチームはゴールを決める必要があります。そのためには、相手チームに勝利し、チームメイトと協力する必要があります。
リーダーボードに加えて、人々が2つのチームを選んでプレイを視覚化できる Space のデモも作成しました 👉 https://huggingface.co/spaces/unity/SoccerTwos
この実験は順調に進んでおり、すでにリーダーボードには48のモデルがあります 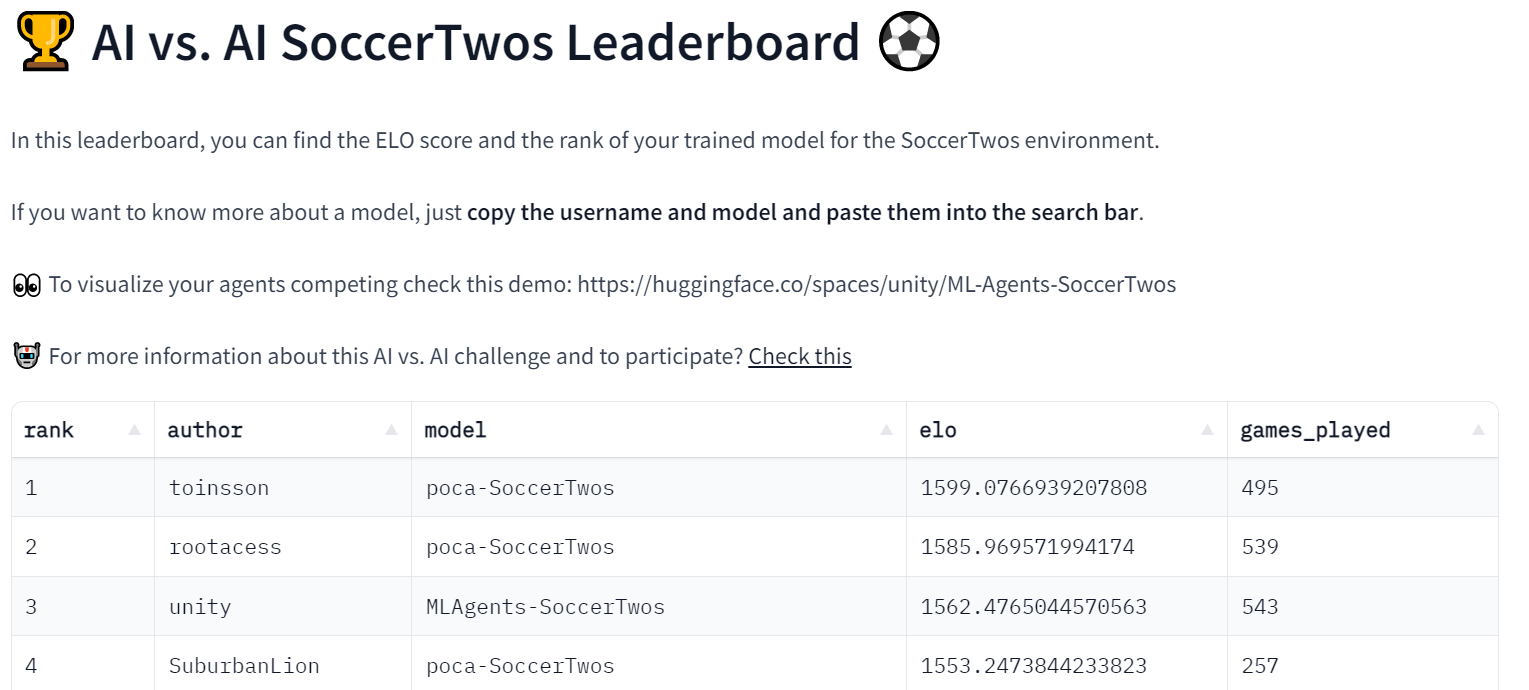
また、ai-vs-ai-competition という Discord チャンネルも作成しましたので、他の人と交流し、アドバイスを共有することができます。
結論と今後の展望
開発したツールは環境に依存しないため、将来的には PettingZoo や他のマルチエージェント環境でさらに多くのチャレンジを開催したいと考えています。もし実施したい環境やチャレンジがある場合は、お気軽にご連絡ください。
将来的には、このツールと私たちが作成した環境で複数のマルチエージェント競技会を開催する予定です。SnowballFightなども含まれます。
マルチエージェント競技会を開催するための便利なツールであるだけでなく、このツールはマルチエージェント設定での堅牢な評価手法としても考えられます。多くのポリシーと対戦することで、あなたのエージェントはさまざまな振る舞いに対して評価され、ポリシーの品質をよく理解することができます。
連絡を保つための最良の方法は、私たちとコミュニティとの交流のために Discord サーバーに参加することです。
****************引用****************
引用:学術的な研究に役立つ場合は、以下のように引用していただければ幸いです。
Cochet, Simonini, "Introducing AI vs. AI a deep reinforcement learning multi-agents competition system", Hugging Face Blog, 2023.
BibTeX 引用:
@article{cochet-simonini2023,
author = {Cochet, Carl and Simonini, Thomas},
title = {Introducing AI vs. AI a deep reinforcement learning multi-agents competition system},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/aivsai},
}We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






