複数の画像やテキストの解釈 Fine Tuning Transformer

テキストをベクトルに変換する:TSDAEによる強化埋め込みの非教示アプローチ
TSDAEの事前学習を対象ドメインで行い、汎用コーパスでの教師付き微調整と組み合わせることで、特化ドメインの埋め込みの品質...
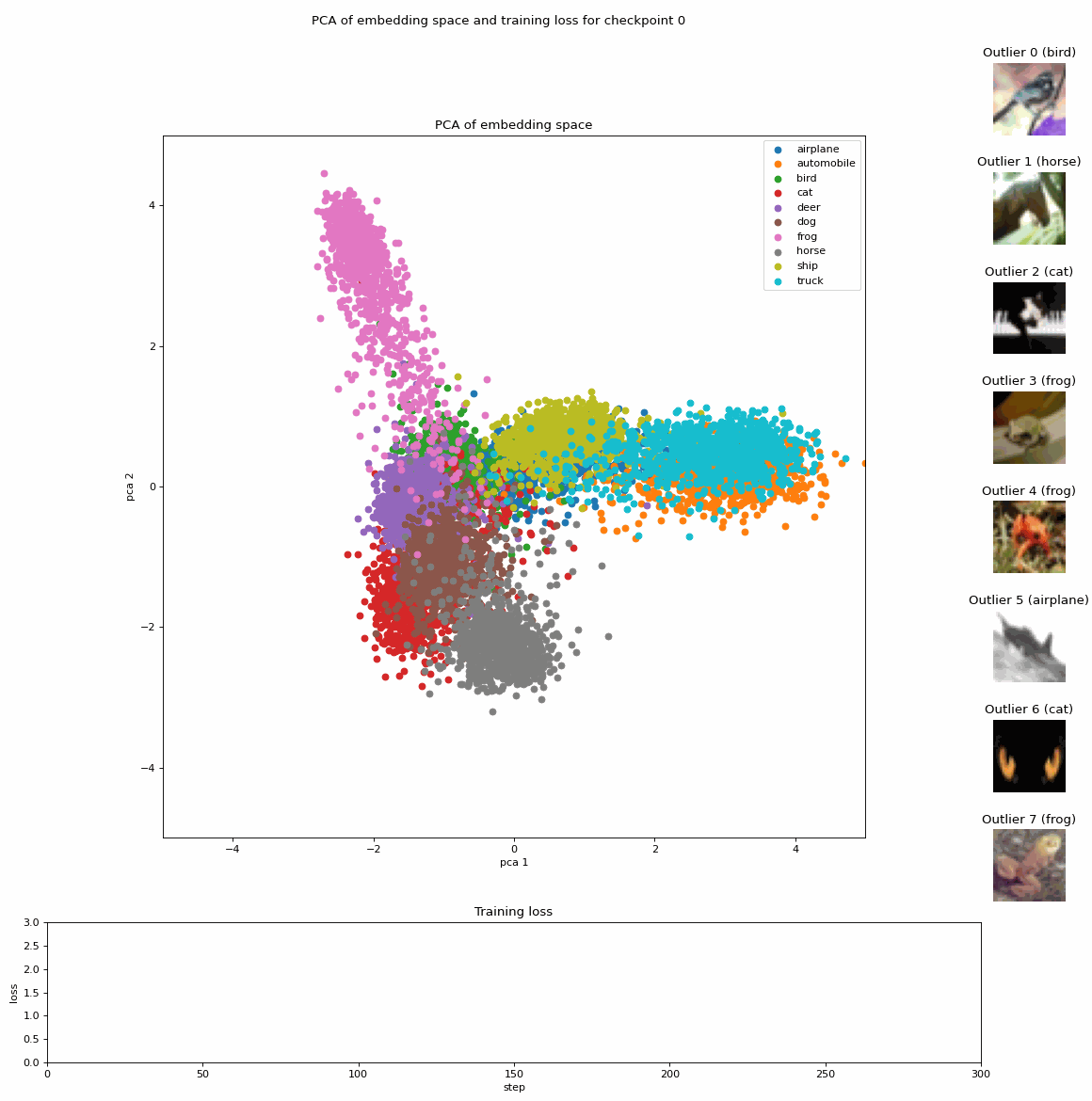
「ファインチューニング中に埋め込みのアニメーションを作成する方法」
「機械学習の分野では、ビジョントランスフォーマー(ViT)は画像分類に使用されるモデルの一種です従来の畳み込みニューラル...

- You may be interested
- 「Transformerモデルの実践的な導入 BERT」
- アマゾンセージメーカーでのLlama 2のベン...
- 究極のGFNサーズデー:41の新しいゲームに...
- 「SuperDuperDBを活用して簡単にシンプル...
- 顧客の生涯価値をモデリングする方法:良...
- 洞察を具体的な成果に変える
- AIにおける幻覚の克服:事実に基づく強化...
- 偽りの預言者:自家製の時系列回帰モデル
- 「生成型AIのGPT-3.5からGPT-4への移行の...
- 現代の時代において、信頼性のある量子コ...
- 「お知らせ:フォーカスエンターテイメン...
- ローカルマシン上でGenAI LLMsのパワーを...
- ImageBind-LLMにおけるマルチモーダリティ...
- 「AIは忘れることも学ぶべきです」
- 3Dで「ウォーリーを探せ」をプレイする:O...
Find your business way
Globalization of Business, We can all achieve our own Success.