Learn more about Search Results arXiv - Page 9

- You may be interested
- 「人型ロボットは人間よりも飛行機を操縦...
- Hugging Faceを使用してWav2Vec2を英語音...
- 「ReLU vs. Softmax in Vision Transforme...
- 「クリエイティブな超能力を持つPix2Pixの...
- 「Google CloudがGenerative AIの保護を顧...
- 「研究者がWindows Helloの実装に脆弱性を...
- このAI論文は、大規模なビジョン・ランゲ...
- データサイエンスのためのSQL:ジョインの...
- CPU上でBERT推論をスケーリングアップする...
- USCの研究者は、新しい共有知識生涯学習(...
- DatabricksがMosaicMLとその他の最近のAI...
- 「ジンディのCEO兼共同創設者、セリーナ・...
- AIのレンズを通じた世界の歴史
- 「LLMsはインコンテキスト学習を達成する...
- 「クリスマスラッシュ」3Dシーンが今週の...

「データサイエンス30年:データサイエンス実践者からのレビュー」
データサイエンスの実践者からのレビュー

「コンテキストに基づくドキュメント検索の強化:GPT-2とLlamaIndexの活用」
はじめに 情報検索の世界では、探索を待ち受けるテキストデータの海において、関連するドキュメントを効率的に特定する能力は非常に貴重です。従来のキーワードベースの検索には限界がありますが、特に個人情報や機密データを扱う場合には、これらの課題を克服するために、2つの素晴らしいツール、GPT-2とLlamaIndexの統合に頼ることがあります。この記事では、これら2つのテクノロジーがどのように連携してドキュメントの検索を変革するかを示すコードについて詳しく説明します。 学習目標 GPT-2という多目的な言語モデルと、個人情報に焦点を当てたライブラリであるLLAMAINDEXのパワーを効果的に組み合わせて、ドキュメントの検索を変革する方法を学ぶ。 GPT-2の埋め込みを使用してドキュメントをインデックスし、ユーザーのクエリとの類似度に基づいてランキングするプロセスを示す、シンプルなコードの実装についての洞察を得る。 大きな言語モデルの統合、マルチモーダルコンテンツのサポート、倫理的な考慮を含む、ドキュメントの検索の将来のトレンドを探索し、これらのトレンドがこの分野をどのように形作るかを理解する。 この記事は、データサイエンスブログマラソンの一環として公開されました。 GPT-2:言語モデルの巨人の解明 GPT-2の解説 GPT-2は、「Generative Pre-trained Transformer 2」の略であり、オリジナルのGPTモデルの後継です。OpenAIによって開発されたGPT-2は、理解力と人間らしいテキストの生成能力において画期的な能力を持って登場しました。これは、現代のNLPの基盤となったTransformerモデルに基づく傑出したアーキテクチャを誇っています。 Transformerアーキテクチャ GPT-2の基盤となるのはTransformerアーキテクチャです。これは、Ashish Vaswaniらによって発表された「Let it be what you want it to be」という論文で紹介されたニューラルネットワークの設計です。このモデルは、一貫性、効率性、効果を向上させることで、NLPを革新しました。セルフモニタリング、空間変換、マルチヘッドリスニングなどのTransformerのコア機能により、GPT-2はテキストの内容や関係性を前例のない方法で理解することができます。…
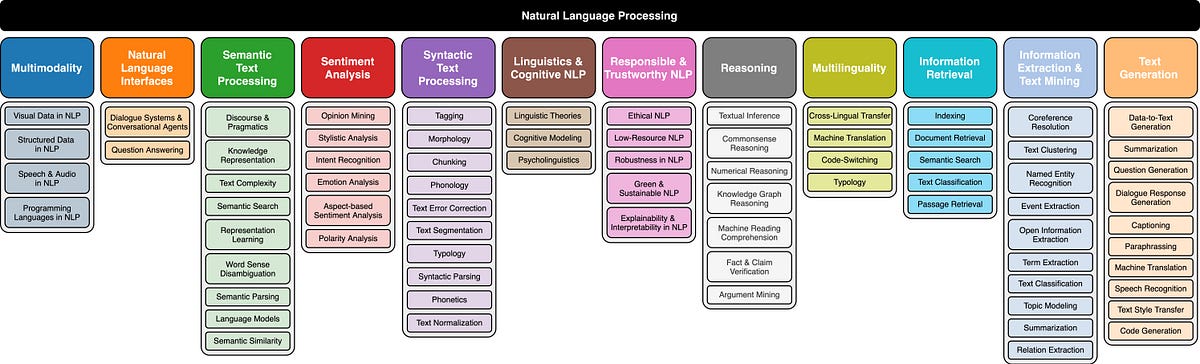
自然言語処理のタクソノミー
「異なる研究分野と最近の自然言語処理(NLP)の進展の概要」
「自分の武器を選ぶ:うつ病AIコンサルタントの生存戦略」
最新のターミネーターの映画が最近公開されましたこの新しいエピソードでは、未来の人間の抵抗組織がロボットを過去に送り、OpenAIのサーバーファームを破壊し、それによって…の出現を防ぎます
「ゼロからLLMを構築する方法」
「これは、大規模言語モデル(LLM)を実践的に使用するシリーズの6番目の記事です以前の記事では、プロンプトエンジニアリングとファインチューニングを通じて事前学習済みのLLMを活用する方法について詳しく調査しましたこれらに対して…」

「ヌガットモデルを使用した研究論文の生成AI」
最近の大規模言語モデル(LLM)の進展(例:GPT-4)は、一貫したテキストの生成能力において印象的な成果を示していますしかし、研究論文の解析と理解は依然として…

「LLaMaをポケットに収めるトリック:LLMの効率とパフォーマンスを結ぶAIメソッド、OmniQuantに出会おう」
大型言語モデル(LLM)は、機械翻訳、テキスト要約、質問応答など、さまざまな自然言語処理タスクで印象的なパフォーマンスを発揮しています。彼らは私たちがコンピュータとコミュニケーションを取る方法やタスクを行う方法を変えてきました。 LLMは、自然言語の理解と生成の限界を押し広げる変革的な存在として現れています。その中でもChatGPTは、会話の文脈でユーザーと対話するために設計されたLLMのクラスを代表する注目すべき例です。これらのモデルは、非常に大きなテキストデータセットでの集中的なトレーニングの結果、人間のようなテキストを理解し生成する能力を持っています。 しかし、これらのモデルは計算とメモリの消費量が多く、実用的な展開を制限しています。その名前が示すように、これらのモデルは大きいです。最新のオープンソースLLMであるMetaのLLaMa2は、約700億のパラメータを含んでいます。 これらの要件を削減することは、より実用的にするための重要なステップです。量子化は、LLMの計算とメモリのオーバーヘッドを削減する有望な技術です。量子化には、トレーニング後の量子化(PTQ)と量子化に対応したトレーニング(QAT)の2つの主要な方法があります。QATは競争力のある精度を提供しますが、計算と時間の両方の面で非常に高価です。そのため、PTQは多くの量子化の試みで主要な方法となっています。 重みのみの量子化や重み活性化の量子化など、既存のPTQ技術は、メモリ消費量と計算オーバーヘッドの大幅な削減を達成しています。ただし、効率的な展開には重要な低ビット量子化で苦労する傾向があります。低ビット量子化におけるこの性能の低下は、手作業での量子化パラメータに依存しているため、最適な結果が得られないことが主な原因です。 それでは、OmniQuantに会いましょう。これはLLM用の画期的な量子化技術であり、特に低ビット設定でさまざまな量子化シナリオで最先端のパフォーマンスを実現し、PTQの時間とデータの効率性を保ちます。 OmniQuantのLLaMaファミリーにおける特徴。出典: https://arxiv.org/pdf/2308.13137.pdf OmniQuantは、元の完全精度の重みを凍結し、一部の学習可能な量子化パラメータを組み込むというユニークなアプローチを取ります。QATとは異なり、煩雑な重みの最適化を必要とせず、OmniQuantは個々のレイヤーに焦点を当てた順次量子化プロセスに焦点を当てています。これにより、単純なアルゴリズムを使用した効率的な最適化が可能になります。 OmniQuantは、学習可能な重みクリッピング(LWC)と学習可能な等価変換(LET)という2つの重要なコンポーネントで構成されています。LWCはクリッピング閾値を最適化し、極端な重み値を調整します。一方、LETはトランスフォーマーエンコーダ内で等価変換を学習することで、アクティベーションの外れ値に対処します。これらのコンポーネントにより、完全精度の重みとアクティベーションを量子化しやすくします。 OmniQuantの柔軟性は、重みのみの量子化や重み活性化の量子化の両方に対応しており、量子化されたモデルには追加の計算負荷やパラメータが必要ありません。なぜなら、量子化パラメータは量子化された重みに融合されるからです。 OmniQuantの概要。出典: https://arxiv.org/pdf/2308.13137.pdf LLM全体のすべてのパラメータを共同で最適化する代わりに、「OmniQuant」は次のレイヤーに移る前に1つのレイヤーのパラメータを順次量子化します。これにより、OmniQuantは単純な確率的勾配降下法(SGD)アルゴリズムを使用して効率的に最適化することができます。 これは実用的なモデルであり、単一のGPU上でも簡単に実装できます。自分自身のLLMを16時間で訓練することができるため、さまざまな実世界のアプリケーションで本当にアクセスしやすくなります。また、OmniQuantは以前のPTQベースの方法よりも優れたパフォーマンスを発揮するため、パフォーマンスを犠牲にすることはありません。 ただし、これはまだ比較的新しい手法であり、パフォーマンスにはいくつかの制約があります。たとえば、フルプレシジョンモデルよりもわずかに悪い結果を生み出すことがある場合があります。しかし、これはOmniQuantの小さな不便さであり、LLMの効率的な展開のための有望な技術です。

無料でGoogle Colab上でQLoraを使用してLLAMAv2を微調整する
「Google Colabで最も影響力のあるオープンソースモデルの微調整方法を無料で学びましょう」

LLMs(Language Model)と知識グラフ
LLMとは何ですか? Large Language Models (LLMs)は、人間の言語を理解し生成できるAIツールです。これらは、膨大な量のテキストデータでトレーニングされた数十億のパラメータを持つ強力なニューラルネットワークです。これらのモデルの広範なトレーニングにより、人間の言語の構造と意味について深い理解を持っています。 LLMsは、翻訳、感情分析、チャットボットの会話など、さまざまな言語タスクを実行することができます。LLMsは、複雑なテキスト情報を理解し、エンティティとその関係を認識し、繋がりを保ち、文法的に正しいテキストを生成することができます。 ナレッジグラフとは何ですか? ナレッジグラフは、異なるエンティティに関するデータと情報を表し結びつけるデータベースです。これには、オブジェクト、人物、場所を表すノードと、ノード間の関係を定義するエッジが含まれます。これにより、機械はエンティティがどのように関連し、属性を共有し、私たちの周りの世界の異なるものとの関係を把握することができます。 ナレッジグラフは、YouTubeの推奨ビデオ、保険詐欺の検出、小売業での製品推奨、予測モデリングなど、さまざまなアプリケーションで使用することができます。 出典:https://arxiv.org/pdf/2306.08302.pdf | ナレッジグラフの例 LLMsとナレッジグラフ LLMsの主な制限の1つは、「ブラックボックス」であること、つまり、彼らが結論にどのようにたどり着いているかを理解するのが難しいということです。さらに、彼らはしばしば事実情報を把握し取得するのが難しく、幻覚として知られる誤りや不正確さが生じることがあります。 ここで、ナレッジグラフがLLMsを推論するための外部知識を提供することができます。ただし、ナレッジグラフは構築が困難であり、進化している性質を持っています。そのため、LLMsとナレッジグラフを一緒に使用して、それぞれの強みを最大限に活かすことは良いアイデアです。 LLMsは、次の3つのアプローチを使用してナレッジグラフ(KGs)と組み合わせることができます: KGを活用したLLMs:これらは、トレーニング中にKGをLLMsに統合し、より理解力を高めるために使用します。 LLMを拡張したKGs:LLMsは、埋め込み、完了、質問応答など、さまざまなKGタスクを改善することができます。 シナジー効果のあるLLMs + KGs:LLMsとKGsは互いに補完し合い、データと知識に基づいた双方向の推論を促進します。 KGを活用したLLMs LLMsは、広範なテキストデータから学習することによって、さまざまな言語タスクで優れた能力を持つことで知られています。ただし、誤った情報(幻覚)を生成したり、解釈可能性に欠けたりするという批判も受けています。研究者は、これらの問題に対処するために、LLMsをナレッジグラフ(KGs)で拡張することを提案しています。 KGsは構造化された知識を保存しており、それを使用してLLMsの理解を向上させることができます。一部の手法では、LLMの事前トレーニング中にKGsを統合して知識の獲得を支援し、他の手法では推論中にKGsを使用してドメイン固有の知識アクセスを向上させます。KGsは、LLMsの推論と事実の解釈に使用され、透明性を改善します。…

「見えないものを拡大する:この人工知能AIの手法は、3Dで微妙な動きを可視化するためにNeRFを使用します」
私たちは、身体の微妙な動きから地球の大規模な動きまで、動きに満ちた世界に生きています。しかし、これらの動きの多くは肉眼では見えないほど小さいものです。コンピュータビジョンの技術を使用して、これらの微妙な動きを抽出し、拡大することで、より見やすく理解しやすくすることができます。 最近、ニューラル放射フィールド(NeRF)が3Dシーンの再構築とレンダリングにおける強力なツールとして登場しました。 NeRFは、画像のコレクションから3Dシーンの外観を表現するために訓練することができ、その後、任意の視点からシーンをレンダリングするために使用することができます。 NeRFは、画像のコレクションから3Dシーンの外観を表現します。 NeRFは、3Dポイントから対応する色と輝度へのマッピング関数を学習することによって動作します。この関数は、任意の視点からシーンをレンダリングするために使用することができます。これらのモデルは、複雑な3Dシーンの外観を非常に効果的に表現することが示されています。これらは、物体、シーン、さらには人物のリアルな3Dモデルをレンダリングするために使用されています。 NeRFは、仮想現実、拡張現実、コンピュータグラフィックスの新しいアプリケーションの開発にも使用されています。 3Dシーンの微妙な動きを拡大するためにNeRFの力を利用したらどうでしょうか?これは簡単な課題ではありません。いくつかの課題が存在します。 最初の課題は、微妙な動きを持つシーンの画像のセットを収集することです。これは困難な課題であり、動きは肉眼では感じられないほど小さくなければなりませんが、カメラでキャプチャするには十分に大きくなければなりません。 2番目の課題は、収集した画像からシーンの外観を表現するためにNeRFを訓練することです。これは難しい課題であり、NeRFはシーンの微妙な時間的変動を学習できる必要があります。 3番目の課題は、NeRFのポイント埋め込みにオイラー運動解析を行うことです。これは計算量の多いタスクであり、高次元空間での時間的変動を分析する必要があります。 それでは、これらの課題に賢明に対処する3Dモーションマグニフィケーションについて見てみましょう。 3Dモーションマグニフィケーション。出典:https://arxiv.org/pdf/2308.03757.pdf 3Dモーションマグニフィケーションは、NeRFの力を利用するAIの手法です。 NeRFを使用して、微妙な時間的変動を持つシーンを表現します。 NeRFのレンダリングの上に、オイラー運動解析が適用され、NeRFのポイント埋め込みの時間的変動が増幅されます。これにより、以前は見えなかった微妙な動きが拡大された3Dシーンが表示されます。 この手法にはいくつかの重要なステップがあります。最初のステップはデータ収集とNeRFの訓練です。微妙な動きを持つシーンの画像のセットを収集することから始まります。画像は異なる視点から、さまざまな時間ステップでキャプチャする必要があります。そして、これらの収集した画像を使用して、収集した画像からシーンの外観を表現するために使用するNeRFモデルを訓練します。これは、レンダリングされた画像と正解の画像との間の差を測定する損失関数を最小化するために訓練されます。 提案手法の概要。出典:https://arxiv.org/pdf/2308.03757.pdf NeRFモデルが準備できたら、次のステップはオイラー運動解析を行うことです。NeRFのポイント埋め込みの時間変動は、オイラー運動解析を使用して増幅されます。これは流体や固体の運動を解析するための数学的なフレームワークです。NeRFのポイント埋め込みなど、任意の時間変動するフィールドの時間変動を抽出するために使用することができます。これらの増幅された時間変動は、シーン内の動きを拡大するために使用されます。これは、増幅されたポイント埋め込みを使用してNeRFからシーンをレンダリングすることによって行われます。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.