Learn more about Search Results analyticsvidhya - Page 9

- You may be interested
- 「CEO氏によると、ホンダは東京で自動運転...
- 「Azure Data Factory(ADF)とは何ですか...
- 大規模言語モデル(LLM)の調査
- 大規模な言語モデルにおけるコンテキスト...
- AI増強ソフトウェアエンジニアリング:知...
- 「先進的なマルチモーダル生成AIの探求」
- データサイエンスプロジェクトでのPython...
- 「ChatGPTなどの大規模言語モデル(LLM)が...
- トランスフォーマーにおける対比的探索を...
- GEKKOを使用して、世界を確定的な方法でモ...
- 交通部門でのAIのトップ6の使用法
- 「クラシック音楽の作曲家を識別するため...
- 「データサイエンスをマスターするための...
- 『Generative AIがサイバーセキュリティを...
- 初心者向けチュートリアル:Microsoft Azu...

テキストから音声へ – 大規模な言語モデルのトレーニング
はじめに 音楽家の声コマンドをAIが受け取り、美しいメロディックなギターサウンドに変換する世界を想像してみてください。これはSFではありません。オープンソースコミュニティでの画期的な研究「The Sound of AI」の成果です。本記事では、「テキストからサウンドへ」というジェネレーティブAIギターサウンドの範囲内で、「ミュージシャンの意図認識」のための大規模言語モデル(LLM)の作成の道のりを探求します。このビジョンを実現するために直面した課題と革新的な解決策についても議論します。 学習目標: 「テキストからサウンド」のドメインでの大規模言語モデルの作成における課題と革新的な解決策を理解する。 声コマンドに基づいてギターサウンドを生成するAIモデルの開発において直面する主な課題を探求する。 ChatGPTやQLoRAモデルなどのAIの進歩を活用した将来のアプローチについて、ジェネレーティブAIの改善に関する洞察を得る。 問題の明確化:ミュージシャンの意図認識 問題は、AIが音楽家の声コマンドに基づいてギターサウンドを生成できるようにすることでした。例えば、音楽家が「明るいギターサウンドを出してください」と言った場合、ジェネレーティブAIモデルは明るいギターサウンドを生成する意図を理解する必要があります。これには文脈とドメイン特有の理解が必要であり、一般的な言語では「明るい」という言葉には異なる意味がありますが、音楽のドメインでは特定の音色の品質を表します。 データセットの課題と解決策 大規模言語モデルのトレーニングには、モデルの入力と望ましい出力に一致するデータセットが必要です。ミュージシャンのコマンドを理解し、適切なギターサウンドで応答するために、適切なデータセットを見つける際にいくつかの問題が発生しました。以下に、これらの問題の対処方法を示します。 課題1:ギターミュージックドメインのデータセットの準備 最初の大きな課題は、ギターミュージックに特化したデータセットが容易に入手できないことでした。これを克服するために、チームは独自のデータセットを作成する必要がありました。このデータセットには、音楽家がギターサウンドについて話し合う会話が含まれる必要がありました。Redditの議論などのソースを利用しましたが、データプールを拡大する必要があると判断しました。データ拡張、BiLSTMディープラーニングモデルの使用、コンテキストベースの拡張データセットの生成などの技術を使用しました。 課題2:データの注釈付けとラベル付きデータセットの作成 2番目の課題は、データの注釈付けを行い、ラベル付きのデータセットを作成することでした。ChatGPTなどの大規模言語モデルは一般的なデータセットでトレーニングされることが多く、ドメイン固有のタスクに対してファインチューニングが必要です。例えば、「明るい」という言葉は、光や音楽の品質を指す場合があります。チームは、正しい文脈をモデルに教えるために、Doccanoという注釈付けツールを使用しました。ミュージシャンは楽器や音色の品質に関するラベルをデータに注釈付けしました。ドメインの専門知識が必要であるため、注釈付けは困難でしたが、チームはデータを自動的にラベル付けするためにアクティブラーニングの手法を一部適用し、これに対処しました。 課題3:MLタスクとしてのモデリング – NERアプローチ 適切なモデリングアプローチを決定することもまた、別のハードルでした。トピックまたはエンティティの識別として見るべきでしょうか?チームは、モデルが音楽に関連するエンティティを識別して抽出できるNamed Entity Recognition(NER)を採用しました。spaCyの自然言語処理パイプライン、HuggingFaceのRoBERTaなどのトランスフォーマーモデルを活用しました。このアプローチにより、ジェネレーティブAIは音楽のドメインにおける「明るい」や「ギター」といった単語の文脈を認識できるようになりました。 モデルトレーニングの課題と解決策…
「AIを使ってGmailの受信トレイをクリアする方法」
あなたはGmailの受信トレイでメールの山を探検するのに疲れていますか?ニュースレターやプロモーション、スパムに溺れている自分を見つけますか?それでは、あなたは一人ではありません。メールの過負荷は私たちのデジタル時代における共通の問題です。そして、AIのおかげで、メールがあふれる問題に完璧な解決策があります。AIを使ってGmailの受信トレイを整理する方法を学びましょう! Gmailの受信トレイを整理するためのトップ5のAIツール これらのAIパワードツールは、Gmailの受信トレイを取り戻すために必要な方にとって非常に価値のあるものです。メールのクリーンアップ、整理、優先順位付けを自動化することで、ユーザーは生産性を保ち、重要なことに集中することができます。混雑した受信トレイに対処しているか、単にメールの管理を効率化したい場合でも、これらのトップ5のAIツールはあなたをサポートします。 Clean.email Clean.emailは、メールの受信トレイを簡単にクリーンアップし管理するための強力なツールと機能を提供しています。Clean.emailがあなたにできることを詳しく見てみましょう: 主な特徴 メールのバンドル: Clean.emailは、送信者、件名、またはラベルなどの共通の特徴に基づいてメールを知的にバンドルすることができます。これらのバンドルされたメールは、便利にゴミ箱に移動したり一緒にアーカイブしたりすることができます。これにより、受信トレイが整理され、シンプルになります。 ニュースレターの管理: 邪魔なニュースレターが受信トレイを詰まらせているのにうんざりしていますか?Clean.emailを使用すると、ニュースレターの購読を解除したり一時停止したりすることができます。また、ニュースレターの最新バージョンのみを保持することも選択できますので、受信トレイを新鮮で関連性のある状態に保つことができます。 クイッククリーン: メールを迅速にクリアしたいですか?クイッククリーン機能は、ソーシャル通知や指定期間より古いメッセージ(例:3年以上前のメール)など、一般的にクリーンアップされるメールを対象にしており、簡単に整理するのに役立ちます。 スマートビュー: Clean.emailはスマートビューを使用してメールを知的に整理します。類似した種類のメールは一緒にグループ化され、受信トレイのナビゲーションが簡素化され、重要なことに集中しやすくなります。 広範なメールプロバイダのサポート: Gmail、Yahoo、AOL、iCloud、Outlook、およびIMAPを使用している他のメールサービス。 このツールを使ってGmailの受信トレイをクリーニングしてみましょう。 Mailsorm このAIメールクリーナーは、メールの管理を簡素化する堅牢なメールクリーンアップツールです。 主な特徴 メールのバンドル: Mailsormは、関連するメールを特定し、それらを一緒にバンドルすることに優れています。この機能により、関連するメールをグループとして管理できるため、一括でアクションを実行しやすくなります。 スパムブロック: 受信トレイを詰ませるスパムメールにさようならを言いましょう。Mailsormは便利なワンクリックのスパムブロック機能を提供し、受信トレイをクリーンで不要なメールから解放します。…

ARとAI:拡張現実におけるAIの役割
イントロダクション AI(人工知能)と拡張現実(AR)の画期的なテクノロジーによって、数値産業は変革されています。AIは機械に人間の思考や意思決定を行わせる一方、ARはデジタル情報を物理環境に重ね合わせます。これら2つの先端技術が組み合わさることで、新たな可能性が開かれます。本記事では、AIとARの統合について、基礎知識、シナジー効果、および異なる産業への潜在的な影響について議論します。 AIと拡張現実の概要 拡張現実(AR): ARは、コンピュータ生成の画像、映画、情報を現実世界に重ね合わせて、私たちの現実体験を変えるテクノロジーです。仮想現実とは異なり、完全にシミュレーションされた環境にユーザーを融合させるのではなく、拡張現実(AR)は現実世界にデジタルの要素を追加します。 人工知能(AI): AIは、従来、人間の知能を必要とするタスクを実行できる機械を作り出すことを指します。これには、意思決定、問題解決、音声認識、言語翻訳などが含まれます。AIシステムはデータから学習し、環境に応じて変化することができます。 関連記事:アルゴリズムのバイアスの理解:種類、原因、事例 なぜAIを拡張現実に統合するのか? AIとARの統合は、いくつかの理由から重要です: ユーザーエクスペリエンスの向上: AIの能力により、ARアプリケーションはユーザーの環境、好み、行動を分析・理解することができるため、より個別化された没入型のエクスペリエンスを提供することができます。 リアルタイムの意思決定: AIアルゴリズムは、大量のデータをリアルタイムで分析する能力があり、ユーザーの環境の変化に迅速に対応することができるため、ARアプリは素早く反応することができます。 物体認識の向上: AIによる拡張現実は、現実世界の物体を正確に認識・追跡することができるため、ゲーム、小売り、ナビゲーションに適しています。 効率的なデータ処理: AIは、ARアプリがさまざまなセンサーやカメラからのデータを処理・解釈するのを支援し、よりスムーズで正確なAR体験を実現します。 多様性: AIとARは、ゲーム、教育から医療や製造に至るまで、さまざまな用途があります。 拡張現実の理解 ARとその応用の定義 その名の通り、拡張現実は物理世界にデジタルデータを追加します。テキスト、映画、インタラクティブな機能、3Dモデルなど、さまざまな要素が含まれます。拡張現実のさまざまな用途には、次のようなものがあります: ゲーム:…

アルゴリズムのバイアスの理解:タイプ、原因、および事例研究
はじめに あなたのソーシャルメディアのフィードがあなたの興味を驚くほど正確に予測するのはなぜでしょうか?また、特定の個人がAIシステムとのやり取りで差別を受けるのはなぜでしょうか?その答えは、人工知能内の複雑で浸透力のある問題であるアルゴリズムの偏りにあります。この記事では、アルゴリズムの偏りとは何か、そのさまざまな側面、原因、および結果について開示します。さらに、責任あるAI開発と公正な利用のために、AIシステムへの信頼を確立することの緊迫性を強調します。 アルゴリズムの偏りとは何ですか? アルゴリズムの偏りとは、コンピュータプログラムが不公平な決定を下すことです。これは、完全に公平ではないデータから学習したためです。例えば、仕事を決定するのに役立つロボットを想像してください。そのロボットが主に男性の履歴書で訓練され、女性の資格についてはほとんど知識がない場合、候補者を選ぶ際に男性に不当に有利になるかもしれません。これはロボットが不公平でありたいわけではなく、バイアスのあるデータから学んだためです。アルゴリズムの偏りとは、コンピュータが教えられた情報のせいで、このように不公平な選択を意図せずにすることです。 出典:LinkedIN アルゴリズムの偏りの種類 データの偏り これは、AIモデルの訓練に使用されるデータが実世界の人口を代表していないため、偏ったまたはバランスの取れていないデータセットが生じると発生します。例えば、顔認識システムが主に肌の色の明るい人々の画像で訓練されている場合、より暗い肌色の人々を認識しようとする際にパフォーマンスが低下し、特定の人種グループに過度の影響を与えるデータの偏りが生じることがあります。 モデルの偏り これはAIモデルの設計とアーキテクチャ中に生じる偏りを指します。例えば、AIアルゴリズムが利益最大化のために設計されている場合、倫理的な考慮よりも財務上の利益を優先する決定を下すことがあり、公正性や安全性よりも利益最大化を優先するモデルの偏りが生じる可能性があります。 評価の偏り これは、AIシステムのパフォーマンスを評価するために使用される基準自体が偏っている場合に発生します。例えば、特定の文化や社会経済集団に有利な標準化されたテストを使用する教育評価AIの場合、教育における不平等を継続させる評価の偏りが生じる可能性があります。 アルゴリズムの偏りの原因 アルゴリズムの偏りの原因はいくつかありますが、それらの原因を理解し、差別を効果的に緩和し対処するためには重要です。以下にいくつかの主な原因を示します: バイアスのある訓練データ バイアスのある訓練データはバイアスの主な原因の一つです。AIシステムに教えるために使用されるデータが歴史的な偏見や不平等を反映している場合、AIはそのバイアスを学習し継続させる可能性があります。例えば、歴史的な採用データが女性や少数派グループに対してバイアスがある場合、採用のために使用されるAIも特定の人口を好む傾向があるかもしれません。 サンプリングバイアス サンプリングバイアスは、訓練に使用されるデータが全人口を代表していない場合に発生します。例えば、データが主に都市部から収集され、農村部からは収集されない場合、AIは農村のシナリオに対してうまく機能せず、農村の人口に対するバイアスが生じる可能性があります。 データの前処理 データのクリーニングと前処理の方法によってバイアスが導入される可能性があります。データの前処理方法がバイアスを考慮して慎重に設計されていない場合、最終的なモデルにおいてバイアスが持続したり増幅されたりすることがあります。 特徴選択 モデルを訓練するために選択される特徴や属性はバイアスを導入する可能性があります。特徴が公平性の影響を考慮せずに選択された場合、モデルは無意識に特定のグループを優遇する可能性があります。 モデルの選択とアーキテクチャ 機械学習アルゴリズムとモデルのアーキテクチャの選択はバイアスに寄与する場合があります。一部のアルゴリズムは他よりもバイアスの影響を受けやすく、モデルの設計方法はその公正性に影響を与える可能性があります。…

「LangchainなしでPDFチャットボットを構築する方法」
はじめに Chatgptのリリース以来、AI領域では進歩のペースが減速する気配はありません。毎日新しいツールや技術が開発されています。ビジネスやAI領域全般にとっては素晴らしいことですが、プログラマとして、すべてを学んで何かを構築する必要があるでしょうか? 答えはノーです。この場合、より現実的なアプローチは、必要なものについて学ぶことです。ものを簡単にすると約束するツールや技術がたくさんありますが、すべての場合にそれらが必要というわけではありません。単純なユースケースに対して大規模なフレームワークを使用すると、コードが肥大化してしまいます。そこで、この記事では、LangchainなしでCLI PDFチャットボットを構築し、なぜ必ずしもAIフレームワークが必要ではないのかを理解していきます。 学習目標 LangchainやLlama IndexのようなAIフレームワークが必要ない理由 フレームワークが必要な場合 ベクトルデータベースとインデックス作成について学ぶ PythonでゼロからCLI Q&Aチャットボットを構築する この記事は、Data Science Blogathonの一環として公開されました。 Langchainなしで済むのか? 最近の数ヶ月間、LangchainやLLama Indexなどのフレームワークは、開発者によるLLMアプリの便利な開発を可能にする非凡な能力により、注目を集めています。しかし、多くのユースケースでは、これらのフレームワークは過剰となる場合があります。それは、銃撃戦にバズーカを持ってくるようなものです。 これらのフレームワークには、プロジェクトで必要のないものも含まれています。Pythonはすでに肥大化していることで有名です。その上で、ほとんど必要のない依存関係を追加すると、環境が混乱するだけです。そのようなユースケースの一つがドキュメントのクエリです。プロジェクトがAIエージェントやその他の複雑なものを含まない場合、Langchainを捨ててゼロからワークフローを作成することで、不要な肥大化を減らすことができます。また、LangchainやLlama Indexのようなフレームワークは急速に開発が進んでおり、コードのリファクタリングによってビルドが壊れる可能性があります。 Langchainはいつ必要ですか? 複雑なソフトウェアを自動化するエージェントを構築したり、ゼロから構築するのに長時間のエンジニアリングが必要なプロジェクトなど、より高度なニーズがある場合は、事前に作成されたソリューションを使用することは合理的です。改めて発明する必要はありません、より良い車輪が必要な場合を除いては。その他にも、微調整を加えた既製のソリューションを使用することが絶対に合理的な場合は数多くあります。 QAチャットボットの構築 LLMの最も求められているユースケースの一つは、ドキュメントの質問応答です。そして、OpenAIがChatGPTのエンドポイントを公開した後、テキストデータソースを使用して対話型の会話ボットを構築することがより簡単になりました。この記事では、ゼロからLLM Q&A…

「データ冗長性とは何ですか?利点、欠点、およびヒント」
紹介 データ中心の時代において、効果的なデータ管理と保護はこれまで以上に重要となっています。データ管理の中で、よく取り上げられる概念の一つが「データの冗長性」です。この記事では、データの冗長性の複雑さについて掘り下げ、その利点や欠点について明らかにし、成功した統合のための貴重な洞察を提供します。 データの冗長性とは何ですか? データの冗長性は、データのセキュリティと強靱性を高めるため、システム内またはシステム間でデータを意図的に複製することを意味します。データの冗長性には次の2つの主要な形式が存在します: 完全な冗長性:このアプローチでは、データの同一のコピーを複数の場所に保持します。1つのコピーがハードウェアの故障やその他の問題によってアクセスできなくなった場合、すぐに別のコピーがその場所に入ることができます。 部分的な冗長性:部分的な冗長性は、データのセキュリティとリソースの効率性のバランスを取ります。重要なデータを複製する一方で、いくつかの変化や差異を許容します。 データの冗長性は、データが複数の形式や場所に保存されることで、誤って発生することもあります。これは、一貫性の欠如や混乱を引き起こす可能性があります。 データの冗長性はどのように機能しますか? データの冗長性は、システム内または複数のシステム間でデータを意図的に複製するデータ管理戦略です。この実践により、データの可用性、整合性、耐障害性が確保されます。データの重複コピーは異なる場所に保存され、同期メカニズムが使用されてこれらのコピーを一貫性を保ち、最新の状態に保ちます。 データの冗長性はいくつかの重要な機能を果たします: 1つのソースが利用できなくなった場合でもデータの可用性を向上させ、ダウンタイムを削減し、中断のない運用を保証します。 システムの障害耐性を強化し、ハードウェアの故障やシステムのクラッシュに対する安全なバックアップを提供します。 データの整合性を保護し、事故やサイバー脅威によるデータの損失や破損から守ります。 データの冗長性は、災害復旧に基本的です。災害後の迅速なデータの復元を可能にします。 負荷分散、並列処理、スケーラビリティをサポートすることができ、システムのパフォーマンスを向上させます。 データの冗長性の利点 データの冗長性の利点を探りましょう: データの可用性の向上 データの冗長性により、1つのソースが利用できなくなってもデータにアクセスできるようになります。これは特に、ダウンタイムが許容されないミッションクリティカルなシステムにおいて重要です。 影響:データの可用性の向上により、中断のない運用、ダウンタイムの削減、ユーザーエクスペリエンスの向上が実現します。これは、金融、医療、電子商取引などの分野で重要です。 システムの耐障害性の強化 冗長性はシステムの障害に対する安全装置として機能します。1つのデータソースが破損したり、侵害されたり、ハードウェアの故障やその他の問題によってアクセスできなくなった場合、冗長なソースがシームレスに代わりになります。 影響:障害耐性はシステムの信頼性を高め、重要なアプリケーションやサービスが中断することなく機能することを保証します。これは、システムの障害が重大な影響を及ぼす可能性がある産業において特に重要です。 データの整合性の保護…

「LLMの力を活用する:ゼロショットとフューショットのプロンプティング」
はじめに LLMのパワーはAIコミュニティで新たなブームとなりました。GPT 3.5、GPT 4、BARDなどのさまざまな生成型AIソリューションが異なるユースケースで早期採用されています。これらは質問応答タスク、クリエイティブなテキストの執筆、批判的分析などに使用されています。これらのモデルは、さまざまなコーパス上で次の文予測などのタスクにトレーニングされているため、テキスト生成に優れていると期待されています。 頑健なトランスフォーマーベースのニューラルネットワークにより、モデルは分類、翻訳、予測、エンティティの認識などの言語に基づく機械学習タスクにも適応することができます。したがって、適切な指示を与えることで、データサイエンティストは生成型AIプラットフォームをより実践的で産業的な言語ベースのMLユースケースに活用することが容易になりました。本記事では、プロンプティングを使用した普及した言語ベースのMLタスクに対する生成型LLMの使用方法を示し、ゼロショットとフューショットのプロンプティングの利点と制限を厳密に分析することを目指します。 学習目標 ゼロショットとフューショットのプロンプティングについて学ぶ。 例として機械学習タスクのパフォーマンスを分析する。 フューショットのプロンプティングをファインチューニングなどのより高度な技術と比較評価する。 プロンプティング技術の利点と欠点を理解する。 この記事はData Science Blogathonの一部として公開されました。 プロンプティングとは? まず、LLMを定義しましょう。大規模言語モデル(LLM)とは、数億から数十億のパラメータを持つ、複数のトランスフォーマーとフィードフォワードニューラルネットワークの層で構築されたディープラーニングシステムです。これらはさまざまなソースの大規模なデータセットでトレーニングされ、テキストを理解し生成するために構築されています。言語翻訳、テキスト要約、質問応答、コンテンツ生成などが例です。LLMにはさまざまなタイプがあります:エンコーダのみ(BERT)、エンコーダ+デコーダ(BART、T5)、デコーダのみ(PALM、GPTなど)。デコーダコンポーネントを持つLLMは生成型LLMと呼ばれ、これがほとんどのモダンなLLMの場合です。 生成型LLMに特定のタスクを実行させるには、適切な指示を与えます。LLMは、プロンプトとも呼ばれる指示に基づいてエンドユーザーに応答するように設計されています。ChatGPTなどのLLMと対話したことがある場合、プロンプトを使用したことがあります。プロンプティングは、モデルが望ましい応答を返すための自然言語のクエリで私たちの意図をパッケージングすることです(例:図1、出典:Chat GPT)。 以下のセクションでは、ゼロショットとフューショットの2つの主要なプロンプティング技術を詳しく見ていきます。それぞれの詳細と基本的な例を見ていきましょう。 ゼロショットプロンプティング ゼロショットプロンプティングは、生成型LLMに特有のゼロショット学習の特定のシナリオです。ゼロショットでは、モデルにラベル付きのデータを提供せず、完全に新しい問題に取り組むことを期待します。例えば、適切な指示を提供することにより、新しいタスクに対してChatGPTをゼロショットプロンプティングに使用します。LLMは多くのリソースからコンテンツを理解しているため、未知の問題に適応することができます。いくつかの例を見てみましょう。 以下は、テキストをポジティブ、ニュートラル、ネガティブの感情クラスに分類するための例です。 ツイートの例 ツイートの例は、Twitter US…

大規模言語モデル(LLM)のファインチューニング入門ガイド
はじめに 人工知能の進化と自然言語処理(NLP)の驚異的な進歩をたどる旅に出ましょう。AIは一瞬で急速に進化し、私たちの世界を形作っています。大規模言語モデルの微調整の地殻変動的な影響は、NLPを完全に変革し、私たちの技術的な相互作用を革命化しました。2017年にさかのぼり、「Attention is all you need」という画期的な「Transformer」アーキテクチャが生まれたという節目の瞬間を思い起こしてみてください。このアーキテクチャは現在、NLPの基盤となるものであり、有名なChatGPTを含むすべての大規模言語モデルのレシピに欠かせない要素です。 GPT-3のようなモデルを使って、連続性のある文脈豊かなテキストを簡単に生成することを想像してみてください。チャットボット、翻訳、コンテンツ生成のためのパワーハウスとして、その輝きはアーキテクチャと事前学習と微調整の緻密なダンスによって生まれます。私たちの今回の記事では、これらの変革的な手法の魅力に迫り、大規模言語モデルをタスクに活用するための事前学習と微調整のダイナミックなデュエットを巧みに扱う芸術を明らかにします。一緒にこれらの変革的な手法を解き明かす旅に出ましょう! 学習目標 LLMアプリケーションを構築するさまざまな方法を理解する。 特徴抽出、レイヤーの微調整、アダプターメソッドなどの技術を学ぶ。 Huggingface transformersライブラリを使用して、下流タスクでLLMを微調整する。 LLMの始め方 LLMは大規模言語モデルの略です。LLMは、人間のようなテキストの意味を理解し、感情分析、言語モデリング(次の単語の予測)、テキスト生成、テキスト要約など、さまざまなタスクを実行するために設計されたディープラーニングモデルです。これらのモデルは膨大なテキストデータで訓練されます。 私たちは、これらのLLMをベースにしたアプリケーションを日常的に使っていますが、それに気づいていないことがあります。GoogleはBERT(Bidirectional Encoder Representations for Transformers)を使用して、クエリの補完、クエリの文脈の理解、より関連性の高く正確な検索結果の出力、言語翻訳など、さまざまなアプリケーションで使用しています。 これらのモデルは、深層学習の手法、複雑なニューラルネットワーク、セルフアテンションなどの高度な技術を基に構築されています。これらのモデルは、言語のパターン、構造、意味を学ぶために膨大なテキストデータで訓練されます。 これらのモデルは広範なデータセットで訓練されているため、それらを訓練するには多くの時間とリソースがかかり、ゼロから訓練することは合理的ではありません。特定のタスクにこれらのモデルを直接使用する方法があります。それでは、詳細について説明しましょう。 LLMアプリケーションを構築するさまざまな方法の概要 私たちは日常生活で興味深いLLMアプリケーションをよく見ます。LLMアプリケーションを構築する方法について知りたいですか?以下はLLMアプリケーションを構築するための3つの方法です: ゼロからLLMを訓練する…
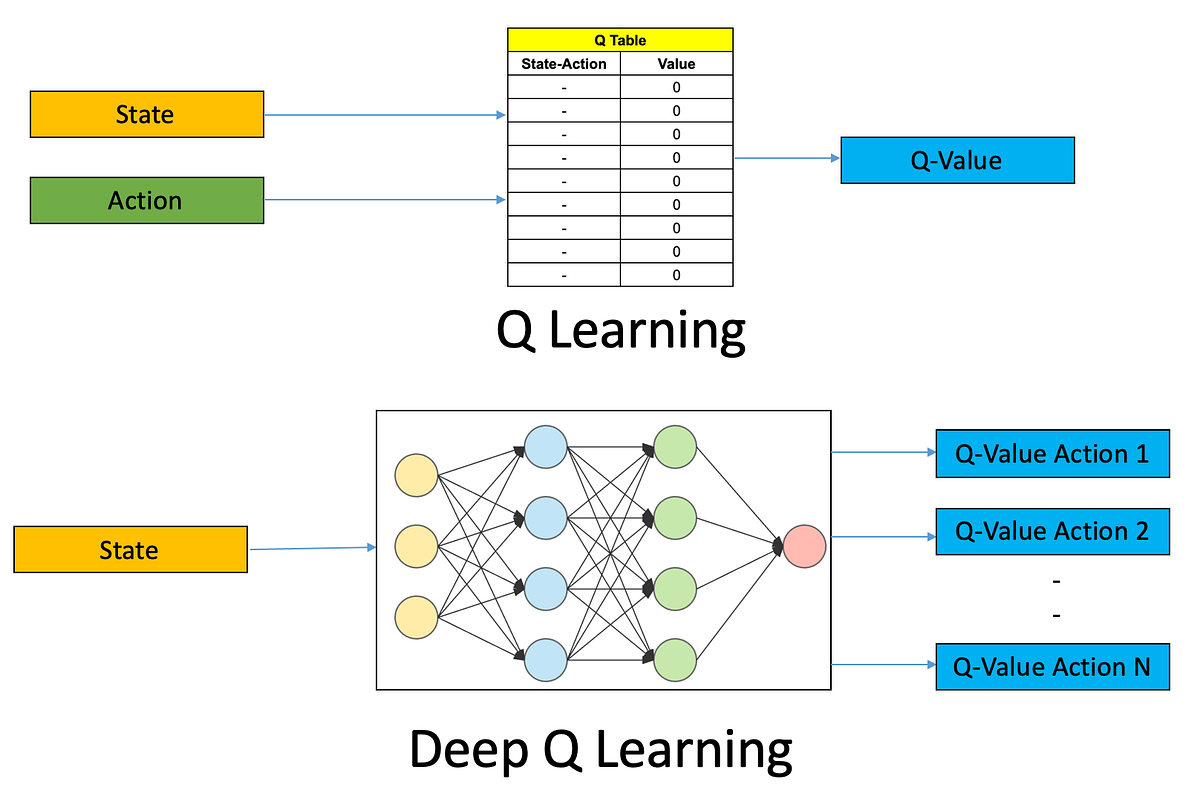
初めてのDeep Q学習ベースの強化学習エージェントをトレーニングする:ステップバイステップガイド
強化学習(RL)は、人工知能(AI)の魅力的な領域であり、機械が環境との相互作用を通じて学習し、意思決定を行うことができるようにしますRLエージェントを訓練する...

「2023年の最高のAIアバタージェネレーター10選」
ゲームの冒険に最適なバーチャルなキャラクターを選ぶというスリルを覚えていますか?今日では、バーチャルなアイデンティティはゲームを超えて私たちのオンラインの生活に溶け込んでいます。それらは単なる遊びではなく、ソーシャルメディアやデジタルプラットフォーム上で私たちを表すものです。AIアバタージェネレータは、個人のためにパーソナライズされたアバターを作成するために広く使用されています。この記事では、10の最高のAIアバタージェネレータについてご紹介します。 AIアバタージェネレータとは何ですか? ニューラルネットワークと人工知能アルゴリズムを使用して、AIアバタージェネレータは個々の人やチームのためにパーソナライズされたアバターを作成します。ユーザーは自分のセルフィー、肖像画、全身画像、またはテキストのプロンプトをアップロードしてパーソナライズされたアバターを生成する必要があります。これらは、倫理的な懸念に沿ってプライバシーを保ちながら機能します。 異なるAIアバタージェネレータは、革新的で創造的なアバターを生成するためのユニークな機能を提供しています。一部のAIアバタージェネレータは自動化されていますが、他のものはユーザーのニーズに応じてカスタマイズ可能です。ユニークなアバターを作成する目的は、AIアバタージェネレータを選ぶ際の決定基準の一つであるべきです。 トップ10のAIアバタージェネレータ 以下は、参考のための有料および無料のトップ10のAIアバタージェネレータのリストです: PicsArt Synthesia Aragon Fotor AIアバタージェネレータ Lensa AIマジックアバター Magic AIアバター Reface Dawn AI Starry AI Photoleap PicsArt PicsArtは他のソフトウェアアプリとは異なり、テキストやプロンプトを必要としません。ユーザーはアバターを生成するためにプリセットを選択し、好みに応じてカスタマイズする必要があります。アバターはギャラリーから画像を選択して生成することができます。PicsArtでは、AndroidやiPhoneであれば、10から30枚の写真で50から200のアバターを作成することができます。 無料版ではアバターの生成は利用できません。プレミアム機能を利用するためには、ソフトウェアの有料版にアクセスする必要があります。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.