Learn more about Search Results SVM - Page 9

- You may be interested
- 「金融機関は責任あるAIを活用して金融犯...
- 「機械学習モデルが医学的診断と治療にお...
- 「MLの学習に勇気を持つ:L1&L2正則化の...
- 「バリー・ディラー対生成AI:著作権法的...
- 「組織内で責任ある効果的なAI駆動文化を...
- エントロピーとジニ指数入門
- DLノート:勾配降下法
- 「ジェネレーティブAIの企業導入」
- オムニヴォアに出会おう:スタートアップ...
- Pandas 2.0 データサイエンティストにとっ...
- 専門家モデルを用いた機械学習:入門
- シナプスCoR:革命的なアレンジでのChatGPT
- 線形代数4:行列方程式
- このAI研究は、車両の後続振る舞いモデリ...
- 「ChatGPTのような大規模言語モデルによる...

「データサイエンスの仕事を得る方法?[8つの簡単なステップで解説]」
データサイエンス分野での有望なキャリアは競争が激化しています。多くの候補者が役職を得るために激しく競い合っている中、機会はしばしば適切なスキルと経験を持つ人々に与えられます。データサイエンスの仕事を得るための前提条件や答えは、以下の8つの詳細なステップにあります。 データサイエンスの仕事を得るための8つのステップ 以下の8つのステップに従って、希望するデータサイエンスの仕事を得ることができます。 ステップ1:目標とパスを明確にする データサイエンスのキャリア目標を明確にする キャリアの目標を明確に定義し、経験レベルと専門知識に基づいてデータサイエンスのキャリア目標を明確に定義します。短期目標として、インターンシップや初級職のデータアナリストになることを考えてください。中期目標には、専門家としての知識を持ち、研究論文を発表することが含まれます。長期目標には、トップのデータサイエンティストになること、企業との協力、企業の立ち上げ、大学や学術誌への貢献などが含まれる場合があります。 さまざまなデータサイエンスの役割を調査し、自分の興味とスキルに合ったものを選ぶ さまざまなデータサイエンスの役割を調査し、興味とスキルに合った役割を選択します。データアナリストになる、機械学習をマスターする、自然言語処理に特化する、ビッグデータプロジェクトに取り組む、またはディープラーニングを進めるなどの選択肢があります。 希望する役割に必要なスキルと知識を特定し、学習計画を作成する データサイエンスに入る方法について考えていますか?学習計画を作成しましょう。これには、認定コースへの参加、YouTubeでの無料講義の受講、書籍からの情報収集、他の専門家との協力などが含まれます。さらに、新卒者としてデータアナリストの仕事を得る方法やデータサイエンスの仕事を得る方法についての回答をするために、以下の表にはさまざまなデータサイエンスの役割に必要なスキルと知識が示されています。 役割 スキル 知識 データアナリスト データの操作と可視化、Excel、SQL、データの可視化ライブラリ データのクリーニング、前処理、クエリ、可視化 機械学習 アルゴリズム、ハイパーパラメータの調整、モデルの選択、評価指標、TensorFlow、scikit-learn、PyTorch 教師あり学習と教師なし学習、クラスタリング、回帰、分類、アンサンブル法、ディープラーニングのアーキテクチャ 自然言語処理 NLPライブラリ、フレームワーク、spaCy、NLTK、transformers、分類、エンティティ認識、感情分析、言語モデルの微調整 単語の埋め込み、再帰型ニューラルネットワーク(RNN)と畳み込みニューラルネットワーク(CNN)、テキストの前処理 ビッグデータ 大規模データ処理、分散環境でのストレージと処理…

確率的な関係の直感に反する性質
実数値変数xとyを考えます例えば、父親の身長とその息子の身長です統計学における回帰分析の中心的な問題は、xを知っている場合にyを推測することです例えば...

「マーケティングからデータサイエンスへのキャリアチェンジ方法」
イントロダクション データの指数関数的な成長とデータに基づく意思決定の必要性により、マーケティングとデータサイエンスの交差点はますます重要になっています。多くの専門家がデータサイエンスへのキャリア転換を考えています。この記事では、マーケティングからデータサイエンスへの成功した転換をガイドします。 スキルギャップの評価 マーケティングからデータサイエンスへのキャリア転換を考える際には、これら2つの分野のスキルギャップを評価することが重要です。自分のスキルが一致する領域と追加の知識が必要な領域を理解することは、データサイエンティストへの成功への道筋を描くのに役立ちます。 データサイエンティストの役割に必要な主要なスキルと知識 データサイエンティストには、データ分析、プログラミング、統計、機械学習の専門知識など、多様なスキルセットが必要です。以下に、必要なすべてのスキルのリストを示します: 技術的なスキル PythonやRなどのプログラミング言語またはデータ言語 線形回帰やロジスティック回帰、ランダムフォレスト、決定木、SVM、KNNなどの機械学習アルゴリズム SAP HANA、MySQL、Microsoft SQL Server、Oracle Databaseなどのリレーショナルデータベース 自然言語処理(NLP)、光学文字認識(OCR)、ニューラルネットワーク、コンピュータビジョン、ディープラーニングなどの特殊スキル RShiny、ggplot、Plotly、Matplotlitなどのデータ可視化能力 Hadoop、MapReduce、Sparkなどの分散コンピューティング 分析スキル IBM Watson、OAuth、Microsoft AzureなどのAPIツール 実験とA/Bテスト 回帰、分類、時系列分析などの予測モデリングと統計概念 ドメイン知識…

ソースコード付きのトップ14のデータマイニングプロジェクト
現代では、データマイニングと機械学習の驚異的な進歩により、組織はデータに基づく意思決定を行うための先進的な技術を備えています。私たちが生きるデジタル時代は、急速な技術の発展によって特徴付けられ、よりデータに基づいた社会の道を切り開いています。ビッグデータと産業革命4.0の登場により、組織は貴重な洞察を抽出し、イノベーションを推進するために利用できる膨大な量のデータにアクセスできるようになりました。本記事では、スキルを磨くことができるトップ10のデータマイニングプロジェクトについて探っていきます。 データマイニングとは? データマイニングは、ユーザーから収集されるデータや企業の業務に重要なデータから隠れたパターンを見つけるプラクティスです。これはいくつかのデータ整形手順に従います。ビジネスは、この膨大な量のデータを収集するクリエイティブな方法を探して、有用な企業データを提供するためのデータマイニングがイノベーションのための最も重要な手法の1つとして浮上しています。データマイニングプロジェクトは、現在の科学のこの領域で働きたい場合には理想的な出発点かもしれません。 トップ14のデータマイニングプロジェクト 以下は、初心者、中級者、上級者向けのトップ14のデータマイニングプロジェクトです。 住宅価格予測 ナイーブベイズを用いたスマートヘルス疾患予測 オンラインフェイクロゴ検出システム 色検出 製品と価格の比較ツール 手書き数字認識 アニメ推奨システム キノコ分類プロジェクト グローバルテロリズムデータの評価と分析 画像キャプション生成プロジェクト 映画推奨システム 乳がん検出 太陽光発電予測 国勢調査データに基づく成人の収入予測 初心者向けデータマイニングプロジェクト 1. 住宅価格予測 このデータマイニングプロジェクトは、住宅データセットを利用して物件価格を予測することに焦点を当てています。初心者や中級レベルのデータマイナーに適しており、サイズ、場所、設備などの要素を考慮して家の販売価格を正確に予測するモデルを開発することを目指しています。 決定木や線形回帰などの回帰技術を利用して結果を得ます。このプロジェクトでは、様々なデータマイニングアルゴリズムを利用して物件価値を予測し、最も高い精度評価を持つ予測を選択します。過去のデータを活用することで、このプロジェクトは不動産業界内での物件価格の予測に関する洞察を提供します。…

「サポートベクトルマシンの優しい入門」
「分類のためのサポートベクターマシンの理解ガイド:理論からscikit-learnの実装まで」
サポートベクターマシンへの優しい入門
「分類のためのサポートベクトルマシン理解ガイド 理論からscikit-learnの実装まで」

「人工知能 vs 人間の知能:トップ7の違い」
はじめに 人工知能は、架空のAIキャラクターJARVISから現実のChatGPTまで、長い道のりを経て進化してきました。しかしながら、人間の知性は学習、理解、革新的な解決策の発見を支援する特性であり、データを基に人間を模倣する人工知能とは異なります。AIが今日、非常に普及したことで、人工知能 vs 人間の知能という新たな議論が浮上し、これら2つの競合するパラダイムを比較するようになりました。 人工知能とは何ですか? 人工知能と呼ばれるデータサイエンスのサブフィールドは、人間の知性と認識を必要とするさまざまなタスクを実行できる知的なコンピュータを作成することに関連しています。これらの洗練されたマシンは、過去のエラーや歴史的データから学び、周囲の状況を分析し、必要な手段を決定することができます。 AIは、計算科学、認知科学、言語学、神経科学、心理学、数学など、多くの他の学問からのアイデアと手法を統合した分野です。 この機械は自己学習、自己分析、自己改善の能力を持ち、処理中には最小限またはほとんど人間の努力を必要とします。 これは、メディア業界、医療業界、グラフィックスやアニメーションなど、あらゆるビジネスで、技術が行動を人間に基づいて再現するのを支援するために利用されています。 人間の知能とは何ですか? 人間の知能は、理性的に考え、さまざまな表現を理解し、難しい概念を理解し、数学の問題を解決し、変化する状況に適応し、知識を使って環境を制御し、他者とコミュニケーションする能力を指します。 それは、特定のスキルセットや知識の体系に関する情報を提供するかもしれず、別の人間に関連するかもしれません。また、情報エージェントやロケーターの場合は、アクセスしなければならない外交情報を提供するかもしれません。さらに、それはソーシャルネットワークや個人的なつながりについての情報を提供するかもしれません。 人間の知能と行動は、個人の独特な遺伝子、幼少期の成長、さまざまな出来事や環境への経験に根ざしています。さらに、それは個人の新しく獲得した知識を使って自分の環境を変える能力に完全に依存しています。 人工知能 vs 人間の知能 以下に人間の知能と人工知能の詳細な違いを説明します: パラメータ 人間の知能 人工知能 起源 人間は理性的に考え、思考し、評価し、他の認知的なタスクを実行する能力を持って生まれます。 AIは人間の洞察によって生み出された革新であり、Norbert Wienerは批判のメカニズムについて理論を進めることでこの分野の発展に貢献しました。…

エンドツーエンドのMLパイプラインの構築方法
コミュニティ内のMLエンジニアから最もよく聞かれる不満の1つは、モデルの構築と展開のMLワークフローを手動で行うことがどれだけ費用がかかり、エラーが発生しやすいかということです彼らはトレーニングデータを前処理するためにスクリプトを手動で実行し、展開スクリプトを再実行し、モデルを手動で調整し、働く時間を費やします...
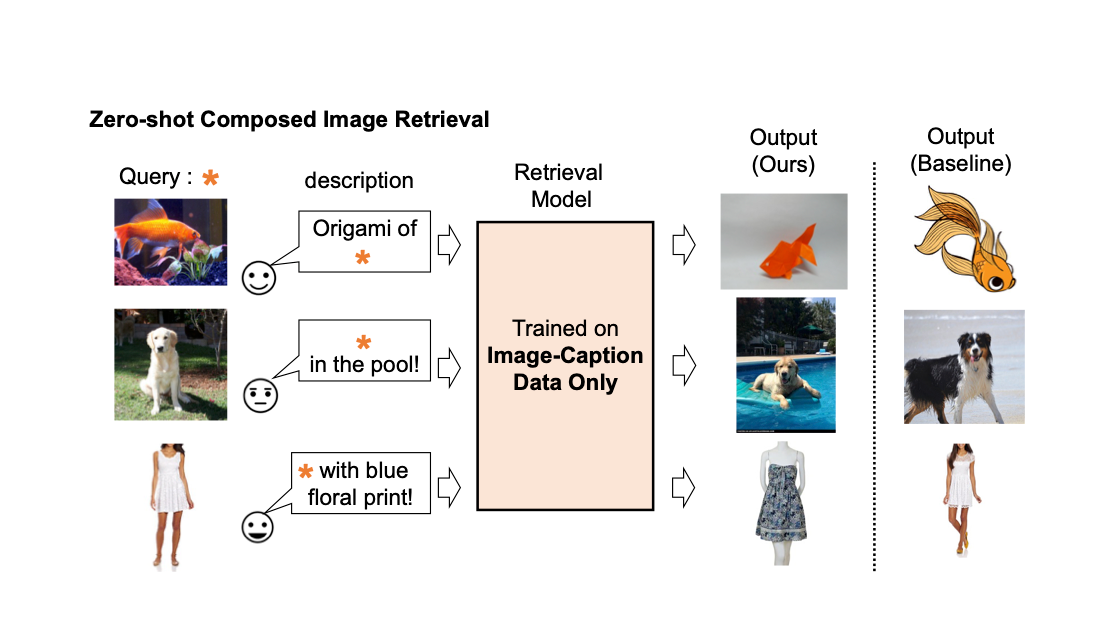
Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。 画像の検索エンジンでは、画像またはテキストをクエリとして使用して目的の画像を取得することが重要です。しかし、テキストに基づいた検索には限界があります。言葉で正確に目的の画像を説明することは難しいからです。たとえば、ファッションアイテムを検索する場合、ユーザーはウェブサイトで見つけたものとは異なる、ロゴの色やロゴ自体などの特定の属性を持つアイテムを求めるかもしれません。しかし、既存の検索エンジンでそのアイテムを検索することは容易ではありません。なぜなら、テキストでファッションアイテムを正確に説明することは難しいからです。この事実に対処するために、組み合わせ画像検索(CIR)は、画像とテキストの両方を組み合わせたクエリに基づいて画像を取得します。そのため、CIRは画像とテキストを組み合わせることで、目的の画像を正確に取得することができます。 しかし、CIRの方法には大量のラベル付きデータが必要です。つまり、1)クエリ画像、2)説明、および3)目標画像の3つ組を必要とします。このようなラベル付きデータを収集することはコストがかかり、このデータで訓練されたモデルはしばしば特定のユースケースに適応されており、異なるデータセットには一般化できる能力が制限されています。 これらの課題に対処するために、「Pic2Word:ゼロショット組み合わせ画像検索のための画像から単語へのマッピング」というタイトルの論文で、私たちはゼロショットCIR(ZS-CIR)というタスクを提案しています。ZS-CIRでは、ラベル付きの3つ組データを必要とせずに、オブジェクトの組み合わせ、属性の編集、またはドメインの変換など、さまざまなCIRのタスクを実行する単一のCIRモデルを構築することを目指しています。代わりに、大規模な画像キャプションのペアとラベルのない画像を使用して検索モデルを訓練することを提案しています。これらのデータは、大規模な教師ありCIRデータセットよりも容易に収集できます。再現性を促進し、この分野をさらに進展させるために、私たちはコードも公開しています。 既存の組み合わせ画像検索モデルの説明。 私たちは、画像キャプションのデータのみを使用して組み合わせ画像検索モデルを訓練します。私たちのモデルは、クエリ画像とテキストの組み合わせに合わせた画像を取得します。 手法の概要 私たちは、コントラスト言語-画像事前学習モデル(CLIP)の言語エンコーダの言語能力を活用することを提案しています。CLIPは、さまざまなテキストの概念と属性に対して意味のある言語埋め込みを生成することに優れています。そのため、CLIP内の軽量なマッピングサブモジュールを使用して、画像の埋め込み空間からテキスト入力空間の単語トークンにマッピングすることを目指します。全体のネットワークは、ビジョン-言語コントラスト損失を最適化して、画像とテキストの埋め込み空間が可能な限り近接するようにします。そして、クエリ画像を単語のように扱うことができます。これにより、言語エンコーダによるクエリ画像の特徴とテキストの説明の柔軟でシームレスな組み合わせが可能になります。私たちはこの手法をPic2Wordと呼び、その訓練プロセスの概要を以下の図で提供します。マップされたトークンsは、単語トークン形式で入力画像を表すようにしたいと考えています。その後、マッピングネットワークを訓練して、言語埋め込みp内で画像埋め込みを再構築します。具体的には、CLIPで提案されたコントラスト損失を最適化し、ビジュアル埋め込みvとテキスト埋め込みpの間のコントラスト損失を計算します。 未ラベルの画像のみを使用してマッピングネットワーク(fM)のトレーニングを行います。視覚とテキストのエンコーダーは固定されたまま、マッピングネットワークのみを最適化します。 トレーニングされたマッピングネットワークを考慮すると、以下の図に示すように、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成することができます。 トレーニングされたマッピングネットワークを使用して、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成します。 評価 さまざまな実験を行って、Pic2WordのCIRタスクでの性能を評価します。 ドメイン変換 まず、提案手法の合成能力をドメイン変換で評価します。画像と変換先の画像ドメイン(例:彫刻、折り紙、漫画、おもちゃ)を与えられた場合、システムの出力は同じ内容の画像を新しい望ましい画像ドメインまたはスタイルで出力する必要があります。以下の図で示されるように、画像とテキストのカテゴリ情報やドメイン説明を柔軟に組み合わせる能力を評価します。ImageNetとImageNet-Rを使用して、実際の画像から4つのドメインへの変換を評価します。 教師付きトレーニングデータを必要としないアプローチとの比較のために、次の3つのアプローチを選びます:(i)画像のみは視覚埋め込みのみで検索を実行します、(ii)テキストのみはテキスト埋め込みのみを使用します、(iii)画像+テキストは視覚とテキストの埋め込みを平均化してクエリを構成します。 (iii)との比較では、言語エンコーダーを使用して画像とテキストを組み合わせる重要性が示されます。また、Fashion-IQまたはCIRRでCIRモデルをトレーニングするCombinerとも比較します。 入力クエリ画像のドメインを、テキストで指定されたドメイン(例:折り紙)に変換することを目指します。 下の図に示されているように、提案された手法はベースラインを大きく上回る結果を示しています。 ドメイン変換のための合成画像検索における結果(リコール@10、つまり最初の10枚の画像で関連するインスタンスの割合)。…

データサイエンスは良いキャリアですか?
イントロダクション データサイエンスはその持続的な重要性と影響力により、キャリアパスを考える個人たちの間で非常に興味深く魅力的な話題となっています。データの生成、分析、利用が指数関数的に増加する時代において、データサイエンスは良いキャリアなのかという疑問が生じます。データサイエンスの多様な側面、職業成長への潜在能力、さまざまな産業での関連性を探求することで、データサイエンスが魅力的で良いキャリア選択肢であるという価値と見通しを理解することができます。 この記事では、データサイエンティストが良い仕事なのか、データサイエンスが将来の良いキャリアなのかについての疑問に答えます。これらの疑問への回答は、データサイエンスが持つ見通しと機会について包括的な理解を提供します。さあ、始めましょう! データサイエンスとは何ですか? データサイエンスは、さまざまな科学的手法、アルゴリズム、手順を利用して膨大なデータから知識を抽出することに焦点を当てています。それは生データの中にある曖昧なパターンを見つけるのに役立ちます。データサイエンスはビジネスの問題を研究プロジェクトに変え、それを実際の解決策に変えることができます。多くの人々は、データサイエンスのキャリアを求める理由として、多くの役割と魅力的な給与があるためです。 また読む: 2023年にデータサイエンティストになるためのステップバイステップガイド なぜデータサイエンスを選ぶのですか? データサイエンスの分野は広範で多様です。この分野には、テクノロジーの分野でキャリアを求めている専門家に多くのものを提供しています。それは成長の機会が多い魅力的なキャリアオプションです。データサイエンスをキャリアに考えるべき理由のいくつかは次のとおりです: 需要がある データサイエンスは非常に求められています。見込みのある従業員の機会は数多くあります。LinkedInでは、この職種の成長率が最も高く、2026年までに1150万の仕事が追加されると予想されています。そのため、データサイエンスの分野は需要があります。 多くの職種があります データサイエンティストになるためには必要なスキルセットを持っている人はごく一部です。そのため、データサイエンスは他のIT産業よりも発展が遅れています。その結果、データサイエンスの領域は非常に多様で、多くの選択肢があります。データサイエンティストは需要が高いですが、さらに需要があります。 報酬の良いキャリア データサイエンスの分野は最高の給与をもたらします。Glassdoorによると、データサイエンティストの平均年収は11万6100ドルです。そのため、データサイエンスの仕事は非常に報酬が良いです。 データサイエンスは柔軟な分野です データサイエンスには幅広い応用があります。銀行、医療、コンサルティング、電子商取引などで頻繁に使用されます。データサイエンスの分野は非常に多様です。そのため、さまざまな領域で働くことができます。 データサイエンスのトレンドと産業事実 データサイエンスは著しい成長を遂げ、多くの産業に不可欠な存在となっています。データサイエンスのトレンドと産業事実には、キャリア選択肢としてのデータサイエンスの重要性と潜在能力を示すものがいくつかあります。データサイエンスの分野は魅力的な報酬パッケージを提供しています。Glassdoorによると、アメリカのデータサイエンティストの平均給与は年間約11万3000ドルです。この高い収益性は、データサイエンスのスキルと専門知識の求人市場での価値を示しています。 さらに、データサイエンスはさまざまな産業に応用されています。医療や金融からマーケティングや電子商取引まで、さまざまなセクターの組織はデータサイエンティストに頼って意味のある洞察を抽出し、戦略的な意思決定を推進しています。例えば、医療業界では、データサイエンスは患者データの分析や個別化された治療計画の開発に使用されます。同様に、マーケティングでは、データサイエンスが消費者のトレンドを特定し、特定のターゲットオーディエンスを対象にし、広告キャンペーンを最適化するのに役立ちます。 これらのトレンドと産業事実は、データサイエンスが発展し求められているキャリアパスであり、さまざまなセクターでの成長と影響の大きな機会があることを示しています。 データサイエンスのキャリアの未来 仕事の機会に関して、データサイエンスには数多くのものがあります。経済学者によれば、2026年までに全国で1100万以上の求人があると予測されています。実際、2019年以来、データサイエンスの採用は46%増加しています。それにもかかわらず、2020年8月末までにインドでは約9万3000件のデータサイエンスの求人がありました。そのため、データサイエンスの潜在能力は否定できません。 データサイエンティストの役割に加えて、この分野には多くの仕事の選択肢があります。以下はその一部です:…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.