Learn more about Search Results ResNet - Page 9

- You may be interested
- GenAIにとっての重要なデータファブリック...
- ハギングフェイスフェローシッププログラ...
- 「GoogleのDeblur AI:画像を鮮明にする」
- 『データサイエンスをマスターするための5...
- 『見て学ぶ小さなロボット:このAIアプロ...
- PyTorch FSDPを使用してLlama 2 70Bのファ...
- 「SwimXYZとの出会い:水泳モーションとビ...
- 「生物コンピューター」の独自の約束
- 「ChatGPT時代の会話支援の未来はどうなる...
- 今日、開発者の70%がAIを受け入れています...
- あなたの究極のチャットGPTおよびその他の...
- AIシステムは、構造設計のターゲットを満...
- 予測保守を理解する-データの取得と信号の...
- 「ロボットのセンシングと移動のためのア...
- 「2023年に注目すべきトップ7のデジタルマ...

CVモデルの構築と展開:コンピュータビジョンエンジニアからの教訓
コンピュータビジョン(CV)モデルの設計、構築、展開の経験を3年以上積んできましたが、私は人々がこのような複雑なシステムの構築と展開において重要な側面に十分な注力をしていないことに気づきましたこのブログ投稿では、私自身の経験と、最先端のCVモデルの設計、構築、展開において得た貴重な知見を共有します...

スケールを通じた高精度の差分プライバシー画像分類の解除
前の研究の経験的な証拠によると、DP-SGDにおける効用の低下は、より大規模なニューラルネットワークモデルでより深刻になる傾向がありますこれには、難しい画像分類のベンチマークで最高のパフォーマンスを達成するために定期的に使用されるモデルも含まれます私たちの研究では、この現象を調査し、トレーニング手順とモデルアーキテクチャの両方に一連の単純な修正を提案して、標準的な画像分類ベンチマークでのDPトレーニングの正確性を大幅に向上させることを示しています
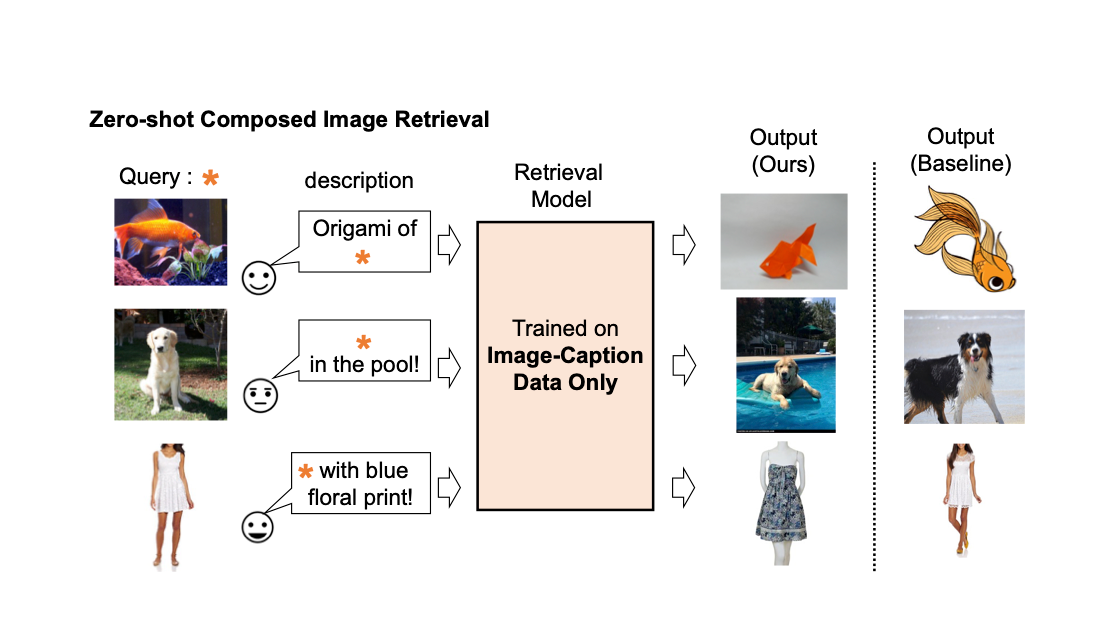
Pic2Word:ゼロショット構成画像検索のための写真から単語へのマッピング
Google Researchの学生研究者であるKuniaki SaitoとGoogle Researchの研究科学者であるKihyuk Sohnが投稿しました。 画像の検索エンジンでは、画像またはテキストをクエリとして使用して目的の画像を取得することが重要です。しかし、テキストに基づいた検索には限界があります。言葉で正確に目的の画像を説明することは難しいからです。たとえば、ファッションアイテムを検索する場合、ユーザーはウェブサイトで見つけたものとは異なる、ロゴの色やロゴ自体などの特定の属性を持つアイテムを求めるかもしれません。しかし、既存の検索エンジンでそのアイテムを検索することは容易ではありません。なぜなら、テキストでファッションアイテムを正確に説明することは難しいからです。この事実に対処するために、組み合わせ画像検索(CIR)は、画像とテキストの両方を組み合わせたクエリに基づいて画像を取得します。そのため、CIRは画像とテキストを組み合わせることで、目的の画像を正確に取得することができます。 しかし、CIRの方法には大量のラベル付きデータが必要です。つまり、1)クエリ画像、2)説明、および3)目標画像の3つ組を必要とします。このようなラベル付きデータを収集することはコストがかかり、このデータで訓練されたモデルはしばしば特定のユースケースに適応されており、異なるデータセットには一般化できる能力が制限されています。 これらの課題に対処するために、「Pic2Word:ゼロショット組み合わせ画像検索のための画像から単語へのマッピング」というタイトルの論文で、私たちはゼロショットCIR(ZS-CIR)というタスクを提案しています。ZS-CIRでは、ラベル付きの3つ組データを必要とせずに、オブジェクトの組み合わせ、属性の編集、またはドメインの変換など、さまざまなCIRのタスクを実行する単一のCIRモデルを構築することを目指しています。代わりに、大規模な画像キャプションのペアとラベルのない画像を使用して検索モデルを訓練することを提案しています。これらのデータは、大規模な教師ありCIRデータセットよりも容易に収集できます。再現性を促進し、この分野をさらに進展させるために、私たちはコードも公開しています。 既存の組み合わせ画像検索モデルの説明。 私たちは、画像キャプションのデータのみを使用して組み合わせ画像検索モデルを訓練します。私たちのモデルは、クエリ画像とテキストの組み合わせに合わせた画像を取得します。 手法の概要 私たちは、コントラスト言語-画像事前学習モデル(CLIP)の言語エンコーダの言語能力を活用することを提案しています。CLIPは、さまざまなテキストの概念と属性に対して意味のある言語埋め込みを生成することに優れています。そのため、CLIP内の軽量なマッピングサブモジュールを使用して、画像の埋め込み空間からテキスト入力空間の単語トークンにマッピングすることを目指します。全体のネットワークは、ビジョン-言語コントラスト損失を最適化して、画像とテキストの埋め込み空間が可能な限り近接するようにします。そして、クエリ画像を単語のように扱うことができます。これにより、言語エンコーダによるクエリ画像の特徴とテキストの説明の柔軟でシームレスな組み合わせが可能になります。私たちはこの手法をPic2Wordと呼び、その訓練プロセスの概要を以下の図で提供します。マップされたトークンsは、単語トークン形式で入力画像を表すようにしたいと考えています。その後、マッピングネットワークを訓練して、言語埋め込みp内で画像埋め込みを再構築します。具体的には、CLIPで提案されたコントラスト損失を最適化し、ビジュアル埋め込みvとテキスト埋め込みpの間のコントラスト損失を計算します。 未ラベルの画像のみを使用してマッピングネットワーク(fM)のトレーニングを行います。視覚とテキストのエンコーダーは固定されたまま、マッピングネットワークのみを最適化します。 トレーニングされたマッピングネットワークを考慮すると、以下の図に示すように、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成することができます。 トレーニングされたマッピングネットワークを使用して、画像を単語トークンと見なし、テキストの説明とペアにすることで、共通の画像-テキストクエリを柔軟に構成します。 評価 さまざまな実験を行って、Pic2WordのCIRタスクでの性能を評価します。 ドメイン変換 まず、提案手法の合成能力をドメイン変換で評価します。画像と変換先の画像ドメイン(例:彫刻、折り紙、漫画、おもちゃ)を与えられた場合、システムの出力は同じ内容の画像を新しい望ましい画像ドメインまたはスタイルで出力する必要があります。以下の図で示されるように、画像とテキストのカテゴリ情報やドメイン説明を柔軟に組み合わせる能力を評価します。ImageNetとImageNet-Rを使用して、実際の画像から4つのドメインへの変換を評価します。 教師付きトレーニングデータを必要としないアプローチとの比較のために、次の3つのアプローチを選びます:(i)画像のみは視覚埋め込みのみで検索を実行します、(ii)テキストのみはテキスト埋め込みのみを使用します、(iii)画像+テキストは視覚とテキストの埋め込みを平均化してクエリを構成します。 (iii)との比較では、言語エンコーダーを使用して画像とテキストを組み合わせる重要性が示されます。また、Fashion-IQまたはCIRRでCIRモデルをトレーニングするCombinerとも比較します。 入力クエリ画像のドメインを、テキストで指定されたドメイン(例:折り紙)に変換することを目指します。 下の図に示されているように、提案された手法はベースラインを大きく上回る結果を示しています。 ドメイン変換のための合成画像検索における結果(リコール@10、つまり最初の10枚の画像で関連するインスタンスの割合)。…

AWS上で動作する深層学習ベースの先進運転支援システムのための自動ラベリングモジュール
コンピュータビジョン(CV)では、興味のあるオブジェクトを識別するためのタグを追加したり、オブジェクトの位置を特定するためのバウンディングボックスを追加したりすることをラベリングと呼びますこれは、深層学習モデルを訓練するためのトレーニングデータを準備するための事前のタスクの1つです数十万時間以上の作業時間が、様々なCVのために画像やビデオから高品質なラベルを生成するために費やされています

AIの汎化ギャップに対処:ロンドン大学の研究者たちは、Spawriousという画像分類ベンチマークスイートを提案しましたこのスイートには、クラスと背景の間に偽の相関が含まれます
人工知能の人気が高まるにつれ、新しいモデルがほぼ毎日リリースされています。これらのモデルには新しい機能や問題解決能力があります。近年、研究者たちは、AIモデルの抵抗力を強化し、スパリアスフィーチャーへの依存度を減らすアプローチを考えることに重点を置いています。自動運転車や自律型キッチンロボットの例を考えると、彼らは彼らが訓練データから学習したものと大きく異なるシナリオで動作する際に生じる課題のためにまだ広く展開されていません。 多くの研究がスパリアス相関の問題を調査し、モデルのパフォーマンスに対するその負の影響を軽減する方法を提案しています。ImageNetなどのよく知られたデータセットで訓練された分類器は、クラスラベルと相関があるが、それらを予測するわけではない背景データに依存していることが示されています。SCの問題に対処する方法の開発に進展はあったものの、既存のベンチマークの制限に対処する必要があります。現在のWaterbirdsやCelebA hair color benchmarksなどのベンチマークには制限があり、そのうちの1つは、現実では多対多(M2M)のスパリアス相関がより一般的であり、クラスと背景のグループを含む単純な1対1(O2O)スパリアス相関に焦点を当てていることです。 最近、ロンドン大学カレッジの研究チームが、クラスと背景の間にスパリアス相関が含まれる画像分類ベンチマークスイートであるSpawriousデータセットを導入しました。それは1対1(O2O)および多対多(M2M)のスパリアス相関の両方を含み、3つの難易度レベル(Easy、VoAGI、Hard)に分類されています。データセットは、テキストから画像を生成するモデルを使用して生成された約152,000の高品質の写真リアルな画像で構成されており、画像キャプションモデルを使用して不適切な画像をフィルタリングし、データセットの品質と関連性を確保しています。 Spawriousデータセットの評価により、現在の最先端のグループ頑健性アプローチに対してHard-splitsなどの課題が課せられ、ImageNetで事前学習されたResNet50モデルを使用してもテストされた方法のいずれも70%以上の正確性を達成できなかったことが示されました。チームは、分類器が間違った分類を行った際に背景に依存していることを見て、モデルのパフォーマンスの短所が引き起こされたと説明しています。これは、スパリアスデータの弱点を成功裏にテストし、分類器の弱点を明らかにすることができたことを示しています。 O2OとM2Mベンチマークの違いを説明するために、チームは、夏に訓練データを収集する例を使用しました。それは、2つの異なる場所から2つの動物種のグループで構成され、各動物グループが特定の背景グループに関連付けられているものです。しかし、季節が変わり、動物が移動すると、グループは場所を交換し、動物グループと背景の間のスパリアス相関が1対1で一致することはできなくなります。これは、M2Mスパリアス相関の複雑な関係と相互依存関係を捉える必要性を強調しています。 Spawriousは、OOD、ドメイン汎化アルゴリズムにおける有望なベンチマークスイートであり、スパリアスフィーチャーの存在下でモデルの評価と改善を行うためにも使用できます。

あなたのポケットにアーティストの相棒:SnapFusionは、拡散モデルのパワーをモバイルデバイスにもたらすAIアプローチです
拡散モデル。AI領域の進歩に注目している場合、この用語については多く聞いたことがあるでしょう。それらは生成型AI手法の革命を可能にした鍵でした。我々は今や、テキストプロンプトを使用して数秒で写真のような逼真的な画像を生成するモデルを持っています。それらは、コンテンツ生成、画像編集、スーパーレゾリューション、ビデオ合成、3Dアセット生成を革新しました。 しかし、この印象的なパフォーマンスには高いコンピューテーション要件が伴います。つまり、それらを完全に活用するには本当に高性能のGPUが必要です。はい、それらをローカルコンピュータで実行する試みもありますが、それでも高性能なものが必要です。一方、クラウドプロバイダを使用することも代替解決策となりますが、その場合はプライバシーを危険にさらす可能性があります。 そして、考えなければならないのは、移動中に使用することです。ほとんどの人々は、コンピュータよりもスマートフォンで時間を過ごしています。拡散モデルをモバイルデバイスで使用したい場合、デバイス自体の限られたハードウェアパワーにとって要求が高すぎるため、うまくいく可能性はほぼありません。 拡散モデルは次の大きな流行ですが、実用的なアプリケーションに適用する前にその複雑さに対処する必要があります。モバイルデバイスでの推論の高速化に焦点を当てた複数の試みが行われていますが、シームレスなユーザーエクスペリエンスや定量的な生成品質を達成していませんでした。それは今までの話であり、新しいプレイヤーがフィールドに登場しているのです。SnapFusionと名付けられたこのプレイヤーです。 SnapFusionは、モバイルデバイスで2秒以下で画像を生成する最初のテキストから画像への拡散モデルです。UNetアーキテクチャを最適化し、ノイズ除去ステップ数を減らすことで推論速度を向上させています。さらに、進化するトレーニングフレームワークを使用し、データ蒸留パイプラインを導入し、ステップ蒸留中に学習目標を強化しています。 SnapFusionの概要。出典:https://arxiv.org/pdf/2306.00980.pdf SnapFusionの構造に変更を加える前に、SD-v1.5のアーキテクチャの冗長性を調査して、効率的なニューラルネットワークを得ることが最初に行われました。しかし、SDに従来のプルーニングやアーキテクチャサーチ技術を適用することは、高いトレーニングコストのために困難でした。アーキテクチャの変更は性能の低下につながる可能性があり、大規模な計算リソースを必要とする厳密な微調整が必要となります。そのため、その道は閉ざされ、彼らは、事前にトレーニングされたUNetモデルのパフォーマンスを維持しながら効果を徐々に向上させる代替方法を開発する必要がありました。 推論速度を向上させるために、SnapFusionは、条件付き拡散モデルのボトルネックであるUNetアーキテクチャを最適化することに焦点を当てています。既存の作品は主にトレーニング後の最適化に焦点を当てていますが、SnapFusionはアーキテクチャの冗長性を特定し、元のStable Diffusionモデルを上回る進化するトレーニングフレームワークを提案することで、推論速度を大幅に向上させています。また、イメージデコーダーを圧縮して高速化するためのデータ蒸留パイプラインを導入しています。 SnapFusionには、各クロスアテンションとResNetブロックを一定の確率で実行する確率的フォワード伝播が適用される堅牢なトレーニングフェーズが含まれています。この堅牢なトレーニング拡張機能により、ネットワークがアーキテクチャの変化に対して耐性があることが保証され、各ブロックの正確な評価と安定したアーキテクチャの進化が可能になります。 効率的なイメージデコーダーは、チャネル削減によって得られたデコーダーを使用して合成データを使用して蒸留パイプラインを介して達成されます。この圧縮デコーダは、SD-v1.5のものよりもはるかに少ないパラメータを持ち、より速くなっています。蒸留プロセスには、テキストプロンプトを使用してSD-v1.5のUNetから潜在表現を取得することで、効率的なデコーダーから1つ、SD-v1.5から1つの画像を生成することが含まれます。 提案されたステップ蒸留アプローチには、バニラ蒸留損失目的が含まれており、これは、生徒のUNetの予測と教師のUNetのノイズのある潜在表現との不一致を最小化することを目的としています。さらに、CFG-aware蒸留損失目的が導入され、CLIPスコアを改善します。CFGガイドされた予測は、教師モデルと生徒モデルの両方で使用され、CFGスケールはトレーニング中にFIDスコアとCLIPスコアのトレードオフを提供するためにランダムにサンプリングされます。 SnapFusionによって生成されたサンプル画像。出典: https://arxiv.org/pdf/2306.00980.pdf 改善されたステップ蒸留とネットワークアーキテクチャの開発のおかげで、SnapFusionは、モバイルデバイス上のテキストプロンプトから512×512の画像を2秒未満で生成することができます。生成された画像は、最先端のStable Diffusionモデルと同様の品質を示しています。

マルチヘッドアテンションを使用した注意機構の理解
はじめに Transformerモデルについて詳しく学ぶ良い方法は、アテンションメカニズムについて学ぶことです。特に他のタイプのアテンションメカニズムを学ぶ前に、マルチヘッドアテンションについて学ぶことは良い選択です。なぜなら、この概念は少し理解しやすい傾向があるためです。 アテンションメカニズムは、通常の深層学習モデルに追加できるニューラルネットワークレイヤーと見なすことができます。これにより、重要な部分に割り当てられた重みを使用して、入力の特定の部分に焦点を当てるモデルを作成することができます。ここでは、マルチヘッドアテンションメカニズムを使用して、アテンションメカニズムについて詳しく見ていきます。 学習目標 アテンションメカニズムの概念 マルチヘッドアテンションについて Transformerのマルチヘッドアテンションのアーキテクチャ 他のタイプのアテンションメカニズムの概要 この記事は、データサイエンスブログマラソンの一環として公開されました。 アテンションメカニズムの理解 まず、この概念を人間の心理学から見てみましょう。心理学では、注意は他の刺激の影響を除外して、イベントに意識を集中することです。つまり、他の注意を引くものがある場合でも、私たちは選択したものに焦点を合わせます。注意は全体の一部に集中します。 これがTransformerで使用される概念です。彼らは入力のターゲット部分に焦点を当て、残りの部分を無視することができます。これにより、非常に効果的な方法で動作することができます。 マルチヘッドアテンションとは? マルチヘッドアテンションは、Transformerにおいて中心的なメカニズムであり、ResNet50アーキテクチャにおけるskip-joiningに相当します。場合によっては、アテンドするべきシーケンスの複数の他の点があります。全体の平均を見つける方法では、重みを分散させて多様な値を重みとして与えることができません。これにより、複数のアテンションメカニズムを個別に作成するアイデアが生まれ、複数のアテンションメカニズムが生じます。実装では、1つの機能に複数の異なるクエリキー値トリプレットが表示されます。 出典:Pngwing.com 計算は、アテンションモジュールが何度も反復し、アテンションヘッドとして知られる並列レイヤーに組織化される方法で実行されます。各別のヘッドは、入力シーケンスと関連する出力シーケンスの要素を独立して処理します。各ヘッドからの累積スコアは、すべての入力シーケンスの詳細を組み合わせた最終的なアテンションスコアを得るために組み合わされます。 数式表現 具体的には、キーマトリックスとバリューマトリックスがある場合、値をℎサブクエリ、サブキー、サブバリューに変換し、アテンションを独立して通過させることができます。連結すると、ヘッドが得られ、最終的な重み行列でそれらを組み合わせます。 学習可能なパラメータは、アテンションに割り当てられた値であり、各パラメータはマルチヘッドアテンションレイヤーと呼ばれます。以下の図はこのプロセスを示しています。 これらの変数を簡単に見てみましょう。Xの値は、単語埋め込みの行列の連結です。 行列の説明 クエリ:シーケンスのターゲットについての洞察を提供する特徴ベクトルです。クエリは、何がアテンションを必要としているかをシーケンスに要求します。 キー:要素に含まれるものを説明する特徴ベクトルです。クエリによってアテンションが与えられ、要素のアイデンティティを提供します。 値:…
METAのHiera:複雑さを減らして精度を高める
畳み込みニューラルネットワークは、20年以上にわたってコンピュータビジョンの分野を支配してきましたトランスフォーマーの登場により、それらは放棄されると考えられていましたしかし、多くの実践者は…
PyTorchを使った転移学習の実践ガイド
この記事では、転移学習と呼ばれる技術を使用して、カスタム分類タスクに事前学習済みモデルを適応する方法を学びますPyTorchを使用した画像分類タスクで、Vgg16、ResNet50、およびResNet152の3つの事前学習済みモデルで転移学習を比較します

SRGANs:低解像度と高解像度画像のギャップを埋める
イントロダクション あなたが古い家族の写真アルバムをほこりっぽい屋根裏部屋で見つけるシナリオを想像してください。あなたはすぐにほこりを取り、最も興奮してページをめくるでしょう。そして、多くの年月前の写真を見つけました。しかし、それでも、あなたは幸せではないです。なぜなら、写真が薄く、ぼやけているからです。写真の顔や細部を見つけるために目をこらします。これは昔のシナリオです。現代の新しいテクノロジーのおかげで、私たちはスーパーレゾリューション・ジェネレーティブ・アドバーサリ・ネットワーク(SRGAN)を使用して、低解像度の画像を高解像度の画像に変換することができます。この記事では、私たちはSRGANについて最も学び、QRコードの強化のために実装します。 出典: Vecteezy 学習目標 この記事では、以下のことを学びます: スーパーレゾリューションと通常のズームとの違いについて スーパーレゾリューションのアプローチとそのタイプについて SRGAN、その損失関数、アーキテクチャ、およびそのアプリケーションについて深く掘り下げる SRGANを使用したQRエンハンスメントの実装とその詳細な説明 この記事は、データサイエンスブログマラソンの一環として公開されました。 スーパーレゾリューションとは何ですか? 多くの犯罪捜査映画では、証拠を求めて探偵がCCTV映像をチェックする典型的なシナリオがよくあります。そして、ぼやけた小さな画像を見つけて、ズームして強化してはっきりした画像を得るシーンがあります。それは可能ですか?はい、スーパーレゾリューションの助けを借りて、それはできます。スーパーレゾリューション技術は、CCTVカメラによってキャプチャされたぼやけた画像を強化し、より詳細な視覚効果を提供することができます。 ………………………………………………………………………………………………………………………………………………………….. ………………………………………………………………………………………………………………………………………………………….. 画像の拡大と強化のプロセスをスーパーレゾリューションと呼びます。それは、対応する低解像度の入力から画像またはビデオの高解像度バージョンを生成することを目的としています。それによって、欠落している詳細を回復し、鮮明さを向上させ、視覚的品質を向上させることができます。強化せずに画像をズームインするだけでは、以下の画像のようにぼやけた画像が得られます。強化はスーパーレゾリューションによって実現されます。写真、監視システム、医療画像、衛星画像など、さまざまな領域で多くの応用があります。 ……….. スーパーレゾリューションの従来のアプローチ 従来のアプローチでは、欠落しているピクセル値を推定し、画像の解像度を向上させることに重点を置いています。2つのアプローチがあります。補間ベースの方法と正則化ベースの方法です。 補間ベースの方法 スーパーレゾリューションの初期の日々には、補間ベースの方法に重点が置かれ、欠落しているピクセル値を推定し、その後画像を拡大します。隣接するピクセル値が類似しているという仮定を使用して、これらの値を使用して欠落している値を推定します。最も一般的に使用される補間方法には、バイキュービック、バイリニア、および最近傍補間があります。しかし、その結果は満足できないものでした。これにより、ぼやけた画像が生じました。これらの方法は、基本的な解像度タスクや計算リソースに制限がある状況に適しているため、効率的に計算できます。 正則化ベースの手法 一方で、正則化ベースの手法は、画像再構成プロセスに追加の制約や先行条件を導入することで、超解像度の結果を改善することを目的としています。これらの技術は、画像の統計的特徴を利用して、再構築された画像の精度を向上させながら、細部を保存します。これにより、再構築プロセスにより多くの制御が可能になり、画像の鮮明度と細部が向上します。しかし、複雑な画像コンテンツを扱う場合には、過度の平滑化を引き起こすため、いくつかの制限があります。 これらの従来のアプローチにはいくつかの制限があるにもかかわらず、超解像度の強力な手法の出現への道を示しました。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.