Learn more about Search Results RLHF - Page 9

- You may be interested
- エネルギー省が新興技術を加速させます
- 「RustコードのSIMD高速化のための9つのル...
- 「Cheetorと会ってください:幅広い種類の...
- query()メソッドを使用してPandasデータフ...
- In Japanese, the translation of Time Se...
- AIの時代のコーディング:ChatGPTの役割と...
- AutoNLPとProdigyを使用したアクティブラ...
- 「RAGを忘れて、未来はRAG-Fusionです」
- データ汚染とモデル崩壊:迫りくるAIの災害
- ChatGPTによるデータサイエンス面接チート...
- 「LLMsを使用した用語の翻訳(GPTとVertex...
- 「13/11から19/11までの週の最も重要なコ...
- 「初心者のためのイメージ分類」
- このAI論文では、ディープラーニングモデ...
- アップリフトモデリング—クレジットカード...

「Seerの最高データオフィサーであるDr. Serafim Batzoglouによるインタビューシリーズ」
セラフィム・バツォグルはSeerのチーフデータオフィサーですSeerに加わる前は、セラフィムはInsitroのチーフデータオフィサーとして、薬物発見の手法における機械学習とデータサイエンスを率いましたInsitroの前には、Illuminaの応用および計算生物学の副社長として、AIおよび分子に関する研究と技術開発を率いました
「ジェネレーティブAIをマスターしたいなら、すべてを無視して(ただ2つだけを除いて)ツールに集中せよ」という文です
私たちは、生成型AIの疲労感がひどい状態です

「Google Researchが探求:AIのフィードバックは、大規模な言語モデルの効果的な強化学習において人間の入力を置き換えることができるのか?」
人間のフィードバックは、機械学習モデルを改善し最適化するために不可欠です。近年、人間のフィードバックからの強化学習(RLHF)は、大規模な言語モデル(LLM)を人間の好みに合わせるのに非常に効果的であることが証明されていますが、高品質の人間の好みのラベルを収集するという重要な課題があります。Google AIの研究者たちは、研究の中でRLHFとAIフィードバックからの強化学習(RLAIF)を比較しようと試みました。 RLAIFは、人間のアノテーターに頼らずに事前に訓練されたLLMによって優先順位が付けられる技術です。 この研究では、研究者たちは要約タスクの文脈でRLAIFとRLHFを直接比較しました。彼らは、テキストが与えられた場合に2つの候補応答の優先順位ラベルを提供することを課されました。これには、市販の大規模言語モデル(LLM)を利用して推測された優先順位に基づいて報酬モデル(RM)をトレーニングし、対照的な損失を組み込むことが含まれています。最後のステップでは、強化学習の技術を用いてポリシーモデルを微調整することが求められました。上記の画像は、RLAIF(上)とRLHF(下)を示すダイアグラムを示しています。 上記の画像は、Redditの投稿に対してSFT、RLHF、RLAIFのポリシーによって生成された例の要約を示しています。SFTはキーポイントを捉えることができず、RLHFとRLAIFはより高品質の要約を生成しました。 この研究で示された結果は、次の2つの異なる方法で評価された場合に、RLAIFがRLHFと同等のパフォーマンスを達成していることを示しています: まず、RLAIFとRLHFのポリシーはそれぞれの場合において、監視された微調整(SFT)ベースラインよりも人間の評価者から好意を受け取ったことが71%と73%のケースで観察されました。重要なことに、統計分析によって2つのアプローチ間の勝率に有意差は見られませんでした。 次に、RLAIFとRLHFによって生成された結果を直接比較するように人間に求めた場合、両方に対して同等の好みが表明され、それぞれの方法について50%の勝率となりました。これらの結果から、RLAIFは人間の注釈に依存せず、魅力的なスケーラビリティ特性を持つRLHFの代替手段であることが示唆されます。 この研究では要約タスクのみを探求しており、他のタスクへの一般化についてのオープンな問題が残されています。さらに、この研究では、費用対効果の観点から人間のラベリングと比較して大規模言語モデル(LLM)の推論がどれほど費用対効果があるかの推定は含まれていません。研究者は将来的にこの領域を探求することを望んでいます。

「Amazon SageMaker JumpStartでのテキスト生成のために、Llama 2を微調整する」
「本日は、Amazon SageMaker JumpStartを使用して、MetaによってLlama 2モデルを微調整する機能を発表できることを喜んでお知らせしますLlama 2ファミリーの大規模言語モデル(LLM)は、事前学習および微調整された生成テキストモデルのコレクションで、7億から700億のパラメータのスケールで提供されていますLlama-2-chatと呼ばれる微調整されたLLMは、対話の使用事例に最適化されています」
このAIニュースレターは、あなたが必要なすべてです#63
「AIの今週のハイライトでは、Large Language Models(LLM)の採用による西洋市場での収益成長のさらなる証拠と、新しいAIモデルの導入を紹介しています...」

「Llama 2:ChatGPTに挑むオープンソースの深層ダイブ」
「プログラミングや創造的な文章作成などの特定の領域で有望な複雑な推論タスクをこなす大規模言語モデル(LLM)が存在しますしかし、LLMの世界はただプラグアンドプレイの楽園ではありません使いやすさ、安全性、計算要件において課題があります本記事では、Llama 2の能力について詳しく掘り下げながら、[…]を提供します」
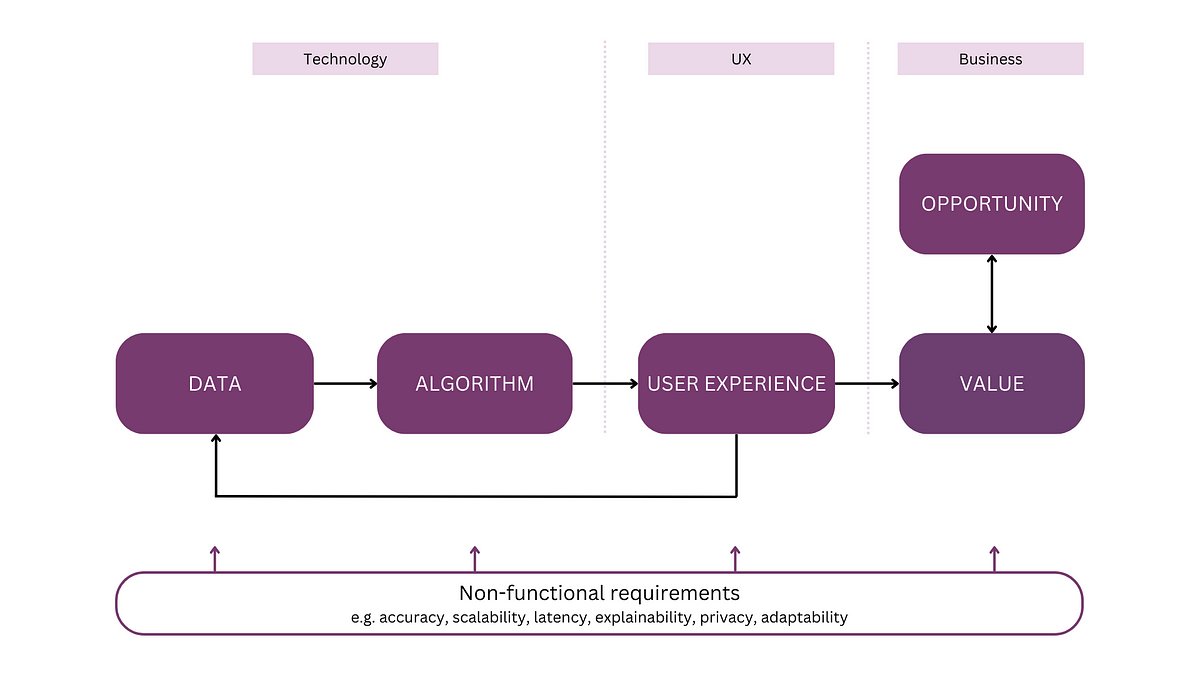
「全体的なメンタルモデルを持つAI製品の開発」
注:この記事は「AIアプリケーションの解析」というシリーズの最初の記事ですこのシリーズでは、AIシステムのためのメンタルモデルを紹介しますこのモデルは、議論や計画、そして...のためのツールとして機能します
このAIニュースレターは、あなたが必要とするすべてです#62
今週は、METAのコーディングモデルの開発とOpenAIの新しいファインチューニング機能の進展を見てきましたMetaは、Code LLaMAという大規模な言語モデルを導入しましたこのモデルは…

推論:可観測性のAI主導の未来?
この記事では、オペラビリティの後続としての推論、AIOpsからの教訓、その成功の不足、および推論ソリューションの新興原則について探求します

生成AIにおけるプロンプトエンジニアリングの基本原則
導入 この記事では、生成型AIにおけるChatGPTプロンプトエンジニアリングについて説明します。ChatGPTは2022年11月以来、技術者や非技術者の間で最も話題となっているトピックの一つです。これは知的な会話の一形態であり、知的な会話の時代の幕開けを示しています。科学、芸術、商業、スポーツなど、ほぼ何でも尋ねることができ、それらの質問に答えを得ることができます。 この記事はデータサイエンスブログマラソンの一環として公開されました。 ChatGPT Chat Generative Pre-trained Transformer、通常はChatGPTとして知られているものは、ユーザープロンプトに基づいて新しいテキストを生成する役割を示すChat Generative Pre-trained Transformerの頭字語です。この会話フレームワークは、オリジナルのコンテンツを作成するために広範なデータセットでのトレーニングを行います。Sam AltmanのOpenAIは、ChatGPTによって示されるように、最も重要な言語モデルの一つを開発したとされています。この素晴らしいツールは、テキスト生成、翻訳、要約のタスクを容易に実行することができます。これはGPTの3番目のバージョンです。ChatGPTの使い方はほとんどの人が知っているため、インターフェースや操作方法などについては議論しません。しかし、LLMについては議論します。 プロンプトエンジニアリングとは何ですか? 生成型AIにおけるプロンプトエンジニアリングは、AI言語モデルの能力を活用する高度なツールです。これにより、モデルに明確で具体的な指示が与えられ、言語モデルのパフォーマンスが最適化されます。指示を与える例は以下の通りです。 モデルに明示的な指示を与えることは、回答を正確にするために有益です。例 – 99 * 555は何ですか?「回答が正確であることを確認してください」という指示は、「99 * 555は何ですか?」よりも良いです。 大規模言語モデル(LLM) LLMは、自己教師あり学習技術を用いて、大量のデータに対してニューラルネットワークの技術を適用して、人間らしいテキストを生成するAIベースのアルゴリズムです。OpenAIのChat GPTやGoogleのBERTなどがLLMの例です。LLMには2つのタイプがあります。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.