Learn more about Search Results Gin - Page 9

- You may be interested
- 「Juliaプログラミング言語の探求:MongoDB」
- 言語の壁を打破:多言語オーディオの文字...
- Earth.comとProvectusがAmazon SageMaker...
- K最近傍法の例の応用
- グループ化および空間計量データの混合効...
- 「AIレポート2023年」を解説する
- 「ミストラル・トリスメギストス7Bにお会...
- 「機械学習、ブロックチェーン技術はフェ...
- アドバンテージアクタークリティック(A2C)
- ハイパーパラメータ最適化のためのトップ...
- 「ディープフェイクの解明:ヘッドポーズ...
- このAI研究は、ロボット学習および具現化...
- 「データと人工知能を利用して、国連の持...
- 「LeanTaaSの創設者兼CEO、モハン・ギリダ...
- 「このテクニックでより良い棒グラフを作...

Hugging FaceのTensorFlowの哲学
はじめに PyTorchやJAXからの競争が増えても、TensorFlowは最も使用されるディープラーニングフレームワークのままです。また、それらの他の2つのライブラリとはいくつか非常に重要な点で異なります。特に、高レベルのAPIであるKerasと、データの読み込みライブラリであるtf.dataとの統合が非常に密接です。 PyTorchのエンジニアの中には(ここでオープンプランオフィスを暗く見つめながら私を想像してください)、これを克服すべき問題だと見なす傾向があります。彼らの目標は、TensorFlowが彼らのやり方に従って低レベルのトレーニングとデータの読み込みコードを使用できるようにする方法を見つけることです。これはTensorFlowに取り組む間違った方法です! Kerasは素晴らしい高レベルのAPIです。プロジェクトが数モジュールよりも大きい場合、それを押しのけると、必要になると気付いたときに、その機能のほとんどを自分で再現することになります。 洗練された、尊敬され、非常に魅力的なTensorFlowエンジニアとして、私たちは最先端のモデルの驚異的なパワーと柔軟性を使用したいと思っていますが、私たちが使い慣れたツールとAPIでそれらを扱いたいのです。このブログポストでは、Hugging Faceでそれを実現するために行う選択と、TensorFlowプログラマーとしてフレームワークから期待できることについて説明します。 インタールード:30秒で🤗 経験豊富なユーザーは、このセクションをざっと読んだりスキップしたりして構いませんが、Hugging Faceとtransformersに初めて出会う方には、ライブラリのコアアイデアについて概要を説明する必要があります。モデルを事前学習済みモデルとして名前でリクエストするだけで、1行のコードで取得できます。最も簡単な方法は、TFAutoModelクラスを使用するだけです。 from transformers import TFAutoModel model = TFAutoModel.from_pretrained("bert-base-cased") この1行でモデルのアーキテクチャがインスタンス化され、重みが読み込まれます。これにより、元の有名なBERTモデルの正確なレプリカが得られます。ただし、このモデル自体ではあまり役に立ちません – 出力ヘッドや損失関数がありません。実際には、これは最後の隠れ層の直後で終了するニューラルネットワークの「ステム」です。では、どのようにして出力ヘッドを追加するのでしょうか?簡単です、異なるAutoModelクラスを使用するだけです。ここでは、Vision Transformer(ViT)モデルを読み込み、画像分類ヘッドを追加しています。 from transformers import TFAutoModelForImageClassification…

ディープダイブ:Hugging Face Optimum GraphcoreにおけるビジョンTransformer
このブログ投稿では、Hugging Face Optimumライブラリを使用して、事前学習済みのTransformerモデルをあなたのデータセットに簡単に微調整する方法をGraphcoreのIntelligence Processing Units(IPUs)で紹介します。例として、大規模で広く使用されている胸部X線データセットを取り上げ、ビジョンTransformer(ViT)モデルを訓練する手順とノートブックを提供します。 ビジョンTransformer(ViT)モデルの紹介 2017年、GoogleのAI研究者グループがTransformerモデルアーキテクチャを紹介する論文を発表しました。Transformerは新しいセルフアテンションメカニズムによって特徴付けられ、言語アプリケーションのための新しい効率的なモデルのグループとして提案されました。実際、過去5年間でTransformerは爆発的な人気を見ており、自然言語処理(NLP)の事実上の標準として受け入れられています。 言語のためのTransformerは、急速に進化するGPTとBERTモデルファミリーによって特に代表されています。両方とも、Hugging Face Optimum Graphcoreライブラリの一部としてGraphcore IPUs上で簡単かつ効率的に実行することができます。 Transformerモデルアーキテクチャの詳細な説明(NLPに焦点を当てたもの)は、Hugging Faceのウェブサイトで見つけることができます。 Transformerは言語で初期の成功を収めましたが、非常に多目的であり、このブログ投稿でカバーするように、コンピュータビジョン(CV)などのさまざまな目的に使用することができます。 CVは、畳み込みニューラルネットワーク(CNN)が間違いなく最も人気のあるアーキテクチャの1つです。しかし、ビジョンTransformer(ViT)アーキテクチャは、Google Researchが2021年の論文で初めて紹介された画像認識のブレークスルーであり、BERTやGPTと同じセルフアテンションメカニズムを主要なコンポーネントとして使用しています。 BERTや他のTransformerベースの言語処理モデルは、文(つまり単語のリスト)を入力として受け取りますが、ViTモデルは入力画像をいくつかの小さなパッチに分割し、言語処理における個々の単語に相当するものにします。各パッチは、Transformerモデルによって線形にエンコードされ、個別に処理できるベクトル表現に変換されます。この画像をパッチやビジュアルトークンに分割するアプローチは、CNNが使用するピクセル配列とは対照的です。 事前学習により、ViTモデルは画像の内部表現を学習し、それを下流タスクに役立つ視覚的な特徴を抽出するために使用できます。たとえば、事前学習されたビジュアルエンコーダの上に線形層を配置することで、新しいラベル付き画像データセットで分類器を訓練することができます。通常、[CLS]トークンの上に線形層を配置します。このトークンの最後の隠れ状態は、画像全体の表現と見なすことができます。 CNNと比較して、ViTモデルはより高い認識精度を持ちながら、より低い計算コストで動作し、画像分類、物体検出、セグメンテーションなどのさまざまなアプリケーションに適用されています。医療領域のユースケースには、COVID-19、大腿骨骨折、肺気腫、乳がん、アルツハイマー病などの検出と分類などが含まれます。 ViTモデル – IPUに最適なモデル GraphcoreのIPUは、データパイプライニングとモデル並列処理の組み合わせを使用して、ViTモデルに特に適しています。この大規模並列プロセスの高速化は、IPUのMIMDアーキテクチャとIPU-Fabricを中心としたスケールアウトソリューションによって可能になっています。…

Hugging Face TransformersとHabana Gaudiを使用して、BERTを事前に学習する
このチュートリアルでは、Habana GaudiベースのDL1インスタンスを使用してBERT-baseをゼロから事前トレーニングする方法を学びます。Gaudiのコストパフォーマンスの利点を活用するためにAWSで使用します。Hugging Face Transformers、Optimum Habana、およびDatasetsライブラリを使用して、マスクされた言語モデリングを使用してBERT-baseモデルを事前トレーニングします。これは、最初のBERT事前トレーニングタスクの一つです。始める前に、ディープラーニング環境をセットアップする必要があります。 コードを表示する 以下のことを学びます: データセットの準備 トークナイザのトレーニング データセットの前処理 Habana Gaudi上でBERTを事前トレーニングする 注意:ステップ1から3は、CPUを多く使用するタスクのため、異なるインスタンスサイズで実行することができます/すべきです。 要件 始める前に、以下の要件を満たしていることを確認してください DL1インスタンスタイプのクオータを持つAWSアカウント AWS CLIがインストールされていること AWS IAMユーザーがCLIで構成され、ec2インスタンスの作成と管理の権限を持っていること 役立つリソース Hugging Face TransformersとHabana…

Hugging Face Spacesでタンパク質を可視化する
この投稿では、Hugging Face Spacesでタンパク質を可視化する方法について見ていきます。 動機 🤗 タンパク質は、医薬品から洗剤まで私たちの生活に大きな影響を与えています。タンパク質の機械学習は、新しい興味深いタンパク質の設計を支援するための急速に成長している分野です。タンパク質は、主にアミノ酸と呼ばれる一連の構成要素を3D空間に配列して、タンパク質の機能を与える複雑な3Dオブジェクトです。機械学習の目的で、タンパク質は、例えば座標、グラフ、またはタンパク質言語モデルで使用するための1次元の文字列として表現することができます。 タンパク質の有名な機械学習モデルの一つにAlphaFold2があります。AlphaFold2は、類似のタンパク質の多重配列と構造モジュールを使用してタンパク質配列の構造を予測します。 AlphaFold2が登場して以来、OmegaFold、OpenFoldなど、さまざまなモデルが登場しました(詳細はこのリストやこのリストを参照)。 見ることは信じること タンパク質の構造は、タンパク質の機能を理解する上で重要な要素です。現在、mol*や3dmol.jsなどのブラウザで直接タンパク質を可視化するためのツールがいくつか利用可能です。この投稿では、3Dmol.jsとHTMLブロックを使用して、Hugging Face Spaceに構造可視化を統合する方法を学びます。 必要条件 すでにgradio Pythonパッケージがインストールされていること、およびJavascript / JQueryの基本的な知識を持っていることを確認してください。 コードの概要 3Dmol.jsのセットアップ方法に入る前に、インターフェースの最小機能デモを作成する方法を見てみましょう。 以下のコードは、4桁のPDBコードまたはPDBファイルを受け入れる簡単なデモアプリを作成します。アプリは、RCSB Protein Databankからpdbファイルを取得して表示するか、アップロードされたファイルを使用して表示します。 import gradio…

Hugging Faceの機械学習デモ(arXiv上)
私たちは、Hugging FaceがarXivと協力して論文をよりアクセスしやすく、見つけやすく、楽しくすることを発表できることを非常に嬉しく思っています!今日から、Hugging Face SpacesはarXivLabsとの統合を通じて、コミュニティまたは著者自身によって作成されたデモへのリンクを含むDemoタブとして提供されます。お気に入りの論文のデモタブに移動することで、オープンソースのデモへのリンクを見つけ、すぐに試すことができます🔥 Hugging Face Spacesは2021年10月のローンチ以来、コミュニティによって作成された12,000以上のオープンソースの機械学習デモを構築し共有するために使用されています。Spacesを使用すると、Hugging Faceユーザーはブラウザを使用してコードを実行することなく、モデルを共有、探索、議論し、対話型アプリケーションを構築することができます。これらのデモは、GradioやStreamlitなどのオープンソースのツールを使用し、Hugging Face Hubで利用可能なモデルとデータセットを活用して構築されています。 最新のarXivの統合により、ユーザーは論文のarXivの要約ページで最も人気のあるデモを見つけることができます。たとえば、BERT言語モデルのデモを試したい場合は、BERT論文のarXivページに移動し、デモタブに移動します。そこには、オープンソースコミュニティによって作成された200以上のデモが表示されます。一部のデモは単にBERTモデルを紹介しているだけであり、他のデモはBERTをより大きなパイプラインの一部として変更または使用する関連アプリケーションを紹介しています。上記のデモのようなものです。 デモにより、機械学習だけでなく、生物学、化学、天文学、経済学など、計算モデルが構築される他の分野を広範な視聴者が探索できるようになります。デモはモデルの動作原理の認識と理解を高め、研究者の仕事の可視性を高め、より多様な視聴者がバイアスやその他の問題を特定およびデバッグできるようにします。これらのデモにより、コードを一行も書くことなく、他の人が論文の結果を探索することができるため、研究の再現性が向上します!arXivとのこの統合に興奮しており、研究コミュニティがコミュニケーション、発信、解釈性を向上させるためにどのように活用するかを楽しみにしています。
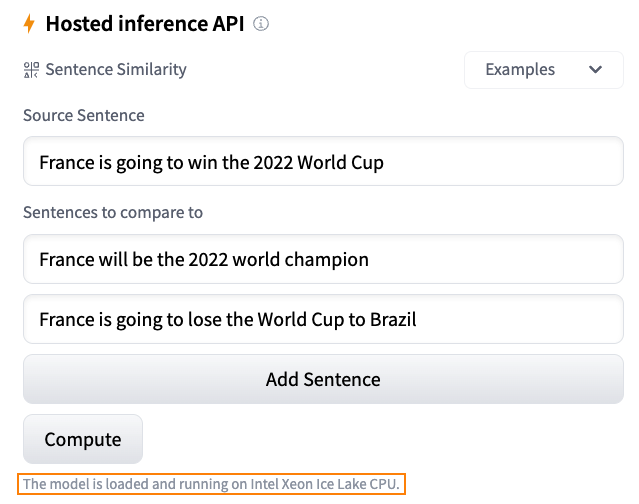
Hugging Faceにおける推論ソリューションの概要
毎日、開発者や組織はHugging Faceでホストされたモデルを採用し、アイデアを概念実証デモに、デモを本格的なアプリケーションに変えています。例えば、Transformerモデルは、自然言語処理、コンピュータビジョン、音声など、さまざまな機械学習(ML)アプリケーションの人気のあるアーキテクチャとなりました。最近では、ディフューザーがテキストから画像または画像から画像を生成するための人気のあるアーキテクチャとなりました。他のアーキテクチャも他のタスクで人気があり、私たちはそれらをすべてHF Hubでホストしています! Hugging Faceでは、最新のモデルを最小限の摩擦でテストおよび展開できる能力は、MLプロジェクトのライフサイクル全体で重要です。コストとパフォーマンスの比率を最適化することも同様に重要であり、無料のCPUベースの推論ソリューションを提供していただいたインテルの友人に感謝申し上げます。これは私たちのパートナーシップにおけるさらなる大きな一歩です。また、Intel Xeon Ice Lakeアーキテクチャによる高速化を無料でお楽しみいただけるため、ユーザーコミュニティの皆様にとっても素晴らしいニュースです。 さあ、Hugging Faceでの推論オプションを見てみましょう。 無料推論ウィジェット Hugging Faceハブでの私のお気に入りの機能の1つは、推論ウィジェットです。モデルページにある推論ウィジェットを使用すると、サンプルデータをアップロードして1クリックで予測することができます。 以下は、sentence-transformers/all-MiniLM-L6-v2モデルを使用した文の類似性の例です: モデルの動作、出力、およびデータセットのいくつかのサンプルでのパフォーマンスを素早く把握する最良の方法です。モデルはサーバー上でオンデマンドでロードされ、必要なくなるとアンロードされます。コードを書く必要はありませんし、この機能は無料です。どこが好きではないですか? 無料推論API 推論APIは、推論ウィジェットの内部で動作しています。単純なHTTPリクエストで、ハブの任意のモデルをロードし、数秒でデータを予測することができます。モデルのURLと有効なハブトークンが必要です。 以下は、xlm-roberta-baseモデルを1行でロードして予測する方法です: curl https://api-inference.huggingface.co/models/xlm-roberta-base \ -X POST \…

GPT2からStable Diffusionへ:Hugging FaceがElixirコミュニティに参入します
エリクサーのコミュニティは、GPT2からStable Diffusionまでのいくつかのニューラルネットワークモデルがエリクサーに到着したことをお知らせいたします。これは、Hugging Face Transformersを純粋なエリクサーで実装したBumblebeeライブラリによって可能になりました。 これらのモデルで始めるために、エリクサーの計算ノートブックプラットフォームであるLivebookのチームが、「スマートセル」と呼ばれるコレクションを作成しました。これにより、開発者はわずか3回のクリックで異なるニューラルネットワークタスクのスキャフォールドを作成できます。詳細については、私のビデオアナウンスをご覧ください。 エリクサーが実行されるErlang仮想マシンの並行性と分散サポートのおかげで、開発者はこれらのモデルを既存のPhoenixウェブアプリケーションの一部として埋め込み、提供することができます。また、Broadwayを使用してデータ処理パイプラインに統合し、Nerves組み込みシステムと一緒にデプロイすることもできます。いずれのシナリオでも、BumblebeeモデルはCPUとGPUの両方にコンパイルされます。 背景 エリクサーに機械学習を導入する取り組みは、ほぼ2年前にNumerical Elixir(Nx)プロジェクトで始まりました。Nxプロジェクトは、マルチ次元テンソルと「数値定義」を実装しています。これは、CPU/GPUにコンパイルできるElixirのサブセットです。Nxは、Google XLA(EXLA)とLibtorch(Torchx)のバインディングを使用して、車輪の再発明を防いでいます。 Nxイニシアチブからは、他のいくつかのプロジェクトが生まれました。Axonは、FlaxやPyTorch Igniteなどのプロジェクトからインスピレーションを受け、エリクサーに機能的で組み合わせ可能なニューラルネットワークをもたらします。Explorerプロジェクトは、dplyrとRustのPolarsから借用して、エリクサーコミュニティに表現力豊かで高性能なデータフレームを提供します。 BumblebeeとTokenizersは、私たちが最近リリースしたものです。私たちは、Hugging Faceがコミュニティとツール間での協力的な機械学習を可能にすることに感謝しています。これは、エリクサーエコシステムを迅速に進化させる上で重要な役割を果たしました。 次に、エリクサーでのニューラルネットワークのトレーニングと転移学習に焦点を当てる予定です。これにより、開発者は事業やアプリケーションのニーズに合わせて事前学習済みモデルを拡張および特化することができます。また、伝統的な機械学習アルゴリズムの開発についても、さらに発表する予定です。 あなたの番です Bumblebeeを試してみたい場合は、次のことができます: Livebook v0.8をダウンロードし、ノートブック内の「+ Smart」セルメニューから「ニューラルネットワークタスク」を自動生成します。現在、Livebookを追加のプラットフォームとスペースで実行できるようにする作業を進めています(お楽しみに!😉)。 Bumblebeeモデルの例として、単一ファイルのPhoenixアプリケーションも作成しました。これは、Phoenix(+ LiveView)アプリケーションの一部として統合するための必要な基盤を提供します。 より実践的なアプローチに興味がある場合は、いくつかのノートブックを読んでみてください。 エリクサーの機械学習エコシステムの構築を支援したい場合は、上記のプロジェクトをチェックして試してみてください。コンパイラ開発からモデル構築まで、多くの興味深い領域があります。たとえば、Bumblebeeにさらにモデルやアーキテクチャを追加するプルリクエストは、歓迎されるでしょう。未来は並行、分散、そして楽しいです!

Hugging Faceデータセットとトランスフォーマーを使用した画像の類似性
この投稿では、🤗 Transformersを使用して画像の類似性システムを構築する方法を学びます。クエリ画像と候補画像の類似性を見つけることは、逆画像検索などの情報検索システムの重要なユースケースです。システムが答えようとしているのは、クエリ画像と候補画像セットが与えられた場合、どの画像がクエリ画像に最も類似しているかということです。 このシステムの構築には、このシステムの構築時に便利な並列処理をシームレスにサポートする🤗のdatasetsライブラリを活用します。 この投稿では、ViTベースのモデル( nateraw/vit-base-beans )と特定のデータセット(Beans)を使用していますが、ビジョンモダリティをサポートし、他の画像データセットを使用するために拡張することもできます。試してみることができるいくつかの注目すべきモデルには次のものがあります: Swin Transformer ConvNeXT RegNet また、投稿で紹介されているアプローチは、他のモダリティにも拡張できる可能性があります。 完全に動作する画像の類似性システムを学習するには、最初に2つの画像間の類似性をどのように定義するかを定義する必要があります。 このシステムを構築するためには、まず与えられた画像の密な表現(埋め込み)を計算し、その後、余弦類似性指標を使用して2つの画像の類似性を決定する一般的な方法があります。 この投稿では、画像をベクトル空間で表現するために「埋め込み」を使用します。これにより、画像の高次元ピクセル空間(たとえば224 x 224 x 3)を意味のある低次元空間(たとえば768)にうまく圧縮する方法が得られます。これによる主な利点は、後続のステップでの計算時間の削減です。 画像から埋め込みを計算するために、入力画像をベクトル空間で表現する方法について理解しているビジョンモデルを使用します。このタイプのモデルは画像エンコーダとも呼ばれます。 モデルをロードするために、AutoModelクラスを活用します。これにより、Hugging Face Hubから互換性のあるモデルチェックポイントをロードするためのインターフェースが提供されます。モデルと共に、データ前処理に関連するプロセッサもロードします。 from transformers…

Hugging Face Hubへようこそ、PaddlePaddleさん
私たちは、オープンソースのコラボレーションをHugging FaceとPaddlePaddleの間で共有し、オープンソースを通じてAIの進歩と民主化を推進する共通の使命を喜んで共有します! 2016年にBaiduによって最初にオープンソース化されたPaddlePaddleは、スキルレベルに関係なく、開発者がディープラーニングをスケールで採用および実装できるようにします。2022年第4四半期現在、PaddlePaddleは500万人以上の開発者と20万社以上の企業によって使用されており、中国のディープラーニングプラットフォームの中で市場シェア第1位です。PaddlePaddleには、Paddle Deep Learning Framework、さまざまなモダリティのモデルライブラリ(例:PaddleOCR、PaddleDetection、PaddleNLP、PaddleSpeech)、モデル圧縮のためのPaddleSlim、モデル展開のためのFastDeployなど、人気のあるオープンソースのリポジトリがあります。 PaddleNLPが先導する中、PaddlePaddleはHugging Face Hubとそのライブラリを徐々に統合していく予定です。近々、テキスト、画像、音声、ビデオ、マルチモダリティの豪華な事前学習済みPaddlePaddleモデルのフルスイートをHubでお楽しみいただけるようになります! PaddlePaddleモデルの検索 PaddlePaddleモデルは、PaddlePaddleライブラリタグでフィルタリングすることで、モデルハブで見つけることができます。 既にハブには75以上のPaddlePaddleモデルがあります。例えば、マルチタスク情報抽出モデルシリーズUIE、最先端の中国語言語モデルERNIE 3.0モデルシリーズ、全ワークフローにおけるレイアウト知識強化のための革新的なドキュメントプレトレーニングモデルErnie-Layoutなどがあります。 HuggingFace HubのPaddlePaddle orgもぜひご覧ください。上記のモデルに加えて、テキストからイメージへの変換Ernie-ViLG、クロスモーダル情報抽出エンジンUIE-X、素晴らしいマルチリンガルOCRツールキットPaddleOCRなど、さまざまなスペースを探索することもできます。 推論APIとウィジェット PaddlePaddleモデルは、HTTPを介してcURL、Pythonのrequestsライブラリ、またはネットワークリクエストを行うためのご希望の方法でアクセスできる推論APIを通じて利用できます。 タスクをサポートするモデルには、ブラウザで直接モデルを操作できるインタラクティブなウィジェットが備わっています。 既存のモデルの使用 特定のモデルを読み込む方法を確認したい場合は、Use in paddlenlp(または将来の他のPaddlePaddleライブラリ)をクリックすると、それを読み込むための動作するスニペットが表示されます! モデルの共有…

Optimum+ONNX Runtime – Hugging Faceモデルのより簡単で高速なトレーニング
はじめに 言語、ビジョン、音声におけるトランスフォーマーベースのモデルは、複雑なマルチモーダルのユースケースをサポートするためにますます大きくなっています。モデルのサイズが増えるにつれて、これらのモデルをトレーニングし、サイズが増えるにつれてスケーリングするために必要なリソースにも直接的な影響があります。Hugging FaceとMicrosoftのONNX Runtimeチームは、大規模な言語、音声、ビジョンモデルのファインチューニングにおいて進歩をもたらすために協力しています。Hugging FaceのOptimumライブラリは、ONNX Runtimeとの統合により、多くの人気のあるHugging Faceモデルのトレーニング時間を35%以上短縮するオープンなソリューションを提供します。本稿では、Hugging Face OptimumとONNX Runtimeトレーニングエコシステムの詳細を紹介し、Optimumライブラリの利点を示すパフォーマンスの数値を提示します。 パフォーマンスの結果 以下のチャートは、Optimumを使用したHugging Faceモデルのパフォーマンスを示しており、トレーニングにONNX RuntimeとDeepSpeed ZeRO Stage 1を使用することで、39%から130%までの印象的な高速化が実現されています。パフォーマンスの測定は、ベースライン実行としてPyTorchを使用した選択されたHugging Faceモデルで行われ、2番目の実行ではトレーニングのためにONNX Runtimeのみを使用し、最終的な実行ではONNX Runtime + DeepSpeed ZeRO Stage…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.