Learn more about Search Results データサイエンスブログマラソン - Page 9

- You may be interested
- 「タコ」の複雑な細胞は彼らの高い知能の...
- ハリソン.aiのCEOであるエンガス・トラン...
- マシンラーニングのCRISP ML(Q)とは何です...
- 「Pymcと統計モデルを記述するための言語...
- 「Google AIの新しいパラダイムは、多段階...
- 「Ego-Exo4Dを紹介:ビデオ学習とマルチモ...
- 「GPT-4は数学の問題を解くことができます...
- リフレックスを使って、純粋なPythonでCha...
- 偽のレビューがオンラインで横行していま...
- 「Appleの研究者たちは、暗黙的なフィード...
- 「ToolLLMをご紹介します:大規模言語モデ...
- 「Spring Bootを使用して独自のChatGPTア...
- 「二つの封筒の問題」
- 大ニュース:Google、ジェミニAIモデルの...
- アラゴンAIレビュー:2023年における究極...

ONNXモデル | オープンニューラルネットワークエクスチェンジ
はじめに ONNX(Open Neural Network Exchange)は、深層学習モデルの表現を容易にする標準化されたフォーマットとして広く認識されるようになりました。PyTorch、TensorFlow、Cafe2などのさまざまなフレームワーク間でのシームレスなデータ交換とコラボレーションを促進する能力により、その使用は大きな注目を集めています。 ONNXの主な利点の1つは、フレームワーク間の一貫性を確保する能力にあります。さらに、Python、C++、C#、Javaなどの複数のプログラミング言語を使用してモデルをエクスポートおよびインポートする柔軟性を提供しています。この柔軟性により、開発者は好みのプログラミング言語に関係なく、広いコミュニティ内でモデルを簡単に共有し活用することができます。 学習目標 このセクションでは、ONNXについて詳しく説明し、モデルをONNX形式に変換する包括的なチュートリアルを提供します。内容は個別のサブヘッダーに整理されます。 さらに、ONNX形式へのモデル変換に使用できるさまざまなツールについても探求します。 その後、PyTorchモデルをONNX形式に変換する手順に重点を置きます。 最後に、ONNXの機能に関する主な結果と洞察を強調した包括的なまとめを発表します。 この記事はデータサイエンスブログマラソンの一環として公開されました。 詳細な概要 ONNX(Open Neural Network Exchange)は、深層学習モデルに特化した自由に利用できるフォーマットです。その主な目的は、TensorFlowやCaffe2などと共にPyTorchを使用した際に異なる深層学習フレームワーク間でモデルのシームレスな交換と共有を促進することです。 ONNXの注目すべき利点の1つは、最小限の準備とモデルの書き直しの必要性なく、さまざまなフレームワーク間でモデルを転送できる能力です。この機能により、異なるハードウェアプラットフォーム(GPUやTPUなど)上でのモデルの最適化と高速化が大幅に簡素化されます。さらに、研究者はモデルを標準化された形式で共有することができ、コラボレーションと再現性を促進します。 効率的にONNXモデルを操作するために、ONNXがいくつかの便利なツールを提供しています。たとえば、ONNX Runtimeはモデルの実行に使用される高性能エンジンとして機能します。さらに、ONNXコンバータはさまざまなフレームワーク間でのモデル変換をシームレスにサポートします。 ONNXは、MicrosoftやFacebookなどの主要なAIコミュニティの貢献によって共同開発されている活発に開発されているプロジェクトです。さらに、NvidiaやIntelなどのハードウェアパートナー、AWS、Microsoft Azure、Google Cloudなどの主要なクラウドプロバイダもONNXをサポートしています。 ONNXとは何ですか?…

Pythonを使用したMann-Kendall傾向検定
はじめに マン・ケンドール傾向検定は、H.A.マンとD.R.ケンドールにちなんで名付けられた非パラメトリック検定であり、時間の経過に伴う傾向が有意であるかを判断するために使用されます。傾向は、時間の経過とともに単調に増加または減少することができます。パラメトリック検定ではデータの分布について心配する必要がないため、非パラメトリック検定です。ただし、データには直列相関/自己相関(時系列の誤差項が1期から別の期に移動すること)がない必要があります。 マン・ケンドール検定は、特定のデータの分布を仮定せずに、一貫して増加または減少する傾向を検出するために設計されています。これは、正規性などのパラメトリック検定の仮定を満たさない可能性のあるデータを扱う際に特に有用です。 この記事は、データサイエンスブログマラソンの一環として公開されました。 サンプルサイズの要件 サンプルが3または4のように非常に小さい場合、トレンドを見つける可能性が非常に低いです。時間の経過とともにサンプル数が増えるほど、テスト統計量は信頼性が高くなります。ただし、非常に少ないサンプルでもテストを実施することができます。したがって、推奨されるデータは少なくとも10です。 テストの目的 この記事では、列車の脱線に関連する事故について、時間の経過とともに研究します。オリッサ州で最近の列車脱線事故は、再び鉄道の安全性について問題を提起しました。鉄道事故は、事故の種類(例:正面衝突、後方衝突、爆発、側面衝突、脱線、火災など)で分類される場合があります。時間の経過とともに、技術的およびインフラ面で鉄道には多くの改善がありました。しかし、世界中で列車事故は頻繁に発生しています。列車事故は、世界中の鉄道システムで発生する不幸な出来事です。これらの事故は、生命の喪失、負傷、財産の損害につながる可能性があります。 この研究では、年月をかけて、インドの鉄道事故(ここでは脱線事故のカテゴリを研究します)を、過去の改善策を考慮に入れながら、減少させることができたかどうかを判断します。インドの脱線事故に関するデータは、時系列の性質を持っています。2001年から2016年までの脱線事故のデータが整理されています。 私たちのデータ 上記の表から、データの減少傾向が明らかにわかります。2001年から、脱線事故の数は非常に大幅に減少しました。2001年には350件の脱線事故があり、2016年には65件に減少しました。データが順番に整理されているため、Python環境に直接入力して作業することができます。Pythonでデータを適切に視覚化するためにプロットを作成しましょう。 !pip install seaborn import seaborn as sns import matplotlib.pyplot as plt fig =…
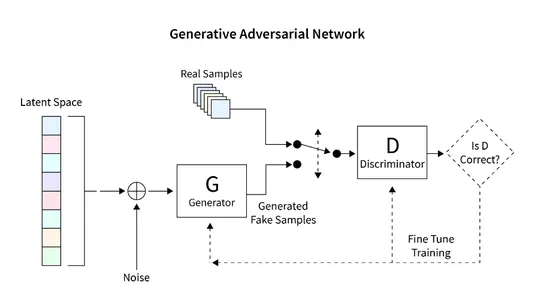
TensorFlowを使用したGANの利用による画像生成
イントロダクション この記事では、GAN(Generative Adversarial Networks)を使用して手書き数字のユニークなレンダリングを生成するためのTensorFlowの応用について探求します。GANフレームワークには、ジェネレータとディスクリミネータという2つの主要なコンポーネントがあります。ジェネレータはランダムな方法で新しい画像を生成し、ディスクリミネータは本物と偽物の画像を区別するために設計されています。GANのトレーニングを通じて、手書き数字に似たコレクションの画像を得ることができます。この記事の主な目的は、MNISTデータセットを使用してGANを構築し評価する手順を概説することです。 学習目標 この記事は、生成的対抗ネットワーク(GAN)の包括的な紹介を提供し、画像生成におけるその応用を探求します。 このチュートリアルの主な目的は、TensorFlowライブラリを使用してGANを構築する手順をステップバイステップで読者に案内することです。MNISTデータセットでGANをトレーニングして手書き数字の新しい画像を生成する方法をカバーしています。 この記事では、ジェネレータとディスクリミネータを含むGANのアーキテクチャとコンポーネントについて説明し、基本的な動作原理を読者の理解を深めるために探求します。 学習を支援するために、記事にはMNISTデータセットの読み込みと前処理、GANアーキテクチャの構築、損失関数の計算、ネットワークのトレーニング、結果の評価などさまざまなタスクをデモンストレーションするコード例が含まれています。 さらに、この記事ではGANの予想される成果物である手書き数字に酷似した画像のコレクションを探求します。 この記事は、データサイエンスブログマラソンの一環として公開されました。 何を構築するのか? 既存の画像データベースを使用して新しい画像を生成することは、生成的対抗ネットワーク(GAN)と呼ばれる特殊なモデルの主要な特徴です。GANは多様な画像データセットを活用して教師なしまたは半教師ありの画像を生成することに優れています。 この記事では、GANの画像生成の潜在能力を活用して手書き数字を作成します。手法としては、手書き数字のデータベースでネットワークをトレーニングすることが含まれます。この教示的な記事では、Tensorflowライブラリを利用して基本的なGANを構築し、MNISTデータセットでトレーニングを行い、手書き数字の新しい画像を生成します。 どのように設定しますか? この記事の主な焦点は、GANの画像生成の潜在能力を活用することです。手順は、画像データベースの読み込みと前処理から始まり、GANのトレーニングプロセスを容易にするためです。データが正常に読み込まれたら、GANモデルを構築し、トレーニングとテストのための必要なコードを開発します。次のセクションでは、この機能を実装し、MNISTデータベースを使用して新しい画像を生成するための詳細な手順が提供されます。 モデルの構築 構築するGANモデルは、2つの重要なコンポーネントで構成されています: ジェネレータ:このコンポーネントは新しい画像を生成する責任があります。 ディスクリミネータ:このコンポーネントは生成された画像の品質を評価します。 GANを使用して画像を生成するために開発する一般的なアーキテクチャは、以下の図に示されています。次のセクションでは、データベースの読み取り、必要なアーキテクチャの作成、損失関数の計算、ネットワークのトレーニングなどの詳細な手順について簡単に説明します。また、ネットワークの検査と新しい画像の生成に使用するコードも提供されます。 データセットの読み込み MNISTデータセットは、コンピュータビジョンの分野で非常に重要で、28×28ピクセルの大きさの手書き数字の広範なコレクションで構成されています。このデータセットは、グレースケールの単一チャンネルの画像形式であるため、GANの実装に理想的です。 次のコードスニペットは、Tensorflowの組み込み関数を使用してMNISTデータセットを読み込む例を示しています。読み込みが成功したら、画像を正規化し、3次元形式に変形します。この変換により、GANアーキテクチャ内で2D画像データを効率的に処理することができます。また、トレーニングデータと検証データの両方にメモリが割り当てられます。…

言語モデルの構築:ステップバイステップのBERTの実装ガイド
イントロダクション 言語処理を行う機械学習モデルの進歩は、ここ数年で急速に進んでいます。この進歩は、研究室を出て、いくつかの主要なデジタル製品の動力となり始めています。良い例として、BERTモデルがGoogle検索の重要な要素となったことが発表されたことがあります。Googleは、この進化(自然言語理解の進歩が検索に応用されること)は、「過去5年間で最大の進歩であり、検索の歴史上でも最大の進歩の1つ」と考えています。では、BERTとは何かについて理解しましょう。 BERTは、Bidirectional Encoder Representations from Transformersの略です。その設計では、未ラベルのテキストから左右の文脈の両方に依存して事前学習された深層双方向表現を作成します。我々は、追加の出力層を追加するだけで、事前学習されたBERTモデルを異なるNLPタスクに適用することができます。 学習目標 BERTのアーキテクチャとコンポーネントを理解する。 BERTの入力に必要な前処理ステップと、異なる入力シーケンスの長さを扱う方法を学ぶ。 TensorFlowやPyTorchなどの人気のある機械学習フレームワークを使用してBERTを実装するための実践的な知識を得る。 テキスト分類や固有表現認識などの特定の下流タスクにBERTを微調整する方法を学ぶ。 次に、「なぜそれが必要なのか?」という別の質問が出てきます。それを説明しましょう。 この記事は、データサイエンスブログマラソンの一環として公開されました。 なぜBERTが必要なのか? 適切な言語表現とは、機械が一般的な言語を理解する能力です。word2VecやGloveのような文脈非依存モデルは、語彙中の各単語に対して単一の単語埋め込み表現を生成します。例えば、”crane”という用語は、”crane in the sky”や”crane to lift heavy objects”といった文脈で厳密に同じ表現を持ちます。文脈モデルは、文内の他の単語に基づいて各単語を表現します。つまり、BERTはこれらの関係を双方向に捉える文脈モデルです。 BERTは、Semi-supervised…

プロンプトエンジニアリングへの紹介
イントロダクション 自然言語処理は、基盤となる技術や手法を使用した実装の豊かな領域であります。近年、特に2022年の始まり以来、自然言語処理(NLP)と生成型AIは進化を遂げています。これにより、プロンプトエンジニアリングは、言語モデル(LM)をマスターするために理解する必要のある特別なスキルとなりました。 学習目標 プロンプト、プロンプトエンジニアリング、および例の理解 プロンプトを洗練させるためのヒント プロンプトとプロンプトのパターンの要素 プロンプトの技法 プロンプトエンジニアリングの知識は、大規模な言語モデル(LLM)を基本的に使用する際の能力と制限をより良く理解するのに役立ちます。 この記事は、データサイエンスブログマラソンの一部として公開されました。 プロンプトエンジニアリングとは何ですか? プロンプトエンジニアリングは、人工知能の自然言語処理の分野で、AIが行うべきことをテキストで説明する実践です。この入力によってガイドされ、AIは出力を生成します。これは、人間が理解できるテキストを対話的にモデルとコミュニケーションするためのもので、タスクの説明が入力に埋め込まれているため、モデルは柔軟に動作し、可能性が広がります。 詳細はこちらをご覧ください:プロンプトエンジニアリング:パワフルなプロンプトの作成のアート プロンプトとは何ですか? プロンプトは、モデルから期待される出力の詳細な説明です。これはユーザーとAIモデルの間の対話です。これにより、エンジニアリングについてより理解が深まります。 プロンプトの例 ChatGPTやGPT-3などの大規模な言語モデルで使用されるプロンプトは、単純なテキストクエリの場合もあります。これらは提供できる詳細の量によって品質が測定されます。これらは、テキスト要約、質問と回答、コード生成、情報抽出などに使用されます。 多くの指示が含まれる複雑な問題を解決するためにLLMが使用されるため、詳細であることが重要です。基本的なプロンプトのいくつかの例を見てみましょう: プロンプト 抗生物質は、細菌感染症を治療するために使用される薬の一種です。それらは細菌を殺したり、増殖を防いだりすることで、体の免疫系が感染症と戦えるようにします。抗生物質は通常、錠剤、カプセル、液体溶液の形で経口的に摂取され、時には静脈内投与されます。抗生物質はウイルス感染症には効果がなく、不適切に使用すると抗生物質耐性が生じることがあります。 上記を2文に要約してください: この出力はQ&Aの形式で要約を表示します。 抗生物質は、細菌感染症を殺菌または増殖を防ぎ、免疫系が感染症と戦えるようにします。経口または静脈内投与され、ウイルス感染症には効果がなく、抗生物質耐性を引き起こす可能性があります。 LLMの使用例を見ました。可能性は無限です。 プロンプトを洗練させるためのヒント…

事前学習済みのViTモデルを使用した画像キャプショニングにおけるVision Transformer(ViT)
はじめに 事前学習済みのViTモデルを使用した画像キャプショニングは、画像の詳細な説明を提供するために画像の下に表示されるテキストまたは書き込みのことを指します。つまり、画像をテキストの説明に翻訳するタスクであり、ビジョン(画像)と言語(テキスト)を接続することで行われます。この記事では、PyTorchバックエンドを使用して、画像のViTを主要な技術として使用して、トランスフォーマーを使用した画像キャプショニングの生成方法を、スクラッチから再トレーニングすることなくトレーニング済みモデルを使用して実現します。 出典: Springer 現在のソーシャルメディアプラットフォームや画像のオンライン利用の流行に対応するため、この技術を学ぶことは、説明、引用、視覚障害者の支援、さらには検索エンジン最適化といった多くの理由で役立ちます。これは、画像を含むプロジェクトにとって非常に便利な技術であります。 学習目標 画像キャプショニングのアイデア ViTを使用した画像キャプチャリング トレーニング済みモデルを使用した画像キャプショニングの実行 Pythonを使用したトランスフォーマーの利用 この記事で使用されたコード全体は、このGitHubリポジトリで見つけることができます。 この記事は、データサイエンスブログマラソンの一環として公開されました。 トランスフォーマーモデルとは何ですか? ViTについて説明する前に、トランスフォーマーについて理解しましょう。Google Brainによって2017年に導入されて以来、トランスフォーマーはNLPの能力において注目を集めています。トランスフォーマーは、入力データの各部分の重要性を異なる重み付けする自己注意を採用して区別されるディープラーニングモデルです。これは、主に自然言語処理(NLP)の分野で使用されています。 トランスフォーマーは、自然言語のようなシーケンシャルな入力データを処理しますが、トランスフォーマーは一度にすべての入力を処理します。注意機構の助けを借りて、入力シーケンスの任意の位置にはコンテキストがあります。この効率性により、より並列化が可能となり、トレーニング時間が短縮され、効率が向上します。 トランスフォーマーアーキテクチャ 次に、トランスフォーマーのアーキテクチャの構成を見てみましょう。トランスフォーマーアーキテクチャは、主にエンコーダー-デコーダー構造から構成されています。トランスフォーマーアーキテクチャのエンコーダー-デコーダー構造は、「Attention Is All You Need」という有名な論文で発表されました。 エンコーダーは、各レイヤーが入力を反復的に処理することを担当し、一方で、デコーダーレイヤーはエンコーダーの出力を受け取り、デコードされた出力を生成します。単純に言えば、エンコーダーは入力シーケンスをシーケンスにマッピングし、それをデコーダーに供給します。デコーダーは、出力シーケンスを生成します。 ビジョン・トランスフォーマーとは何ですか?…

紛争のトレンドとパターンの探索:マニプールのACLEDデータ分析
はじめに データ分析と可視化は、複雑なデータセットを理解し、洞察を効果的に伝えるための強力なツールです。この現実世界の紛争データを深く掘り下げる没入型探索では、紛争の厳しい現実と複雑さに深く踏み込みます。焦点は、長期にわたる暴力と不安定状態によって悲惨な状況に陥ったインド北東部のマニプール州にあります。私たちは、武装紛争ロケーション&イベントデータプロジェクト(ACLED)データセット[1]を使用し、紛争の多面的な性質を明らかにするための詳細なデータ分析の旅に出ます。 学習目標 ACLEDデータセットのデータ分析技術に熟達する。 効果的なデータ可視化のスキルを開発する。 脆弱な人口に対する暴力の影響を理解する。 紛争の時間的および空間的な側面に関する洞察を得る。 人道的ニーズに対処するための根拠に基づくアプローチを支援する。 この記事は、データサイエンスブログマラソンの一環として公開されました。 利害の衝突 このブログで提示された分析と解釈に責任を持つ特定の組織や団体はありません。目的は、紛争分析におけるデータサイエンスの潜在力を紹介することです。さらに、これらの調査結果には個人的な利益や偏見が含まれておらず、紛争のダイナミクスを客観的に理解するアプローチが確保されています。データ駆動型の方法を促進し、紛争分析に関する広範な議論に情報を提供するために、積極的に利用することを推奨します。 実装 なぜACLEDデータセットを使用するのか? ACLEDデータセットを活用することで、データサイエンス技術の力を活用することができます。これにより、マニプール州の状況を理解するだけでなく、暴力に関連する人道的側面にも光を当てることができます。ACLEDコードブックは、このデータセット[2]で使用されるコーディングスキームと変数に関する詳細な情報を提供する包括的な参考資料です。 ACLEDの重要性は、共感的なデータ分析にあります。これにより、マニプール州の暴力に関する理解が深まり、人道的ニーズが明らかにされ、暴力の解決と軽減に貢献します。これにより、影響を受けるコミュニティに平和で包摂的な未来が促進されます。 このデータ駆動型の分析により、貴重な洞察力を得るだけでなく、マニプール州の暴力の人的コストにも光が当てられます。ACLEDデータを精査することで、市民人口、強制的移動、必要なサービスへのアクセスなど、地域で直面する人道的現実の包括的な描写が可能になります。 紛争のイベント まず、ACLEDデータセットを使用して、マニプール州の紛争のイベントを調査します。以下のコードスニペットは、インドのACLEDデータセットを読み込み、マニプール州のデータをフィルタリングして、形状が(行数、列数)のフィルタリングされたデータセットを生成します。フィルタリングされたデータの形状を出力します。 import pandas as pd # ACLEDデータをダウンロードして国別のcsvをインポートする…

マルチヘッドアテンションを使用した注意機構の理解
はじめに Transformerモデルについて詳しく学ぶ良い方法は、アテンションメカニズムについて学ぶことです。特に他のタイプのアテンションメカニズムを学ぶ前に、マルチヘッドアテンションについて学ぶことは良い選択です。なぜなら、この概念は少し理解しやすい傾向があるためです。 アテンションメカニズムは、通常の深層学習モデルに追加できるニューラルネットワークレイヤーと見なすことができます。これにより、重要な部分に割り当てられた重みを使用して、入力の特定の部分に焦点を当てるモデルを作成することができます。ここでは、マルチヘッドアテンションメカニズムを使用して、アテンションメカニズムについて詳しく見ていきます。 学習目標 アテンションメカニズムの概念 マルチヘッドアテンションについて Transformerのマルチヘッドアテンションのアーキテクチャ 他のタイプのアテンションメカニズムの概要 この記事は、データサイエンスブログマラソンの一環として公開されました。 アテンションメカニズムの理解 まず、この概念を人間の心理学から見てみましょう。心理学では、注意は他の刺激の影響を除外して、イベントに意識を集中することです。つまり、他の注意を引くものがある場合でも、私たちは選択したものに焦点を合わせます。注意は全体の一部に集中します。 これがTransformerで使用される概念です。彼らは入力のターゲット部分に焦点を当て、残りの部分を無視することができます。これにより、非常に効果的な方法で動作することができます。 マルチヘッドアテンションとは? マルチヘッドアテンションは、Transformerにおいて中心的なメカニズムであり、ResNet50アーキテクチャにおけるskip-joiningに相当します。場合によっては、アテンドするべきシーケンスの複数の他の点があります。全体の平均を見つける方法では、重みを分散させて多様な値を重みとして与えることができません。これにより、複数のアテンションメカニズムを個別に作成するアイデアが生まれ、複数のアテンションメカニズムが生じます。実装では、1つの機能に複数の異なるクエリキー値トリプレットが表示されます。 出典:Pngwing.com 計算は、アテンションモジュールが何度も反復し、アテンションヘッドとして知られる並列レイヤーに組織化される方法で実行されます。各別のヘッドは、入力シーケンスと関連する出力シーケンスの要素を独立して処理します。各ヘッドからの累積スコアは、すべての入力シーケンスの詳細を組み合わせた最終的なアテンションスコアを得るために組み合わされます。 数式表現 具体的には、キーマトリックスとバリューマトリックスがある場合、値をℎサブクエリ、サブキー、サブバリューに変換し、アテンションを独立して通過させることができます。連結すると、ヘッドが得られ、最終的な重み行列でそれらを組み合わせます。 学習可能なパラメータは、アテンションに割り当てられた値であり、各パラメータはマルチヘッドアテンションレイヤーと呼ばれます。以下の図はこのプロセスを示しています。 これらの変数を簡単に見てみましょう。Xの値は、単語埋め込みの行列の連結です。 行列の説明 クエリ:シーケンスのターゲットについての洞察を提供する特徴ベクトルです。クエリは、何がアテンションを必要としているかをシーケンスに要求します。 キー:要素に含まれるものを説明する特徴ベクトルです。クエリによってアテンションが与えられ、要素のアイデンティティを提供します。 値:…

機械学習によるストレス検出の洞察を開示
イントロダクション ストレスとは、身体や心が要求や挑戦的な状況に対して自然に反応することです。外部の圧力や内部の思考や感情に対する身体の反応です。仕事に関するプレッシャーや財政的な困難、人間関係の問題、健康上の問題、または重要な人生の出来事など、様々な要因によってストレスが引き起こされることがあります。データサイエンスと機械学習によるストレス検知インサイトは、個人や集団のストレスレベルを予測することを目的としています。生理学的な測定、行動データ、環境要因などの様々なデータソースを分析することで、予測モデルはストレスに関連するパターンやリスク要因を特定することができます。 この予防的アプローチにより、タイムリーな介入と適切なサポートが可能になります。ストレス予測は、健康管理において早期発見と個別化介入、職場環境の最適化に役立ちます。また、公衆衛生プログラムや政策決定にも貢献します。ストレスを予測する能力により、これらのモデルは個人やコミュニティの健康増進と回復力の向上に貢献する貴重な情報を提供します。 この記事は、データサイエンスブログマラソンの一部として公開されました。 機械学習を用いたストレス検知の概要 機械学習を用いたストレス検知は、データの収集、クリーニング、前処理を含みます。特徴量エンジニアリング技術を適用して、ストレスに関連するパターンを捉えることができる意味のある情報を抽出したり、新しい特徴を作成したりすることができます。これには、統計的な測定、周波数領域解析、または時間系列解析などが含まれ、ストレスの生理学的または行動的指標を捉えることができます。関連する特徴量を抽出またはエンジニアリングすることで、パフォーマンスを向上させることができます。 研究者は、ロジスティック回帰、SVM、決定木、ランダムフォレスト、またはニューラルネットワークなどの機械学習モデルを、ストレスレベルを分類するためのラベル付きデータを使用してトレーニングします。彼らは、正解率、適合率、再現率、F1スコアなどの指標を使用してモデルのパフォーマンスを評価します。トレーニングされたモデルを実世界のアプリケーションに統合することで、リアルタイムのストレス監視が可能になります。継続的なモニタリング、更新、およびユーザーフィードバックは、精度向上に重要です。 ストレスに関連する個人情報の扱いには、倫理的な問題やプライバシーの懸念を考慮することが重要です。個人のプライバシーや権利を保護するために、適切なインフォームドコンセント、データの匿名化、セキュアなデータストレージ手順に従う必要があります。倫理的な考慮事項、プライバシー、およびデータセキュリティは、全体のプロセスにおいて重要です。機械学習に基づくストレス検知は、早期介入、個別化ストレス管理、および健康増進に役立ちます。 データの説明 「ストレス」データセットには、ストレスレベルに関する情報が含まれています。データセットの特定の構造や列を持たない場合でも、パーセンタイルのためのデータ説明の一般的な概要を提供できます。 データセットには、年齢、血圧、心拍数、またはスケールで測定されたストレスレベルなど、数量的な測定を表す数値変数が含まれる場合があります。また、性別、職業カテゴリ、または異なるカテゴリ(低、VoAGI、高)に分類されたストレスレベルなど、定性的な特徴を表すカテゴリカル変数も含まれる場合があります。 # Array import numpy as np # Dataframe import pandas as pd #Visualization…

アテンションメカニズムを利用した時系列予測
はじめに 時系列予測は、金融、気象予測、株式市場分析、リソース計画など、さまざまな分野で重要な役割を果たしています。正確な予測は、企業が情報に基づいた決定を行い、プロセスを最適化し、競争上の優位性を得るのに役立ちます。近年、注意機構が、時系列予測モデルの性能を向上させるための強力なツールとして登場しています。本記事では、注意の概念と、時系列予測の精度を向上させるために注意を利用する方法について探求します。 この記事は、データサイエンスブログマラソンの一環として公開されました。 時系列予測の理解 注意機構について詳しく説明する前に、まず時系列予測の基礎を簡単に見直してみましょう。時系列は、日々の温度計測値、株価、月次の売上高など、時間の経過とともに収集されたデータポイントの系列から構成されます。時系列予測の目的は、過去の観測値に基づいて将来の値を予測することです。 従来の時系列予測手法、例えば自己回帰和分移動平均(ARIMA)や指数平滑法は、統計的手法や基礎となるデータに関する仮定に依存しています。研究者たちはこれらの手法を広く利用し、合理的な結果を得ていますが、データ内の複雑なパターンや依存関係を捉えることに課題を抱えることがあります。 注意機構とは何か? 人間の認知プロセスに着想を得た注意機構は、深層学習の分野で大きな注目を集めています。機械翻訳の文脈で初めて紹介された後、注意機構は自然言語処理、画像キャプション、そして最近では時系列予測など、様々な分野で広く採用されています。 注意機構の主要なアイデアは、モデルが予測を行うために最も関連性の高い入力シーケンスの特定の部分に焦点を合わせることを可能にすることです。注意は、すべての入力要素を同等に扱うのではなく、関連性に応じて異なる重みや重要度を割り当てることができるようにします。 注意の可視化 注意の仕組みをよりよく理解するために、例を可視化してみましょう。数年にわたって日々の株価を含む時系列データセットを考えます。次の日の株価を予測したいとします。注意機構を適用することで、モデルは、将来の価格に影響を与える可能性が高い、過去の価格の特定のパターンやトレンドに焦点を合わせることができます。 提供された可視化では、各時間ステップが小さな正方形として描かれ、その特定の時間ステップに割り当てられた注意重みが正方形のサイズで示されています。注意機構は、将来の価格を予測するために、関連性が高いと判断された最近の価格により高い重みを割り当てることができることがわかります。 注意に基づく時系列予測モデル 注意機構の理解ができたところで、時系列予測モデルにどのように統合できるかを探ってみましょう。人気のあるアプローチの1つは、注意を再帰型ニューラルネットワーク(RNN)と組み合わせることで、シーケンスモデリングに広く使用されている方法です。 エンコーダ・デコーダアーキテクチャ エンコーダ・デコーダアーキテクチャは、エンコーダとデコーダの2つの主要なコンポーネントから構成されています。過去の入力シーケンスをX = [X1、X2、…、XT]、Xiが時間ステップiの入力を表すようにします。 エンコーダ エンコーダは、入力シーケンスXを処理し、基礎となるパターンと依存関係を捉えます。このアーキテクチャでは、エンコーダは通常、LSTM(長短期記憶)レイヤを使用して実装されます。入力シーケンスXを取り、隠れ状態のシーケンスH = [H1、H2、…、HT]を生成します。各隠れ状態Hiは、時間ステップiの入力のエンコード表現を表します。 H、_= LSTM(X)…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.