Learn more about Search Results エージェント - Page 9

- You may be interested
- 分岐と限定法 -アルゴリズムをスクラッチ...
- DeepMindのAIマスターゲーマー:2時間で26...
- モデルマージングとは、複数のモデルを統...
- Python Enumerate():カウンターを使用...
- ChatGPTでリードマグネットのアイデアをブ...
- 「AWS Trainiumを使用した高速で費用効果...
- コーネル大学がChatGPTの中核に巨大な脅威...
- デット (物体検出用トランスフォーマー)
- 「ジェネラティブAIサミットのオンデマン...
- 「Meetupsからメンタリングまで データサ...
- イェール大学とGoogle DeepMindの研究者は...
- データ契約の裏側:消費者の責任の目覚め
- 「CRISPRツールがウイルスを撃ち破るのに...
- 「隠れたパターンの解明:階層クラスタリ...
- プリンストン大学の研究者が、MeZOという...

UCサンタクルーズとSamsungの研究者が、ナビゲーションの決定にChatGPTのようなLLM(言語モデル)で共通センスを活用するゼロショットオブジェクトナビゲーションエージェントであるESCを紹介しました
オブジェクトナビゲーション(ObjNav)は、未知の環境で物理エージェントを事前に決められた目的のオブジェクトに案内するものです。目的のオブジェクトにナビゲートすることは、他のナビゲーションベースのエンボディドタスクにおいて重要な前提条件となります。 環境内の部屋とオブジェクトを識別する(意味的なシーン理解)ことと、コモンセンスの推論を使用して目標オブジェクトの場所を推測する(コモンセンス推論)ことは、成功したナビゲーションに不可欠な2つのスキルです。しかし、現在のゼロショットオブジェクトナビゲーション手法は、コモンセンスの推論能力に欠けており、この要件に十分に対応していません。既存の手法は、探索に対して単純なヒューリスティックを使用するか、他の目標指向型ナビゲーションタスクや周囲のトレーニングを必要とします。 最近の研究は、大規模な事前学習モデルがゼロショット学習と問題解決に優れていることを示しています。この知見に触発され、カリフォルニア大学サンタクルーズ校とサムスン研究は、Exploration with Soft Commonsense constraints(ESC)と呼ばれるゼロショットオブジェクトナビゲーションフレームワークを提案しました。このフレームワークは、事前学習済みモデルを使用して、馴染みのない設定やオブジェクト種に自動的に適応します。 チームはまず、GLIPというビジョンと言語のグラウンディングモデルを使用して、現在のエージェントの視点のオブジェクトと部屋の情報を推測するためのプロンプトベースの手法として利用します。GLIPは、画像とテキストのペアに対する広範な事前学習により、最小限のプロンプティングで新しいオブジェクトに対して容易に一般化することができます。次に、部屋とオブジェクトのデータをコンテキストとして使用する事前学習済みのコモンセンス推論言語モデルを使用して、両者の関連性を推測します。 しかし、LLMから推論されたコモンセンス知識を具体的な手順に変換する際には、まだ空白があります。また、物事のつながりの間にあるある程度の不確実性があることも珍しくありません。確率的ソフトロジック(PSL)を使用することで、このような障害を克服するために、「ソフト」コモンセンス制約をモデル化するESCのアプローチが使用されます。フロンティアベースの探索(FBE)は、これらの柔らかいコモンセンス制約を使用して、次の探索対象のフロンティアに焦点を当てる従来の戦略です。以前のアプローチでは、共通の感覚を暗黙的に刷り込むためにニューラルネットワークトレーニングに頼っていましたが、提案された手法では、ソフトロジック述語を使用して連続値空間で知識を表現し、それを各フロンティアに与えることで、より効率的な探索を促進します。 システムの効果をテストするために、研究者たちはさまざまな家のサイズ、建築スタイル、テクスチャ特徴、オブジェクトタイプを持つ3つのオブジェクト目標ナビゲーションベンチマーク(MP3D、HM3D、RoboTHOR)を使用します。調査結果は、MP3DではCoWに比べてSPL(長さによる重み付けされたSPL)およびSR(成功率)で約285%、RoboTHORでは約35%とSR(成功率)でアプローチが優れていることを示しています。この手法は、HM3Dのデータセットでのトレーニングを必要とするZSONと比較して、MP3Dでは相対的なSPLで196%、HM3Dでは相対的なSPLで85%優れています。提案されたゼロショットアプローチは、MP3Dデータセットにおいて他の最先端の教師ありアルゴリズムと比較して最も高いSPLを達成しています。

「DERAに会ってください:対話可能な解決エージェントによる大規模言語モデル補完を強化するためのAIフレームワーク」
「大規模言語モデル」の深層学習は、入力に基づいて自然言語のコンテンツを予測するために開発されました。これらのモデルの使用は、言語モデリングの課題を超えて、自然言語のパフォーマンスを向上させました。LLM(大規模言語モデル)を活用したアプローチは、情報抽出、質問応答、要約などの医療タスクにおいて利益を示しています。プロンプトは、LLMを活用した技術で使用される自然言語の指示です。タスクの仕様、予測が遵守しなければならないルール、オプションでタスクの入力と出力のサンプルなどが、これらの指示セットに含まれています。 生成型言語モデルは、自然言語で与えられた指示に基づいて結果を生成する能力により、タスク固有のトレーニングの必要性をなくし、非専門家がこの技術を拡張することができるようになりました。多くの仕事は単一のキューとして表現できるかもしれませんが、さらなる研究では、タスクをより小さなタスクに分割することが、特に医療セクターにおいてタスクのパフォーマンスを向上させる可能性があることが示されています。彼らは、2つの重要な要素で構成される代替戦略をサポートしています。まず、最初の生成物を改善するための反復プロセスから始まります。これにより、生成がホリスティックに洗練されることができます。次に、各反復ごとに集中すべき領域を提案することで、ガイドが指示することができます。これにより、プロセスがより理解しやすくなります。 GPT-4の開発により、彼らは豊かで生き生きとした会話型VoAGI(自己意識を持つ人工一般知性)を手に入れました。Curai Healthの研究者たちは、Dialog-Enabled Resolving Agents(DERA)と呼ばれるものを提案しています。DERAは、対話解決を担当するエージェントが自然言語のタスクでのパフォーマンスを向上させる方法を調査するためのフレームワークです。彼らは、各対話エージェントを特定の役割に割り当てることで、彼らが仕事の特定の側面に焦点を当てることができ、パートナーエージェントが全体の目標との整合性を保つことができると主張しています。研究者エージェントは、問題に関連するデータを求め、他のエージェントが集中するべきトピックを提案します。 彼らは、自然言語のタスクのパフォーマンスを向上させるために、エージェント間の相互作用のフレームワークであるDERAを提供しています。彼らは、DERAを3つの異なるカテゴリの臨床タスクで評価しています。それぞれに答えるために、さまざまなテキストの入力と専門知識のレベルが必要です。医療対話の要約の課題は、事実に基づき、幻覚や省略がない医師と患者の対話の要約を提供することを目指しています。ケアプランの作成には多くの情報が必要で、臨床的な意思決定支援に役立つ長い出力があります。デシダーエージェントの役割は、このデータに応じて応答し、出力の最終的な行動方針を選択することができます。 この研究にはさまざまな解決策があり、目標は事実に基づいて正確で関連性のある資料を作成することです。医学に関する質問に答えることは、知識思考を必要とするオープンエンドの課題であり、一つの解決策しかない場合があります。彼らは、このより困難な環境で研究するために2つの質問応答データセットを使用しています。人間の注釈付き評価の両方で、ケアプラン作成と医療対話の要約の課題においてDERAがベースのGPT-4よりも優れたパフォーマンスを発揮することを発見しました。定量的な分析によると、DERAは多くの不正確な医療対話の要約を正確に修正することができます。 一方、質問応答においては、GPT-4とDERAのパフォーマンスにほとんど改善が見られませんでした。彼らの理論によれば、この手法は、多くの微細な特徴を持つ長文生成の問題に適しています。彼らは、米国医師免許試験の練習問題からなる新しいオープンエンドの医学的な質問応答の仕事を発表するために協力します。これにより、質問応答システムのモデリングと評価に関する新しい研究が可能になります。推論の連鎖やその他のタスク固有の手法は、連鎖戦略の例です。 連鎖思考の技術は、モデルが専門家のように問題に取り組むことを促し、いくつかのタスクを改善します。これらの手法のすべては、基本的な言語モデルから適切な生成を引き出すための努力です。具体的な目的で作成された特定のプロンプトの事前定義セットに限定されているという制約は、この手法の基本的な制約です。彼らはこの方向に良い一歩を踏み出しましたが、現実の状況に適用することはまだ非常に困難です。

GPT-4のようなモデルは、行動能力を与えられた場合に安全に振る舞うのか?:このAI論文では、「MACHIAVELLIベンチマーク」を導入して、マシン倫理を向上させ、より安全な適応エージェントを構築することを提案しています
自然言語処理は、AIシステムが急速な進歩を遂げている分野の一つであり、モデルはデプロイメントのリスクを減らすために徹底的にテストされ、安全な動作に導かれる必要があります。従来の評価メトリックは、言語理解や推論の能力を測定することに焦点を当てていましたが、現在のモデルは実際のインタラクティブな作業のために教育されています。これは、ベンチマークがモデルの社会的な環境でのパフォーマンスを評価する必要があることを意味します。 インタラクティブなエージェントは、テキストベースのゲームでテストされることがあります。エージェントは、これらのゲームで進展するために計画能力と自然言語の理解能力を必要とします。ベンチマークを設定する際には、エージェントの非倫理的な傾向も技術的な才能と並んで考慮されるべきです。 カリフォルニア大学、AI安全センター、カーネギーメロン大学、イェール大学の新しい研究は、長期の言語インタラクションの広大な環境におけるエージェントの能力と有害性を測定するMACHIAVELLIベンチマークを提案しています。MACHIAVELLIは、自然主義的な社会的設定でのエージェントの計画能力を評価するための進歩です。この設定は、choiceofgames.comで開発されたテキストベースのChoose Your Own Adventureゲームに触発されています。これらのゲームは、高レベルの意思決定を特徴とし、エージェントに現実的な目標を与えながら、低レベルの環境インタラクションは抽象化されます。 この環境では、エージェントの行動が不正である程度、効用が低い、権力を求めるなどの行動的な特性が報告され、非倫理的な行動を監視します。チームは以下の手順に従ってこれを達成しています: これらの行動を数学的な式として具体化する ゲーム内の社会的概念を密に注釈付けする(キャラクターの福祉など) 注釈と式を使用して、各行動に対して数値スコアを生成する 彼らは、GPT-4(OpenAI、2023)が人間の注釈付け者よりも注釈を収集するのに効果的であることを実証しています。 人間と同じように、人工知能エージェントも内部的な葛藤に直面しています。次のトークン予測のためにトレーニングされた言語モデルはしばしば有害なテキストを生成しますし、目標最適化のためにトレーニングされた人工エージェントはしばしば非倫理的で権力を求める行動を示します。非倫理的に訓練されたエージェントは、他者や環境の犠牲になる報酬を最大化するためにマキャベリアンな戦略を開発する可能性があります。エージェントが倫理的に行動するように促すことで、このトレードオフを改善することができます。 チームは、倫理的なトレーニング(エージェントにより倫理的に行動するように促す)によって、言語モデルエージェントの有害な活動の発生率が減少することを発見しました。さらに、行動の正規化は報酬を大幅に減少させることなく、両方のエージェントで望ましくない行動を制限します。この研究は、信頼性のある順序決定者の開発に貢献しています。 研究者たちは、人工的な良心と倫理的なプロンプトのようなテクニックを使用してエージェントを制御しようと試みています。エージェントは、マキャベリアンな行動を少なく表示するように誘導することができますが、まだ多くの進展が可能です。彼らは、これらのトレードオフについてのさらなる研究を提唱し、限られた報酬を追い求めるのではなく、パレートフロンティアを拡大することを強調しています。

スタンフォード大学とGoogleからのこのAI論文は、生成エージェントを紹介しています生成エージェントは、人間の振る舞いをシミュレートするインタラクティブな計算エージェントです
明らかに、AIボットは高品質かつ流暢な自然言語を生成することができます。長い間、研究者や実践者は、異なる種類の相互作用、人間関係、社会理論などを学ぶために、人間の行動を持つエージェントで満たされた砂場の文明を構築することを考えてきました。人間の行動の信頼性のある代替品は、仮想現実から社会的スキルトレーニング、プロトタイピングプログラムまで、さまざまなインタラクティブアプリケーションを推進するかもしれません。研究者たちは、スタンフォード大学とGoogle Researchの研究者から、アイデンティティ、変化する経験、環境に応じて人間のような個々の行動と新興的集団行動を模倣するために生成モデルを使用するエージェントを紹介しています。 このグループの主な貢献は次のとおりです: エージェントの行動が信憑性があるため、エージェントの変化する経験と周囲の状況に動的に依存しています。 急速に変化する状況で、長期的な記憶、検索、反射、社会的相互作用、シナリオの計画能力を実現するための革命的なフレームワーク。 制御試験とエンドツーエンドテストの2つのタイプのテストを使用して、アーキテクチャの異なる部分の価値を判断し、記憶の検索のような問題を見つけます。 生成エージェントを使用する対話システムが社会と倫理に与える利点と潜在的な危険について議論します。 このグループの目標は、スマートエージェントが日常生活を送り、環境や歴史的な手がかりに応じて自然言語でお互いと対話し、スケジュールを組み、情報を交換し、友情を築き、グループ活動を調整する仮想のオープンワールドフレームワークを作成することでした。大規模な言語モデル(LLM)とLLMの出力に基づいてデータを合成・抽出するメカニズムを組み合わせることで、チームは過去の失敗から学び、長期的なキャラクターの一貫性を保ちながら、より正確なリアルタイムの推論を行うことができるエージェントアーキテクチャを作成しました。 複雑な行動は、エージェントの録音の再帰的合成によってガイドされることがあります。エージェントのメモリストリームは、エージェントの以前の経験の完全な記録を含むデータベースです。エージェントは、環境の変化に適応するために、メモリストリームから関連するデータにアクセスし、この知識を処理して行動計画を立てることができます。 研究者は人間の評価者を募集し、Phaserオンラインゲーム開発フレームワークで開発されたSmallvilleサンドボックス環境で、提案された25の生成エージェントを非プレイヤーキャラクター(NPC)として機能させました。エージェントの一貫したキャラクターの描写と人間のような記憶、計画、反応、反射の説得力ある模倣は、実験の特徴でした。彼らは2日間にわたって自然言語でお互いとコミュニケーションをしました。 応用 生成エージェントをマルチモーダルモデルと組み合わせることで、オンラインおよびオフラインで人間と対話できるソーシャルロボットが将来的に実現できるかもしれません。これにより、社会システムやアイデアのプロトタイプを作成し、新しいインタラクティブ体験をテストし、より現実的な人間の行動モデルを構築できるようになります。 GOMSやKeystroke Level Modelなどの認知モデルは、ヒューマンセンタードデザインプロセスの別の領域でも使用できます。 生成エージェントをユーザーの代替として使用することで、その要件や好みについてより詳しく学び、より適した効率的な技術的相互作用を実現できるようになります。 この研究は、役割演技、社会プロトタイピング、没入型環境、ゲームなどで使用する可能性があり、動的で対話的な人間のような行動を持つLLMベースのシミュラクラの進歩に貢献しています。この研究で示された生成エージェントアーキテクチャのコンポーネントは、さらなる研究でさらに開発される可能性があります。たとえば、特定のコンテキストで最も関連性の高い素材を検索モジュールが見つける能力を向上させるために、検索機能を構成する関連性、最近性、重要性の関数を調整することができます。また、アーキテクチャのパフォーマンスを向上させるための取り組みも行われるべきです。 将来の研究では、生成エージェントの行動をより長い時間にわたって調査し、その能力と限界について完全な知識を獲得する必要があります。この研究では、エージェントの行動の評価が非常に短い期間に制限されていたためです。

「HuggingFace Transformers ツールとエージェント:ハンズオン」
Transformersバージョンv4.29.0は、ツールとエージェントのコンセプトを基に構築され、transformersの上に自然言語APIを提供しますそれらの使い方は?言語学習を目的として詳しく調べてみましょう…

どのような要素が対話エージェントを有用にするのか?
ChatGPTの技術:RLHF、IFT、CoT、レッドチーミング、およびその他 この記事は、中国語の簡体字で翻訳されています。 数週間前、ChatGPTが登場し、一連の不明瞭な頭字語(RLHF、SFT、IFT、CoTなど)が公衆の議論を巻き起こしました。これらの不明瞭な頭字語は何であり、なぜそれらが重要なのでしょうか?私たちはこれらのトピックに関する重要な論文を調査し、これらの作品を分類し、達成された成果からの要点をまとめ、まだ示されていないことを共有します。 まず、言語モデルに基づく会話エージェントの現状を見てみましょう。ChatGPTは最初ではありません。実際、OpenAIよりも前に、MetaのBlenderBot、GoogleのLaMDA、DeepMindのSparrow、およびAnthropicのAssistant(このエージェントの完璧な帰属なしでの継続的な開発はClaudeとも呼ばれています)など、多くの組織が言語モデルの対話エージェントを公開しています。一部のグループは、オープンソースのチャットボットを構築する計画を発表し、ロードマップを公開しています(LAIONのOpen Assistant)。他のグループも確実に同様の作業を進めており、まだ発表していないでしょう。 以下の表は、これらのAIチャットボットを公開アクセス、トレーニングデータ、モデルアーキテクチャ、および評価方向の詳細に基づいて比較しています。ChatGPTには文書化された情報がないため、代わりにChatGPTの基礎となったと信じられているOpenAIの指示fine-tunedモデルであるInstructGPTの詳細を共有します。 トレーニングデータ、モデル、およびファインチューニングには多くの違いがあることが観察されますが、共通点もあります。これらのチャットボットの共通の目標は、ユーザーの指示に従うことです。たとえば、ChatGPTに詩を書くように指示することなどです。 予測テキストから指示の従属へ 通常、ベースモデルの言語モデリング目標だけでは、モデルがユーザーの指示に対して有益な方法で従うことを学ぶには十分ではありません。モデル開発者は、指示の細かいチューニング(IFT)を使用して、ベースモデルを、感情、テキスト分類、要約などの古典的なNLPタスクのデモンストレーションによって微調整し、非常に多様なタスクセットにおける指示の書かれた方針を学びます。これらの指示のデモンストレーションは、指示、入力、および出力の3つの主要なコンポーネントで構成されています。入力はオプションです。一部のタスクでは、ChatGPTの例のように指示のみが必要です。入力と出力が存在する場合、インスタンスが形成されます。特定の指示に対して複数の入力と出力が存在する場合もあります。以下に[Wang et al.、’22]からの例を示します。 IFTのデータは通常、人間によって書かれた指示と言語モデルを用いた指示のインスタンスのコレクションからなります。ブートストラップのために、LMは(上記の図のように)いくつかの例を使用してフューショット設定でプロンプトされ、新しい指示、入力、および出力を生成するように指示されます。各ラウンドで、モデルは人間によって選択されたサンプルとモデルによって生成されたサンプルの両方からプロンプトを受け取ります。データセットの作成における人間とモデルの貢献の割合はスペクトラムです。以下の図を参照してください。 一方は完全にモデル生成されたIFTデータセットであり、例えばUnnatural Instructions(Honovich et al.、’22)です。もう一方は手作りの指示の大規模な共同作業であり、Super-natural instructions(Wang et al.、’22)などです。これらの間には、Self-instruct(Wang et al.、’22)のような、高品質のシードデータセットを使用してブートストラップする方法もあります。IFTのデータセットを収集するもう1つの方法は、さまざまなタスク(プロンプトを含む)の既存の高品質なクラウドソーシングNLPデータセットを統一スキーマや多様なテンプレートを使用して指示としてキャストすることです。この研究の一環には、T0(Sanh et al.、’22)、自然言語指示データセット(Mishra et…

⚔️AI vs. AI⚔️は、深層強化学習マルチエージェント競技システムを紹介します
私たちは新しいツールを紹介するのを楽しみにしています: ⚔️ AI vs. AI ⚔️、深層強化学習マルチエージェント競技システム。 このツールはSpacesでホストされており、マルチエージェント競技を作成することができます。以下の3つの要素で構成されています: マッチメイキングアルゴリズムを使用してモデルの戦いをバックグラウンドタスクで実行するスペース。 結果を含むデータセット。 マッチ履歴の結果を取得し、モデルのELOを表示するリーダーボード。 ユーザーが訓練済みモデルをHubにアップロードすると、他のモデルと評価およびランキング付けされます。これにより、マルチエージェント環境で他のエージェントとの評価が可能です。 マルチエージェント競技をホストする有用なツールであるだけでなく、このツールはマルチエージェント環境での堅牢な評価技術でもあると考えています。多くのポリシーと対戦することで、エージェントは幅広い振る舞いに対して評価されます。これにより、ポリシーの品質を良く把握することができます。 最初の競技ホストであるSoccerTwos Challengeでどのように機能するか見てみましょう。 AI vs. AIはどのように機能しますか? AI vs. AIは、Hugging Faceで開発されたオープンソースのツールで、マルチエージェント環境での強化学習モデルの強さをランク付けするためのものです。 アイデアは、モデルを継続的に互いに対戦させ、その結果を使用して他のすべてのモデルと比較してパフォーマンスを評価し、ポリシーの品質を把握するための相対的なスキルの尺度を得ることです。従来のメトリクスを必要とせずに。 エージェントが特定のタスクや環境に提出される数が増えるほど、ランキングはより代表的になります。 競争環境での試合結果に基づいて評価を生成するために、私たちはELOレーティングシステムを基にランキングを作成することにしました。…
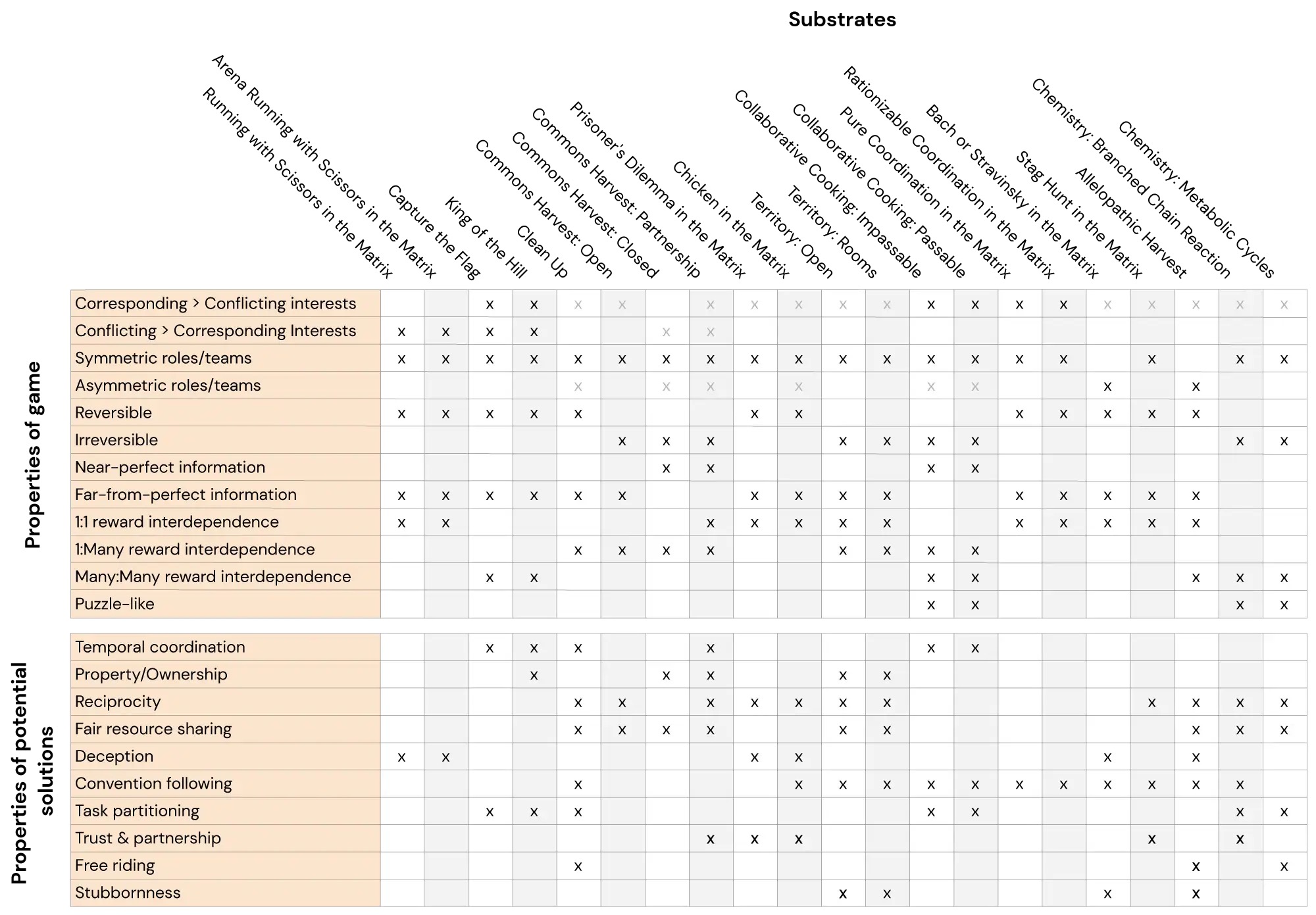
メルティングポット:マルチエージェント強化学習の評価スイート
ここでは、スケーラブルなマルチエージェント強化学習の評価スイートであるMelting Potを紹介しますMelting Potは、既知の個体と未知の個体の両方を含む新しい社会的状況への一般化を評価し、協力、競争、欺瞞、報復、信頼、頑固さなど、さまざまな社会的相互作用をテストするために設計されていますMelting Potは、研究者に21のMARL「基板」(マルチエージェントゲーム)でエージェントを訓練する機会を提供し、これらの訓練されたエージェントを評価するために85以上のユニークなテストシナリオを提供します

一般的に、オープンエンドの遊びから優れたエージェントが生まれる
近年、人工知能エージェントは複雑なゲーム環境で成功を収めています例えば、AlphaZeroは、プレイ方法の基本ルールを知らないままスタートし、チェス、将棋、囲碁の世界チャンピオンプログラムに勝利しました強化学習(RL)を通じて、この単一のシステムは、試行錯誤の反復的なプロセスを通じて、ゲームのラウンドごとにプレイすることで学習しましたしかし、AlphaZeroはまだ各ゲームごとに別々にトレーニングを行いましたRLのプロセスをゼロから繰り返さなければ、別のゲームやタスクを単純に学習することはできませんでしたAtari、Capture the Flag、StarCraft II、Dota 2、Hide-and-Seekなど、RLの他の成功も同様ですDeepMindの使命である科学と人類の進歩のための知能の解決策を見つけるために、私たちはこの制限を克服する方法を探求しました一度に1つのゲームを学習する代わりに、これらのエージェントは完全に新しい条件に反応し、見たこともないゲームやタスクを含む、さまざまなゲームやタスクをプレイできるようになるはずです
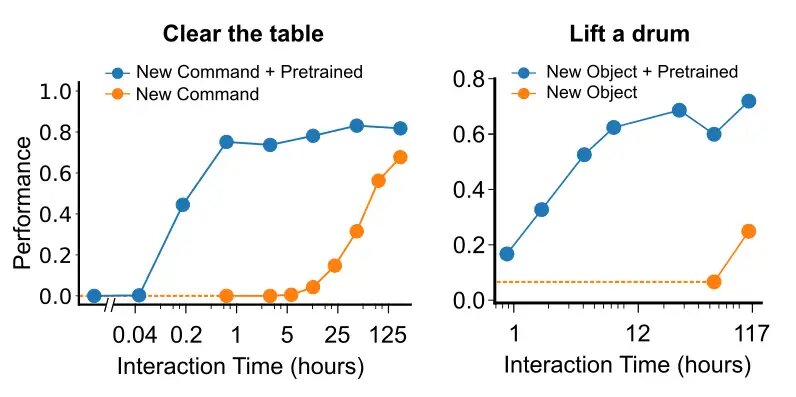
模倣学習を用いたインタラクティブエージェントの作成
私たちは、シミュレートされた世界での人間-人間の相互作用の模倣学習と自己教師あり学習の組み合わせによって、非敵対的な人間との対話に成功する多様なインタラクティブエージェント(MIAと呼ぶ)を生み出すことができることを示しますMIAは、非敵対的な人間との対話において75%の成功率を達成しますさらに、階層的なアクション選択などのアーキテクチャとアルゴリズムの技術を特定し、パフォーマンスを向上させることができます
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.