Learn more about Search Results アダプタ - Page 9

- You may be interested
- WhatsAppチャットで言語モデルを構築しま...
- 『nnU-Netの究極ガイド』
- 「リターンオファーを得る方法」 (リター...
- NMFを使用した製品の推薦
- ジャーナリズムでのAIの受容 – ニュ...
- 『LangChainを使用してテキストから辞書を...
- 神経刺激のための4Dプリント技術
- 「CNNにおけるアトラウス畳み込みの総合ガ...
- 「マイクロソフトに韻を踏む事件」
- 洞察を具体的な成果に変える
- データストーリーテリング – データ...
- データの汚染を防ぐためのサイバーセキュ...
- アルファベットは、遠隔地域でのインター...
- スケーリングダウン、スケーリングアップ...
- データ可視化のリニューアル:Pandasでの...
LLMのトレーニングの異なる方法
大規模言語モデル(LLM)の領域では、さまざまなトレーニングメカニズムがあり、異なる手段、要件、目標がありますそれぞれが異なる目的を果たすため、混同しないようにすることが重要です...

ReLoRa GPU上で大規模な言語モデルを事前学習する
ReLoRaは、各イテレーションごとにわずかな訓練可能なパラメータのみを活性化させながら、LoRaをリセットして事前学習を可能にする方法です

チューリッヒ大学の研究者たちは、スイスの4つの公用語向けの多言語言語モデルであるSwissBERTを開発しました
有名なBERTモデルは、最近の自然言語処理の主要な言語モデルの1つです。この言語モデルは、入力シーケンスを出力シーケンスに変換するいくつかのNLPタスクに適しています。BERT(Bidirectional Encoder Representations from Transformers)は、Transformerのアテンションメカニズムを使用しています。アテンションメカニズムは、テキストのコーパス内の単語やサブワード間の文脈的な関係を学習します。BERT言語モデルは、NLPの進歩の最も顕著な例の1つであり、自己教師あり学習の技術を使用しています。 BERTモデルを開発する前、言語モデルは訓練時にテキストシーケンスを左から右に解析したり、左から右および右から左の組み合わせで解析することがありました。この一方向のアプローチは、次の単語を予測してシーケンスに追加し、それを繰り返して完全な意味のある文を生成するためにうまく機能しました。BERTでは、双方向のトレーニングが導入され、以前の言語モデルと比較して言語の文脈と流れのより深い理解が得られました。 元々のBERTモデルは英語向けにリリースされました。その後、フランス語向けのCamemBERTやイタリア語向けのGilBERToなど、他の言語モデルが開発されました。最近、チューリッヒ大学の研究者チームがスイスのための多言語言語モデルを開発しました。SwissBERTと呼ばれるこのモデルは、スイス標準ドイツ語、フランス語、イタリア語、ロマンシュグリシュンで21,000万以上のスイスのニュース記事をトレーニングし、合計120億トークンでトレーニングされました。 SwissBERTは、スイスの研究者が多言語タスクを実行することができないという課題に対処するために導入されました。スイスは主に4つの公用語、ドイツ語、フランス語、イタリア語、ロマンシュ語を持っており、各言語ごとに個別の言語モデルを組み合わせて多言語タスクを実行することは困難です。また、第4の国語であるロマンシュ語のための独立したニューラル言語モデルはありません。NLPの分野では多言語タスクの実装がやや困難であるため、SwissBERTの前にスイスの国語のための統一されたモデルは存在しませんでした。SwissBERTは、これらの言語の記事を単純に組み合わせて、共通のエンティティとイベントを暗黙的に利用して多言語表現を作成することで、この課題を克服します。 SwissBERTモデルは、81の言語で共に事前トレーニングされたクロスリンガルモジュラープリトレーニング(X-MOD)トランスフォーマーからリモデルされました。研究者は、カスタム言語アダプタをトレーニングすることで、プリトレーニング済みのX-MODトランスフォーマーを自分たちのコーパスに適応させました。彼らはSwissBERTのためのスイス固有のサブワード語彙を作成し、その結果得られたモデルは総パラメータ数が1億5300万にもなります。 研究チームは、SwissBERTのパフォーマンスを様々なタスクで評価しました。これには、現代のニュース(SwissNER)での固有名詞の認識や、スイスの政治に関するユーザー生成コメントでの立場の検出などが含まれます。SwissBERTは、一般的なベースラインを上回り、XLM-Rに比べて立場の検出においても改善が見られました。また、ロマンシュ語でのモデルの能力を評価した結果、SwissBERTは、言語でトレーニングされていないモデルに比べて、ゼロショットのクロスリンガル転送やドイツ語-ロマンシュ語の単語や文の整列において優れたパフォーマンスを発揮しました。ただし、モデルは、歴史的なOCR処理されたニュースでの固有名詞の認識にはあまり優れていませんでした。 研究者は、SwissBERTをダウンストリームタスクのファインチューニングのための例と共に公開しました。このモデルは将来の研究や非営利目的においても有望です。さらなる適応により、ダウンストリームタスクはモデルの多言語性の恩恵を受けることができます。
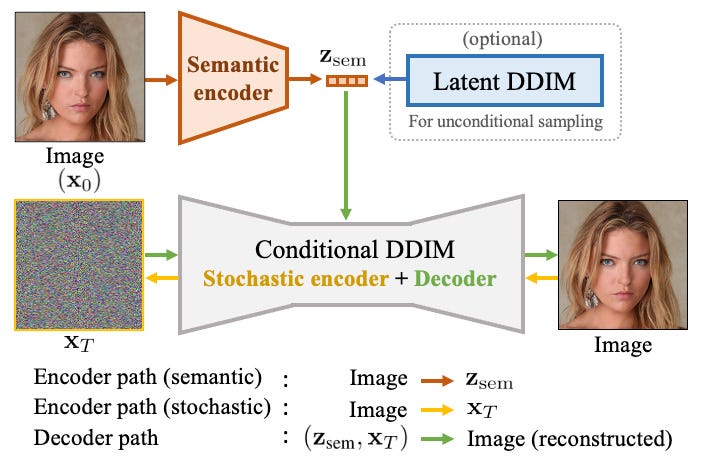
「DAE Talking 高忠実度音声駆動の話し相手生成における拡散オートエンコーダー」
今日は、新しい論文と、私が出会った中で最高品質の音声駆動ディープフェイクモデルについて話し合いますマイクロソフトリサーチから来たDAE-talkerは、個別の人物に特化したフルヘッドモデルです...

パラメータ効率の高いファインチューニングを使用する 🤗 PEFT
動機 トランスフォーマーアーキテクチャに基づく大規模言語モデル(LLM)であるGPT、T5、BERTなどは、さまざまな自然言語処理(NLP)タスクで最先端の結果を達成しています。これらのモデルは、コンピュータビジョン(CV)(VIT、Stable Diffusion、LayoutLM)やオーディオ(Whisper、XLS-R)などの他の領域にも進出しています。従来のパラダイムは、一般的なWebスケールのデータでの大規模な事前学習に続いて、ダウンストリームのタスクに対する微調整です。ダウンストリームのデータセットでこれらの事前学習済みLLMを微調整することで、事前学習済みLLMをそのまま使用する場合(ゼロショット推論など)と比較して、大幅な性能向上が得られます。 しかし、モデルが大きくなるにつれて、完全な微調整は一般的なハードウェアで訓練することが不可能になります。また、各ダウンストリームタスクごとに微調整済みモデルを独立して保存および展開することは非常に高コストです。なぜなら、微調整済みモデルのサイズは元の事前学習済みモデルと同じサイズだからです。パラメータ効率の良い微調整(PEFT)アプローチは、これらの問題に対処するために開発されました! PEFTアプローチは、事前学習済みLLMのほとんどのパラメータを凍結しながら、わずかな(追加の)モデルパラメータのみを微調整するため、計算およびストレージコストを大幅に削減します。これにより、LLMの完全な微調整中に観察される「壊滅的な忘却」という問題も克服されます。PEFTアプローチは、低データレジメでの微調整よりも優れた性能を示し、ドメイン外のシナリオにもより適応します。これは、画像分類や安定拡散ドリームブースなどのさまざまなモダリティに適用することができます。 また、PEFTアプローチは移植性にも役立ちます。ユーザーはPEFTメソッドを使用してモデルを微調整し、完全な微調整の大きなチェックポイントと比較して数MBの小さなチェックポイントを取得することができます。たとえば、「bigscience/mt0-xxl」は40GBのストレージを使用し、完全な微調整では各ダウンストリームデータセットに40GBのチェックポイントが生成されますが、PEFTメソッドを使用すると、各ダウンストリームデータセットにはわずか数MBのチェックポイントでありながら、完全な微調整と同等の性能が得られます。PEFTアプローチからの小さなトレーニング済み重みは、事前学習済みLLMの上に追加されます。そのため、モデル全体を置き換えることなく、小さな重みを追加することで同じLLMを複数のタスクに使用することができます。 つまり、PEFTアプローチは、わずかなトレーニング可能なパラメータの数だけで完全な微調整と同等のパフォーマンスを実現できるようにします。 本日は、🤗 PEFTライブラリをご紹介いたします。このライブラリは、最新のパラメータ効率の良い微調整技術を🤗 Transformersと🤗 Accelerateにシームレスに統合しています。これにより、Transformersの最も人気のあるモデルを使用し、Accelerateのシンプルさとスケーラビリティを活用することができます。以下は現在サポートされているPEFTメソッドですが、今後も追加される予定です: LoRA:LORA:大規模言語モデルの低ランク適応 Prefix Tuning:P-Tuning v2:プロンプトチューニングは、スケールとタスクにわたって完全な微調整と同等の性能を発揮することができます Prompt Tuning:パラメータ効率の良いプロンプトチューニングの力 P-Tuning:GPTも理解しています ユースケース ここでは多くの興味深いユースケースを探求しています。以下はいくつかの興味深い例です: Google Colabで、Nvidia GeForce RTX…

StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。 このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します: 教師あり微調整(SFT) 報酬/選好モデリング(RM) 人間のフィードバックからの強化学習(RLHF) From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human…

24GBのコンシューマーGPUでRLHFを使用して20B LLMを微調整する
私たちは、trlとpeftの統合を正式にリリースし、Reinforcement Learningを用いたLarge Language Model (LLM)のファインチューニングを誰でも簡単に利用できるようにしました!この投稿では、既存のファインチューニング手法と競合する代替手法である理由を説明します。 peftは一般的なツールであり、多くのMLユースケースに適用できますが、特にメモリを多く必要とするRLHFにとって興味深いです! コードに直接深く入りたい場合は、TRLのドキュメンテーションページで直接例のスクリプトをチェックしてください。 イントロダクション LLMとRLHF 言語モデルとRLHF(Reinforcement Learning with Human Feedback)を組み合わせることは、ChatGPTなどの非常に強力なAIシステムを構築するための次の手段として注目されています。 RLHFを用いた言語モデルのトレーニングは、通常以下の3つのステップを含みます: 1- 特定のドメインまたは命令のコーパスで事前学習されたLLMをファインチューニングする 2- 人間によって注釈付けされたデータセットを収集し、報酬モデルをトレーニングする 3- ステップ1で得られたLLMを報酬モデルとデータセットを用いてRL(例:PPO)でさらにファインチューニングする ここで、ベースとなるLLMの選択は非常に重要です。現時点では、多くのタスクに直接使用できる「最も優れた」オープンソースのLLMは、命令にファインチューニングされたLLMです。有名なモデルとしては、BLOOMZ、Flan-T5、Flan-UL2、OPT-IMLなどがあります。これらのモデルの欠点は、そのサイズです。まともなモデルを得るには、少なくとも10B+スケールのモデルを使用する必要がありますが、モデルを単一のGPUデバイスに合わせるだけでも40GBのGPUメモリが必要です。 TRLとは何ですか? trlライブラリは、カスタムデータセットとトレーニングセットアップを使用して、誰でも簡単に自分のLMをRLでファインチューニングできるようにすることを目指しています。他の多くのアプリケーションの中で、このアルゴリズムを使用して、ポジティブな映画のレビューを生成するモデルをファインチューニングしたり、制御された生成を行ったり、モデルをより毒性のないものにしたりすることができます。…

bitsandbytes、4ビットの量子化、そしてQLoRAを使用して、LLMをさらに利用しやすくする
LLMは大きいことで知られており、一般のハードウェア上で実行またはトレーニングすることは、ユーザーにとって大きな課題であり、アクセシビリティも困難です。私たちのLLM.int8ブログポストでは、LLM.int8論文の技術がtransformersでどのように統合され、bitsandbytesライブラリを使用しているかを示しています。私たちは、モデルをより多くの人々にアクセス可能にするために、再びbitsandbytesと協力することを決定し、ユーザーが4ビット精度でモデルを実行できるようにしました。これには、テキスト、ビジョン、マルチモーダルなどの異なるモダリティの多くのHFモデルが含まれます。ユーザーはまた、Hugging Faceのエコシステムからのツールを活用して4ビットモデルの上にアダプタをトレーニングすることもできます。これは、DettmersらによるQLoRA論文で今日紹介された新しい手法です。論文の概要は以下の通りです: QLoRAは、1つの48GBのGPUで65Bパラメータモデルをフィントゥーニングするためのメモリ使用量を十分に削減しながら、完全な16ビットのフィントゥーニングタスクのパフォーマンスを維持する効率的なフィントゥーニングアプローチです。QLoRAは、凍結された4ビット量子化された事前学習言語モデルをLow Rank Adapters(LoRA)に逆伝搬させます。私たちの最高のモデルファミリーであるGuanacoは、Vicunaベンチマークで以前に公開されたすべてのモデルを上回り、ChatGPTのパフォーマンスレベルの99.3%に達しますが、1つのGPUでのフィントゥーニングには24時間しかかかりません。QLoRAは、パフォーマンスを犠牲にすることなくメモリを節約するためのいくつかの革新を導入しています:(a)通常分布された重みに対して情報理論的に最適な新しいデータ型である4ビットNormalFloat(NF4)(b)量子化定数を量子化して平均メモリフットプリントを減らすためのダブル量子化、および(c)メモリスパイクを管理するためのページドオプティマイザ。私たちはQLoRAを使用して1,000以上のモデルをフィントゥーニングし、高品質のデータセットを使用した指示の追跡とチャットボットのパフォーマンスの詳細な分析を提供しています。これは通常のフィントゥーニングでは実行不可能である(例えば33Bおよび65Bパラメータモデル)モデルタイプ(LLaMA、T5)とモデルスケールを横断したものです。私たちの結果は、QLoRAによる小規模な高品質データセットでのフィントゥーニングが、以前のSoTAよりも小さいモデルを使用しても最先端の結果をもたらすことを示しています。さらに、ヒューマンとGPT-4の評価に基づいてチャットボットのパフォーマンスの詳細な分析を提供し、GPT-4の評価がヒューマンの評価に対して安価で合理的な代替手段であることを示しています。さらに、現在のチャットボットのベンチマークは、チャットボットのパフォーマンスレベルを正確に評価するための信頼性がないことがわかります。レモンピックされた分析では、GuanacoがChatGPTに比べてどこで失敗するかを示しています。私たちは4ビットトレーニングのためのCUDAカーネルを含む、すべてのモデルとコードを公開しています。 リソース このブログポストとリリースには、4ビットモデルとQLoRAを始めるためのいくつかのリソースがあります: 元の論文 基本的な使用法Google Colabノートブック-このノートブックでは、4ビットモデルとその変種を使用した推論の方法、およびGoogle ColabインスタンスでGPT-neo-X(20Bパラメータモデル)を実行する方法を示しています。 フィントゥーニングGoogle Colabノートブック-このノートブックでは、Hugging Faceエコシステムを使用してダウンストリームタスクで4ビットモデルをフィントゥーニングする方法を示しています。Google ColabインスタンスでGPT-neo-X 20Bをフィントゥーニングすることが可能であることを示しています。 論文の結果を再現するための元のリポジトリ Guanaco 33b playground-または以下のプレイグラウンドセクションをチェック はじめに モデルの精度と最も一般的なデータ型(float16、float32、bfloat16、int8)について詳しく知りたくない場合は、これらの概念の詳細について視覚化を含めた簡単な言葉で説明している私たちの最初のブログポストの紹介を注意深くお読みいただくことをお勧めします。 詳細については、このwikibookドキュメントを通じて浮動小数点表現の基本を読むことをお勧めします。 最近のQLoRA論文では、4ビットFloatと4ビットNormalFloatという異なるデータ型を探求しています。ここでは、理解しやすい4ビットFloatデータ型について説明します。…

ファルコンはHugging Faceのエコシステムに着陸しました
イントロダクション ファルコンは、アブダビのテクノロジーイノベーション研究所が作成し、Apache 2.0ライセンスの下で公開された最新の言語モデルの新しいファミリーです。 特筆すべきは、Falcon-40Bが多くの現在のクローズドソースモデルと同等の機能を持つ、初めての「真にオープンな」モデルであることです 。これは、開発者、愛好家、産業界にとって素晴らしいニュースであり、多くのエキサイティングなユースケースの扉を開くものです。 このブログでは、ファルコンモデルについて詳しく調査し、まずそれらがどのようにユニークであるかを説明し、その後、Hugging Faceのエコシステムのツールを使ってそれらの上に構築することがどれほど簡単かを紹介します。 目次 ファルコンモデル デモ 推論 評価 PEFTによるファインチューニング 結論 ファルコンモデル ファルコンファミリーは、2つのベースモデルで構成されています:Falcon-40Bとその弟であるFalcon-7Bです。 40Bパラメータモデルは現在、Open LLM Leaderboardのトップを占めており、7Bモデルはそのクラスで最高のモデルです 。 Falcon-40BはGPUメモリを約90GB必要としますが、それでもLLaMA-65Bよりは少なく、Falconはそれを上回します。一方、Falcon-7Bは約15GBしか必要とせず、推論やファインチューニングは一般的なハードウェアでも利用可能です。 (このブログの後半では、より安価なGPUでもFalcon-40Bを利用できるように、量子化を活用する方法について説明します!) TIIはまた、モデルのInstructバージョンであるFalcon-7B-InstructとFalcon-40B-Instructを提供しています。これらの実験的なバリアントは、命令と会話データに適応された調整が行われているため、人気のあるアシスタントスタイルのタスクに適しています。 モデルを素早く試してみたい場合は、これらが最適な選択肢です。…

MLモデルのトレーニングパイプラインの構築方法
手を挙げてください、もしもあなたがごちゃ混ぜのスクリプトをほどくのに時間を無駄にしたことがあるか、またはそう難解なバグを修正しようとしている間に幽霊を追いかけているような気持ちになったことがあるかそしてその間にモデルの訓練が永遠にかかっているという状況も経験したことがあるかもしれません私たちは皆、そんな経験をしたことがあるはずですよね?でも今、別のシナリオを思い浮かべてくださいきれいなコード効率的なワークフロー効率的なモデルの訓練信じられないほど素晴らしい光景ですよね…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.