Learn more about Search Results こちらの - Page 9

- You may be interested
- キュービットマジック:量子コンピューテ...
- 正確にピークと谷を検出するためのステッ...
- 「固有表現とニュース」
- 「なぜ自宅でPythonを使って10億桁の円周...
- コグVLM、革命的なマルチモーダルモデルで...
- 幸運なことに、「The Day Before」はGeFor...
- 「GenAI-Infused ChatGPT 有効なプロンプ...
- パーキンソン病を抱える男性が、脊髄イン...
- 安全で信頼性の高い自動操縦飛行への一歩
- 効率的で安定した拡散微調整のためのLoRA...
- 「MicrosoftとKPMGが20億ドルのAIパートナ...
- 「Ai X ビジネスおよびイノベーションサミ...
- エグゼクティブアーキテクトのFinOpsへの...
- UCLAとCMUの研究者が、優れた中程度範囲の...
- メタAIは、リアルタイムに高品質の再照明...

「2023年に機械学習とコンピュータビジョンの進歩について最新情報を入手する方法」
学界や産業界で実践している機械学習やコンピュータビジョンの最近の進展に圧倒されていますか?YouTubeチャンネル、ニュースレター、ポッドキャスト、プラットフォームなどを知っていますか?
「OpenAIとLangchainを使用した言語的なメール作成Webアプリケーション」
はじめに この記事では、Langchainの助けを借りてOpenAIを使用してウェブアプリケーションを構築する方法について説明します。このウェブアプリは、ユーザーが非構造化のメールを正しくフォーマットされた英語に変換することができます。ユーザーはメールのテキストを入力し、希望するトーンと方言(フォーマル/インフォーマルおよびアメリカン/ブリティッシュイングリッシュ)を指定することができます。アプリは選択したスタイルで美しくフォーマットされたメールを提供します。私たちは毎回スケールアプリケーションを構築することはできません。クエリとともにプロンプトをコピーして貼り付けるだけではありません。代わりに、さあ始めましょう、そしてこの素晴らしい「Professional Email Writer」ツールを構築しましょう。 学習目標 Streamlitを使用して美しいウェブアプリケーションを構築する方法を学ぶ。 プロンプトエンジニアリングとは何か、メールの生成に効果的なプロンプトを作成する方法を理解する。 LangchainのPromptTemplateを使用してOpenAI LLMをクエリする方法を学ぶ。 Streamlitを使用してPythonアプリケーションをデプロイする方法を学ぶ。 この記事はData Science Blogathonの一部として公開されました。 Streamlitのセットアップ まず、Streamlitが何であるか、どのように機能するか、そしてユースケースに設定する方法を理解する必要があります。Streamlitを使用すると、Pythonでウェブアプリケーションを作成し、ローカルおよびWeb上でホストすることができます。まず、ターミナルに移動し、以下のコマンドを使用してStreamlitをインストールします。 pip install streamlit スクリプト用の空のPythonファイルを作成し、以下のコマンドを使用してファイルを実行します。 python -m streamlit run [your_file_name.py]…
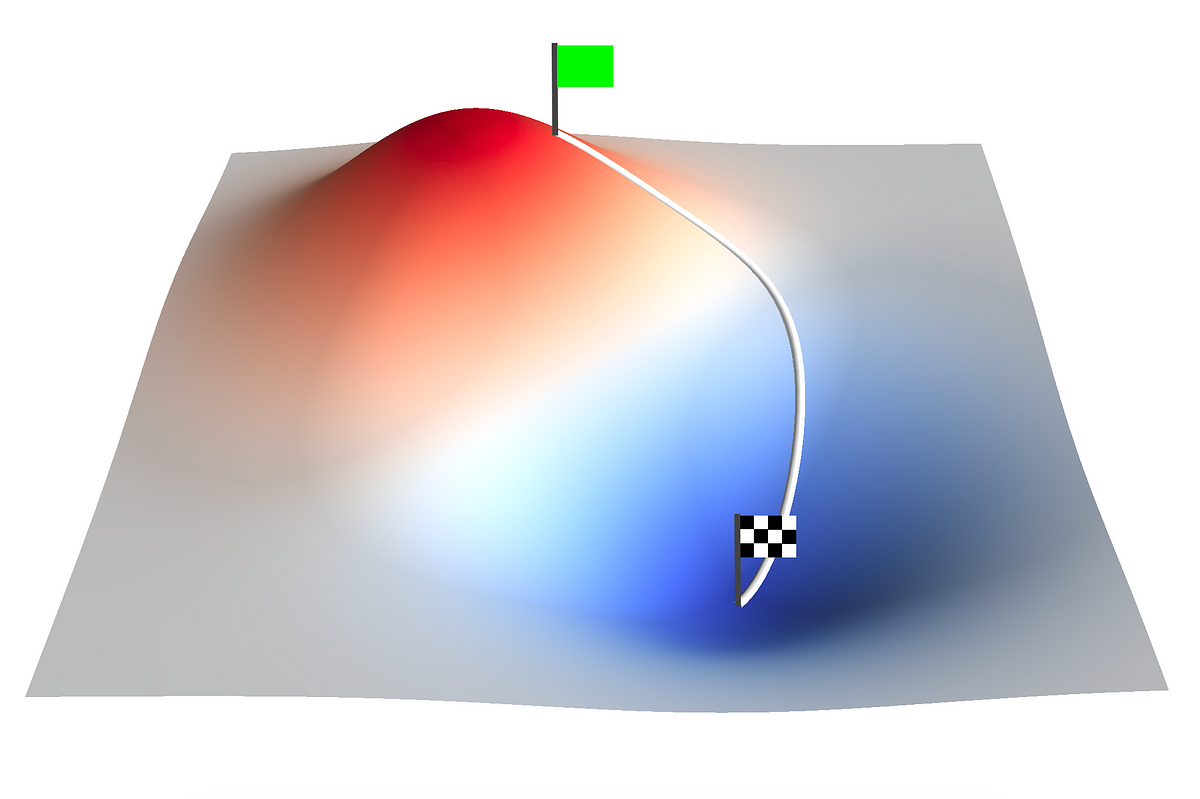
PIDコントローラの最適化:勾配降下法のアプローチ
「機械学習ディープラーニングAIこれらの技術を日々利用する人々がますます増えていますこれは、ChatGPTやBardなどによって展開された大規模言語モデルの台頭によって大いに推進されています...」
ChatGPTにおけるCSVファイルのクエリパフォーマンス向上
洗練された言語モデル(例:ChatGPT)の出現により、表形式のデータへのクエリの新しい有望なアプローチがもたらされましたしかし、トークンの制限により、クエリを直接実行することができません...
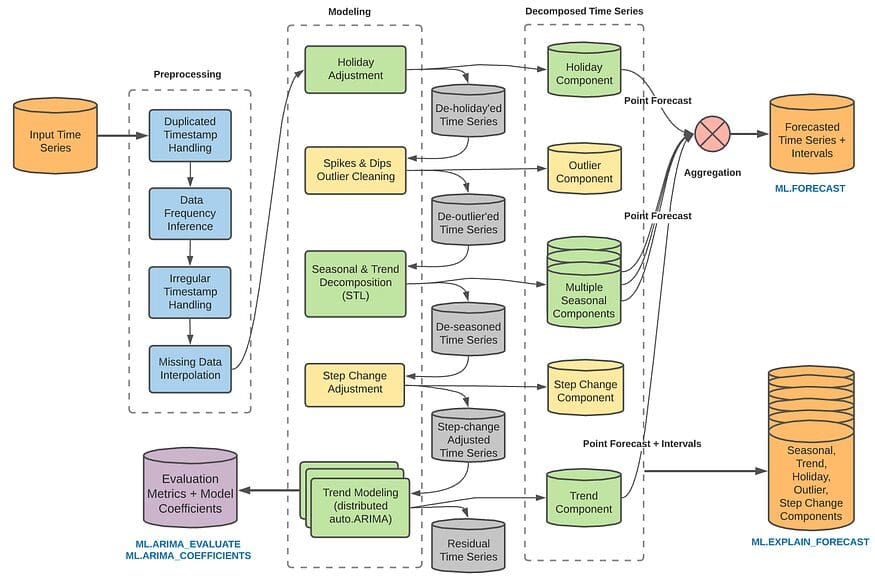
BQMLを使用した多変量時系列予測
GoogleのBQMLは、時系列モデルを作成するために使用することができます最近、マルチバリエート時系列モデルを作成するためにアップデートされましたこの記事では、シンプルなコードを使用してマルチバリエート時系列の予測方法を紹介し、単変量時系列モデルよりも強力な性能を発揮することができます
「Scikit-Learnクラスを使用したカスタムトランスフォーマを作成するためのシンプルなアプローチ」
データの前処理はデータサイエンスのライフサイクルで最も重要なステップの一つです非常に人気のある機械学習ライブラリであるScikit-Learnは、私たちをサポートするための多くの定義済みのトランスフォーマーを持っています
NLPの探究- NLPの立ち上げ(ステップ#2)を探る
最近、面接の一環として、2つの質問を探求するよう求められ、その過程で新しい概念を学びました以下に、2つの質問に対する私の解答を記載しますデータにはラベルが付いています...

NLPの探求 – NLPのキックスタート(ステップ#3)
「以下は、特に単語の埋め込みについて、私が週間で学んだいくつかの概念です実際に手を動かして試してみましたので、その一部を近々シリーズとして共有します!ここで、サチン氏に感謝を述べたいと思います...」

NLPの探求- NLPのキックスタート(ステップ#4)
お帰りなさい!シリーズを続けて、今回は(主に)POSタギングについてのメモを共有します特に、CENのサチン・クマール・S氏(アムリタ・コインバトール)に感謝したいと思います...

AI ポリシー @🤗 EU AI Act におけるオープンな機械学習の考慮事項
機械学習の皆様と同様に、Hugging FaceでもEU AI Actに注目しています。これは画期的な法律であり、民主的な要素がAI技術開発との相互作用をどのように形成するかを世界中に広めるものです。また、社会のさまざまな要素を代表する組織との広範な協議と作業の結果でもあります。私たちはコミュニティ主導の企業として、このプロセスに特に敏感に取り組んでいます。このポジションペーパーでは、Creative Commons、Eleuther AI、GitHub、LAION、Open Futureとの連携により、オープンなML開発の必要性が法律の目標をサポートする方法についての私たちの経験を共有し、逆に、規制がオープンでモジュラーで協力的なML開発のニーズをより適切に考慮するための具体的な方法を示すことを目指しています。 Hugging Faceは、開発者コミュニティのおかげで今日の地位にあります。そのため、オープンな開発がもたらす効果を直接目にしてきました。より堅牢なイノベーションをサポートし、より多様でコンテキストに応じたユースケースを可能にする場所です。開発者は革新的な新しい技術を簡単に共有し、自分のニーズに合わせてMLコンポーネントを組み合わせ、スタック全体について完全な可視性を持って信頼性のある作業ができます。また、技術の透明性がより責任ある取り組みと包括性をサポートする上での必要な役割にも痛感しており、MLアーティファクトの文書化とアクセシビリティの改善、教育活動、大規模な多学科のコラボレーションのホスティングなどを通じてこれを促進してきました。そのため、EU AI Actが最終段階に向かうにつれて、MLシステムのオープンかつオープンソースな開発の特定のニーズと強みを考慮することが、その長期的な目標をサポートする上で重要になると考えています。共同署名したパートナー組織と共に、以下の5つの推奨事項を提案します: AIコンポーネントを明確に定義すること オープンソースのAIコンポーネントの共同開発とパブリックリポジトリでの公開は、開発者をAI Actの要件の対象としないことを明確にすること(パーラメントの文章のRecitals 12a-cとArticle 2(5e)を基に改善すること) AIオフィスの調整と包括的なガバナンスをオープンソースエコシステムと連携させること(パーラメントの文章を基に改善すること) 研究開発の例外が実用的かつ効果的であることを確保すること。現実世界の条件での限定的なテストを許可し、理事会の取り組みの一部とパーラメントのArticle 2(5d)の改訂版を組み合わせること 「基礎モデル」に対して比例の要件を設定すること。異なる使用方法と開発モダリティを明確に区別し、オープンソースアプローチを含めること。パーラメントのArticle 28bを適用すること これらについての詳細と文脈は、こちらの全文をご覧ください!
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.