Learn more about Search Results お知らせ - Page 9

- You may be interested
- 「コントロールされたフェード」
- HuggingFaceはTextEnvironmentsを紹介しま...
- 「A.I.ブームで最も不可欠な賞を必死に追...
- テーブルの6つの高度な可視化
- AIがVRデバイスのユーザーエクスペリエン...
- 「LAMPをご紹介します:テキストからイメ...
- 「2023年に就職するために必要な10のビッ...
- モデルマージングとは、複数のモデルを統...
- Google AIは、スケールで事前に訓練された...
- 「Synthesysレビュー:最高のAIビデオジェ...
- 「AWSに基づいたカスケーディングデータパ...
- 「LangChainが評価しようとしている6つのL...
- 「CityDreamerと出会う:無限の3D都市のた...
- 最高のAIジョブコース(2023年)
- 「見逃すな!2023年が終わる前に無料のコ...

PythonとDashを使用してダッシュボードを作成する
この記事では、PythonとDashを使用してNetflixのダッシュボードを構築し、地図、グラフ、チャートを使用してコンテンツの配信と分類を視覚化する方法について説明しています

「Amazon SageMaker プロファイラーのプレビューを発表します:モデルトレーニングのワークロードの詳細なハードウェアパフォーマンスデータを追跡および可視化します」
本日は、Amazon SageMaker Profilerのプレビューを発表できることを喜んでお知らせしますこれはAmazon SageMakerの機能の一部であり、SageMaker上でディープラーニングモデルのトレーニング中にプロビジョニングされるAWSのコンピューティングリソースの詳細なビューを提供しますSageMaker Profilerを使用すると、CPUとGPUのすべてのアクティビティをトラックできますCPUとGPUの利用率、GPU上でのカーネルの実行、CPU上でのカーネルの起動、同期操作、GPU間のメモリ操作、カーネルの起動と対応する実行とのレイテンシ、CPUとGPU間のデータ転送などが含まれますこの記事では、SageMaker Profilerの機能について詳しく説明します
非常に大きなデータセットのランダム化
最近では、サイズがギガバイト、あるいはテラバイトで測定されるデータセットを見つけることはまったく珍しくありませんそのような大量のデータは、頑健な機械学習モデルを作るためのトレーニングプロセスに非常に役立ちます...
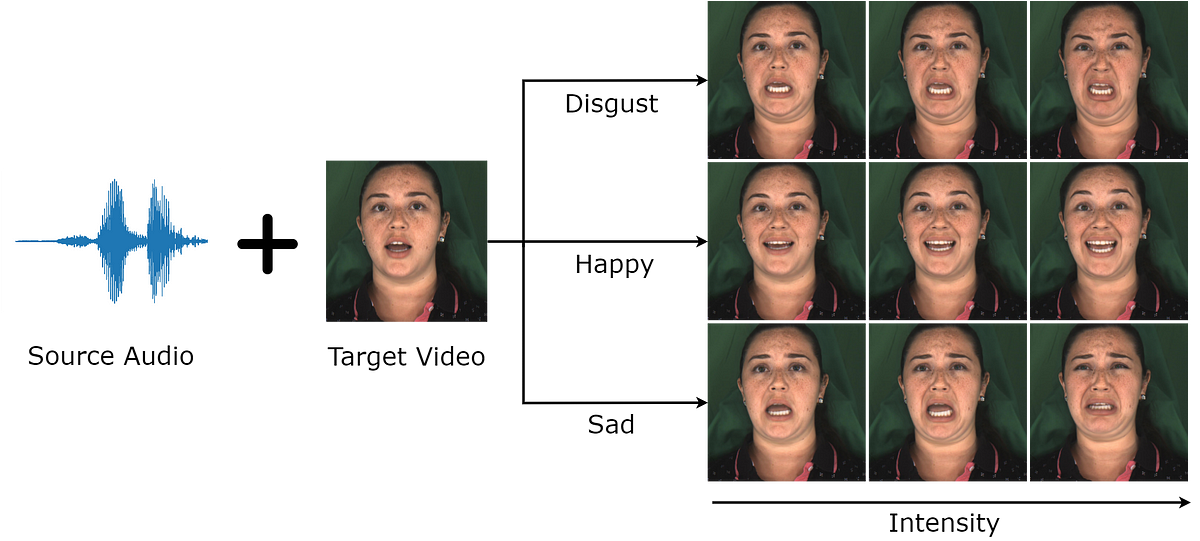
「読むアバター:リアルな感情制御可能な音声駆動のアバター」
「既存の音声駆動型のディープフェイクの重要な制約の1つは、スタイル属性をより制御できる能力の必要性です理想的には、これらの側面を変えたいと思います例えば、…」

埋め込みの視覚化
「私は1990年に初めてAIの論文を地元の小さなカンファレンスである「ミッドウエスト人工知能・認知科学協会」に提出しました当時のAIの分野は完全に...」

「データサイエンティストには試してみるべきジェンAIプロンプト」
「データサイエンティストのためのGen AIの力を探求する以下には、データサイエンティストを支援するためのいくつかの必須のGen AIプロンプトがあります」

Databricks ❤️ Hugging Face 大規模言語モデルのトレーニングとチューニングが最大40%高速化されました
生成AIは世界中で大きな注目を集めています。データとAIの会社として、私たちはオープンソースの大規模言語モデルDollyのリリース、およびそれを微調整するために使用した研究および商用利用のための内部クラウドソーシングデータセットであるdatabricks-dolly-15kのリリースと共にこの旅に参加してきました。モデルとデータセットはHugging Faceで利用可能です。このプロセスを通じて多くのことを学びましたが、今日はApache Spark™のデータフレームから簡単にHugging Faceデータセットを作成できるようにするHugging Faceコードベースへの初めての公式コミットの1つを発表することを喜んでお知らせします。 「Databricksがモデルとデータセットをコミュニティにリリースしてくれたのを見るのは素晴らしいことでしたが、それをHugging Faceへの直接のオープンソースコミットメントにまで拡張しているのを見るのはさらに素晴らしいことです。Sparkは、大規模なデータでの作業に最も効率的なエンジンの1つであり、その技術を使用してHugging Faceのモデルをより効果的に微調整できるようになったユーザーを見るのは素晴らしいことです。」 — Clem Delange、Hugging Face CEO Hugging Faceが一流のSparkサポートを受ける 過去数週間、ユーザーから、SparkのデータフレームをHugging Faceデータセットに簡単にロードする方法を求める多くのリクエストを受け取りました。今日のリリースよりも前は、SparkのデータフレームからHugging Faceデータセットにデータを取得するために、データをParquetファイルに書き込み、それからHugging Faceデータセットをこれらのファイルに指定して再ロードする必要がありました。たとえば: from datasets import load_dataset train_df…

セーフコーダーを紹介します
今日は、エンタープライズ向けのコードアシスタントソリューションであるSafeCoderの発表をお知らせいたします。 SafeCoderの目標は、エンタープライズ向けに完全に準拠し、自己ホスト型のペアプログラマーを提供することで、ソフトウェア開発の生産性を向上させることです。マーケティングの言葉で言えば、「独自のオンプレミスGitHub Copilot」です。 さらに詳しく見ていく前に、以下のことを知っておく必要があります: SafeCoderはモデルではなく、完全なエンドツーエンドの商用ソリューションです SafeCoderはセキュリティとプライバシーを中心に設計されており、トレーニングや推論中にコードがVPCから出ることはありません SafeCoderは、顧客が独自のインフラストラクチャ上で自己ホストすることを前提としています SafeCoderは、顧客が独自のCode Large Language Modelを所有することを目指して設計されています SafeCoderの利点は何ですか? GitHub CopilotなどのLLMを活用したコードアシスタントソリューションは、生産性の向上に大きく貢献しています。エンタープライズでは、企業のコードベースに合わせてCode LLMを調整し、独自のCode LLMを作成することで、補完の信頼性と関連性を向上させ、さらなる生産性の向上を実現できます。例えば、Googleの内部LLMコードアシスタントは、内部のコードベースをトレーニングデータとして学習することで、25-34%の補完受け入れ率を報告しています。 しかし、クローズドソースのCode LLMを利用して内部のコードアシスタントを作成することは、コンプライアンスとセキュリティの問題につながります。トレーニング中には、クローズドソースのCode LLMを内部のコードベースに微調整するために、このコードベースを第三者に公開する必要があります。そして、推論中には、微調整されたCode LLMがトレーニングデータセットからコードを「漏洩」させる可能性があります。コンプライアンス要件を満たすためには、企業は自社のインフラストラクチャ内で微調整されたCode LLMを展開する必要がありますが、クローズドソースのLLMではそれは不可能です。 Hugging Faceでは、SafeCoderによって顧客が独自のCode LLMを構築できるようになります。最新のオープンソースモデルとライブラリを使用して、独自のコードベースに微調整されたCode…

「IDEFICSをご紹介します:最新の視覚言語モデルのオープンな再現」
私たちは、IDEFICS(Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS)をリリースすることを喜んでいます。IDEFICSは、Flamingoに基づいたオープンアクセスのビジュアル言語モデルです。FlamingoはDeepMindによって開発された最先端のビジュアル言語モデルであり、公開されていません。GPT-4と同様に、このモデルは画像とテキストの任意のシーケンスを受け入れ、テキストの出力を生成します。IDEFICSは、公開されているデータとモデル(LLaMA v1およびOpenCLIP)のみを使用して構築されており、ベースバージョンと指示付きバージョンの2つのバリアントが9,000,000,000および80,000,000,000のパラメーターサイズで利用可能です。 最先端のAIモデルの開発はより透明性を持つべきです。IDEFICSの目標は、Flamingoのような大規模な専有モデルの能力に匹敵するシステムを再現し、AIコミュニティに提供することです。そのために、これらのAIシステムに透明性をもたらすために重要なステップを踏みました。公開されているデータのみを使用し、トレーニングデータセットを探索するためのツールを提供し、このようなアーティファクトの構築における技術的な教訓とミスを共有し、リリース前に敵対的なプロンプトを使用してモデルの有害性を評価しました。IDEFICSは、マルチモーダルAIシステムのよりオープンな研究のための堅固な基盤として機能することを期待しています。また、9,000,000,000のパラメータースケールでのFlamingoの別のオープン再現であるOpenFlamingoなどのモデルと並んでいます。 デモとモデルをハブで試してみてください! IDEFICSとは何ですか? IDEFICSは、80,000,000,000のパラメーターを持つマルチモーダルモデルであり、画像とテキストのシーケンスを入力とし、一貫したテキストを出力します。画像に関する質問に答えることができ、視覚的なコンテンツを説明し、複数の画像に基づいて物語を作成することができます。 IDEFICSは、Flamingoのオープンアクセス再現であり、さまざまな画像テキスト理解ベンチマークで元のクローズドソースモデルと同等のパフォーマンスを発揮します。80,000,000,000および9,000,000,000のパラメーターの2つのバリアントがあります。 会話型の使用事例に適した、idefics-80B-instructとidefics-9B-instructのファインチューニングバージョンも提供しています。 トレーニングデータ IDEFICSは、Wikipedia、Public Multimodal Dataset、LAION、および新しい115BトークンのデータセットであるOBELICSのオープンデータセットの混合物でトレーニングされました。OBELICSは、ウェブからスクレイプされた141,000,000の交互に配置された画像テキストドキュメントで構成され、353,000,000の画像を含んでいます。 OBELICSの内容をNomic AIで探索できるインタラクティブな可視化も提供しています。 IDEFICSのアーキテクチャ、トレーニング方法論、評価、およびデータセットに関する詳細は、モデルカードと研究論文で入手できます。さらに、モデルのトレーニングから得られた技術的な洞察と学びを文書化しており、IDEFICSの開発に関する貴重な見解を提供しています。 倫理的評価…

この秋登場予定:NVIDIA DLSS 3.5 が Chaos Vantage、D5 Render、Omniverse、そして人気のあるゲームタイトルに対応します
エディターの注:この投稿は、弊社の週刊「NVIDIA Studio」シリーズの一部であり、注目のアーティストを称え、クリエイティブなヒントやトリックを提供し、NVIDIA Studioテクノロジーがクリエイティブなワークフローを向上させる方法を示しています。また、新しいGeForce RTX 40シリーズGPUの機能、技術、リソースについて詳しく掘り下げ、コンテンツ作成を劇的に加速する方法も説明しています。 年間最大のゲームイベントであるGamescomが明日ドイツのケルンで開催されますが、ゲーマーやコンテンツクリエイターは、今週NVIDIA Studioで最新のイノベーション、ツール、AIパワードテクノロジーを見つけることができます。 公式オープンの前夜に、NVIDIAは、リアルタイムの3Dクリエイティブアプリやゲームにおいて、従来のレンダリング方法よりも美しくリアルなレイトレーシングビジュアルを作成する新しいニューラルレンダリングAIモデルである「NVIDIA DLSS 3.5 featurning Ray Reconstruction」を発表しました。 NVIDIA Omniverse上に構築された無料のモディングプラットフォームである「NVIDIA RTX Remix」は、古典的なゲームのための#RTXONモッズを作成して共有するためのツールを提供します。また、私たちはValveのハイレーティングゲームである「Half-Life 2」のコミュニティリマスタープロジェクトである「Half-Life 2 RTX: An RTX Remix Project」も発表しました。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.