Learn more about Search Results OPT - Page 96

- You may be interested
- 人工知能の台頭に備えるために、高校生を...
- セールスフォース・アインシュタイン:あ...
- PolarsによるEDA:Pandasユーザーのための...
- コーネル大学がChatGPTの中核に巨大な脅威...
- チャットアプリのLLMを比較する:LLaMA v2...
- ビジネスにおけるAIパワードのテキストメ...
- テキストデータの創造的で時折乱雑な世界&...
- StarCoder:コードのための最先端のLLM
- シンガポール国立大学の研究者が提案するM...
- 「マスク言語モデリングタスクのBERTトレ...
- フリーMITコース:TinyMLと効率的なディー...
- 「設定パラメータを使用して、ChatGPTの出...
- 「データ駆動方程式発見について」という...
- 「2024年にデータサイエンティストになる...
- マイクロソフトの研究者が、言語AIを活用...
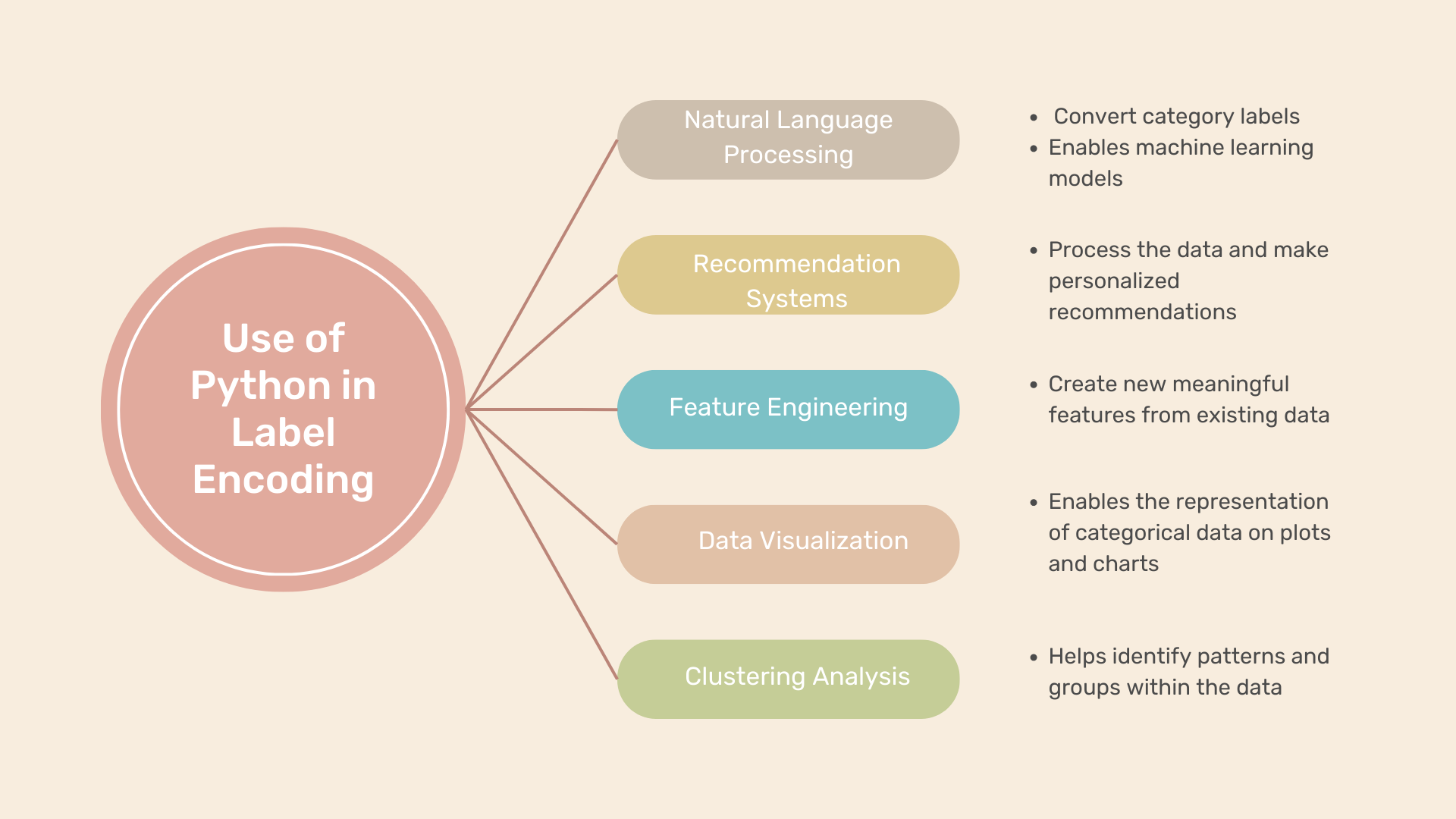
「Pythonでのラベルエンコーディングの実行方法」
データ分析や機械学習では、しばしばカテゴリカル変数を含むデータセットに遭遇します。これらの変数は数値ではなく、質的属性を表します。しかし、多くの機械学習アルゴリズムでは数値の入力が必要です。ここでラベルエンコーディングが重要な役割を果たします。カテゴリデータを数値のラベルに変換することで、ラベルエンコーディングはさまざまなアルゴリズムで使用することができます。この投稿では、ラベルエンコーディングの説明と、Pythonでの応用例、そして人気のあるsci-kit-learnモジュールを使用したラベルエンコーディングの適用方法の例を示します。 Pythonにおけるラベルエンコーディングとは何ですか? Pythonでは、カテゴリカル変数をラベルエンコーディング技術を使用して数値のラベルに変換することができます。これにより、機械学習アルゴリズムがデータを効果的に解釈して分析することができます。ラベルエンコーディングの関数の使い方を学ぶために、いくつかの例を見てみましょう。 Pythonでのラベルエンコーディングの例 例1:顧客セグメンテーション 顧客セグメンテーションのデータセットを想定してみましょう。このデータセットには、顧客の人口統計的特徴に関するデータが含まれています。「性別」、「年齢層」、「婚姻状況」などの変数があります。これらの変数内の各カテゴリに複数のラベルを付けることで、ラベルエンコーディングを実行することができます。例えば: カテゴリカル変数にラベルエンコーディングを適用することで、顧客セグメンテーション分析に適した数値形式でデータを表現することができます。 例2:製品カテゴリ 製品カテゴリのデータセットを考えてみましょう。このデータセットには、「製品名」や「カテゴリ」などの変数が含まれています。ラベルエンコーディングを行うために、各カテゴリに数値のラベルを割り当てます: ラベルエンコーディングにより、製品カテゴリを数値のラベルで表現することができます。これにより、さらなる分析やモデリングのタスクが可能になります。 例3:感情分析 感情分析のデータセットでは、「感情」という変数があります。この変数は、テキストドキュメントに関連付けられた感情(例:positive、negative、neutral)を表します。この変数にラベルエンコーディングを適用することで、各感情カテゴリに数値のラベルを割り当てることができます: ラベルエンコーディングにより、感情カテゴリを数値のラベルに変換することができます。これにより、感情分析のタスクをより簡単に実行することができます。 これらの例は、ラベルエンコーディングが異なるデータセットと変数に適用され、カテゴリ情報を数値のラベルに変換することで、さまざまな分析および機械学習のタスクを可能にすることを示しています。 Pythonでのラベルエンコーディングの使用例 ラベルエンコーディングは、カテゴリデータを扱う際にさまざまなシナリオで使用することができます。以下にいくつかの例を示します: 自然言語処理(NLP): ラベルエンコーディングは、テキストの分類や感情分析などのNLPアプリケーションで、positive、negative、neutralなどのカテゴリラベルを数値表現に変換することができます。これにより、機械学習モデルがテキストデータを正しく理解して分析することができます。 レコメンデーションシステム: レコメンデーションシステムでは、ユーザの好みやアイテムのカテゴリを表すためにカテゴリカル変数を使用することがよくあります。これらの変数にラベルエンコーディングを行うことで、レコメンデーションアルゴリズムはデータを処理し、ユーザの好みに基づいて個別の推薦を行うことができます。 特徴エンジニアリング: ラベルエンコーディングは特徴エンジニアリングの重要なステップです。ここでは既存のデータから新しい意味のある特徴を作成します。カテゴリカル変数を数値のラベルにエンコードすることで、異なるカテゴリ間の関係を捉えた新しい特徴を作成し、モデルの予測力を向上させることができます。 データの可視化: ラベルエンコーディングはデータの可視化のためにも使用することができます。カテゴリカル変数をエンコードすることで、数値入力が必要なプロットやチャート上でカテゴリデータを表現することができます。カテゴリ変数をエンコードすることで、データに対する洞察を提供する意味のある可視化を作成することができます。…

「機械エンジニアからデータサイエンティストへの転職方法」
データサイエンスは世界を変革し、問題解決のアプローチ方法を変えました。データプロフェッショナルへの高い需要、高収入、そして成長するキャリアパスにより、さまざまな分野の専門家がデータサイエンスへのキャリア転換を望んでいます。それは機械工学者にも言えます。機械工学者からデータサイエンティストへの転身は、エンジニアリングの専門知識とデータ分析、機械学習、プログラミングの複雑さとのギャップを埋めることを求められる興奮を伴うものです。 新しい技術的なスキルを身につけるだけでなく、データの力を活用して情報に基づいた意思決定を促進する新しいマインドセットを開発する必要があります。この記事では、機械工学者からデータサイエンティストへのキャリア転換方法について詳しく説明します! 機械工学とデータサイエンスの関係はどのようなものですか? 最初に見ると、データサイエンスと機械工学は別々の専門職のように見えますが、さまざまな方法で関連しています。デジタル変革の時代において、データサイエンスの概念とアプローチを機械工学に取り入れることはますます重要になっています。以下に、データサイエンスと機械工学の関連例をいくつか示します: 予知保全 予知保全は機械工学における重要な領域であり、データサイエンスが不可欠です。データサイエンティストは、装置から収集される大量のセンサーデータを分析し、事前に故障や保守の必要性が予測できる予測モデルを作成することができます。この予測モデルにより、ダウンタイムを最小限に抑え、保守スケジュールを最適化し、機械システムの全体的な効果と信頼性を向上させることができます。 設計の最適化 データサイエンスの手法(統計モデリング、シミュレーション、機械学習など)を使用することで、機械システムや部品の設計を改善することができます。シミュレーション、実世界のテスト、過去の性能のデータを分析することで、設計パラメータに対する洞察を得ることができ、ボトルネックを見つけ、性能、耐久性、エネルギー効率を向上させることができます。 性能のモニタリングと分析 データサイエンスのおかげで、機械工学者は複雑なシステムのパフォーマンスをリアルタイムで追跡・評価することができます。センサーデータを使用することで、エンジニアはシステムの振る舞いについて多くのことを学び、異常を検出し、パフォーマンスを向上させることができます。このデータ駆動の手法を使用することで、エンジニアはシステムの運用、保守、改善について情報をもとにした判断を行うことができます。 計算流体力学(CFD) 計算流体力学(CFD)は、流体の流れと熱伝達を分析する機械工学の分野で、データサイエンスの手法を多く利用しています。データサイエンティストは、シミュレーション、アルゴリズム、数値解析手法を使用して流体の振る舞いをモデル化し、分析することができます。データサイエンスの手法により、エンジニアはCFDシミュレーションから貴重なデータを収集し、モデルを検証し、設計を改善することができます。 ビッグデータ分析 センサーデータ、IoTデバイス、自動化システムの利用可能性の拡大により、ビッグデータが生まれました。巨大で複雑なデータセットの取り扱い、分析、結論を得るためには、データサイエンスが不可欠です。機械工学者はビッグデータ分析の手法を使用して、意思決定、システムの最適化、プロセスの改善に役立つパターン、トレンド、相関関係を見つけることができます。 自動化とロボット工学 機械工学において、自動化とロボットはデータサイエンスと機械学習にとって重要な要素です。これらのイノベーションにより、データから学習し、状況の変化に対応し、独立した判断を行うことができるインテリジェントシステムを作成することが可能になります。ロボットシステムはデータサイエンスの手法を使用して訓練され、仕事を実行し、環境を移動し、人々と効果的にコミュニケーションを取ることができます。 参考:石油工学からデータサイエンスへの移行:Jaiyesh Chaharの旅 機械工学者からデータサイエンティストへの転身 機械工学からデータサイエンスへのキャリア転換をする際には、以下のポイントに注意してください: スキルの評価と知識のギャップの特定 まず、現在のスキルセットを評価し、新しい情報を学ぶ必要がある分野を特定します。データサイエンスには、統計分析、機械学習アルゴリズム、データ可視化技術、PythonやRなどのプログラミングスキルの知識が必要です。 オンラインリソースを活用して知識を習得する データサイエンスへの入門方法については、オンラインコースを通じて柔軟かつ快適に学ぶことができます。キャリア転換者向けに特別に作成されたデータサイエンスの詳細なコースを提供する信頼性のあるウェブサイトを探してください。プログラミング、統計学、機械学習、データ分析などのトピックがこれらのクラスに頻繁に含まれています。…
PlotlyとPandas:効果的なデータ可視化のための力の結集
昔々、私たちの多くがこの問題にぶつかったことがありましたもし才能がないか、前もってデザインのコースを受講したことがなければ、視覚的なものを作ることはかなり困難で時間がかかるかもしれません…

「機械学習を使ってイタリアのファンタジーフットボールで勝利した方法」
「機械工学の専門家としてプログラミングとコンピュータサイエンスに興味を持っていた私は、数年前に機械学習と人工知能の世界に魅了されました彼らの重要性を認識し…」
「機械学習を使ったイタリアンファンタジーフットボールで勝利した方法」
数年前からプログラミングとコンピュータサイエンスに興味を持つ機械工学のエンジニアとして、私は機械学習と人工知能の世界に魅了されました彼らの重要性を認識し、
「ディープラーニングモデルのレイヤーを凍結する方法 – 正しいやり方」
「モデルの微調整を行いたい場合や、処理する例に応じて一部のパラメータを固定することは、しばしば有用です以下の例で示されているように、処理する例に応じて一部のレイヤーを固定したい場合があります見てわかる通り…」

「データサイエンスの役割に関するGoogleのトップ50のインタビュー質問」
イントロダクション Googleでのキャリアを手に入れるためのコードを解読することは、多くのデータサイエンティスト志望者にとっての夢です。しかし、厳しいデータサイエンスの面接プロセスをクリアするにはどうすればよいのでしょうか?面接で成功するために、機械学習、統計学、プロダクトセンス、行動面をカバーするトップ50のGoogleのインタビュー質問の包括的なリストを作成しました。これらの質問に慣れて、回答の練習をしてください。これにより、面接官に印象を与え、Googleでのポジションを確保する可能性が高まります。 データサイエンスのGoogle面接プロセス Googleのデータサイエンティストの面接を通過することは、あなたのスキルと能力を評価するエキサイティングな旅です。このプロセスには、データサイエンス、問題解決、コーディング、統計学、コミュニケーションなど、さまざまなラウンドが含まれています。以下は、あなたが期待できる内容の概要です: ステージ 説明 応募の提出 Googleのキャリアウェブサイトを通じて、採用プロセスを開始するために応募と履歴書を提出します。 テクニカルな電話スクリーン 選考された場合、コーディングスキル、統計学の知識、データ分析の経験を評価するためにテクニカルな電話スクリーンが行われます。 オンサイト面接 成功した候補者は、通常、データサイエンティストや技術的な専門家との複数のラウンドからなるオンサイト面接に進みます。これらの面接では、データ分析、アルゴリズム、統計学、機械学習の概念など、より深く掘り下げたトピックについて話し合います。 コーディングと分析の課題 プログラミングスキルを評価するためにコーディングの課題に取り組み、データから洞察を抽出する能力を評価するために分析の課題に直面します。 システム設計と行動面の面接 一部の面接ではシステム設計に焦点を当て、スケーラブルなデータ処理や分析システムの設計を期待されることがあります。また、行動面の面接では、チームワーク、コミュニケーション、問題解決のアプローチを評価します。 採用委員会の審査 面接のフィードバックは採用委員会によって審査され、最終的な採用の決定が行われます。 Googleデータサイエンティストになる方法についての詳細な応募と面接のプロセスについては、当社の記事をご覧ください! データサイエンスの役職に関するトップ50のGoogleインタビューの質問と回答をまとめました。 データサイエンスのためのトップ50のGoogleインタビュー質問 機械学習、統計学、コーディングなどをカバーするトップ50のインタビュー質問の包括的なリストで、Googleのデータサイエンスの面接に備えてください。これらの質問をマスターし、あなたの専門知識を示して、Googleでのポジションを確保しましょう。 Googleの機械学習とAIに関するインタビューの質問 1.…

‘Perceiver IO どんなモダリティにも対応するスケーラブルな完全注意モデル’
TLDR 私たちはPerceiver IOをTransformersに追加しました。これは、テキスト、画像、音声、ビデオ、ポイントクラウドなど、あらゆる種類のモダリティ(それらの組み合わせも含む)に対応した最初のTransformerベースのニューラルネットワークです。以下のスペースをご覧いただくと、いくつかの例をご覧いただけます。 画像間のオプティカルフローの予測 画像の分類。 また、いくつかのノートブックも提供しています。 以下に、モデルの技術的な説明をご覧いただけます。 はじめに Transformerは、元々Vaswaniらによって2017年に紹介され、機械翻訳の最先端(SOTA)の結果を改善するというAIコミュニティでの革命を引き起こしました。2018年には、BERTがリリースされ、トランスフォーマーエンコーダ専用のモデルで、自然言語処理(NLP)のベンチマーク(特にGLUEベンチマーク)を圧倒的に上回りました。 その後まもなくして、AI研究者たちはBERTのアイデアを他の領域にも適用し始めました。以下にいくつかの例を挙げます。 Facebook AIのWav2Vec2は、このアーキテクチャをオーディオに拡張できることを示しました。 Google AIのVision Transformer(ViT)は、このアーキテクチャがビジョンに非常に適していることを示しました。 最近では、Google AIのVideo Vision Transformer(ViViT)もこのアーキテクチャをビデオに適用しました。 これらのすべての領域で、大規模な事前トレーニングとこの強力なアーキテクチャの組み合わせにより、最先端の結果が劇的に改善されました。 ただし、Transformerのアーキテクチャには重要な制約があります。自己注意機構により、計算およびメモリの両方でスケーリングが非常に悪くなります。各レイヤーでは、すべての入力をクエリとキーの生成に使用し、ペアごとのドット積を計算します。したがって、高次元データに自己注意を適用するには、ある形式の前処理が必要です。たとえば、Wav2Vec2では、生の波形を時間ベースの特徴のシーケンスに変換するために、特徴エンコーダを使用してこの問題を解決しています。Vision Transformer(ViT)は、画像を重ならないパッチのシーケンスに分割し、「トークン」として使用します。Video Vision Transformer(ViViT)は、ビデオから重ならない時空間の「チューブ」を抽出し、「トークン」として使用します。Transformerを特定のモダリティで動作させるためには、通常はトークンのシーケンスに離散化する必要があります。…

TransformersとRay Tuneを使用したハイパーパラメータの検索
Anyscale チームの Richard Liaw によるゲストブログ投稿 最先端の研究実装や数千ものトレーニング済みモデルへの簡単なアクセスが可能な Hugging Face transformers ライブラリは、自然言語処理の成功と成長において重要な存在となっています。 良いパフォーマンスを達成するために、ほとんどのユーザーはパラメータのチューニングを行う必要があります。しかし、ほとんどの人はハイパーパラメータのチューニングを無視するか、小さな探索空間で簡素なグリッドサーチを行うことを選択します。 しかし、簡単な実験でも高度なチューニング手法の利点を示すことができます。以下は、Hugging Face transformers の BERT モデルを RTE データセットで実行した最近の実験結果です。PBT のような遺伝的最適化手法は、標準的なハイパーパラメータ最適化手法と比較して大幅なパフォーマンス向上を提供できます。 アルゴリズム 最高の検証精度 最高のテスト精度 合計…

fairseqのwmt19翻訳システムをtransformersに移植する
Stas Bekmanさんによるゲストブログ記事 この記事は、fairseq wmt19翻訳システムがtransformersに移植された方法をドキュメント化する試みです。 私は興味深いプロジェクトを探していて、Sam Shleiferさんが高品質の翻訳者の移植に取り組んでみることを提案してくれました。 私はFacebook FAIRのWMT19ニュース翻訳タスクの提出に関する短い論文を読み、オリジナルのシステムを試してみることにしました。 最初はこの複雑なプロジェクトにどう取り組むか分からず、Samさんがそれを小さなタスクに分解するのを手伝ってくれました。これが非常に助けになりました。 私は、両方の言語を話すため、移植中に事前学習済みのen-ru / ru-enモデルを使用することを選びました。ドイツ語は話せないので、de-en / en-deのペアで作業するのははるかに難しくなります。移植プロセスの高度な段階で出力を読んで意味を理解することで翻訳の品質を評価できることは、多くの時間を節約することができました。 また、最初の移植をen-ru / ru-enモデルで行ったため、de-en / en-deモデルが統合されたボキャブラリを使用していることに全く気づいていませんでした。したがって、2つの異なるサイズのボキャブラリをサポートするより複雑な作業を行った後、統合されたボキャブラリを動作させるのは簡単でした。 手抜きしましょう 最初のステップは、もちろん手抜きです。大きな努力をするよりも小さな努力をする方が良いです。したがって、fairseqへのプロキシとして機能し、transformersのAPIをエミュレートする数行のコードで短いノートブックを作成しました。 もし基本的な翻訳以外のことが必要なければ、これで十分でした。しかし、もちろん、完全な移植を行いたかったので、この小さな勝利の後、より困難な作業に移りました。 準備 この記事では、~/portingの下で作業していると仮定し、したがってこのディレクトリを作成します:…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.