Learn more about Search Results Transformer - Page 94

- You may be interested
- 「チャットGPTとBardの無料版の実用的な比...
- ミッドジャーニーV5:ミッドジャーニーの...
- 木材トランジスターが根付く
- テキストによる画像および3Dシーン編集の...
- 「Amazonが処方せんのドローン配送をテス...
- Amazon SageMakerを使用して、オーバーヘ...
- AI教授:ハーバード大学、ChatGPTのような...
- データサイエンティストが知っておくべき1...
- 「DifFaceに会ってください:盲目の顔の修...
- チャットボットの台頭
- 「GATE DA 2024のサンプル問題集」
- 「コールセンターがAIを活用してエージェ...
- 「人工知能の炭素足跡」
- 「GAN(生成敵対ネットワーク)はおそらく...
- 「データエンジニアリングの面接質問」

GPTとBERT:どちらが優れているのか?
生成AIの人気の高まりに伴い、大規模言語モデルの数も増加していますこの記事では、GPTとBERTの2つのモデルを比較しますGPT(Generative...

大規模言語モデルに関するより多くの無料コース
大規模言語モデルについて学びたいですか? DeepLearning.AI、Google Cloud、Udacityなどの無料のコースで、すぐに始めましょう
PatchTST 時系列予測における画期的な技術革新
トランスフォーマーベースのモデルは、自然言語処理の分野(BERTやGPTモデルなど)やコンピュータビジョンなど、多くの分野で成功を収めていますしかし、時間の問題になると...

Light & WonderがAWS上でゲーミングマシンの予測保守ソリューションを構築した方法
この記事は、ライトアンドワンダー(L&W)のアルナ・アベヤコーン氏とデニス・コリン氏と共同執筆したものですライトアンドワンダーは、ラスベガスを拠点とするクロスプラットフォームゲーム会社であり、ギャンブル製品やサービスを提供していますAWSと協力して、ライトアンドワンダーは最近、業界初の安全なソリューション「Light & Wonder Connect(LnW Connect)」を開発しました[…]
科学者たちは、AIと迅速な応答EEGを用いて、せん妄の検出を改善しました
うつ病を検出することは容易ではありませんが、それには大きな報酬があります。患者に必要な治療を迅速かつ確実に行うことで、より早く、より確実に回復することができます。 改善された検出は、長期的な熟練したケアの必要性を減らし、患者の生活の質を向上させ、重要な財政的負担を減らすことができます。米国では、うつ病に苦しむ人のケアには、国立衛生研究所によると、年間6万4千ドルの費用がかかります。 先月Natureに掲載された論文によると、研究者たちは、高齢者の重症患者におけるうつ病の検出に、NVIDIA GPUによって加速された深層学習モデルであるVision Transformerと、迅速な応答型脳波測定装置であるEEGを使用した方法を説明しています。 この論文は、「限られたリードEEGを使用した監視付き深層学習モデルによるVision Transformerによるうつ病の予測」と題され、サウスカロライナ大学のマリッサ・マルキー、パデュー大学の黄河燃、東カロライナ大学のトーマス・アルバネーゼとSunghan Kim、およびパデュー大学のBaijian Yangが執筆しています。 彼らの革新的なアプローチは、テスト精度率が97%という結果を得て、認知症の予測において可能性のあるブレークスルーを約束しています。そして、AIとEEGを活用することで、研究者たちは予防と治療方法を客観的に評価し、より良いケアを提供することができます。 この印象的な結果は、NVIDIA GPUの高速パフォーマンスの一部によるものであり、CPUに比べてタスクを半分の時間で達成することができました。 うつ病は、重症患者の80%に影響を与えます。しかし、従来の臨床的な検出方法では、症例の40%未満が確認されており、患者ケアの重要なギャップを表しています。現在、ICU患者のスクリーニングには、主観的なベッドサイド評価が必要です。 携帯型EEG装置の導入により、スクリーニングをより正確かつ手頃な価格で実施できるようになる可能性がありますが、技術者と神経学者の不足は課題です。 しかしながら、AIの利用により、神経学者が所見を解釈する必要がなくなり、患者が治療により受容的な2日前にうつ病に関連する変化を検出することができます。また、最小限のトレーニングでEEGを使用することが可能になります。 研究者たちは、自然言語処理のために最初に作成されたAIモデルであるViTを、EEGデータに適用しました。これにより、データ解釈に新しいアプローチが可能になりました。 大型EEGマシンや専門技術者が必要ない迅速なEEG装置の使用は、この研究の重要な発見の一つでした。 この実用的なツールと、収集されたデータを解釈するための高度なAIモデルを組み合わせることで、重症ケアユニットにおけるうつ病のスクリーニングを効率化することができます。 この研究は、病院滞在期間を短縮し、退院率を増加させ、死亡率を減少させ、うつ病に関連する財政的負担を減らすための有望な方法を提供しています。 NVIDIA GPUのパワーと革新的な深層学習モデル、実用的な医療機器を統合することで、この研究は技術が患者ケアを向上させる可能性を強調しています。 AIが成長し発展するにつれて、医療専門家は認知症などの状態を予測し、早期に介入するために、ますますそれに頼ることになるでしょう。これは、重症ケアの将来を変革することになります。 全文を読む。

マルチヘッドアテンションを使用した注意機構の理解
はじめに Transformerモデルについて詳しく学ぶ良い方法は、アテンションメカニズムについて学ぶことです。特に他のタイプのアテンションメカニズムを学ぶ前に、マルチヘッドアテンションについて学ぶことは良い選択です。なぜなら、この概念は少し理解しやすい傾向があるためです。 アテンションメカニズムは、通常の深層学習モデルに追加できるニューラルネットワークレイヤーと見なすことができます。これにより、重要な部分に割り当てられた重みを使用して、入力の特定の部分に焦点を当てるモデルを作成することができます。ここでは、マルチヘッドアテンションメカニズムを使用して、アテンションメカニズムについて詳しく見ていきます。 学習目標 アテンションメカニズムの概念 マルチヘッドアテンションについて Transformerのマルチヘッドアテンションのアーキテクチャ 他のタイプのアテンションメカニズムの概要 この記事は、データサイエンスブログマラソンの一環として公開されました。 アテンションメカニズムの理解 まず、この概念を人間の心理学から見てみましょう。心理学では、注意は他の刺激の影響を除外して、イベントに意識を集中することです。つまり、他の注意を引くものがある場合でも、私たちは選択したものに焦点を合わせます。注意は全体の一部に集中します。 これがTransformerで使用される概念です。彼らは入力のターゲット部分に焦点を当て、残りの部分を無視することができます。これにより、非常に効果的な方法で動作することができます。 マルチヘッドアテンションとは? マルチヘッドアテンションは、Transformerにおいて中心的なメカニズムであり、ResNet50アーキテクチャにおけるskip-joiningに相当します。場合によっては、アテンドするべきシーケンスの複数の他の点があります。全体の平均を見つける方法では、重みを分散させて多様な値を重みとして与えることができません。これにより、複数のアテンションメカニズムを個別に作成するアイデアが生まれ、複数のアテンションメカニズムが生じます。実装では、1つの機能に複数の異なるクエリキー値トリプレットが表示されます。 出典:Pngwing.com 計算は、アテンションモジュールが何度も反復し、アテンションヘッドとして知られる並列レイヤーに組織化される方法で実行されます。各別のヘッドは、入力シーケンスと関連する出力シーケンスの要素を独立して処理します。各ヘッドからの累積スコアは、すべての入力シーケンスの詳細を組み合わせた最終的なアテンションスコアを得るために組み合わされます。 数式表現 具体的には、キーマトリックスとバリューマトリックスがある場合、値をℎサブクエリ、サブキー、サブバリューに変換し、アテンションを独立して通過させることができます。連結すると、ヘッドが得られ、最終的な重み行列でそれらを組み合わせます。 学習可能なパラメータは、アテンションに割り当てられた値であり、各パラメータはマルチヘッドアテンションレイヤーと呼ばれます。以下の図はこのプロセスを示しています。 これらの変数を簡単に見てみましょう。Xの値は、単語埋め込みの行列の連結です。 行列の説明 クエリ:シーケンスのターゲットについての洞察を提供する特徴ベクトルです。クエリは、何がアテンションを必要としているかをシーケンスに要求します。 キー:要素に含まれるものを説明する特徴ベクトルです。クエリによってアテンションが与えられ、要素のアイデンティティを提供します。 値:…

CapPaに会ってください:DeepMindの画像キャプション戦略は、ビジョンプレトレーニングを革新し、スケーラビリティと学習性能でCLIPに匹敵しています
「Image Captioners Are Scalable Vision Learners Too」という最近の論文は、CapPaと呼ばれる興味深い手法を提示しています。CapPaは、画像キャプションを競争力のある事前学習戦略として確立することを目的としており、DeepMindの研究チームによって執筆されたこの論文は、Contrastive Language Image Pretraining(CLIP)の驚異的な性能に匹敵する可能性を持つと同時に、簡単さ、拡張性、効率性を提供することを強調しています。 研究者たちは、Capと広く普及しているCLIPアプローチを比較し、事前学習コンピュータ、モデル容量、トレーニングデータを慎重に一致させ、公平な評価を確保しました。研究者たちは、Capのビジョンバックボーンが、少数派分類、キャプション、光学式文字認識(OCR)、視覚的問い合わせ(VQA)を含むいくつかのタスクでCLIPモデルを上回ったことがわかりました。さらに、大量のラベル付きトレーニングデータを使用した分類タスクに移行する際、CapのビジョンバックボーンはCLIPと同等の性能を発揮し、マルチモーダルなダウンストリームタスクにおける潜在的な優位性を示しています。 さらに、研究者たちは、Capの性能をさらに向上させるために、CapPa事前学習手順を導入しました。この手順は、自己回帰予測(Cap)と並列予測(Pa)を組み合わせたものであり、画像理解に強いVision Transformer(ViT)をビジョンエンコーダーとして利用しました。画像キャプションを予測するために、研究者たちは、標準的なTransformerデコーダーアーキテクチャを使用し、ViTエンコードされたシーケンスをデコードプロセスに効果的に使用するために、クロスアテンションを組み込みました。 研究者たちは、訓練段階でモデルを自己回帰的にのみ訓練するのではなく、モデルがすべてのキャプショントークンを独立して同時に予測する並列予測アプローチを採用しました。これにより、デコーダーは、並列でトークン全体にアクセスできるため、予測精度を向上させるために、画像情報に強く依存できます。この戦略により、デコーダーは、画像が提供する豊富な視覚的文脈を活用することができます。 研究者たちは、画像分類、キャプション、OCR、VQAを含むさまざまなダウンストリームタスクにおけるCapPaの性能を、従来のCapおよび最先端のCLIPアプローチと比較するための研究を行いました。その結果、CapPaはほぼすべてのタスクでCapを上回り、CLIP*と同じバッチサイズで訓練された場合、CapPaは同等または優れた性能を発揮しました。さらに、CapPaは強力なゼロショット機能を備え、見知らぬタスクにも効果的な汎化が可能であり、スケーリングの可能性があります。 全体的に、この論文で提示された作業は、画像キャプションを競争力のあるビジョンバックボーンの事前学習戦略として確立することを示しています。CapPaの高品質な結果をダウンストリームタスクにおいて実現することにより、研究チームは、ビジョンエンコーダーの事前トレーニングタスクとしてのキャプションの探索を促進することを望んでいます。その簡単さ、拡張性、効率性により、CapPaは、ビジョンベースのモデルを進化させ、マルチモーダル学習の境界を押し広げるための興味深い可能性を開拓しています。
再帰型ニューラルネットワークの基礎からの説明と視覚化
再帰型ニューラルネットワーク(RNN)は、順次操作が可能なニューラルネットワークです数年前ほど人気はありませんが、重要な発展を表しています...
言語学習モデルにおけるOpenAIの関数呼び出しの力:包括的なガイド
OpenAIの関数呼び出し機能を使用したデータパイプラインの変換:PostgreSQLとFastAPIを使用した電子メール送信ワークフローの実装
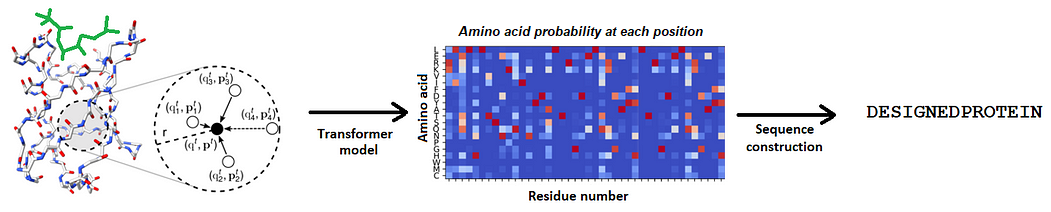
あらゆる種類の分子との相互作用を理解する新しいAIモデルによって、タンパク質デザインの領域での境界を打破する
DeepmindのAlphaFoldによって始まった構造生物学の革命の後、関連するタンパク質設計の分野は、深層学習の力によって最近新しい進展の時代に入りました...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.