Learn more about Search Results Transformer - Page 93

- You may be interested
- 「GPTQまたはbitsandbytes:LLMsのために...
- vLLM:24倍速のLLM推論のためのPagedAtten...
- マイクロソフトリサーチは、競合モデルよ...
- 「AIスタートアップのトレンド:Y Combina...
- 「生成AIは世界を変える可能性があるが、...
- 将来のPythonバージョン(3.12など)に一...
- LLMとデータ分析:ビジネスの洞察を得るた...
- 『ダフニーを使用してラストのアルゴリズ...
- グローバルなチョコレート貿易の概要
- 『デイリースタンドアップで時間を無駄に...
- より小さい相手による言語モデルからの知...
- Falcon AI 新しいオープンソースの大規模...
- 統計的推定と推論の初心者向け解説
- 「Pythonを使用して美しい折れ線グラフを...
- Weaviate入門:ベクトルデータベースを使...

PyTorchを使用した効率的な画像セグメンテーション:パート3
この4部シリーズでは、PyTorchを使用して深層学習技術を使い、画像セグメンテーションをスクラッチからステップバイステップで実装しますこのパートでは、CNNベースラインモデルを最適化することに焦点を当てます
PyTorchを使用した効率的な画像セグメンテーション:Part 4
この4部構成のシリーズでは、PyTorchを使用した深層学習技術を使って、画像セグメンテーションをゼロからステップバイステップで実装しますこのパートでは、Vision Transformerをベースとしたモデルの実装に焦点を当てます

AIは精神疾患の検出に優れています
重症患者のせん妄検知は、患者のケアや回復に重要な影響を与える複雑なタスクです。しかし、人工知能(AI)と迅速な反応型脳波(EEG)の進歩により、せん妄検知が変革されています。Natureに掲載された研究によると、科学者たちはNVIDIA GPUの力を借りてAIを活用し、驚くべき精度でせん妄検知を実現しました。このブレイクスルーには、重症患者のケアを革新し、患者アウトカムを改善し、せん妄に関連する財政的負担を減らす可能性があります。この興味深い研究の詳細について見ていきましょう。 また読む:試行錯誤から精度へ:高血圧治療のAIの答え せん妄の理解 せん妄は、医療状態、精神活性物質、または複数の原因による急性の混乱状態です。数時間から数日で発症し、注意、意識、高次の認知障害を伴います。せん妄の人は、他の神経精神症状、例えば、心理運動活動の変化、睡眠覚醒周期、感情や知覚の障害を経験するかもしれません。ただし、これらは診断に必要ではありません。 せん妄検知の重要性 せん妄は、重症患者の間で広く見られる急性の混乱状態であり、早期に検出することで適切なケアを提供し、回復を促進し、長期にわたるスキルの必要な介護を減らすことができます。米国では、NIHによると、せん妄の財政的影響は年間1人あたり最大で64,000ドルになることがあります。 ブレークスルーの研究:AIとEEGによるせん妄検知 最近のNatureの出版物「Supervised deep learning with vision transformer predicts delirium using limited lead EEG」において、研究チームはせん妄検知に対する画期的なアプローチを紹介しました。NVIDIA GPUによって加速されたディープラーニングモデルであるVision Transformerを、迅速な反応型EEGデバイスと組み合わせることで、驚異的なテスト精度率97%を達成しました。このブレークスルーにより、認知症を予測し、予防や治療方法の評価を容易にし、患者ケアを改善する可能性があります。 また読む:ヘルスケアのMLの利用:予測分析と診断 NVIDIA…

ゼロから学ぶアテンションモデル
はじめに アテンションモデル、またはアテンションメカニズムとも呼ばれるものは、ニューラルネットワークの入力処理技術に使用されるものです。これにより、ネットワークは複雑な入力の異なる側面に集中し、全データセットを分類するまでに個別に処理できます。目標は、複雑なタスクを順次処理される注目の小さな範囲に分解することです。このアプローチは、人間の心が新しい問題をより簡単なタスクに分解し、ステップバイステップで解決する方法に類似しています。アテンションモデルは、特定のタスクにより適応し、パフォーマンスを最適化し、関連情報に注意を払う能力を向上することができます。 NLPにおけるアテンションメカニズムは、過去10年間でディープラーニングにおける最も価値のある発展の1つです。TransformerアーキテクチャやGoogleのBERTなどの自然言語処理(NLP)は、最近の進歩をもたらしています。 学習目標 ディープラーニングにおけるアテンションメカニズムの必要性、機能、モデルのパフォーマンスを向上させる方法を理解する。 アテンションメカニズムの種類や使用例を知る。 あなたのアプリケーションとアテンションメカニズムの使用のメリットとデメリットを探究する。 アテンションの実装例に従ってハンズオンでの経験を得る。 この記事はData Science Blogathonの一部として公開されました。 アテンションフレームワークを使用するタイミング アテンションフレームワークは、元々エンコーダー・デコーダー型のニューラル機械翻訳システムやコンピュータビジョンでのパフォーマンス向上に使用されました。従来の機械翻訳システムは、大規模なデータセットと複雑な機能を処理して翻訳を行っていましたが、アテンションメカニズムはこのプロセスを簡素化しました。アテンションメカニズムは、単語ごとに翻訳する代わりに、固定長のベクトルを割り当てて入力の全体的な意味と感情を捉え、より正確な翻訳を実現します。アテンションフレームワークは、エンコーダー・デコーダー型の翻訳モデルの制限に対処するのに特に役立ちます。入力のフレーズや文の正確なアラインメントと翻訳を可能にします。 アテンションメカニズムは、入力シーケンス全体を単一の固定コンテンツベクトルにエンコードするのではなく、各出力に対してコンテキストベクトルを生成することで、より効率的な翻訳が可能になります。アテンションメカニズムは翻訳の精度を向上させますが、常に言語的な完璧さを実現するわけではありません。しかし、オリジナルの入力の意図と一般的な感情を効果的に捉えることができます。要約すると、アテンションフレームワークは、従来の機械翻訳モデルの制限を克服し、より正確でコンテキストに対応した翻訳を実現するための貴重なツールです。 アテンションモデルはどのように動作するのか? 広い意味では、アテンションモデルは、クエリと一連のキー・バリューペアをマップする関数を使用して出力を生成します。これらの要素、クエリ、キー、値、および最終出力はすべてベクトルとして表されます。出力は、クエリと対応するキーの類似性を評価する互換性関数によって決定される重み付き平均値を取ることによって計算されます。 実践的な意味では、アテンションモデルは、人間が使用する視覚的アテンションメカニズムに近いものをニューラルネットワークで近似することを可能にします。人間が新しいシーンを処理する方法に似て、モデルは画像の特定の点に集中し、高解像度の理解を提供し、周囲の領域を低解像度で認識します。ネットワークがシーンをより良く理解するにつれて、焦点を調整します。 NumPyとSciPyを使用した一般的なアテンションメカニズムの実装 このセクションでは、PythonライブラリNumPyとSciPyを利用した一般的なアテンションメカニズムの実装を調べます。 まず、4つの単語のシーケンスのための単語埋め込みを定義します。単純化のために、単語埋め込みを手動で定義しますが、実際にはエンコーダーによって生成されます。 import numpy as np…

メタAIのもう一つの革命的な大規模モデル — 画像特徴抽出のためのDINOv2
Mete AIは、画像から自動的に視覚的な特徴を抽出する新しい画像特徴抽出モデルDINOv2の新バージョンを紹介しましたこれはAIの分野でのもう一つの革命的な進歩です...

グラフの復活:グラフの年ニュースレター2023年春
今日のナレッジグラフ、グラフデータベース、グラフアナリティクス、グラフAIの現在地と今後の方向性に関するニュースと分析を見つける
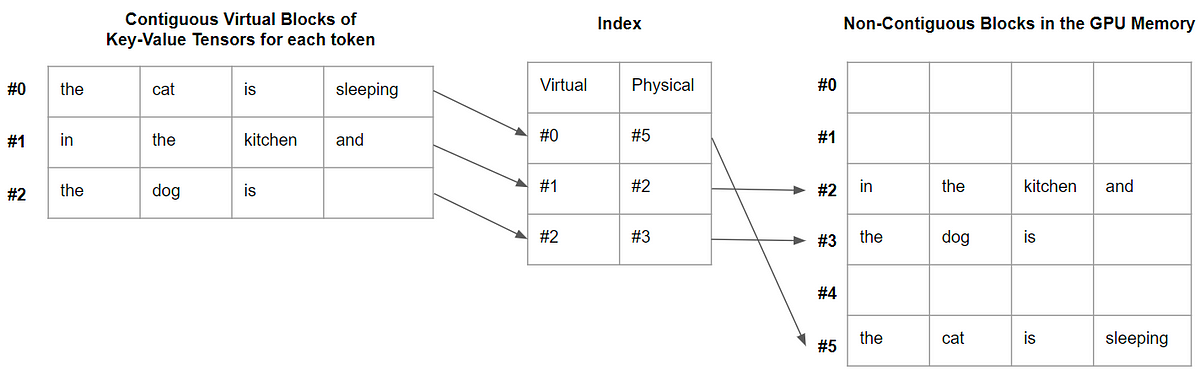
vLLM:24倍速のLLM推論のためのPagedAttention
この記事では、PagedAttentionとは何か、そしてなぜデコードを大幅に高速化するのかを説明します

Google研究者がAudioPaLMを導入:音声技術における革新者 – 聞き、話し、そして前例のない精度で翻訳する新しい大規模言語モデル
大規模言語モデル(LLM)が数ヶ月間注目を集めています。人工知能の分野で最も優れた進歩の1つであり、これらのモデルは人間と機械の相互作用の方法を変革しています。すべての業界がこれらのモデルを採用しているため、これらはAIが世界を支配する最良の例です。LLMは、複雑な相互作用や知識の取得を必要とするタスクに対してテキストを生成することで優れており、その最良の例は、GPT 3.5とGPT 4のTransformerアーキテクチャに基づくOpenAIが開発した有名なチャットボットであるChatGPTです。テキストの生成だけでなく、CLIP(コントラスティブ言語-画像事前トレーニング)のようなモデルも画像生成のために開発されており、画像の内容に応じてテキストを作成することができます。 音声生成と理解の進展を目指して、Googleの研究者チームは、音声理解と生成のタスクに対応できる大規模言語モデルであるAudioPaLMを紹介しました。AudioPaLMは、PaLM-2モデルとAudioLMモデルの2つの既存のモデルの利点を組み合わせて、テキストと音声の両方を処理および生成できる統一されたマルチモーダルアーキテクチャを生成します。これにより、AudioPaLMは音声認識から音声-to-テキスト変換までのさまざまなアプリケーションを処理できます。 AudioLMは話者のアイデンティティやトーンなどの並列言語情報を維持することに優れていますが、テキストベースの言語モデルであるPaLM-2は、テキスト固有の言語知識に特化しています。これら2つのモデルを組み合わせることで、AudioPaLMはPaLM-2の言語的専門知識とAudioLMの並列言語情報の保存を活用し、テキストと音声のより徹底的な理解と生成を実現します。 AudioPaLMは、限られた数の離散トークンを使用して音声とテキストの両方を表すことができる共通の語彙を使用しています。この共通の語彙をマークアップタスクの説明と組み合わせることで、さまざまな音声およびテキストベースのタスクに対して単一のデコーダーのみのモデルをトレーニングすることができます。従来は別々のモデルが対処していた音声認識、テキスト-to-スピーチ合成、音声-to-音声翻訳などのタスクが、単一のアーキテクチャとトレーニングプロセスに統合されるようになりました。 評価の結果、AudioPaLMは音声翻訳の既存システムを大幅に上回りました。未知の言語の組み合わせに対してゼロショット音声-to-テキスト翻訳を実行できるため、より広範な言語サポートの可能性を開くことができます。また、AudioPaLMは短い音声プロンプトに基づいて言語間で声を転送でき、異なる言語で特定の声を捕捉して再生することができるため、声の変換と適応が可能になります。 チームが言及した主な貢献は次のとおりです。 AudioPaLMは、テキストのみの事前トレーニングからPaLMとPaLM-2sの能力を利用しています。 自動音声翻訳および音声-to-音声翻訳のベンチマークでSOTAの結果を達成し、自動音声認識のベンチマークでも競争力のあるパフォーマンスを発揮しています。 モデルは、見たことのないスピーカーの声転送で音声-to-音声翻訳を実行し、音声品質と声の保存において既存の方法を超えています。 AudioPaLMは、見たことのない言語の組み合わせで自動音声翻訳を実行することにより、ゼロショットの機能を実証しています。 結論として、AudioPaLMは、テキストベースのLLMの能力を利用し、オーディオプロンプティング技術を組み合わせて、音声とテキストの両方を処理する統一されたLLMであり、LLMのリストに有望な追加です。

AIの未来を形作る ビジョン・ランゲージ・プリトレーニング・モデルの包括的な調査と、ユニモーダルおよびマルチモーダルタスクにおける役割
機械学習研究の最新リリースで、ビジョン言語事前学習(VLP)とその多様なタスクへの応用について、研究チームが深く掘り下げています。この論文は、単一モーダルトレーニングのアイデアを探究し、それがマルチモーダル適応とどのように異なるかを説明しています。そして、VLPの5つの重要な領域である特徴抽出、モデルアーキテクチャ、事前トレーニング目標、事前トレーニングデータセット、およびダウンストリームタスクを示しています。研究者たちは、既存のVLPモデルとその異なる側面での適応をレビューしています。 人工知能の分野は常に、モデルを人間と同じように知覚、思考、そしてパターンや微妙なニュアンスを理解する方法でトレーニングしようとしてきました。ビジュアル、オーディオ、テキストなど、可能な限り多くのデータ入力フィールドを組み込もうとする試みがいくつか行われてきました。ただし、これらのアプローチのほとんどは、単一モーダル意味で「理解」の問題を解決しようとしたものです。 単一モーダルアプローチは、1つの側面のみを評価するアプローチであり、例えばビデオの場合、音声またはトランスクリプトに焦点を絞っており、マルチモーダルアプローチでは、可能な限り多くの利用可能な特徴をターゲットにしてモデルに組み込もうとします。たとえば、ビデオを分析する際に、音声、トランスクリプト、スピーカーの表情をとらえて、文脈を本当に「理解」することができます。 マルチモーダルアプローチは、リソースが豊富であり、訓練に必要な大量のラベル付きデータを取得することが困難であるため、課題があります。Transformer構造に基づく事前トレーニングモデルは、自己教師あり学習と追加タスクを活用して、大規模な非ラベルデータからユニバーサルな表現を学習することで、この問題に対処しています。 NLPのBERTから始まり、単一モーダルの方法でモデルを事前トレーニングすることで、限られたラベル付きデータでダウンストリームタスクを微調整することができることが示されています。研究者たちは、同じ設計哲学をマルチモーダル分野に拡張することで、ビジョン言語事前学習(VLP)の有効性を探究しました。VLPは、大規模なデータセットで事前トレーニングモデルを使用して、モダリティ間の意味的な対応関係を学習します。 研究者たちは、VLPアプローチの進歩について、5つの主要な領域を検討しています。まず、VLPモデルが画像、ビデオ、テキストを前処理して表現する方法、使用されるさまざまなモデルを強調して説明しています。次に、単一ストリームの観点とその使用可能性、デュアルストリームフュージョンとエンコーダのみ対エンコーダデコーダ設計の観点を探究しています。 論文では、VLPモデルの事前トレーニングについてさらに探求し、完了、マッチング、特定のタイプに分類しています。これらの目標は、ユニバーサルなビジョン言語表現を定義するのに役立ちます。研究者たちは、2つの主要な事前トレーニングデータセットのカテゴリである画像言語モデルとビデオ言語モデルについて概説しました。論文では、マルチモーダルアプローチが文脈を理解し、より適切にマッピングされたコンテンツを生成するためにどのように役立つかを強調しています。最後に、記事は、事前トレーニングモデルの有効性を評価する上での重要性を強調しながら、VLPのダウンストリームタスクの目標と詳細を提示しています。 https://link.springer.com/content/pdf/10.1007/s11633-022-1369-5.pdf https://link.springer.com/content/pdf/10.1007/s11633-022-1369-5.pdf この論文では、SOTA(State-of-the-Art)のVLPモデルについて詳細な概要が提供されています。これらのモデルをリストアップし、その主要な特徴やパフォーマンスを強調しています。言及されているモデルは、最先端の技術開発の堅固な基盤であり、将来の開発のベンチマークとして役立ちます。 研究論文に基づくと、VLPアーキテクチャの将来は有望で信頼性があります。彼らは、音響情報の統合、知識と認知学習、プロンプトチューニング、モデル圧縮と加速、およびドメイン外の事前学習など、様々な改善の領域を提案しています。これらの改善領域は、新しい研究者たちがVLPの分野で前進し、画期的なアプローチを打ち出すためにインスピレーションを与えることを目的としています。
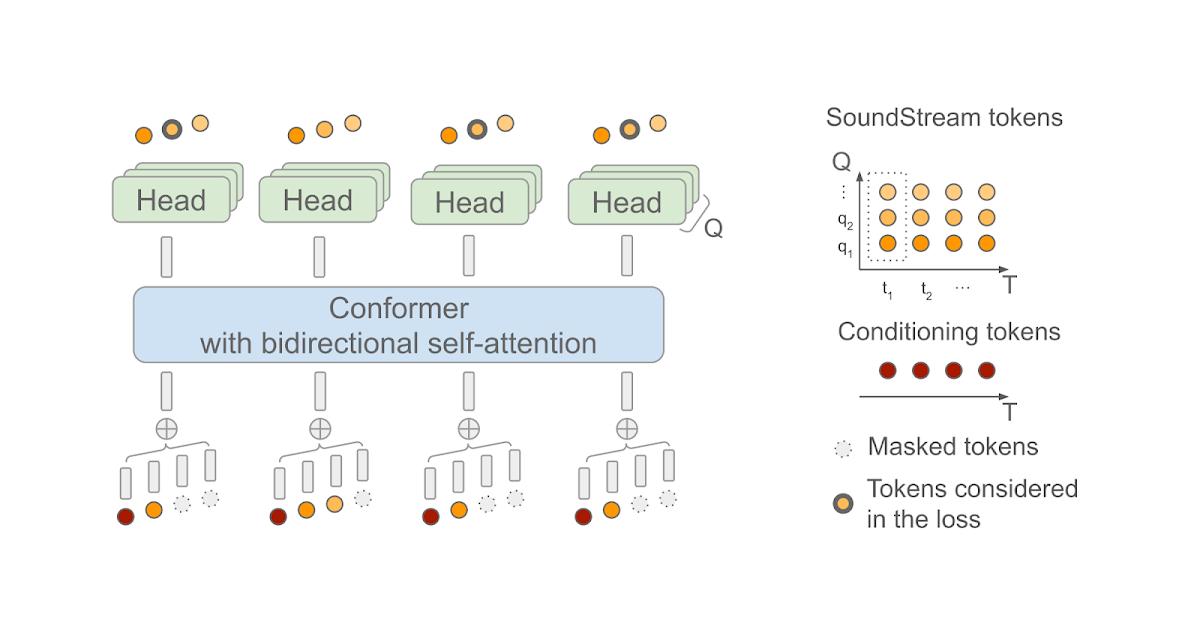
SoundStorm:効率的な並列音声生成
Zalán Borsos氏(リサーチソフトウェアエンジニア)とMarco Tagliasacchi氏(シニアスタッフリサーチサイエンティスト)がGoogle Researchで発表した記事です。 最近の生成AIの進歩により、テキスト、ビジョン、オーディオなど、さまざまな領域で新しいコンテンツを作成する可能性が開かれました。これらのモデルは、生データが最初にトークンのシーケンスとして圧縮されることに依存しています。オーディオの場合、ニューラルオーディオコーデック(例えば、SoundStreamまたはEnCodec)を使用して、波形をコンパクトな表現に効率的に圧縮することができます。これにより、元のオーディオ信号の近似値を再構成できます。この表現は、音の局所的な特性(たとえば、音素)および時間的構造(たとえば、韻律)を捉えた離散的な音声トークンのシーケンスで構成されています。オーディオを離散的なトークンのシーケンスとして表現することで、Transformerベースのシーケンスツーシーケンスモデルを使用してオーディオ生成を実行できるようになりました。これにより、音声継続性(AudioLMを使用した)、テキストから音声への変換(SPEAR-TTSを使用した)、一般的なオーディオや音楽の生成(AudioGenおよびMusicLMを使用した)において急速な進歩が可能になりました。多くの生成オーディオモデル、AudioLMを含む、自己回帰デコーディングに依存しています。この方法は高い音響品質を実現しますが、特に長いシーケンスをデコードする場合、推論(出力の計算)が遅くなることがあります。 この問題に対処するため、「SoundStorm: Efficient Parallel Audio Generation」という記事で、効率的かつ高品質なオーディオ生成の新しい方法を提案しています。SoundStormは、SoundStreamニューラルコーデックによって生成されるオーディオトークンの特性に適合するアーキテクチャと、MaskGITと呼ばれる最近提案された画像生成の方法に着想を得たデコードスキームの2つの新しい要素に依存して、長いオーディオトークンシーケンスの生成の問題に対処します。これにより、AudioLMの自己回帰デコーディングアプローチと比較して、SoundStormはトークンを並列に生成できるため、長いシーケンスの推論時間を100倍短縮することができ、同じ品質で、声質や音響条件の一貫性が高いオーディオを生成できます。さらに、SPEAR-TTSのテキストから意味論的モデリング段階と組み合わせたSoundStormは、例えば以下の例で示されるように、高品質で自然な対話を合成することができ、話される内容(トランスクリプトを介して)、話者の声(短い音声プロンプトを介して)、話者のターン(トランスクリプト注釈を介して)を制御できます。 入力:テキスト(オーディオ生成を駆動するトランスクリプトは太字) 今朝、私にとてもおかしなことが起こりました。| え、本当に?|普段通りに起きて、朝食を食べに下に降りたんです。|なるほど。| 食べ始めてから10分後に、今夜中だと気づいたんです。| あ、それはおもしろい。| 昨晩よく眠れなかったんだ。|え、どうしたの?|よくわからないんだ。どうしても寝付けなくて、一晩中寝返りを打ち続けたんだ。|そうなんだ。今晩は早く寝た方がいいかもしれないし、本でも読んでみるのはどうかな。|ああ、ありがとう。そうだといいんだけど。|どういたしまして。よく眠れるといいね。 入力:オーディオプロンプト 出力:オーディオプロンプト+生成されたオーディオ SoundStormの設計 以前のAudioLMの研究で、オーディオ生成を2つのステップに分解できることを示しました。1つ目は、意味的なトークンを生成する意味モデリングであり、前の意味トークンまたは条件信号(SPEAR-TTSのトランスクリプトやMusicLMのようなテキストプロンプトなど)から意味トークンを生成します。2つ目は、意味トークンから音声トークンを生成する音響モデリングです。SoundStormでは、より高速な並列デコードによって、より遅い自己回帰デコーディングを置き換え、音響モデリングに特に対処しています。 SoundStormは、トランスフォーマーと畳み込みを組み合わせたモデルアーキテクチャであるConformerに双方向アテンションを依存しており、トークンのシーケンスのローカルおよびグローバルな構造を捕捉します。具体的には、AudioLMが生成した意味トークンのシーケンスを入力として与えられた場合、SoundStreamによって生成されたオーディオトークンを予測するようにモデルが訓練されます。この際、各時間ステップtにおいて、SoundStreamは、右側に示すように、残差ベクトル量子化(RVQ)として知られる方法を使用して、最大Qトークンまでオーディオを表現します。主要な考え方は、各ステップで生成されるトークンの数が1からQに増えるにつれて、再構築されたオーディオの品質が徐々に向上するということです。 推論時には、入力として意味トークンを与えた場合、SoundStormは、すべてのオーディオトークンをマスクアウトし、RVQレベルq = 1の粗いトークンから始めて、より細かいトークンまでレベル別に進み、レベルq…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.